이번에 리뷰할 논문은 아래와 같이 Paper with codes, Monocular depth estimation 부문에서 일등을 기록하고 있는 Binsformer입니다.
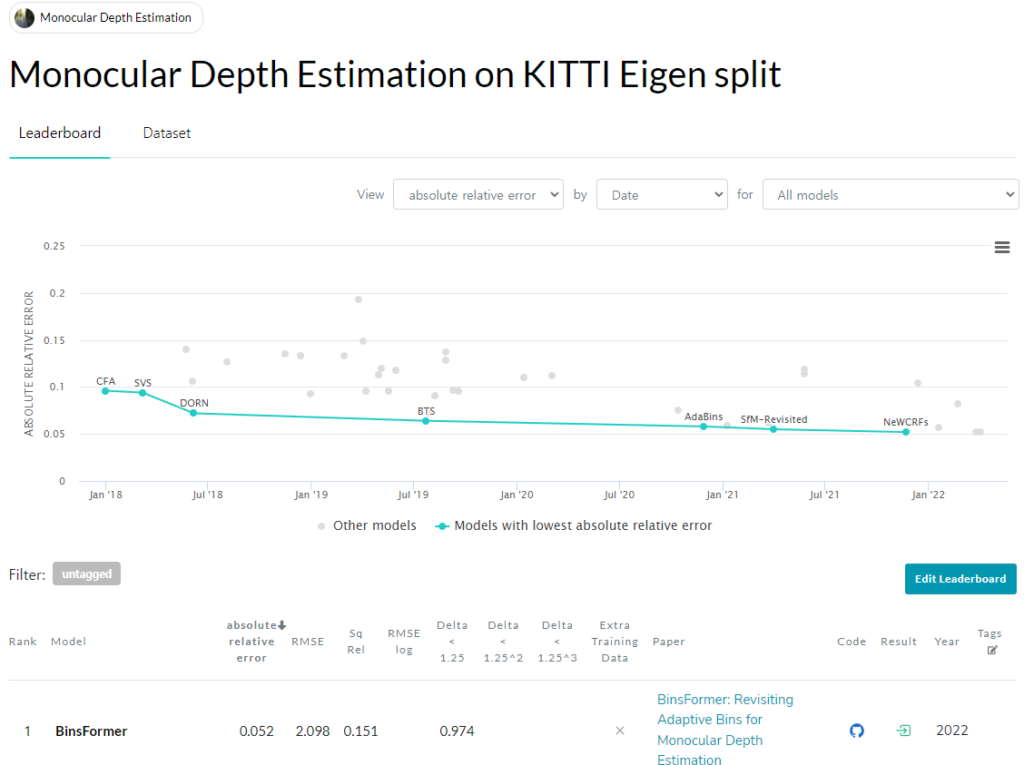
이 논문 외에도 이 동일저자가 낸 Depthformer라는 논문 또한 abs_rel 동일 성능을 보이며 공동 일등을 기록했습니다.
이 논문의 저자가 transformer를 이용해서 Supervised depth estimation하는 논문을 찍어내며 성능을 올리고 있는 상황인데 부러우면서 멋있는 것 같습니다. 또한 Monocular-Depth-Estimation-Toolbox 를 github에 공개하며 mmsegmentation과 같이 monocular depth estimation 도 간편한 라이브러리로 사용할 수 있게 해줍니다. 이 라이브러리 속에는 Adabin, BTS, SimIPU, DPT, Depthformer등 현재 가장 좋은 성능을 보이는 방법론들이 포함되어 있으니 다양한 실험을 할 때 사용하기 괜찮아 보입니다.
- Introduction
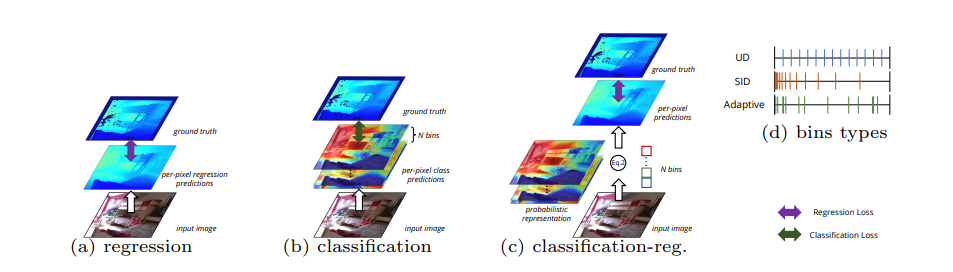
저번 Adabins 리뷰에서 설명할때 쓰인 위 그림은 사실 Adabin 논문에서 따온게 아닌 이 논문에서 가져온 것입니다. 그 리뷰에서 설명했다시피 현재 Supervised depth estimation에서 Loss 및 depth 표현 방식은 위 그림 속과 같이 총 세가지로 나눌 수 있습니다.
매우 많은 논문(DPT, DAV, TransDepth, NeWCRFs)에서 사용되는 Regression, regression의 slow convergence( 무슨 문제인지는 DORN을 읽어봐야 알 것 같음) 과 낮은 성능을 해결하기 위해 제안된 Classification 방식, classification의 discontinuties한 문제를 해결하기 위해 제안된 Adabin, DDV 가 있습니다.
그렇지만 이러한 Adabin일지라도 여전히 문제가 남아 있다고 합니다. 총 두가지 문제가 있는데 다음과 같습니다.
- decoder 의 output에서 나온 feature를 이용해 bin을 예측하니 global informatin과 전체 scence을 알아차리기 어렵다고 합니다.
- Transformer 블록을 사용하는 동안 인코더-디코더의 제한된 receptive fields는 글로벌 정보의 불가피한 손실로 이어집니다.
- bin 및 probabilistic representations은 동일한 단일 레이어을 기반으로 예측되며, 이는 상호 작용이 부족해져서 전역 정보 및 세분화된 정보에 흠이 있게 됩니다.
- loss로 사용된 Chamfer loss가 학습을 방해해서 성능 향상을 막습니다.

그림 2는 adabin아키택쳐인데 보시다시피 하나의 mvit를 이용해서 bin centers와 probability를 예측하는데 이게 문제라고 하는 겁니다.
위 문제들을 해결하기 위해서 이 논문에서는 Binsformer를 제안합니다. 이 Binsformer는 bin center 와 probability를 예측하기 위해서 두개를 분리시켰습니다. 분리를 통해서 fene-graiend 한 depth estimation이 가능해지게 했으며, 추가적으로 scene을 정보를 transformer가 학습하도록 해서 더욱 정확한 depth bin을 예측하도록 했습니다. 그럼 방법론에 대해서 더욱 자세하게 다뤄보겠습니다
2. Method
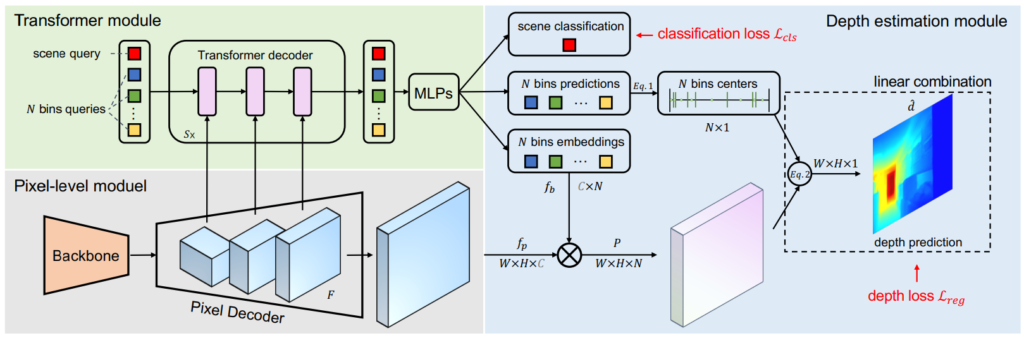
아키택쳐는 두가지로 나눠집니다. 하나는 U-Net 기반의 CNN 아키택쳐를 통해서 probability를 예측하는 pixel-level module과 다른 하나는 0으로 초기화된 N bin centers와 scene query 정보를 입력으로 해서 각각을 예측하는 Transformer module로 나뉘어져있습니다.
CNN과 Transformer를 이렇게 두가지 방식으로 나눠서 학습하므로써 local과 global 전부 챙길 수 있다고 합니다.
2.1 BinsFormer
Per-pixel module
Depth 를 생성하는 모델은 기존에 단순히 CNN을 Transformer로 변경해서 사용하는 모델과는 다르게 두개의 branch로 진행됩니다.
Transformer module
ViT에서 제안된 cross attention과 self-attention 방식을 그대로 사용하며, DETR 에서 제안된것과 동이랗게 입력과 동일한 output을 보일 수 있는 구조를 설계했다고 합니다.
Depth prediction module
예측된 bin 값을 실제 depth bin으로 변화하는 과정 또한 아래와 같이 Adabin에서 제안된것과 동일하게 변환합니다.
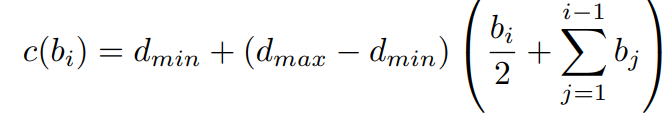
이때 dmin과 dmax는 데이터 셋에 따라서 static 한 값으로 설정하며 아래 식으로 실제 depth로 변환되며 pi는 그림 4와 같이 Nbins embedding 과 곱해져서 만들어진 probability distribution입니다.
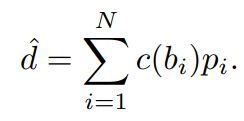
그리고 Loss 계산시에 실제 depth와 SIlog 계산을 통해 regression loss을 얻습니다 .
Auxiliary scene classification
장면의 구분을 통해서 Adabin이 말한 장면마다 depth distribution이 다르다는 것을 학습합니다.
Multi-scale prediction refinement
Transformer를 multi scale로 계산해서 더욱 정확한 깊이 정보를 추정합니다.
3. Experiments
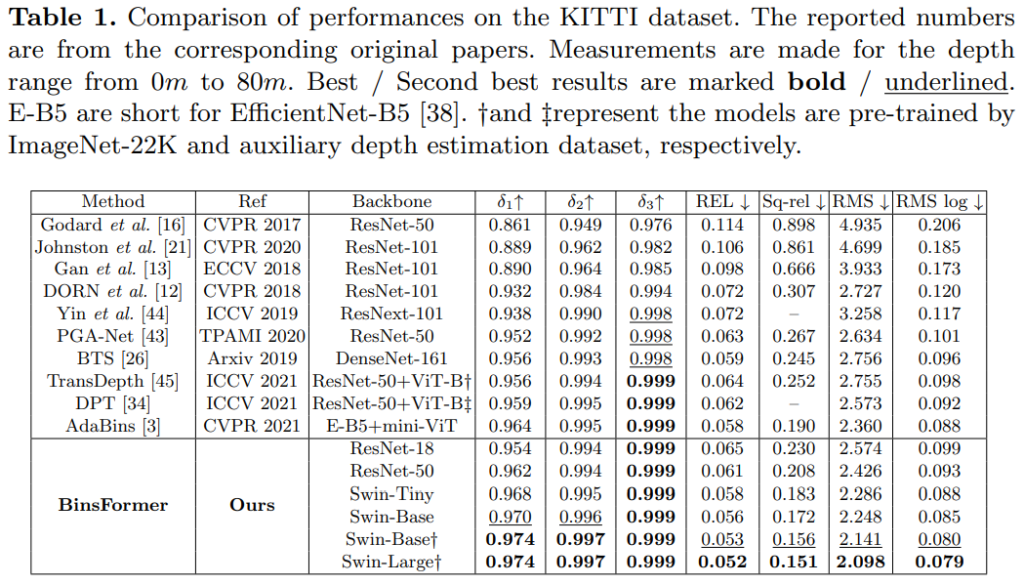
backbone을 다양하게 변경하며 실험했을 떄 Swin-L이 가장 좋은 성능을 보이며 SOTA성능을 보여줍니다. 그렇지만 Swin -L과 E-B5랑 비교하는게 맞는지는 모르겠습니다.
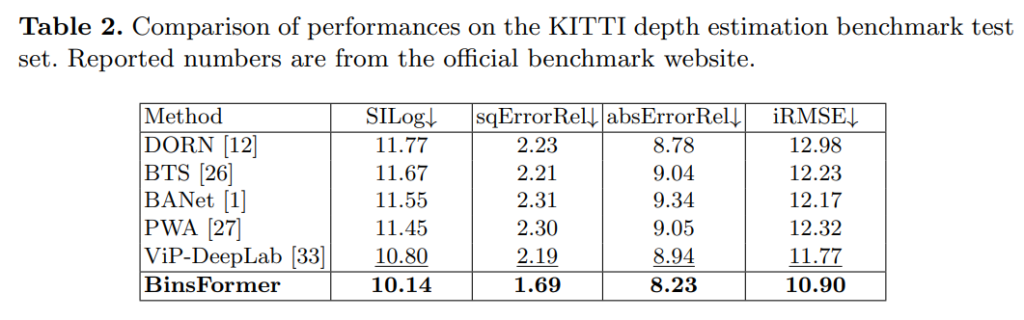
이건 KITTI 온라인 평가 인데 이 비교군에 Adabin이 없는게 살짝 아쉽네요
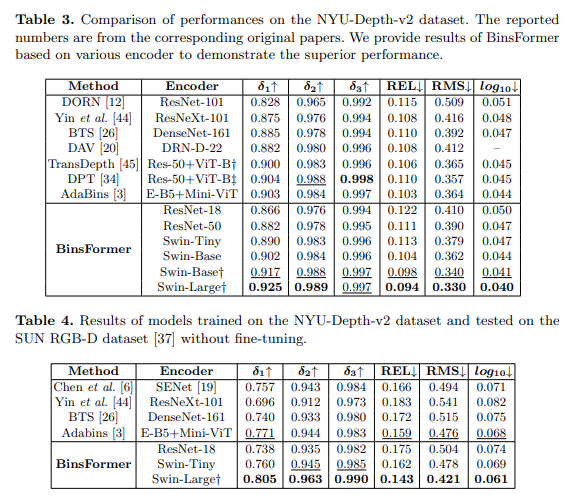
실내에서 또한 좋은 성ㄴ능을 보이지만 여기서도 Swin-T나 ResNet50 이 좋지 못한 성능을 보여주는 것 같아 …음 생각보다 괜찮아 보이지는 않는 것 같습니다.
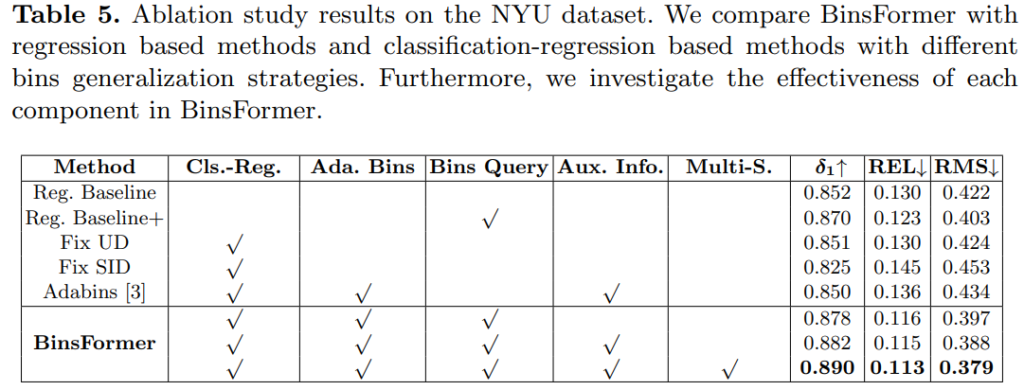
Ablation study 입니다. Adabin 성능이 왤케 않좋게 나온지 모르겠습니다
이렇게 비교해보니…. Adabin이 더 참신하고 괜찮아 보이네요 허허
해당 논문은 AdaBins 저자가 후속 연구로 진행한 것인가요?
아니면 다른 사람이 AdaBins를 분석해서 이를 해결하는 논문을 작성한건가요