이번에 소개드릴 논문은 이번 CVPR2022 oral paper 중 하나인 Shunted ~~ 입니다. 해당 방법론은 transformer backbone과 관련된 논문이며 튜토리얼 발표 때도 다뤘었습니다.
Intro
일반적으로 Transformer backbone 논문을 보면 인트로 내용들이 다들 비슷비슷합니다. 컨볼루션 뉴럴 네트워크(CNN)는 정해진 kernel size만큼의 영역만을 연산하기 때문에 locality 등을 잘 보지만 receptive field가 제한적이라 global context를 포착하지 못하며 반면에 ViT 방법론은 Self-Attention 연산을 통해 global receptive field를 가지고 있다 등의 내용을 말이죠. 덤으로 이러한 ViT의 단점으로는 Self-Attention 연산 자체가 너무 연산량이 많이 들어가기 때문에 고해상도 이미지를 활용하는 down stream task에서는 적용하기 어렵다는 점도 있고요.
이러한 뻔한 얘기들과 더불어 해당 논문에서는 트랜스포머의 한가지 흥미로운 단점을 제시합니다. 바로 하나의 transformer block(내부의 attention layer)에서 연산에 사용되는 token들은 모두 유사한 receptive field를 가진다는 점을 말이죠.
물론 Pyramid Vision Transformer 또는 Swin Transformer와 같이 Encoder의 stage별로 feature map의 해상도가 2배씩 줄어드는 계층적 구조를 채택하고 있어 영상 속 다양한 물체의 요소들을 잘 포착하고 표현할 수 있게 됐지만, 저자는 이러한 인코더 스테이지가 아닌 하나의 스테이지 내부에 단일 attention layer 하나하나 내에서는 token들이 single scale이라는 점이 문제라고 지적합니다.
즉 attention 연산을 수행할 때 multi-scale의 token들을 통해 attention 연산을 수행하면 보다 더 효율적이고 scale 변화에 강인한 학습이 가능하지 않겠냐는 것이죠.

PVT는 제가 예전에 리뷰로도 작성한 [ICCV2021]Pyramid Vision Transformer라는 논문으로 간략하게 특징을 소개드리자면 Attention layer에서 Q와 K, V로 attention 연산을 수행할 때 K와 V를 해당 논문에서 제안하는 Spatial Reduction module을 통해 큰 폭으로 차원을 줄여 연산량을 획기적으로 줄인 것을 의미합니다.
하지만 이번 CVPR2022 논문의 저자는 PVT가 SR module을 통해 연산량을 크게 줄인 것은 맞지만 token을 너무 많이 aggregation하는 바람에 Sofa와 같은 큰 물체들을 위주로만 feature map 활성화된다고 주장합니다.(그림1의 정성적 결과는 feature map이 밝은 것이 좋은게 아니라 물체가 선명하게 보이는 것이 더 좋다 라고 합니다.)
하지만 제안하는 방법론은 Sofa와 같은 큰 물체 뿐만 아니라 방석, 액자 등의 중간급 물체부터 천장에 등 같은 작은 물체까지 잘 활성화가 된 것을 확인하실 수 있습니다.
Overall Framework
그럼 바로 방법론에 대해서 알아보도록 하겠습니다.
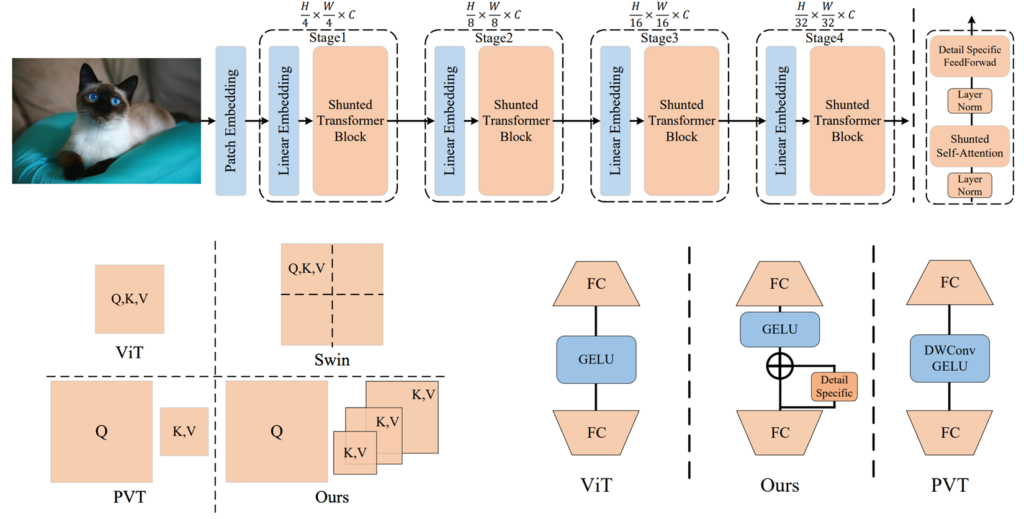
일단 전체적인 구조는 그림2 제일 위에 그림에서 확인하실 수 있습니다. 최근의 대부분의 backbone들이 모두 4stage 형식을 유지하고 있으며 각각의 인코더 스테이지를 통과할 때마다 2배 다운샘플링 되는 것을 확인하실 수 있습니다.
긜고 Shutned Trnasformer Block 내부는 제일 우측상단에서 확인 가능하시며 LN – Shunted Self-Attention – LN – Detail Specific FeedForward network로 이루어져있습니다.
그럼 해당 논문의 contribution들인 Shunted Transformer Block과 Detail Specific FFN을 살펴보도록 하겠습니다.
Shunted Self-Attention
먼저 Shunted Self-Attention의 가장 큰 핵심은 동일한(Intra) Attention layer에서 각 토큰들이 multi-scale로 이루어져 다양한 scale에 대해 self-attention을 수행하도록 하는 것이 핵심입니다.
실제로 그림2 좌측 하단에는 ViT, Swin, PVT 그리고 제안하는 방법론의 token 크기에 대하여 비교한 내용이 있는데, 여기서 Swin Transformer의 경우에는 일정한 Window 내에서만 self-attention 연산을 수행하는 local self-attention을 수행하고 있으며, PVT는 ViT처럼 Global self-attention을 수행하는 것은 맞으나, K와 V의 크기를 SR module로 크게 줄이게 도비니다.
Shunted 방법론의 경우 Swin처럼 local한 attention 대신 PVT처럼 global attention을 하는 방법을 수행하고자 PVT를 baseline으로 설정하였다고 합니다. 즉 K와 V에게 SR module을 적용하는 것을 베이스로 깔고 가며 그 다음에 논문에서 제안하는 multi-scale token aggregation layer를 통하여 K와 V의 크기를 multi-scale로 표현하게 됩니다.
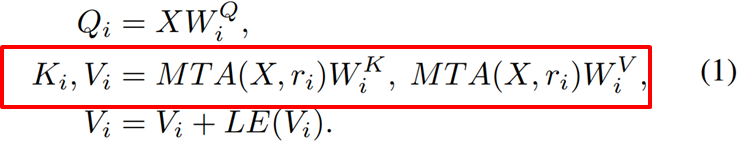
수식적으로 보면 위의 수식1처럼 나타낼 수 있는데, 이때 붉은색 박스가 바로 token을 multi-scale로 aggregation하는 것을 의미합니다. X라는 토큰에 대해 바로 Key weight와 Value weight를 곱해서 K, V token을 생성하는 것이 아닌 한번 MAT(수식에서는 MTA라고 적혀있는데 오타입니다.) 연산을 통해 다양한 scale로 변환 후 Key와 Value로 투영시키게 되는 것입니다.
MAT는 매우 단순하게 구현될 수 있는데 MAT(X, r)에 대하여 X는 입력 token을, r은 down sampling정도를 의미한다고 합니다. 즉 r x r kernel size에 stride도 r 값인 컨볼루션 연산을 한번 수행하게 되는데, 이를 통해 K와 V가 down sampling이 진행될 것입니다.
만약 r값이 커지게 되면 K와 V가 더 많이 합쳐지기 때문에 상대적으로 PVT가 그랬던 것 처럼 큰 물체를 포착할 가능성이 높아지며 K와 V의 차원이 줄어들어 연산량도 더욱 크게 줄어들게 됩니다.
반면 r 값이 작게 설정된다면 연산량은 비록 늘어나긴 하겠지만 middle, small object를 조금 더 잘 포착할 수 있게 될 것입니다. 이러듯 r 값을 다양하게 설정함으로써 하나의 attention layer 내에서 다양한 receptive field를 가지고 attention 연산을 수행할 수 있게 될 것입니다.
Detail-specific Feedforward Layers
바로 다음 contribution인 Detail-specific FFL로 넘어가도록 하겠습니다. 사실 해당 부분은 제가 개인적으로 생각했을 때 크리 큰 기여도가 있다고 판단되지는 않으며 작은 기여도를 만들고자 추가한 것 같습니다.
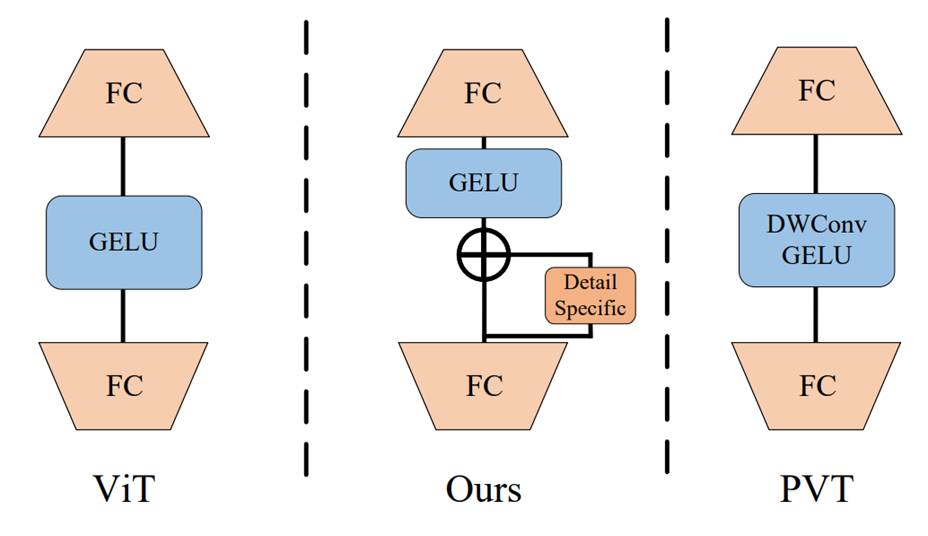
그림3을 보면 ViT, PVT 그리고 Shunted 방법론에 대한 FFL를 비교한 그림입니다. ViT의 경우 단순히 FC – GeLU – FC 라는 단조로운 구조를 이루고 있습니다. 반면 PVT의 경우 중간에 Depth-Wise Convolution이 끼어있는 것을 볼 수 있는데, 최근 2022년도 transformer 논문들을 살펴보면 Depth-Wise Convolution이 채널축이 아닌 spatial 축에 대해서만 convolution 연산을 수행하다보니 이것이 일종의 Self-attention 역할을 수행한다? 라는 관점으로 많이들 사용하고 있습니다.
그래서 제안하는 방법도 역시나 Depth-wise convolution을 사용하고는 싶은데 그저 FC 레이어 중간에 끼어넣으면 PVT랑 크게 다른 바가 없기 때문에 이렇게 Detail-Specific이라는 모듈까지 붙여나가며 Residual 형식으로 연산을 수행하는 것을 볼 수 있습니다.
즉 Detail-Specific 모듈은 DW conv로 구현할 수 있으며 이렇게 DW conv에서 나온 feature map을 그렇지 않은 feature map에 residual 연산을 수행해줌으로써 feature map의 detail을 더 보강해주었다고 주장합니다.
Experiments
그럼 바로 실험결과에 대해서 살펴보도록 하시죠. 데이터셋은 크게 ImageNet-1K와 COCO detection dataset을 활용합니다.
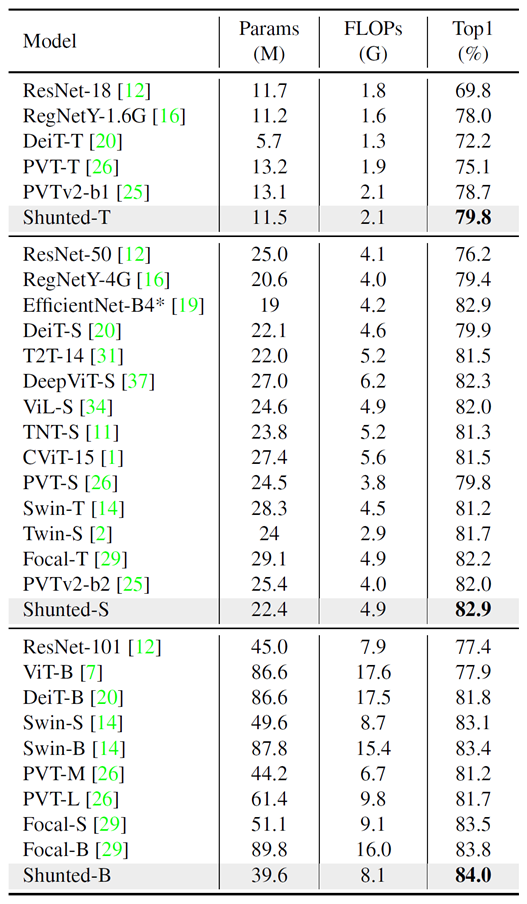
위의 표는 ImageNet-1K에 대한 정량적 결과를 의미합니다. Shunted backbone은 크게 Tiny, Small, Base로 3가지 존재하는데 놀라운점은 어떤 사이즈 백본이든 상관없이 타 방법론들의 비슷한 이름의 모델과 비교하면 모델의 파라미터 수도 매우 가벼우며 그의 비해 성능은 매우 높은 것을 확인하실 수 있습니다.
특히나 PVT를 baseline으로 잡았으니 PVT와 직접적ㅇ니 비교를 해보자면, PVT의 경우 모델의 경량화에 초점을 두었기에 성능 측면에서는 조금 부족한 부분을 볼 수 있는데, Shunted 방법론의 경우 경량화는 물론 성능이라는 2마리 토끼까지 모두 잡은 논문입니다.
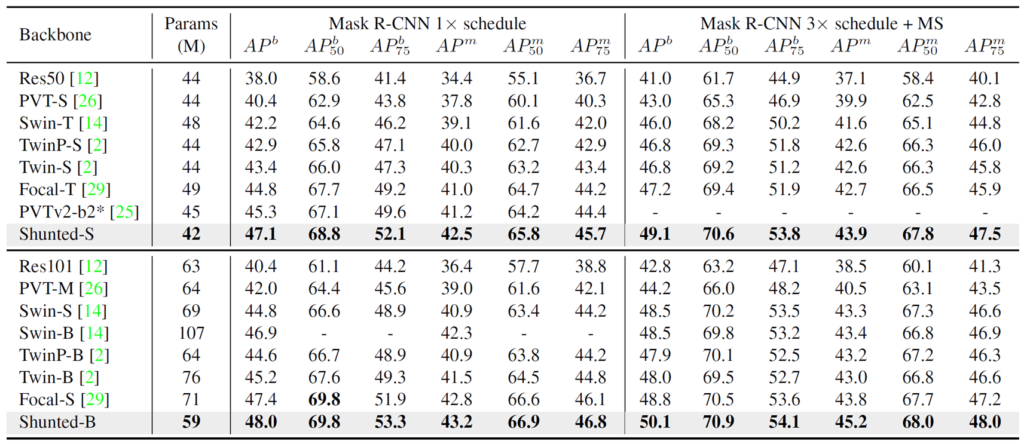
위의 표는 COCO datset에 대한 결과입니다. Mask RCNN을 베이스 방법으로 두고 backbone만을 다양한 방법론들과 비교한 결과인데 Mask에 대한 결과나 bounding box에 대한 결과 어느것을 비교하더라도 모두 SoTA임을 확인하실 수 있습니다.(성능적인 측면 + 속도적인 측면)
결론
해당 논문의 아이디어는 읽어봤을 때 이해하는데 어려움이 없고 어찌보면 단순하다고 생각할지도 모르겠지만 성능과 속도 측면에서 모두 좋은 결과를 보여주었기에 CVPR은 물론 oral 페이퍼로 결정된 것이 아닐까 생각이 듭니다.
좋은 리뷰 감사합니다. PVT에서 K와 V의 크기를 줄일 때 SR module을 사용했다고 하셨는데 여기서 SR module이 어떻게 작동해서 크기를 줄이는 건가요? Convolution이나 Pooling과 비슷하게 작동하는 건가요?
토큰은 일종의 임베딩 벡터로 볼 수 있어서 key와 value token은 HW x c로 구성된 2D 행렬이라고 보면 됩니다. 이때 SR module은 이러한 key와 value token이 들어가서 token의 shape을 HW/R^2 x cR^2로 reshape한 다음 fc layer를 통해 cR^2을 c로 다시 내리게 됩니다. 즉 SR 모듈을 타고 나온 최종 output은 HW/R^2 x c가 되는 것이고 이는 R^2만큼 토큰들의 크기가 줄었다는 의미죠.