

오늘 소개드릴 논문은 Facebook에서 나온 “VRAG: Region Attention Graphs for Content-Based Video Retrieval”라는 논문으로, CBVR (Content-Based Video Retrieval), 즉, 제가 연구하고 있는 Video-to-video Retrieval 분야에서 간만에 나온 논문입니다. 형식으로 보았을 때, 아마 8월말 AAAI에 투고할 예정인 듯한 것으로 보이며, 일부 오타나 문법오류가 있는 것으로 보아 계속 작업 중인 것으로 예상 됩니다.
해당 논문은 학습 시에는 Video-level feature를 Attention Graph를 통해 embedding 시키고, 평가 시에는 Video-level feature 혹은 Shot-level feature를 사용하는 방법론입니다. 자세한 내용은 아래에서 설명드리도록 하겠습니다.
1. Method
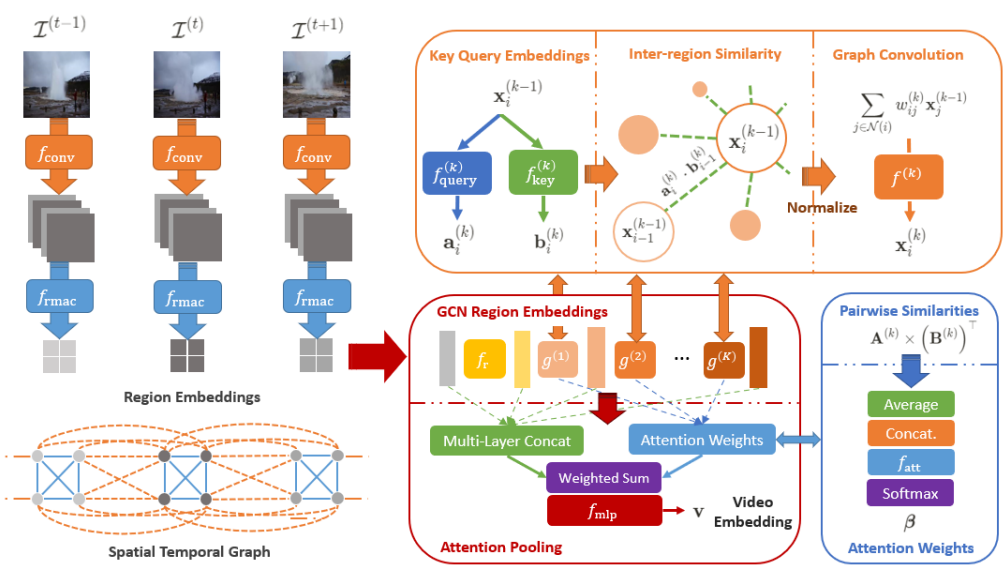
VRAG의 전체 프레임워크는 먼저, ViSiL과 비슷하게 frame-level feature를 기술합니다. 그 후, Attention Graph를 통해 여러 representation을 생성하고, 이들을 모아 video-level feature로 기술합니다. 기술된 video-level feature로 학습하며, 평가 시에는 이렇게 학습된 모델로부터 shot 단위의 feature를 추출하여 비디오 간의 유사도를 계산합니다.
1.1 Input Frame Representation
한 비디오가 있을 때, ViSiL에서와 유사하게 R-MAC을 활용합니다. 비디오의 매 프레임마다 ResNet50을 통과시키며, 중간 단계의 L 개의 layer에서 region-level의 activation map을 추출 및 concat하여 R-MAC feature를 생성합니다. 이는 식 (1)처럼 나타나며, 여기서 \chi^{t}는 t번째 프레임의 R-MAC feature를, T는 비디오 내 프레임 수, N은 L x T, C는 channel을 의미합니다. 실험단계에서 L은 4, C는 3840으로 쓰였다고합니다.
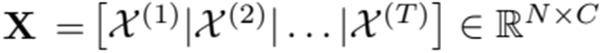
1.2 Spatial and Temporal Graph Structure
Attention Graph 연산 하기 이전, node와 edge를 설정해야합니다. 여기서 node \nu는 앞서 추출한 R-MAC feature로 설정되었으며, 이 node에 대해 edge는 spatial graph edge \varepsilon_{spatial}와 temporal graph edge \varepsilon_{temporal} 로 설정되었습니다. spatial graph edge \varepsilon_{spatial}는 한 프레임 내의 spatial 한 관계를 파악하고 self reference하기 위해 R-MAC에 concat된 중간 단계의 activation map 사이에서 구성됩니다. temporal graph edge \varepsilon_{temporal}는 temporal relation을 판단하기 위해 t번째 프레임 앞뒤에 속한 모든 activation map 사이에서 구성됩니다. (Fig 2 왼쪽 하단)
1.3 Learning Region Embeddings
앞서 구성된 Graph 구조로부터 GCN을 활용해 region-level의 embedding을 학습시킵니다. 이 때, 비디오의 모든 프레임을 사용하기 위해 먼저 FC layer f_r을 통해 차원을 축소시킵니다. (C -> C’) 그 후, 차원 축소된 feature를 입력으로 K개의 Graph Attention layer를 통과시킵니다. 자세하게, Graph Attention 과정은 차원 축소된 feature를 Linear transformation으로 query f_{query} 와 key f_{key}로 변환시키고 식 (2)와 같이 self-attention을 준 뒤 다음 단계의 Graph Attention layer로 전달 시킵니다. K번의 self-attention이 끝난 뒤, 맨 처음 차원 축소 이전 feature와 차원 축소된 feature 그리고 매 K번 마다 다음 layer로 전달되는 feature를 모두 concat하여, 총 N개의 C+(K+1)C’ 차원의 feature를 생성합니다.
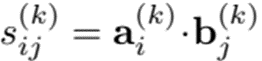
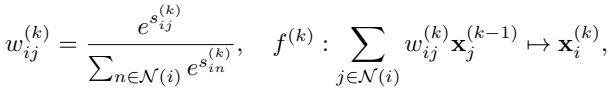
1.4 Video Embedding.
Self-attention 후 얻은 N개의 C+(K+1)C’ 차원 region embedding 을 1개의 video-level feature로 aggregate하기 위해, weighted sum 방식이 사용됩니다. 이때, 앞서 Attention Graph에서 사용된 query와 key를 식 (3)과 같이 재사용해 생성된 \mathcal{A}를 행방향으로 평균내고, linear layer 및 softmax를 통과시켜 weight가 계산됩니다. 이렇게 weight sum 된 feature는 다시 두 개의 linear layer를 거쳐 video-level feature로 변경됩니다.
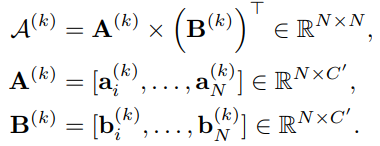
1.5 Training VRAG
ViSiL과 같이, 비디오 단위의 triplet (anchor, positive, negative)에서 각각 video-level feature를 추출하고 triplet margin loss를 통해 학습됩니다.
1.6 Shot Representations
모델을 학습시킨 뒤, 평가 과정에서 두 비디오의 유사도를 측정하기 위해 shot마다 feature를 추출합니다. Video-level feature 대신 shot-level feature가 사용되는 이유는, 평가되는 데이터 셋이 연관이 없는 content를 포함하는 untrimmed video dataset이기에 이 content들의 기여를 제거하기 위함입니다. 여기서 한 비디오의 shot은 연속된 프레임 마다의 R-MAC feature의 cosine 유사도로부터 thresholding하여 나눠집니다. 나눠진 shot 마다 1.1~1.4 절과 같이 feature를 추출하고, 두 비디오에서 생성된 모든 shot-level feature들로부터 shot similarity map을 계산합니다. 이후, shot similarity map 에서 Chamfer similarity(CS) 혹은 Symmetric chamfer similarity(SCS) 연산 하여 video-level의 유사도를 계산합니다. shot similarity map에서부터 video-level의 유사도를 계산하는 과정은 ViSiL에서 사용하는 방식과 동일하니 자세하게 알고싶으신 분들은 ViSiL 논문을 참고하시면 좋을 듯 합니다.
2. Experiments
2.1 Ablation Studies
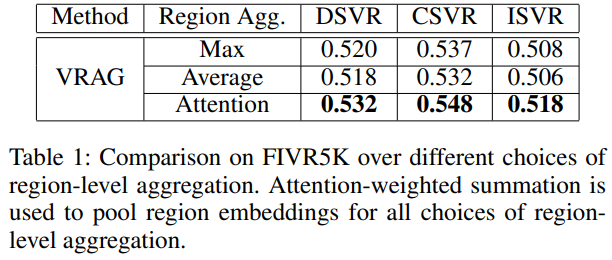
Table 1은 1.3 절에서 region embedding을 만들 때 사용하는 연산 방식에 대한 ablation study입니다. 제안된 Attention Graph 방식이 일반적인 연산 (Max, Average)보다 성능이 좋은 것을 볼 수 있습니다.
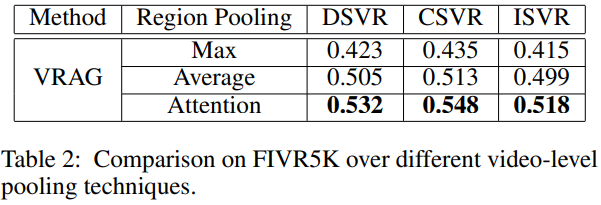
Table 2는 1.4절에서 Video-level feature를 생성할 때 사용하는 연산 방식에 대한 ablation study입니다. Table 1에 대한 ablation보다 연산 방식에 따른 성능 차이가 더 큰 것을 볼 수 있습니다.

Table 3은 1.3절에서 region embedding을 위해 self-attention 연산을 할 때, Query와 Key를 동일한 Linear layer를 통해 생성했을 때와 서로 다르게 생성했을 때의 ablation study입니다. 서로 다르게 생성했을 때 더 높은 성능을 보이며, 이는 별도의 query key를 사용했을 때 region embedding간의 관계가 더 복잡해지기에 성능이 높아지는 것이라고 합니다.

Table 4는 1.3절에서 C+(K+1)C’ 차원의 feature를 생성하기위해 concat할 때 어떤 feature를 concat할 지에 대한 ablation study 입니다. 앞서 설명드린 바와 같이 모든 feature를 concat하는 것이 가장 높은 성능을 보이며, 이는 각 feature들이 각각 구별력을 가지고 있기 때문이라고 합니다.
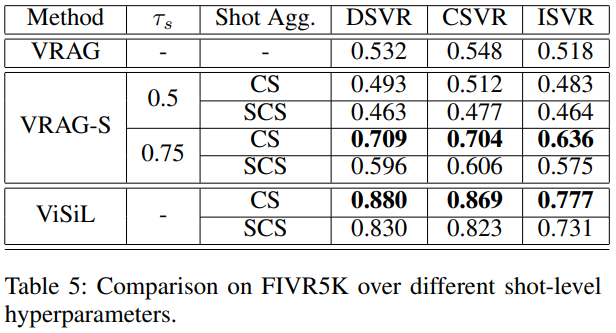
Table 5는 1.6절에서 shot을 나눌 때의 threshold 값과 aggregation하는 방식에 대한 ablation study 결과 입니다. Threshold를 높여 shot을 여러 개로 나누었을 때, frame-level feature를 사용하는 것과 좀 더 유사해져 상대적으로 높은 성능을 보이며, 이때 SCS보단 CS가 더 높은 성능을 보였습니다.
2.2 Comparison with Baseline Methods
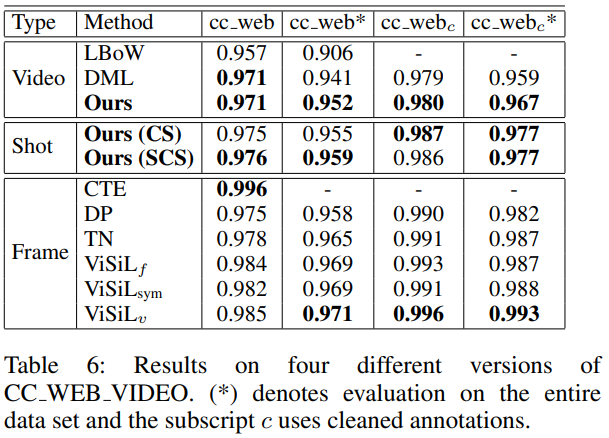
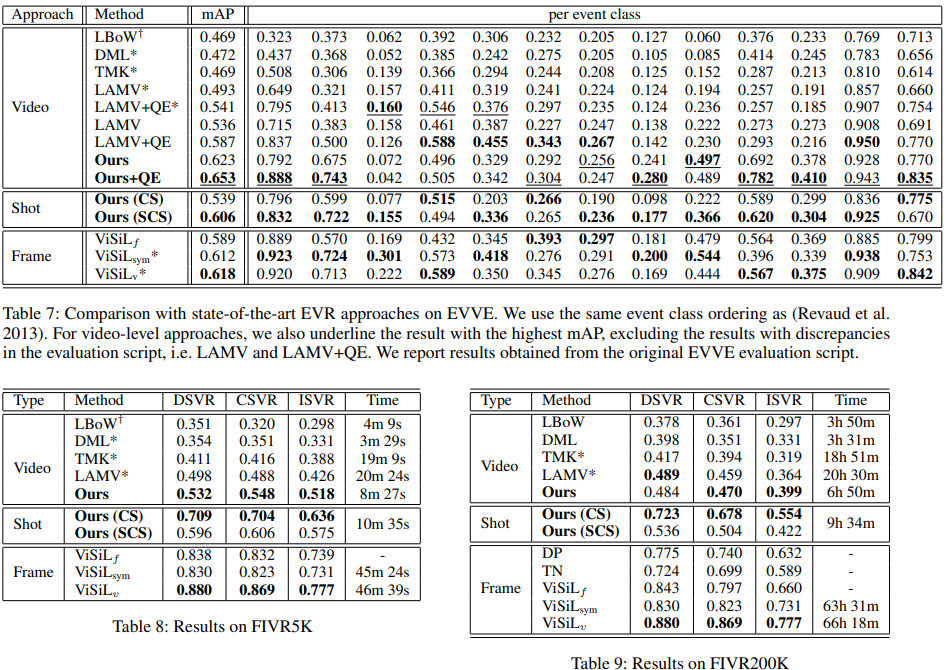
Table 6~9는 각각 CC_WEB_VIDEO, EVVE, FIVR5K, FIVR200K에서의 벤치마크입니다. 상대적으로 ViSiL보다 빠른 inference time과 video-level feature <-> frame-level feature 기반 방법들의 성능의 중간 정도 성능을 장점으로 소개하고 있습니다. 한가지 아쉬운 점은 비슷한 장점을 소개한 TCA가 빠져있다는 점이며, 아마 수정 중인 논문이기에 추후 추가되지 않을까 싶습니다.
3. Reference
[1] https://arxiv.org/pdf/2205.09068.pdf
평가할 때만 shot level feature를 사용하고, 학습할 때는 video level feature를 쓰는 이유는 학습 데이터셋이 VCDB라서 그런건가요? 그리고 속도 측정하는 부분도 DnS에서 측정한 속도 기타 방법론들이랑 차이가 꽤 있어 보여서 이 부분도 본 논문 나올때 눈여겨 봐야할 듯 하네요.
리뷰 감사합니다.
1. 그래프 기반 방법론에서 edge는 정확히 어떻게 모델링을 하는 것인가요? 개념이 조금 헷갈려서 질문 드립니다.
2. 지금 정도의 contribution이라면 AAAI에 억셉 될 수 있다고 보시나요? 개인적인 견해가 궁금합니다.