안녕하세요 제가 이번에 가지고 온 논문은 6DoF Pose estimation 데이터셋 논문으로 NVIDIA에서 발표한 논문입니다.


먼저 데이터셋은 위와같은 이미지들이 있으며, 인도어 상황에서 household object들을 담고 있습니다.
일단 해당 데이터셋이 가장 의미있는 것은 바로 연구자들의 접근성에 있다고 생각합니다. 접근성이 다른 벤치마킹 데이터셋에 비하여 더 좋다는 것을 설명드리기 위해 먼저, BOP 챌린지에 대하여 이야기 해보겠습니다.
6DoF Pose Estimation에서 가장 큰 세계대회인 BOP 챌린지에서는 12개의 데이터셋을 벤치마킹하여 해당 벤치마킹 데이터셋에서의 평균스코어를 기반으로 모델을 평가합니다. 그리고 그 12개의 데이터셋 중에서 현재 리뷰하고 있는 논문인 HOPE데이터셋을 제외하고는 모두 접근성이 안좋다고 논문의 저자는 이야기합니다.
그 이유는 바로 HOPE데이터셋에서는 모두 주변에서 구하기 쉬운 물품들로만 구성하였기 때문입니다. 저자가 말하기로는 간단히 국내/해외 배송을 시키면 쉽게 얻을 수 있는 물건들로 데이터셋을 구성하였다고 합니다. 그러면서도 robotic grasping task에 적절하게 물체의 사이즈, 촬영환경을 다양하게 하였습니다.
예를들어… light condition도 scene마다 약 5가지 정도로 세분화 하였고, occlusion, truncation, clutter, 28개의 objects 등 challenging한 요소를 포함하였습니다. 또한 annotation도 몇 mm단위의 오차만을 가질 정도로 정교하게 하였다고 합니다.
데이터셋 측면에서의 contribution과 별개로 해당 저자는 새로운 metric을 제안합니다. 이는 뒤에서 설명해드리겠습니다.

피규어 1은 28개의 toy grocery로 구성된 데이터셋의 모습입니다. 피규어 2는 synthetic rendering된 3D textured object 모델의 모습입니다. 해당 논문에서는 3D scanner를 이용하여 물체를 scan 하였고, 이를 GT object mesh file로 제공합니다. 그리고 해당 3D 파일을 이용하여 Fig. 2처럼 synthetic dataset을 만들 수 있습니다.

해당 논문에서는 위와같이 다양한 환경에서 다양한 상황을 모사하여 촬영을 진행하였습니다. 논문에서도 이러한 내용을 설명하는데 구성이 깔끔하고 이해하기 쉽게 작성되어있으니 좀 더 디테일한 내용은 참고를 하시면 될거 같습니다. 하지만, 사실 위의 피규어만 봐도 직관적으로 이해하실 수 있습니다. (위의 피규어만 보고도 알 수 있는 내용을 장황하게 설명한 느낌). 예를들어, 실제 다른 데이터셋들에서의 setup과 동일하게 robotic grasping task과 RGB-D depth sensor의 sensing거리를 고려하여 0.5~1m 정도거리에서 촬영하였다, 조명변화를 준 방법 등등..

조명변화의 예시는 위와 같습니다. 한개의 scene마다 평균적으로 4.8개의 조명변화를 주었다고 합니다. 개인적으로 infrared 이미지가 없는게 아쉽네요.
라벨링방법
라벨링하는 방법으로는 1) 텍스쳐정보가 포함된 3D CAD Model을 2D로 Projection 시킨다음 corresponding하는 포인트를 기반으로 PnP& RANSAC을 이용하여 alignment를 맞추는 방법; 2) 2.5D Depth map과 3D CAD model의 alignment를 맞추는 방법 2가지가 존재합니다. 저자는 대부분 2) 방법으로 라벨링을 하였으며, 각기의 방법에는 장단점이 존재합니다. 저자가 말하기로는 1)의 방법은 error-prone이란 단점이 존재하고, 2)는 faster하지만 노이즈나 depth값에 영향을 많이 받는다고 합니다. 그래서 2)방법으로 annotation을 한 뒤에 SimTrack으로 refinement를 하고, 필요한 부분은 manual하게 미세조정 하였다고 합니다. 흠… 개인적으로 느끼기에 논문만 보고는 SimTrack이 뭔지 모르겠고, 2) 방법론에서 alignment를 맞춘 방법이 뭔지 모르겠는데 논문에서 생략된 내용이라고 생각합니다. (읽다가 놓친줄 알고double-check 해본결과)
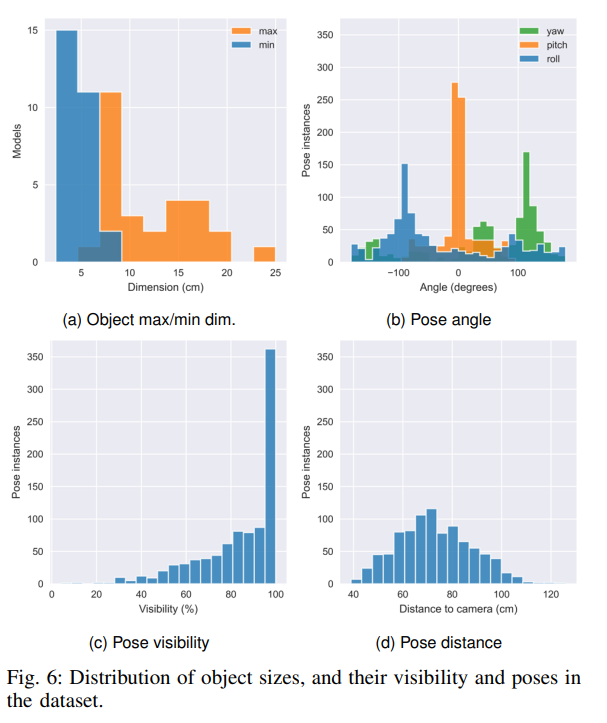
위에는 데이터의 특성에 대한 분석입니다. pose distance가 1m 넘는게 거의 없는거 같은데 일반적으로 0.5~1m 사이쯤에서 촬영을 한다고 하네요. 가동원전 데이터셋 찍을 때 참고해야겠습니다. visibility도 다양하게 설정하여 occlusion label을 별도로 제공합니다. object scale의 max/min 값과 angle의 distribution은 참고정도만 하시면 될거 같습니다.
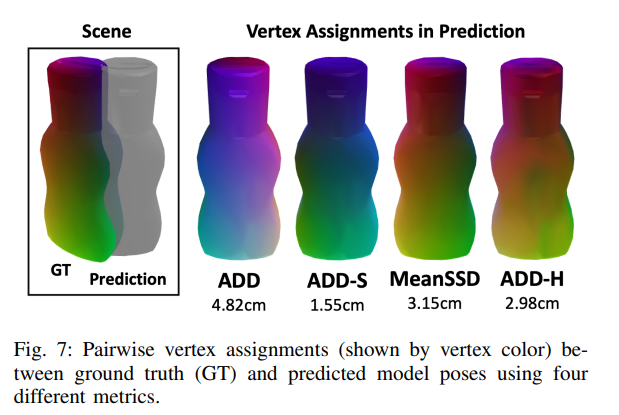
다음으로는 논문에서 제안하는 평가매트릭인 ADD-H에 대한 설명입니다. 위의 그림이 나타내는 것은 GT와 Prediction 값이 있을때, 서로 매칭되는 꼭짓점값을 할당하는 방식에 따른 차이입니다. 위의 그림을 이해하기 전에 우선 기존 평가매트릭들의 단점과 제안하는 평가매트릭에 대해서 이야기 해보겠습니다.
기존에 6DoF Pose Estimation에서는 ADD나 ADD-S를 사용하는게 보편적이었습니다. MeanSSD도 사용하였다고 하는데 (저는 사실 이번에 처음 들어보았습니다.) 아무튼 본 논문에서는 기존 평가매트릭들의 단점들을 아래와 같이 이야기합니다.
우선, ADD같은 경우에는 대칭적인 요소를 고려하지 않고 매칭쌍을 할당하기 때문에 대칭인 물체를 다루는데는 한계가 있습니다. 왜냐하면, ADD같은 경우에는 물체의 pose를 정확하게 맞추어도 대칭인 물체의 경우 pose가 다르다고 예측할 수 있기 때문입니다.
이러한 ADD의 단점을 극복하기 위해서 대부분 기존 논문들은 ADD-S를 사용합니다. ADD-S 에서는 대칭요소를 고려하여 연산합니다. 구체적으로 ADD-S에서는 일반적 상황과 어느 한 쪽 물체를 대칭축을 기준으로 뒤집었을때의 ADD를 측정하여 두 개의 ADD중에서 더 작은 값만을 사용합니다. (ADD 매트릭에 대한 설명은 여러차례 했었기 때문에 넘어가겠습니다.) 하지만, ADD-S는 비현실적으로 꼭짓점의 matching pair를 설정하기 때문에 여전히 한계가 있습니다. 이러한 문제점을 극복하기 위해 사용하는 방법이 Mean-SSD입니다.
Mean-SSD에서는 ADD를 구하고, 대칭변환을 한 다음의 ADD도 구하여서 더 작은값을 사용합니다. Mean-SSD는 꼭짓점을 비현실적으로 매칭하는 연산을 제거하여 좀 더 리얼리스틱 하게 distance를 계산하는데는 성공하였지만, computation time이 높다는 단점이 존재하였습니다.
이러한 문제를 개선하기 위해 저자는 ADD-H 평가 매트릭을 제안합니다. 해당 매트릭에서는 bijective mapping 통하여 각각의 꼭짓점마다 corresponding하는 matching pair를 할당합니다. 이때 할당하는 방식에는 Hungarian algorithm 이 사용된다고 합니다. 평가매트릭 이름이 ADD-H인 이유도 해당 알고리즘의 앞글자를 따서 이기도 합니다.
어찌됐든, 기존의 꼭짓점 매칭페어를 할당하는 방식을 변경한 ADD-H 평가매트릭을 제안하였습니다. (개인적으로 좋은 아이디어라고 생각합니다.)
이제 이론적인 설명을 마치었으니, 위에 그림에 대해 다시 설명하자면, GT와 predictions간에 매칭되는 꼭짓점을 할당하는 방식에 따른 error의 차이를 직관적으로 보여주고 있습니다.
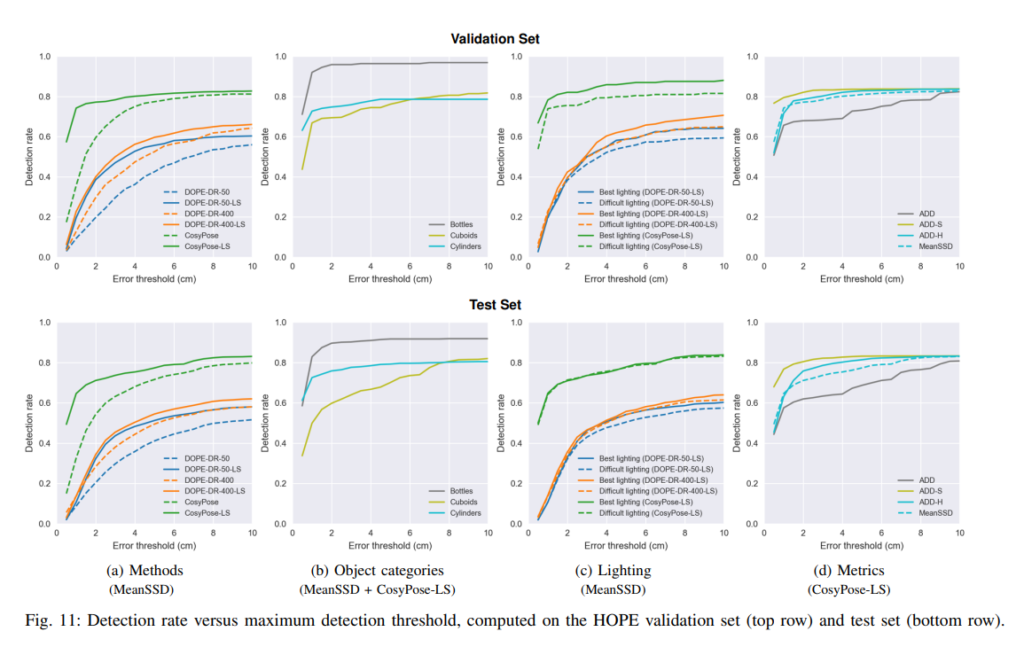
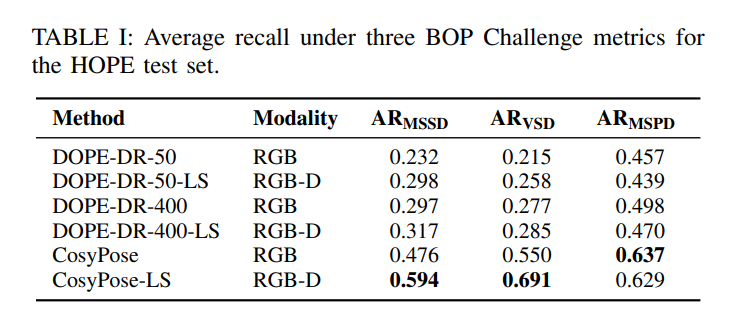
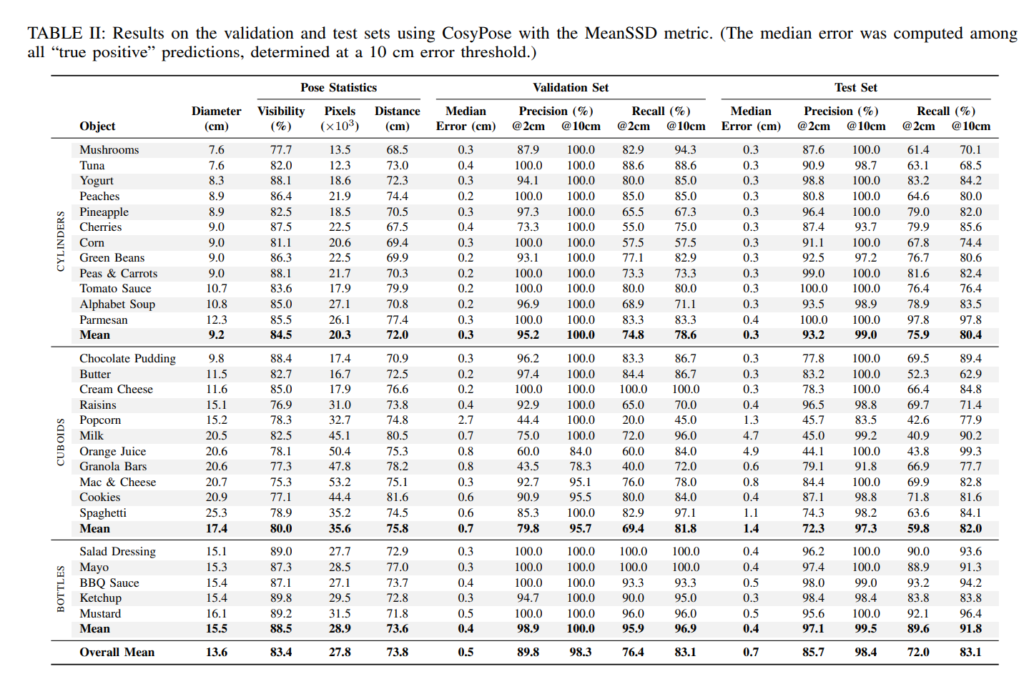
본 논문에서는 벤치마킹 방법론들(DOPE-DR, CosyPose)의 성능을 위와같이 리포팅 하기도 합니다.
다 읽고보니 labeling하는 process보다는 거의 다양한 challenging 요소들을 포함하고, easy to approach한 물체들로 구성한 dataset과 새로운 평가 metric을 제안하는게 논문의 핵심인거 같습니다.
의도는 labeling 하는 방법을 보고자 함 이었는데 새로운 평가매트릭이 좀 흥미롭네요.
이상 리뷰 마치겠습니다.
개인적으로 궁금해진게 Infrared 데이터가 있다고 하더라도 지금 조명변화가 발생하는 상황에서 각 물체마다의 구분이 명확할까요..? 같은 테이블위에 올려있는 종이박스는 온도차이도 크지 않을 것 같아서 혹시 texture 구분이 가능할지 궁금증이 생겼습니다. 혹시 과제에서 FIR 대신 NIR도 사용할 수 있나요..? 저런 상황이면 차라리 NIR이 나을것 같은데..
과제에서 딱히 제한이 있진 않은걸로 알고있습니다. 과제 이야기를 하자면, 스팀/연기/분진 등 상황에 강인한 검출기 설계이므로 FIR이 좀 더 적절하다고 생각중입니다. 근데, 스팀이나 연기의 온도가 높다면 열화상에서도 여전히 occlusion이 발생할 수 있습니다. 그러한 부분들을 고민중입니다.
좋은 논문 발표 감사합니다.
저자가 집중한 접근성이라는 의미가 크게 와닿지는 않는 것 같아요.
접근성이라는 것이 국가나, 나이, 지역에 따라 달라는 것이라고 생각합니다.
이러한 측면에서 물체 중심의 데이터 셋에서 접근성을 해결하려는 것이 쉬운 일이 아니란 생각이 드네요.
다음과 같은 생각으로부터 질문 하나 드리겠습니다.
물체 측면에서의 접근성이 꼭 필요하다고 생각하시나요?
https://www.amazon.com/gp/product/B007EA6PKS 저자가 amazon 구매링크도 제공합니다. 왼쪽 링크는 그 중 하나의 예시입니다. 모든 상품이 손쉽게 해외배송까지 가능합니다. 접근성이 꼭필요하단건 아니나, 아무래도 연구자 입장에서는 접근성이 쉬운 데이터셋을 활용하는게 편하겠죠.