

오늘 리뷰할 논문은 이전 리뷰 에서 다루었던 논문의 motivation이 되었던 논문 “Visual Semantic Role Labeling for Video Understanding” 입니다. 기존 비디오 관련 분야에서는 video action recognition, video captioning과 같이 다양한 분야들이 연구되어 왔습니다. 그러나, video action recognition의 경우, 비디오 내 짧은 구간에 존재하는 특정 행동만을 판단한다는 점, video captioning의 경우, captioning된 text 표현 범위에 제약이 없어서 체계적인 평가가 어려웠다는 점과 같은 한계들이 존재했습니다. 본 논문은 이를 넘어, 한 비디오에서 표현되는 복잡한 event를 이해하는 것을 목표로 하는 VidSRL task를 제안 하였으며, 이 task를 다루기 위해 비디오에 포함되어 있는 각 event마다 다양하지만 체계적인 label이 매겨진 데이터 셋 VidSitu도 제안하였습니다. 그리고 이 데이터 셋에서의 benchmark를 위한 베이스라인도 제안하였습니다.
1. VidSRL: The Task

비디오 내에는 여러 event가 나타나있고, 한 event는 actor와 object 그리고 location으로 구성됩니다. VidSRL은 이 요소들을 판단하고 이들 간의 관계를 이해하는 것을 목표로 합니다.
- Formal task definition
VidSRL은 비디오 V에서 event의 집합인 \{ E_i \}_{i=1}^{k} 에 대해 판단하는 것을 목표로 합니다. 여기서 한 event E_i는 사전에 정의된 동사 집합 V에 속하는 특정 하나의 동사 v_i와 value들 (entities, location, etc.)로 구성되어 있습니다. 이 때 이전 논문 “The Proposition Bank: An Annotated Corpus of Semantic Roles”를 따라, 동사를 기준으로 value들과의 관계들을(argument) 통해 event가 설명됩니다. 예를 들어, Fig 2에서처럼 특정 event에 대한 동사로 accept가 지정되었을 때, accept한 주체 (Arg0), accept 받은 객체 (Arg1), 어떤 것으로부터 accept 되었는지 (Arg2), 또 다른 속성 (Arg3)로 나뉘어 설명됩니다. 그리고 최종적으로 이렇게 설명된 각 event 간의 연관 관계 l(E, E')을 통해 한 비디오가 구성됩니다.

- Timescale of Salient Events
한 비디오에서 어디서부터 어디까지가 하나의 event인지는 사람에 따라 주관적이고 장면 전환이 없을 경우 꽤나 모호하게 됩니다. 이렇게 주관적이고 모호한 성질은 annotation 혹은 평가 시에 판단을 모호하게 하기 때문에, 본 논문에서는 고정된 길이로 event를 정의하였습니다. 하나의 atomic action, 즉, 더이상 나눌 수 없는 action이 최소 2초에 포함될 것이라 가정하고 고정된 길이로 2초를 사용하였습니다. 결과적으로 후술될 VidSitu 데이터 셋에는 10초짜리 비디오 클립 내에는 2초 단위의 5개 event로 구성되었습니다.
- Co-Referencing Entities Across Events
한 비디오 내의 event들에 포함된 entity들은 최소 하나 이상의 event에 연관되어 있습니다. 예를 들어, Fig 2에서 “woman with shield”는 event 1, 2에 속해있으며, “man with trident”는 event 2, 3에 연관되어 있습니다. VidSRL task에서는 이러한 co-referencing 또한 이해하는 것을 목표로 하며, 이상적으로는 bounding box를 통해 매 프레임마다 grounding하는 것이 co-referencing 을 평가하는 방식이지만, cost를 고려하여 여러 event에 대해 동일한 entity라고 예측하는 것으로 평가 방식이 설정되었습니다.
- Event Relations
앞서 언급했듯, 10초짜리 비디오 클립에는 5개의 event가 존재합니다. 이 event들은 한 비디오에 속한만큼 서로 연관 관계에 놓여 있으며, 해당 논문에서는 이를 4가지의 관계로 정의합니다. 먼저, 첫 번째 관계는 “Event B is caused by Event A”로 Event B가 Event A에 직접적인 결과일 때 성립됩니다. 두 번째로는 “Event B is enabled by Event A”로 Event A가 Event B에 대한 원인은 아니지만, Event A 없이 Event B가 발생하지 않을 때 성립됩니다. 세 번째로는 “Event B is a reaction to Event A”로 Event B가 Event A 에 대한 반응일때 성립됩니다. 네 번째로는 “Event B is unrelated to Event A”로 앞선 세 가지 경우에 해당하지 않을때를 의미합니다.
2. VidSitu Dataset
이번 섹션에서는 앞서 정의된 VidSRL task의 benchmark를 위해 제안된 VidSitu 데이터 셋에 대해 소개합니다.
2.1 Dataset Curation
- Video Source Selection
VidSRL task는 여러 event가 얽혀 있는 상황을 가정하고 있기 때문에, 이에 가장 적합한 영화 장르의 비디오로 데이터 셋이 구성되었습니다. 뿐만 아니라 영화 장르의 비디오는 기본적으로 여러 shot으로 변경되면서 시나리오가 구성되기에 높은 난이도로 video understanding을 평가할 수도 있는 장점도 보유하고 있으며, 이와 같은 비디오들은 Condensed-Movies라는 데이터 셋에서 취득되었다고 합니다.
- Video Selection
총 1000시간의 비디오에서 배우들이 단순히 대화를 하는 uneventful한 상황을 제외하고 10초짜리 클립 3만개에 annotation이 진행되었습니다. 3만개 클립 선정 과정에는 human detection, object detection, atomic action prediction을 필터링 과정에 활용하였다고합니다.
- Curating Verb Senses.
논문 Link 에서 정리한 약 6000개의 verb 단어 모음으로부터 시작하여, 시각적으로 특정 행동을 나타내지 않는 동사 혹은 fine-grained-level의 동사를 제거하여 총 2154개의 동사 후보군이 간추려졌습니다.
- Curating Argument Roles
앞서 정의되었듯, 매 event들은 특정 동사를 중심으로 Arg 0, Arg 1, etc. 에 해당하는 value들을 지니고 있습니다. 각 event에 대해 이를 annotation 하기 위해 Amazon Mechanical Turk (AMT)를 활용하였다고 합니다.
- Dataset splits
Annotation이 완료된 후, 80:5:15의 비율로 train, validation, test 셋으로 나뉘었으며, 한 영화로부터 추출된 비디오들은 동일한 셋에 배치되었습니다. 또한, 이 세 셋에서 총 세가지 task, Verb Prediction, Semantic Role Prediction and Co-Referencing, Event Relation Prediction로 나뉘어 모델의 성능을 평가하게 됩니다.
2.2 Dataset Analysis and Statistics

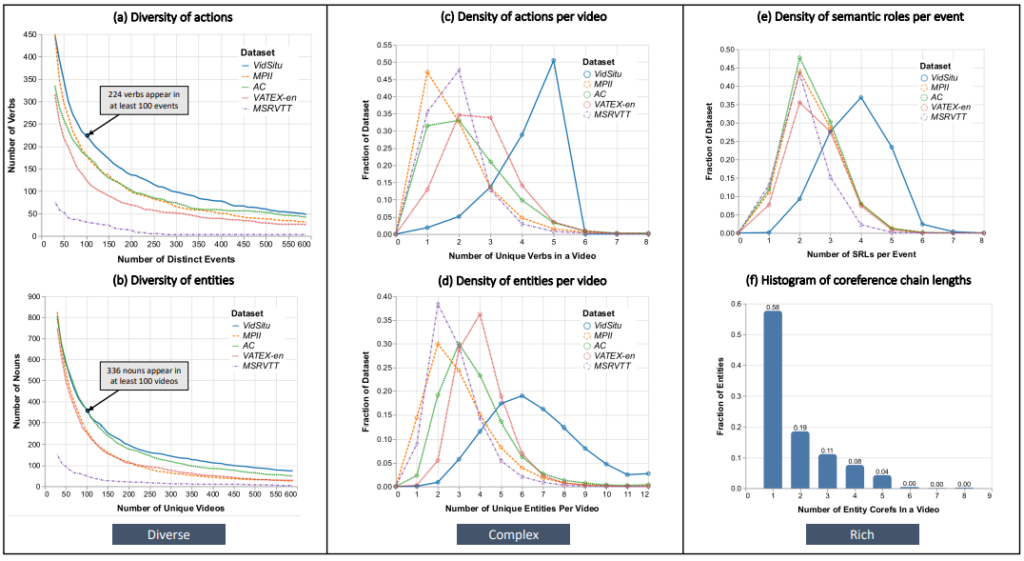
diversity of actions and entities in the dataset (a and b), the complexity of the situations measured in terms of the number of
unique verbs and entities per video (c and d) and the richness of annotations (e and f).
제안된 데이터 셋 VidSitu는 이전 보다 challenging 해진 VidSRL task를 다루기 때문에, 다양한 event와 복잡한 상황으로 구성되며, 이를 설명하는 풍부한 annotation이 존재합니다. Table 1은 기본적인 통계를 나타내며, 다른 데이터 셋과 달리 co-reference한 성질이 annotation 되어있다는 특징을 지닙니다. 또한, Fig 4는 VidSitu 데이터 셋의 세 가지 특징 (다양한 event, 복잡한 상황, 풍부한 annotation)에 대해 설명하는 구체적인 통계 수치이며, 다양한 관점에서볼 때 VidSitu가 대부분의 경우 상위에 속해 있는 경향을 보입니다.
3. Baseline
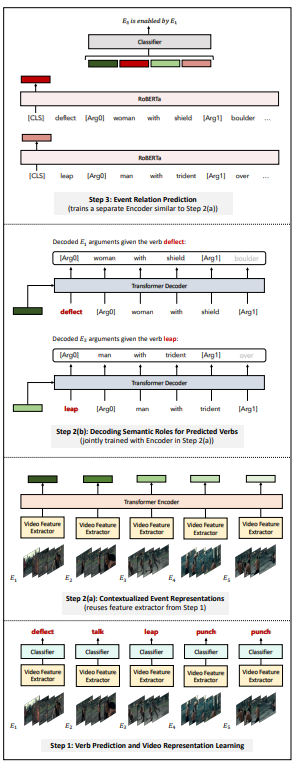
이번 섹션에서는 VidSRL task에서 정의된 세 가지 문제 Verb Prediction, Semantic Role Prediction and Co-Referencing, Event Relation Prediction를 해결하기 위한 베이스 라인에 대해 설명합니다. 이 베이스라인은 여러 모델로 구성되며, 현존하는 SOTA 알고리즘들이 활용되었습니다.
- Verb Prediction
매 2초짜리 event 마다 그 event에 해당하는 동사를 중심으로 event understanding을 시작하기 때문에, verb prediction이 우선적으로 수행됩니다. 이 때 모델은 Action recognition에서 좋은 성능을 보이고 있는 I3D와 SlowFast로 활용되며, Kinetics에서 pretrain하고, VidSitu 데이터 셋에서 finetuning되는 형식으로 학습됩니다. 이후 다른 task에서 이렇게 학습된 모델을 freeze 시킨 뒤 활용합니다.
- Argument Prediction Given Verbs
앞서 event 마다 예측된 verb를 중심으로 entity들을 예측해내야, 해당 event에서 주객체가 어떤 행동을 하고 있는지 알 수 있습니다. 때문에 Fig 3과 같이 Transformer 구조의 encoder 및 decoder로 구성된 seq-to-seq model로부터 entity들이 예측됩니다. Encoder에서는 2초 event에 대해 verb prediction 과정에서 추출된 video feature가 token으로 활용되어 event 들 간의 self-attention 연산을 취하며, decoder에서는 verb와 attention된 video feature를 입력으로 각 event 마다의 argument를 예측하게 됩니다.
- Event Relation Prediction
앞서 예측된 verb와 entity를 기준으로 각 event들이 설명되었으며, 이들을 활용하여 event들 간의 4가지 관계를 예측하고자 multimodal representation을 입력으로 두고 classification 하였습니다. 특정 두 event 별로, verb와 argument들이 RoBERTa라는 모델을 통해 language representation으로 변환되고, verb prediction 시 추출된 visual representation 들과 concat되어 두 event 사이의 relation classifier를 학습시킵니다.
4. Experiments
4.1 Verb Prediction
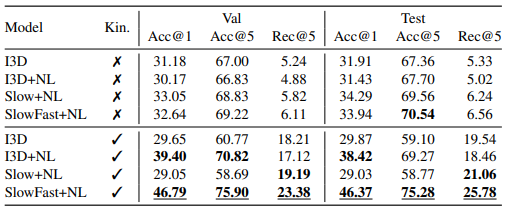
Table 2는 VidSitu 데이터 셋에서 제안된 베이스라인에 대한 benchmark입니다. Event에 대한 video feature를 추출할 때 어떤 모델을 사용하는지에 따라 성능을 리포팅 했으며, 평가지표로는 verb vocabulary에 class imbalance한 문제가 있기 때문에 Recall@k로 선택하였습니다. 이는, 개수가 많은 verb만 잘 맞추면 높은 성능이 보장되는 것을 막기 위함입니다. 또한, 이에 대한 비교용으로 Accuracy도 같이 리포팅 되었습니다. 실제로, Kinetics pretrain에서 I3D+NL의 경우 Accuracy에서는 Slow+NL에 비해 높은 성능을 보이는데도 불구하고 낮은 Recall을 보이는 것으로, 자주 나오는 verb에 좀더 fitting되어 있음을 알 수 있습니다.
4.2 Semantic Role Prediction and Co-referencing
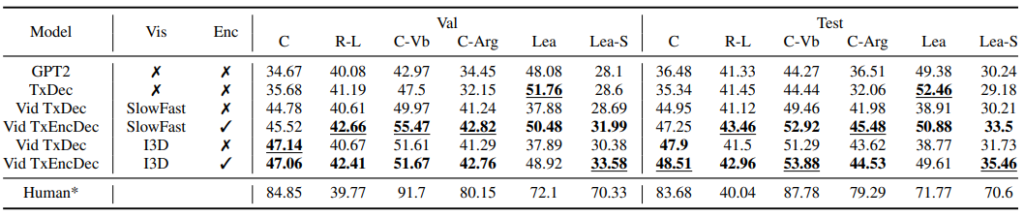
Semantic Role prediction과 co-referencing에 대해 어떤 성능을 보이는지 측정하기 위해, 평가지표 CIDEr 기반으로 여러 평가지표들이 활용되었습니다. CIDEr은 따로 레퍼런스가 달려있지않아, 정확한 측정 방식을 알기 어려우나, 아마도 이 논문인 듯하니 관심있으신 분은 읽어보시길 권장드립니다.
4.3 Event-Relation Prediction Accuracy.
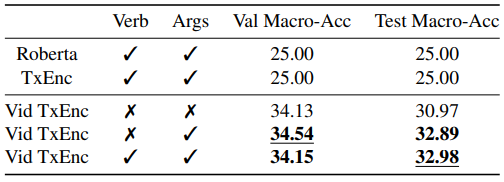
Table 4는 Event relation prediction에 대한 benchmark이며, 4종류로 구성된 분류 문제인만큼 평가지표로는 accuracy가 사용되었습니다. Table 4의 첫 행은 학습시키지 않은 language 모델의 성능이며, 4-way classification에서 랜덤하게 예측된 성능 평균이 두 경우 모두 나온 것으로 보아, 제안된 데이터 셋의 event relation 분포에 bias가 존재하지 않음을 알 수 있습니다. 그리고 학습시킨 두번째 행은 verb를 사용할 때와 argument를 사용할 때 학습시킨 성능으로 학습으로인해 성능이 향상되었음을 보입니다.
5. Reference
[1] Event relation classification metrics. MacroAveraged Accuracy on Validation and Test Sets. We evaluate only on the subset of data where two annotators agree