현재 진행중인 Multispectral Image Registration 연구와 비슷한 연구가 올라와 리뷰하게 됐습니다.
Introduction
저희 연구실에서는 Multispectral Sensor를 이용하여 Detection을 위주로 하다보니 Image Fusion이라는 task가 생소할 수 있습니다. 하지만 실제 찾아보니 Detection보다 Image Fusion이 더 활발히 이뤄지고 있으며, 해당 분야에 대해서 먼저 소개하겠습니다. Image Fusion은 RGB와 Thermal의 정보를 잘 융합한 새로운 Fused Image를 만드는 연구입니다.

이렇게 두 영상을 잘 융합할때, 더욱 풍부한 의미있는 feature를 추출할 수 있고, 이러한 연구는 실제 autonomous driving 이나 video surveillance에 사용된다고 합니다. 하지만 이러한 Image Fusion 분야에서도 한계는 명확히 존재했습니다. 논문에서는 그것을 ‘Hand-crafted pre-registered images’라고 명명했는데요. 두 모달리티 영상의 영상정합은 먼저 사람에 의해서 진행된다는 점이죠. 이러한 작업을 논문에서는 labor-intensive하고 time-sensitive하다고 이야기 합니다. 이뿐만 아니라 hand-crafted로 맞춘다고 하여도 논문에서는 추가적인 문제를 이야기합니다. 바로 fused imaeg에 ghosting artifacts가 존재한다는 점 입니다. 이러한 ghosting artifacts는 열심히 hand-crafted로 정합을 했지만 일부에서 misalignment가 존재하고 이런것들이 ghosting artifacts를 야기시킨다고 논문에서는 이야기합니다.
이와 관련된 여러 연구들을 설명하고, 본 논문에서는 저희 연구실 신정민 연구원이 열심히 사용했던 2020년 CVPR 연구였던 image-to-image translation을 이용하여 Multispectral image alignment를 수행한 연구를 소개하며 해당 연구에서 아이디어를 얻어 현 연구를 수행했다고 이야기했습니다. 따라서 해당 방식도 Unsupervised 방식입니다. 그리고 한가지 주장을 하는데, 열화상 영상은 sharp geometry structures가 texture details보다 강조된다는 점 입니다. 즉, multispectral image registration을 위해서는 sharp structure information이 더욱 도움이 된다는 것 입니다. (저도 이부분에 동의하고 Phase congruency 또한 이부분을 강조하기 위한 방식입니다.)
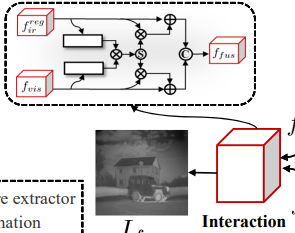
본 연구에서는 이러한 sharp structure information를 더욱 잘 보존하기위해 Cyclegan 기반 Cross-modality Perceptual Style Transfer Network(CPSTN)을 제안하였으며, 이때 RGB로 만든 수도 Infrared image와 reconstruct된 registed infrared image의 deformation을 예측하기 위한 Multi-level Refinement Registration Netowrk(MRRN) 을 활용했다고 합니다. 그리고 해당 연구에서는 이러한 registration연구에 추가적으로 fusion을 진행했다고 합니다. (제가 이해한게 맞다면 registration이 선행됐고, 추가적으로 fusion도 수행한것 같습니다. 아무래도 registration은 fusion 연구에서 대부분 사용되기 때문이라고 생각됩니다.) 추가적으로 수행한 Fusion 모듈에서는 일반적으로 정교하지 못한 concatenation, weighted average 와 같은 방식은 사용하지 않고 Interaction Fusion Module(IFM)을 사용했다고 합니다.
정리하면 2020CVPR 연구를 기반으로 Multispectral Registration을 수행하는데 sharp한 infromation을 더 살리기 위한 CPSTN을 제안하였고, 그때 Registration 방법으로 MRRN을 이용하였습니다. 그리고 이렇게 Registration만 수행할 수 있는데 추가적으로 정합된 영상을 가지고 Image Fusion을 수행하였으며, Image Fusion을 수행하는데 IFM이라는 모듈도 제안했다고 합니다.
본 논문에서 저자가 주장하는 Contribution은 다음과 같습니다.
We propose a highly-robust unsupervised infrared and visible image fusion framework, which is more focused on mitigating ghosting artifacts caused by the fusion of misaligned image pairs compared with learning-based fusion methods specialized for pre-registered images.
Considering the difficulty of the cross-modality image alignment, we exploit a specialized cross-modality generation-registration paradigm to bridge the large discrepancy between modalities, thus achieving effective infrared and visible image alignment.
An interaction fusion module is developed to adaptively fuse multi-modality features, which avoids feature smoothing caused by unsophisticated fusion rules and emphasizes faithful texture details.
Methods
Cross-modality Perceptual Style Transfer
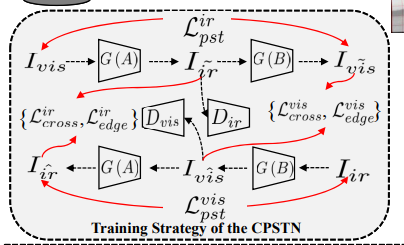
본 연구에서는 결국 Image Translation을 이용하여 Registration 네트워크를 Unsupervised 방식으로 학습합니다. 이때 가장 핵심은 RGB이미지를 이용하여 수도 Thermal 이미지를 만들고, 수도 Thermal 이미지와 실제 Thermal 이미지를 이용하여 Registration을 수행합니다. 아래 그림에서도 Visible을 IR로 만드는 과정을 볼 수 있습니다.
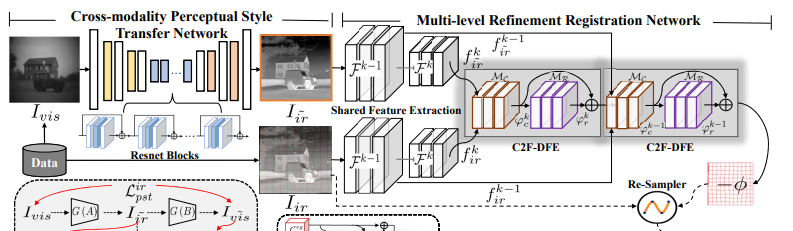
자 그럼 이 Image Translation 네트워크는 어떻게 구성하였을까요? 저자는 Cycle GAN을 기반으로 만들었지만 다르다고 합니다. 만들어지는 수도 Thermal 이미지의 sharp structure를 보존하기 위해서 아래와 같이 학습전략을 디자인했다고 합니다. (2022년 나온 논문들을 참조하여 나타냈는데, 해당 방식은 추후 알아봐야할 것 같습니다.) 자세한 내용은 뒤에서 설명하겠습니다.
Different from CycleGAN , we tend to design a specific learning strategy controlled by a perceptual style transfer constraint and establish the inter-path correlation between the twocycle generative routes to further optimize the generation of sharp structure of the pseudo infrared image.
Multi-level Refinement Registration
앞에서 CPSTN을 통해서 이제 단일 모달리티의 영상정합 문제가 됐습니다. (RGB를 sharp information이 살아있는 수도 Thermal로 만들었기 때문에) 그러면 이제 단일 모달리티간 영상 정합 문제를 해결하면 됩니다. 이를 위해서 본 연구에서는 MMRN을 제안하고 있습니다.
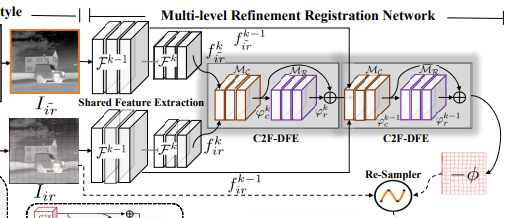
해당 모델은 결국 deformation field를 예측하게 됩니다. 뭐 해당 방식은 K개의 grid에 대해서 각각 offset 즉 deformation예측하고 이를 resampler layer를 통해서 registtration을 수행하게 됩니다.
Dual-path Interaction Fusion
이건 registration한 image를 fusion에 사용하는 부분입니다.
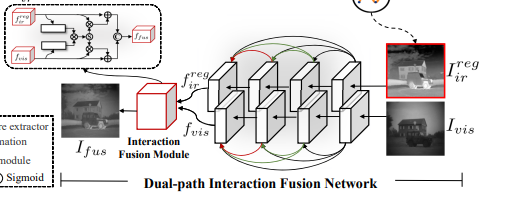
rgb와 thermal feature extract를 dual-pathe feature extraction module로 구성하여 피처를 추출한다고 합니다. (위에 보니까 두개의 path 로 구성됐네요)
Interaction Fusion Module
앞에서 dual path로 피처를 추출했으면 추출된 피처를 융합할때 concat, weighted average 같은 방식이 아니라 Interaction Fusion Module을 통해서 Fusiond을 수행했다고 합니다.
이를 수식으로 표현하면 아래와 같은데.. 굳이 설명하지 않겠습니다.

Loss Function
- Perceptual style transfer loss
리얼한 수도 Thermal 이미지를 만들기 위해서 사용한 Loss라고 합니다. 자세한 내용은 논문을 참조하시길 바랍니다.. (짧게 설명됐는데 다른곳에서 가져다 사용한 부분이라 해당 논문의 특자적인 것은 아니라고 생각돼 생략하겠습니다.) - Cross regularization loss
이거는 새로운 이미지를 만들때 content와 edge를 유지하기 위한 Loss 입니다. 여기서 재밌는 점은 저는 결국 PC를 사용하였는데, 해당 논문에서는 laplacian gradient operator를 사용했다고 합니다. (아마 해당 부분을 PC로 변경해서 성능차이를 확인해보는것도 재밌을것 같습니다)

- Registration loss
해당 부분은 앞서 Registration 한 Thermal와 실제 Thermal의 차이를 비교하는 동시에 반대로도 적용하여 비교하는 Loss 입니다. 즉 예측한 deformation 값을 수도 Thermal에 적용하여 Loss를 계산하고 Real Thermal에 적용하여 계산한것을 합친 Loss 입니다.
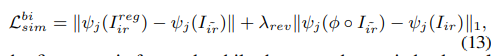
- Fusion Loss
Image Fusion을 위한 Loss인데.. SSIM을 사용합니다. (이후 자세한 부분은 생략하겠습니다.)

Experiments
본 연구에서는 misalignment cross-modality imaeg fusion에서 많이 사용되는 TNO, Road-Scene 데이터셋에서 사용했다고 합니다. 여기서 RoadScene 데이터셋은 FLIR 데이터셋의 일부(200장)를 샘플링하여 만든 데이터셋입니다. 근데 제가 알기로 Roadscene 데이터셋은 뭐 FLIR 같은 인덱스를 사용할 수 있다고 하는데, TNO 데이터셋은 사람이 맞춰서 공개했는데 어떻게 원본을 구했지라고 생각했는데……… 아래와 같이 저자가 설명합니다.
To meet the requirement of misaligned image pairs, we first generate several deformation fields by performing different degrees of affine and elastic transformations and then apply them to infrared images to obtain distorted images.
이게 맞나..? 라는 생각을 하게 됐습니다. 근데 뭐 저도 데이터셋을 못구하는 상황이니까 저자도 저자 나름대로 방식을 찾은건 아닐까 생각됩니다.
Evaluation in IR-VIS Image Registration
Image Registration분야에서는 MI, NCC, MSE로 평가를 수행하며, 본 연구에서도 이를 이용하여 Registration 결과를 평가하였습니다.
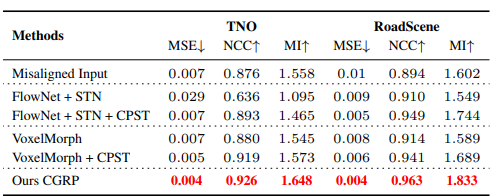
뭐 자신들의 방식이 가장 성능이 좋다고 이야기는 하는데.. 여기서 좀 이상한건 MSE가 Misaligned Input 즉 자신들이 임의로 deformation을 만든 입력에서 0.01이라고 합니다. 그렇다면 해당 방법론은 엄청나게 작은 misalignment에서만 작동하는게 아닌가 싶네요..
뭐 이후 FUsion에 대한 성능도 나타내는데 그것은 제 관심 대상이 아니라서.. 관심있는 평가 지표중 속도관련된 부분이 있습니다.
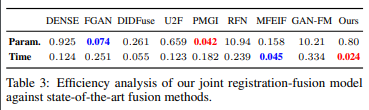
일단 지금 저희가 진행하는 연구보다는 2배정도 느린 속도를 나타내고 있습니다. 물론 Fusion 네트워크까지 합한 속도여서 실제 Registration만 수행했을때 차이가 어떻게 되는지 알아볼 필요성은 있습니다. 하지마 여기서 중요한 점은 모델의 입력이 64×64 입니다. GAN 방식이기 때문에 해상도가 크다면 성능저하가 더 심해질 수도 있습니다. 그래서 실제 detection과 같은 방식에서의 성능은 나타내지 않는건가 싶기도 합니다.


확실히 grid level에서의 deformation을 이용한 정합이라 정성적 결과로는 잘되고 있는것 같습니다만.. 이게 실제 원본 사이즈에 대해서도 적용되는지 부분은 알아봐야할 것 같네요.
결론
저희와 비교해볼 수 있을 것 이라고 생각되는데.. 코드도 공개했으니 확인해봐야할 것 같습니다. 또한 해당 연구에서 수행하는 deformation 기반 alignment 방식을 저희 연구에도 적용할 수 있을지 검토해보면 좋을것 같습니다.
내용이 좀 복잡하네요. 요약하자면 아래와 같나요?
1. 원본RGB에 image-to-image translation 적용해서 pseudo-Thermal 을 만듦
2. 해당 pseudo-thermal과 원본 thermal 이미지를 제안된 MRRN에 통과시켜 grid 단위로 registration
3. 2에서 구한 registered Thermal와 원본 RGB를 제안하는 DIFN으로 fusion함.
2번 단계에서 deformation을 예측하는거 까진 이해하였는데, resampler를 하여 registration을 하는 과정에 대해서는 잘 이해가 안가는데 설명해주실수 있나요?
1. 네, 수도 Thermal을 만들고 registration을 위한 deformation field를 예측합니다. 그리고 registered thermal과 원본 RGB를 이용하여 Image Fusion을 수행합니다.
2. resampler는 그리드의 offset을 이동시키는 과정이며 STN이후부터 많이 사용되고있으며 파이토치 함수로도 구현되어있습니다. https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html