이번 리뷰 논문은 Salient Object Detection 논문 중 가장 보편적으로 인정 받는 방법론 입니다. 간단 명료한 네트워크 구조와 새로운 조합의 loss를 제안했습니다. 또한 Method 설명 중 이해를 돕기 위한 시각적 표현을 잘 설명한 논문이기도 합니다.
Intro

Sailent Object Detection(SOD)는 사람의 시각적인 능력 중 의미론적으로 유의미한 부분을 배경과 전경으로 나눌 수 있는 능력을 모사한 방법론에 해당합니다. 해당 방법론 이전의 방법론에서는 전역적인 의미론적 분석보다는 지역적으로 특징 분석을 통해서만 검출을 수행하였습니다. 또한 대부분 CE Loss만을 이용하여 학습을 진행하였기 때문에 위치적인 특징을 오차만을 계산한다는 문제가 있었습니다. 저자는 이러한 기존 방법론의 한계를 지적하며, Boundary 측면에서의 손실 함수와 모델을 제안합니다.
Method
Architecture
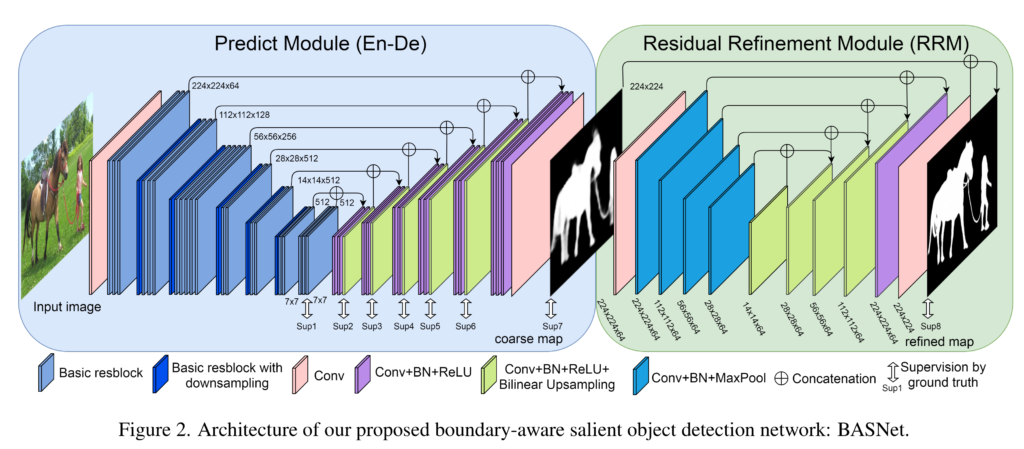
BASNet은 Predict module, Residual Refinement Module 두 가지 모듈로 구성되어 있습니다. 앞단의 predict module에서 saliency map을 획득한 뒤, 뒷 단의 refine module에서 해당 map의 boundary quality를 높여 최종적인 예측값을 출력하는 구조를 가지고 있습니다.
두 모듈 모두 U-Net과 동일한 Encoder-Decoder network 구조를 가지고 있습니다. Encoder와 Decoder간의 bridge stage 구성을 통해 Encoder에서는 high level global contexts를, Decoder에서는 low level details features을 얻어 보다 명확한 물체 검출 수행이 가능해집니다.
Predict module은 ResNet-34를 기반으로 설계되었습니다. 먼저 encoder의 입력 레이어 부분을 입력 영상의 해상도와 동일한 피쳐맵을 유지하여 receptive field 감소시키기 위해 conv (3×3)x64, w/o pooling으로 변경하였으며, 최종적으로 ResNet-34와 동일한 크기의 receptive field를(=layer 4와 동일한 피쳐맵 크기) 보기위해 2개의 block을 추가합니다. 자세한 내용은 fig 2에서 확인 가능합니다. Decoder 부분는 encoder와 동일한 구조를 가지며 bilinear upsampling을 통해 점진적으로 feature map 크기를 입력 영상의 해상도와 동일하게 만듭니다. Encoder와 Decoder 사이에는 bridge stages(Conv(dilation=3) (3×3)x512, ReLU, Batch normalization)를 추가하여 high level feature를 넘겨줍니다. 또한 over-fitting을 방지하기 위해, 각 decoder stages의 HED(Holistically-Nested Edge Detection)~Fig 2의 Sup 1~8에 대한 loss를 계산함 을 적용합니다.
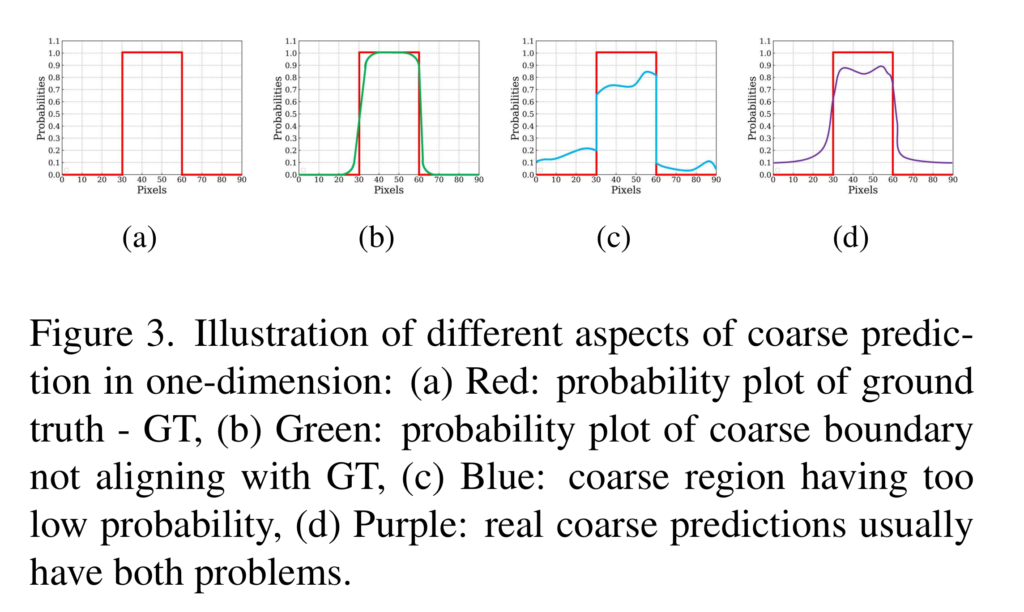
하지만 predict module만 이용하여 예측한 데이터는 확률값이 불명확한 특징을 보입니다. 예를 들어 fig 3의 빨간선이 명확한 구분한 GT라고 한다면 대부분의 예측값들은 fig 3-(b~d)와 같이 불명확하고 거친 예측값이 나온다고 저자는 주장합니다. 그렇기에 저자는 fig 3-(a)와 같이 명확한 확률값을 예측하기 위해서 refine module을 추가하기를 제안합니다. 타이니 버전의 predicted module 형태(U-Net과 유사한 encoder-decoder)로 구성되며, Fig 2의 Residual Refinement Module(RRM)에서 자세하게 볼 수 있습니다.
Hybrid Loss
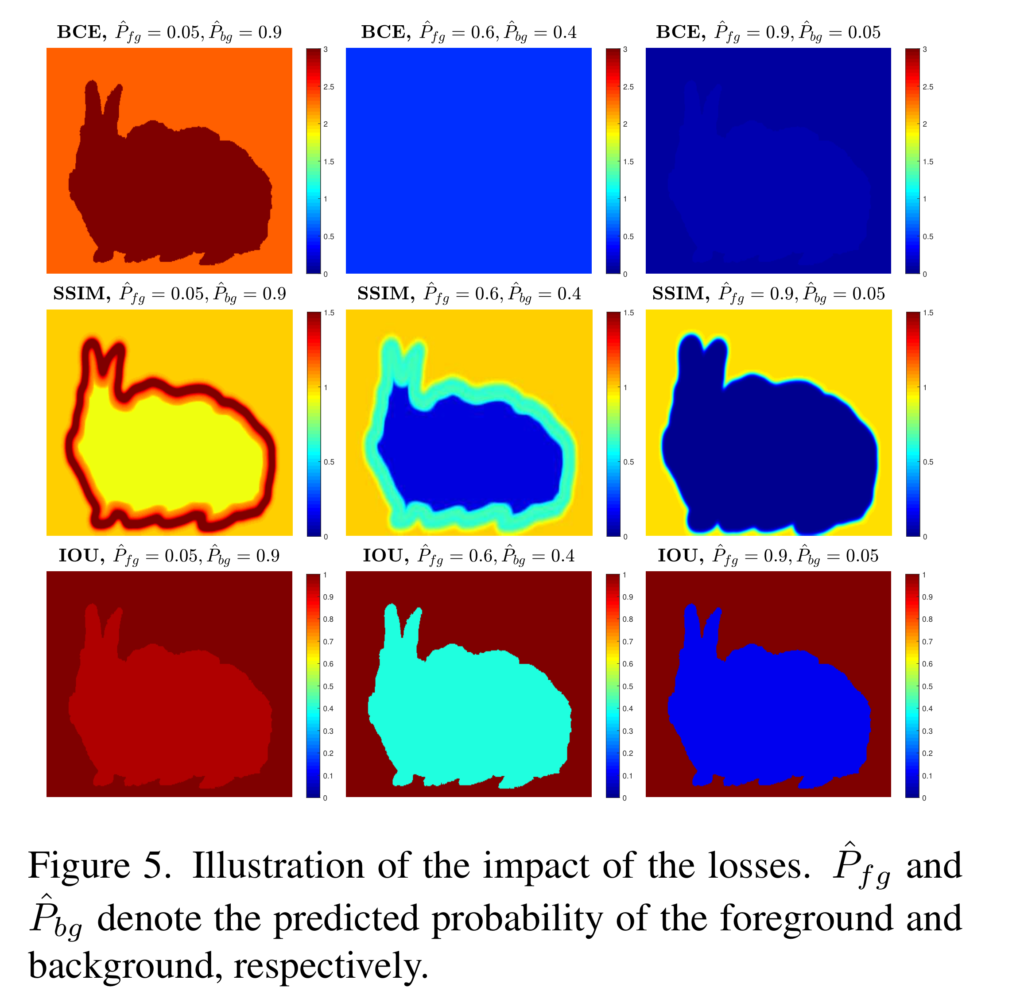
해당 논문의 핵심적인 전략은 loss에 있습니다. 저자는 보다 좋은 성능을 가지기 위해서는 픽셀 수준의 예측 뿐만이 아니라 윤곽 정보에 대해서도 최적화를 수행한다고 주장합니다. 기존의 방법론들은 대부분 BCE Loss만을 사용하여 최적화를 수행합니다. CE Loss의 특성상 픽셀의 맞고 틀림만을 예측합니다. 그럼으로써 Fig 5의 1열과 같이 학습이 진행됨(왼쪽에서 오른쪽 그림 순)에 따라 전반적인 부분에서는 최적화가 진행되는 것을 볼 수 있습니다. 영상의 대부분을 차지하는 백그라운드도 최적화 비율 큰 부분을 차지하게 되면서 class imbalence 문제를 야기 시키며, 백그라운드에서는 0에 까가운 에러값을 보이고 있습니다. 이러한 문제로 적은 부분을 차지하는 전경에는 집중하지 못하는 문제가 발생합니다. 그렇기에 저자는 픽셀 수준에서 예측하는 것이 아닌 pixel, patch, map-level에서 예측할 것을 제안합니다.
Loss는 오버피팅을 방지하기 위해서 HED에서도 최적화를 수행합니다. 수식 2와 같이 각 레이어에서 나온 feature maps에서 최적화를 진행합니다.
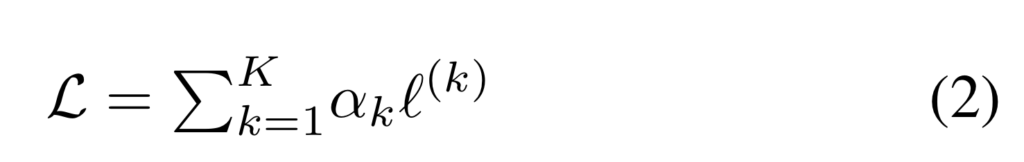
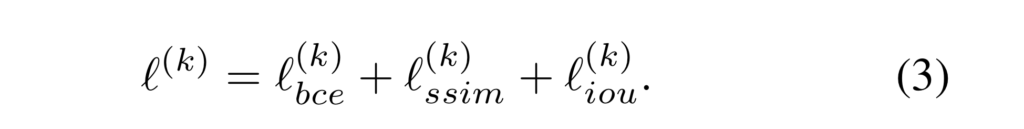
Loss는 픽셀 수준의 예측을 위한 BCE loss, 구조적인 부분에서 예측 성능을 향상 시기키 위한 SSIM loss와 instance 측면에서의 성능 향상을 위한 IoU Loss의 합으로 구성됩니다. 먼저 BCE Loss는 잘알다시피 픽셀 수준에서의 이진 분류 성능 향상을 통해 배경과 전경, 전반적인 예측을 위해 다음과 같은 정의됩니다.
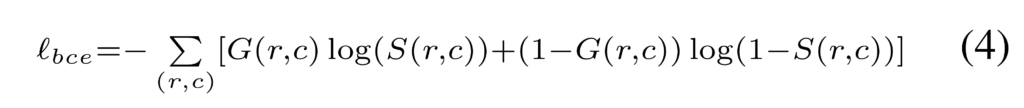
G(r, c)는 r, c 픽셀에서의 GT에 해당하며, S(r,c)는 r,c 픽셀에서의 모델의 예측 값으로 구성됩니다. 앞서 언급한 바와 같이 해당 loss의 직관적인 역할은 fig 3에서도 확인 할 수 있습니다. 하지만 앞서 언급한 바와 같이 상대적으로 많은 비율을 가진 배경에서 오버피팅이 발생시킨다는 문제가 발생합니다. 그렇기에 저자는 영상 평가 메트릭으로도 많이 사용하는 SSIM을 이용한 SSIM loss를 사용합니다. 이는 다음과 같이 정의됩니다.
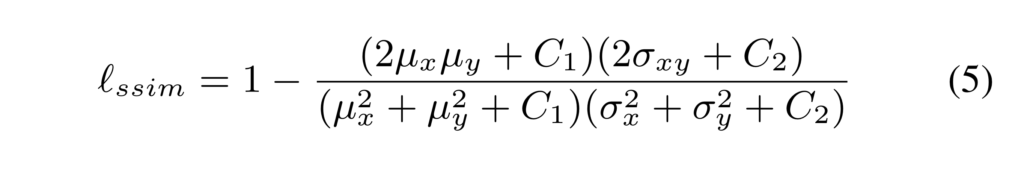
여기서 u, \omega 는 각각 패치 x(예측값), y(GT)간 영상 패치의 평균과 표준 분산을 의미합니다. C는 0 값을 방지하기 위한 파라미터 입니다. Fig 3의 2열을 보면 초기엔 경계면이 크고 오차값이 크게 발생하다가 학습이 진행됨에 따라 경계면이 점점 얇아지고 오차율이 떨어지는 현상을 볼 수 있습니다. 이를 통해 해당 loss를 통해 모델이 전경과 배경의 구분을 명확하게 학습함으로써 모호한 예측을 덜 할 수있도록 합니다. 추가로 저자는 BCE loss로 인한 불균형을 조금 더 보완하기 위해 물체 검출 혹은 영상 분할에서 흔하게 사용되는 평가, IoU를 이용한 loss를 사용합니다. Fig 3의 3열을 보면 배경에서는 오차 값이 그대로인 상태를 유지하다가 학습에 따라 물체에 해당하는 부위에서만 에러율이 줄어드는 것을 볼 수 있습니다. 해당 loss는 다음과 같이 정의됩니다.
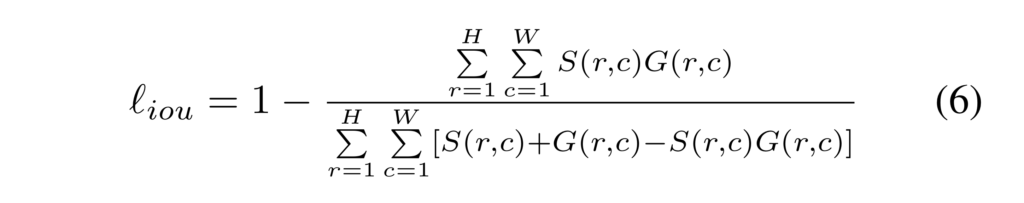
저자는 이 3가지 loss를 통해 픽셀 수준, 패치 수준, 맵 수준에서 모델을 최적화 할 수 있도록 합니다.
Experiment
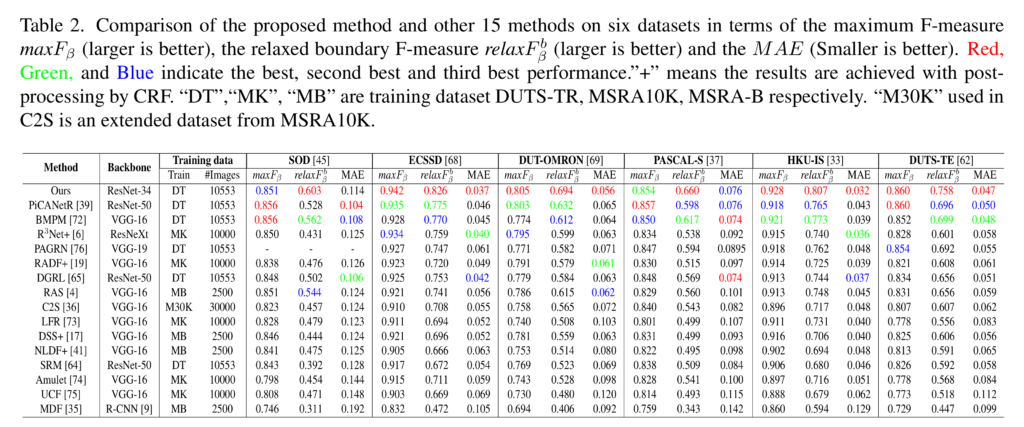
저자는 6가지 SOD 데이터 셋과 16 SOTA 모델과 비교를 수행하였으며, 우월한 성능을 보여줍니다. MaxF_b는나 여러 F-score에서도 오차율이 얼마나 적은 성능을 보이는지 relaxF는 경계면을 얼마나 잘 예측하는지 비교하기 위한 성능 지표이며, MAE는 픽셀 수준에서의 오차율 입니다.
정성적인 결과에서도 다른 방법에 비해 우월한 성능을 보여줍니다. 주목할 부분은다른 방법론에서 흐리거나 경계면이 명확하지 못한 예측을 하는 반면에 BASNet에서 개선된 성능을 보여줍니다.

——————————————————————————————
근래의 saliency detection 방법론은 사람의 시각으로도 구분이 힘든 경우에서도 검출하기 위한 연구나, 사람의 논리적인 측면에서 중요한 물체를 검출하기위한 연구, 가장 많은 연구가 이뤄지는 RGBD에서의 sailency detection 이 있습니다. 즉, 기초적인 데이터 셋에서는 어느정도 saturation 되었다고 판단됩니다. 그렇기에 RGB 뿐만이 아니라 열화상, 이벤트 카메라 등 다양한 도메인에서의 해당 태스크를 풀 수 있도록 제시하는 것도 커뮤니티에 기여할 수 있는 요소로 보고 있습니다.
좋은 리뷰 감사합니다.
‘over-fitting을 방지하기 위해, 각 decoder stages의 HED(Holistically-Nested Edge Detection)~Fig 2의 Sup 1~8에 대한 loss를 계산’하였다고 하셨는데, HED가 무엇인지 궁금합니다.
또한 제안한 loss는 Sup1~8이 적혀있는 부분의 feature map에서 수행되는 것인가요?? 그리고 식(2)의 알파값은 어떻게 결정이 되는 지 궁금합니다.
넵 이해하신 바와 같이 각 스테이지의 피쳐맵에서 예측을 수행합니다. 구체적인 내용은 HED[1]를 참고하시면 좋을 것 같아요. (참고 문헌 걸어둔단걸 까먹었네요… 지적 감사합니다.)
[1] Xie, Saining, and Zhuowen Tu. “Holistically-nested edge detection.” Proceedings of the IEEE international conference on computer vision. 2015.
좋은 리뷰 감사합니다.
predict module만 사용하면 확률값이 불명확한 특성을 보인다고 하셨는데 실험을 통해 알아낸 결과인가요? 아니면 이유가 따로 있는지 궁금합니다.
‘predict module만 사용하면 확률값이 불명확한 특성’을 명백하게 증명하지는 않았습니다. 하지만 정량적인 결과와 정성적인 결과를 통해 충분히 유추할 수는 있습니다.
가장 하단의 정성적인 결과를 보시면, 흐릿한 케이스를 볼 수 있습니다. 이런 현상이 나타나는 이유가 모델의 예측값은 0, 1 두 개의 값을 예측하는 것이 아니라 사이의 값을[0-1] 사이의 확률값으로 나타나기 때문입니다. 이러한 케이스에 대해 저자가 정의한 케이스 부분이 fig 3입니다.
안녕하세요 좋은 리뷰 감사합니다.
기존 방법론의 경우 CE Loss를 주로 이용하였다고 하셨는데 영역을 의미 있는 영역과 의미 없는 영역으로 픽셀을 분류하였다면 이를 개선하기 위해 boundary 정보를 더욱 강화해서 검출하도록 발전한 내용으로 이해하면 될까요?
감사합니다.
넵