감정인식 관련 논문입니다. 저번 리뷰의 음성 인식처럼 한 가지 모달리티가 아니라, 총 세 가지의 모달리티 (video, audio, text) 를 이용하여 감정을 인식하는 task 에 대해 다루고 있습니다.
리뷰를 시작하기 전에 간단히 요약하자면 아래와 같습니다.
- 기존의 two-phase (2단계)의 파이프라인을 사용하는 모델이 아닌, Fully End-to-end (FE2E) 모델을 Emotion recognition task 에 도입하였다.
- 이때 사용할 수 있도록, 기존에 있던 두 가지의 데이터셋을 재구성하였다.
- FE2E 방식은 computational overhead 가 발생한다는 단점이 있었으므로, 이를 감소시키면서도 성능은 유지하는 Multimodal End-to-End Sparse model (MESM) 을 제안하였다.
그럼 리뷰 시작하도록 하겠습니다!
우선, 멀티모달 데이터를 이용해서 감정을 인식하는 모델의 파이프라인은 일반적으로 2 단계로 구성됩니다.
- Hand-crafted 알고리즘을 사용하여 각 modality 로부터 feature representation 을 추출한다.
- 추출된 features 를 이용하여, End-to-end learning 을 수행한다.
이러한 방식을 two-phase pipeline 이라고 하는데, 여기에는 두 가지 단점이 존재합니다.
- 추출된 feature 가 고정되기 때문에, 다른 task 에 사용하기 위해 fine tuning 을 할 수가 없다.
- 어떤 hand-crafted 알고리즘이 최적일지 손수 찾는 것이므로, 다른 task 에 대해 사용할 수 있도록 일반화되지 않는다. 또한 최적이 아닐 수도 있다.
이와 반대로, End-to-end learning 은 이러한 두 가지 장점이 있습니다.
- 학습을 통해 feature 가 특정 target task 에 대해 최적화된다.
- feature를 추출하는 알고리즘을 손수 고를 필요가 없다.
그러나, two-phase pipeline 과 비교했을 때 단점 또한 존재합니다. 바로 computational overhead 를 가져온다는 것입니다. two-phase pipeline 은 입력으로 raw data 의 일부인 feature 를 받는데, 이와 달리 end-to-end 방식은 모든 data points 를 철저하게 processing 해야합니다. 따라서 이로 인해 computaional cost 가 비싸지고, overfitting 되기도 쉽다는 단점이 있습니다.
따라서 본 논문에서는 End-to-end learning 방식을 사용하면서도 computaional overhead 라는 단점을 없애기 위해, Multimodal end-to-end sparse model 을 제안합니다. 이는 해당 task 에 대해 가장 연관있는 feature 를 선택하고, video-audio 에 있는 중복되는 정보와 노이즈를 줄이기 위해, 이전 연구를 바탕으로 Cross-modal attention mechanism 과 sparse CNN 을 합쳐서 만든 모델입니다. 이를 이용하여 감정인식 task 를 해결할 것을 제안합니다.
참고로 Fully end-to-end learning 을 multimodal tasks 가 있긴 했습니다. 논문에 살짝 언급되어 찾아보니 Image captioning, Visual Question Answering, Visual Commonsense Reasoning, Natural Language for Visual Reasoning, Region-to-Phrase Grounding 이라는 task 에 대한 것들이라, Emotion Recognition 에 대해 제안하는 경우는 해당 논문이 처음이라고 합니다.
데이터셋
기존 multimodal emotion recognition 데이터셋(IEMOCAP, CMU-MOSEI) 은 아래의 2가지 이유로 fully end-to-end training 에 적용할 수 없습니다.
- 현존하는 데이터셋은 train / valid / test split 을 제공하는데, 이러한 데이터셋 split 의 인덱스가 직접적으로 해당 데이터셋 split에 match 되지 않는다. 따라서 재생산할 수가 없다.
- 데이터 샘플의 라벨은 text modality 에 대해 정렬되어 있다. 그러나, raw data 에서는 visual / acoustic 모달리티가 text 모달리티에 대해 정렬되어 있지 않아 있다. 따라서 fully end-to-end training 이 불가능하다.
그렇기 때문에, 아래의 방법을 통해 각 데이터셋을 재구성하였습니다.
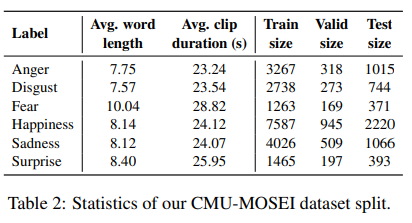
IEMOCAP
전문 배우 2명이 영어로 나눈 대화에 대한 151개의 비디오이고, 감정 카테고리는 9개인 세 가지 모달리티 (video, audio, text) 의 데이터입니다.
그러나 각 클래스에 대한 데이터 불균형으로 인해, 6개의 주요 카테고리 (angry, happy, excited, sad, frustrated, neutral) 의 데이터 만을 사용했다고 합니다. 대화가 utterance level (발화 레벨) 에 대해 annotated 되었으므로, 제공된 text transcription time 을 이용해서 data 를 utterance 에 따라 clip 하였습니다. 이로써 총 7380 개의 data samples 를 얻게됩니다. 그러나 현존하는 연구로부터 제공되는 pre-processed data 는 각 data sample 에 대해 an identifier 를 제공하지 않기 때문에, raw data 로부터 pre-processed data 를 재생산 하는 것은 불가능합니다. 따라서 본 연구진은 이 샘플들을 training / validation / testing sets 를 랜덤하게 70 %, 10%, 20% 할당함으로써 데이터셋을 재구성하였습니다.

CMU-MOSEI
1000 명의 다양한 사람들이 나눈 3,837 개의 비디오이고, 감정 카테고리는 6개 (happy, sad, angry, fearful, disgusted, surpriese) 인 세 가지 모달리티 (video, audio, text) 의 데이터입니다. utterance-level 로 annotated 되어 있고, 총 23,259개의 samples 이 있습니다. 이때, 공식적으로 관련 정보가 주어져서 raw data 를 이용해서 utterance-level data 를 생성할 수 있습니다. 생성된 utterances 는 현존하는 연구로부터 나온 preprocessed data 와 완벽하게 match 하지만, 현존하는 dataset 에는 2가지 이슈가 있다고 합니다.
1) 정렬되지 않는 데이터 샘플들이 많다.
2) 많은 샘플들이 생성된 데이터에 존재하지 않는다.
따라서 이러한 이슈들을 대처하기 위해, 정렬되지 않은 샘플들을 제거하는 data cleaning 을 수행하여 총 20,477 개의 clips 를 얻었습니다. 그 후 sentiment classification task 를 위한 CMU-MOSEI split 을 이용하여 새로운 데이터 split 을 만드는 방식으로 해당 데이터셋을 재구성하였습니다.
문제 정의
X 는 I 개의 multimodal 데이터 샘플이고, Y 는 이에 대한 I개의 라벨입니다. 아래와 같이 정의됩니다.
- X = \{ (t_i, a_i, v_i,) \}^I_{i=1}
- t_i : a sequence of words
- a_i : a sequence of spectogram chunks from audio
- t_i : a sequence of RGB image frames from the video
- Y = \{y_i\}^I_{i=1} : 각 data sample 에 대한 감정 annotation
Fully End-to-End Multimodal Model (FE2E)
감정인식 task에 사용하기 위해서, two-phase pepeline 의 두 가지 단계 (feature extraction 과 multimoal modelling) 를 최적으로 합치는 a fully end-to-end model 을 만들었습니다.
audio / video
- pretrained CNN-model 사용하여 feature extract
- linear transformation 으로 flatten 시켜서 sequential 한 vector representation 생성
- Transformer model 사용하여 sequential representaion 을 encoding
- 인코딩된 token 들 중 CLS token 을 output vector 로 이용
- a feed-forward network (FFN) 에 태워서 classifiaction scores 를 얻는다.
이때, video 와 같은 경우, GPU memory 를 줄이고, human faces 로부터 visual features 를 extract 하는 two-phase baselines 와 align 시키기 위해 MTCNN 이라는 모델을 사용해서, VGG 에 feeding 하기 전의 image frames 의 locaion of faces 를 얻어서 후 진행했다고 합니다.
text
- Transformer model 을 사용해서 sequence of words 를 encoding
- CLS token 을 output vector 로 이용
- 이를 FFN 에 feed 시켜서 classification scores 를 얻는다.
따라서 audio, video, text 의 모달리티로부터 classification scores 를 얻었고, 각 모달리티에 대한 가중치를 이용하여 얻은 weighted sum of the classification scores 를 final prediction score 로 사용합니다.
Multimodal End-to-end sparse model (MESM)
fully end-to-end model 이 two-phase model 보다 장점이 많긴한데, computational overhead 를 엄청 가져온다는 단점이 있었습니다. 그래서 성능은 유지하면서 이 overhead 를 줄이기 위해서, 본 논문에서는 Multiomodal End-to-end Sparse Model (MESM)을 제안합니다.

fully end-to-end model 과는 다르게, original CNN layers 를 N 개의 cross-modal sparse CNN blocks 로 교체했습니다. (이때, low-level feature capturing 을 위해서 가장 첫 번째 CNN layer 는 그대로 두었다.)
A cross-modal sparse CNN block 은 두 개의 부분으로 구성됩니다.
1. a cross modal attention layer
2. a sparse CNN model
아래에서 좀 더 자세하게 살펴보겠습니다.
Cross-modal Attention Layer
input : a query vector q \in R^d , a tack of feature maps M \in R^{C \times S \tims H \times W} (이때 C = channel 의 개수, S = sequence length, H = height, W = width 를 뜻한다.)
– query vector 를 사용해서, feature maps 에 cross-modal spatial attention 이 수행됩니다.
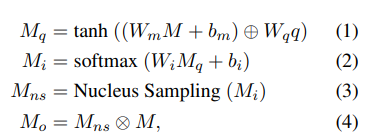
cross modal spatial attention 에서 W_m \in R^{k \times C}, W_i \in R^k 는 linear transformation 의 weights 이고, b_m \in R^k, b_i \in R^q 는 biases 입니다. 이때 k 는 pre-defined hyper-parameter 이고, (+) 는 a tensor 와 a vector 간의 broadcast addition operation 을 뜻합니다.
Eq.2 에서, softmax 함수는 H x W dimensions 에 적용됩니다.
그리고 M_i \in R^{S \tims H \tims W} 는 각 feature map 에 해당하는, spatial attention socres 의 tensor 를 뜻합니다.
마지막으로, input feature maps M 을 sparse 하면서도 import information 을 보존하게 만들기 위해 M_i 에게 Nucleus Sampling 을 적용시켜서, 각 attention score map 에 있는 probability mass 의 top-p portion 을 얻습니다. (이때, p 는 0~1 사이에 있는 pre-defiend hyper-parameter 이다.) M_{nx} 에서, Nucleus Sampling 에 의해 선택된 points 는 1 이 되고, 다른 것들은 0 이 된다.
그리고, M_ns 와 M 을 broadcast point-wise multiplication 을 수행해서, output M_o 를 생성합니다.
따라서, M_o 는 a sparse tensor 로 만들어집니다. 이때 어떤 positions 는 0 이고, sparsity 정도는 p 에 의해 조절됩니다. 즉, p 가 tensori 의 sparsity 를 조절하는 값입니다.
Sparse CNN
본 논문은, corss-modal attention layer 를 통과 시킨 후 submanifold sparse CNN 을 태우는 모델을 제안합니다. 이때 해당 CNN 은 이전 연구에서 제안되었었는데, 더 높은 차원의 공간에 존재하는 낮은 차원의 데이터를 processing 하는데 사용되는 것입니다.
본 연구진은 multimodal emotion recognition task 에서, 데이터의 일부 만이 recogniiton of emotions 에 관여할 것이라고 추측했기 때문에, sparse CNN 을 사용하면 computational overhead 가 줄을 것이라고 매칭시킨 것입니다.
본 논문에서 제안한 모델에서, sparse CNN layer 는 cross modal attention layer 의 output 을 받아서, active positions 에 대해서만 convolution computation 을 수행합니다. 즉, 1 인 부분에만요.
이론적으로, 하나의 location 에 대한 amount of computation (FLOPs) 관점에서, a standard convolution 은 z^2mn FLOPs 가 든다고 합니다. 그리고 a sparse convolution 은 amn FLOPs 가 든다고 합니다. ( 이때 z = kernel size, m = input channel 의 개수, n = output channel 의 개수, a = 해당 location 에서 active points 의 개수)
따라서, 모든 locations 와 모든 layers 를 고려해봤을 때, sparse CNN 은 compu tation 을 상당히 줄이는데 도움을 줍니다.
실험 - Evaluation Metrics
- IEMOCAP : F1-score
- CMU-MOSEI : weighted accuracy, binary F1 score
- 이전 연구를 바탕으로 정하였다고 합니다. 조금 생소한 Weighted accuracy 를 살펴봅시다.
Weighted Accuracy
CMU-MOSEI 데이셋은 각 emotion category 에 대해 positive samples 보다 negative samples 를 많이 가지고 있기 때문입니다. 따라서, 일반적인 accuracy 를 사용하면 model 은 모든 샘플들이 negative 라고 예측했을 때 좋은 score 를 얻게 될 것이기에 WAcc 를 사용합니다.
기존 Accuracy : (TP + TN ) / (TP + FP + FN + TN)
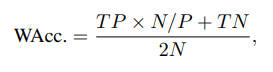
실험 - Baselines
baselines 로는 a two-phase pipeline 을 택했습니다.
Feature extraction 은 이전 연구를 따라 추출하였고 Multiomodal learning 은 3가지가 아닌, 4가지 모달리티를 사용하는 모델을 사용했습니다.
Feature extraction
- visual data : 얼굴 근육의 움직임을 포착하기 위해, OpenFace library 를 사용해서 video 의 image frames 로부터 35 개의 facial action units (FAUs) 를 추출했다.
- acoustic data : 142 차원의 features 를 추출했다. (22 차원의 bark band enery (BBE) features, 12 차원의 mel-frequency cepstral coefficient (MFCC) features, 그리고 18 phonological classes 로부터 얻은 108 개의 statisticla features ) DisVoice library 를 사용해서, 400 ms time frame 마다 features 를 추출했다.
- textual data : pretrained GloVe word embeddings 를 사용했다. (glove-840B.300d)
Multimodal Learning
데이터에 서로 다른 modalities 가 unaligned 되어 있으니까, aligned data 만을 다룰 수 있는 이전 연구의 모델들과 비교할 수가 없어서 4가지의 모달리티를 사용하는 multimodal learning models 를 baseline 으로 사용했습니다.
- late fusion LSTM (LF-LSTM) 모델,
- late fusion Transformer (LF-TRANS) 모델,
- Emotion Embeddigns (EmoEmbs) 모델,
- Multimodal Transformer (MulT) 모델
이러한 모델들이 첫번째 단계에서 추출된 hand-crafted features 를 input 으로 받아서, classificatoin decisions 를 내립니다. 이걸 베이스라인으로 삼아서 비교했습니다.
Training Details
Adam optimizer 와 binary cross-entropy loss 를 사용하였습니다. 추가로, imbalance problem 에 대처하기 위해, positive sampling 에 대한 loss 는 positive 와 negative samples 에 대한 비율로 weighted 되었습니다. 또한 완전한 비교를 위해, 모든 모델에 대해 철저한 hyper-parameter search 를 수행하였습니다. (Appendix A 참고) 실험은 Nvidia 1080Ti GPU 로 수행됐고, 코드는 Pytorch 로 구현됐습니다.
- video / audio modalities 에 대해서는 preprocessing 을 수행했습니다. audio 는 window size 가 25 ms 이고 stride 가 1 2.5 ms 인 mel-spectogram 을 사용한 다음, 400 ms time window 당 spectogram 을 chunk 했습니다.
- text modality 는, baseline 을 위해서는 word tokenization 을 수행했고, end-to-end model 을 위해서는 subword tokenization 을 수행했습니다. 이때 text 의 length 는 50 tokens 로 제한했다.
결과 분석
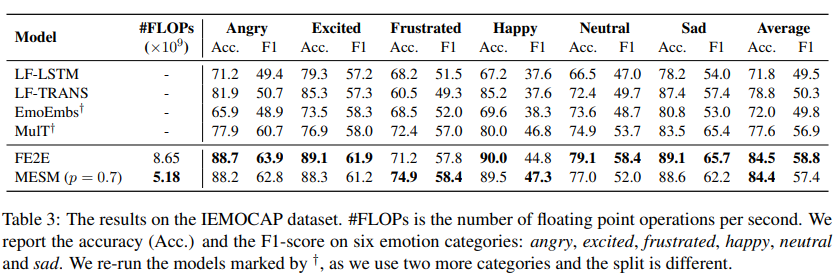
baseline 을 FE2E 가 능가했습니다. 또한 feature extraction 에서 computation cost를 줄였음에도 불구하고, MESM 가 FE2E 과 비슷한 성능을 달성했음을 알 수 있습니다. (이때 p 는, 실험을 통해 구한 Nucleus Sampling 최적의 값)
Case study
제안한 모델에 대한 insight 를 얻기 위해, 6개의 basic emotions (happy, sad, angry, surprised, fear, disgusted)에 대한 sparse cross-modal attention mechanism 에 대한 attention map 을 시각화를 했습니다.
- video

Figure 3 에서도 볼 수 있듯이 입, 눈, 눈썹, 눈과 입 주변의 얼굴 근육 등을 region of interest 로 고려하여 집중하고 있음을 알 수 있었습니다. 따라서 해당 메소드를 검증하기 위해, 이전 연구를 바탕으로 facial action coding system (FACS) 이 포착한 region 과 비교해보았다고 합니다.
예를 들어, happy 는 lip 의 양쪽을 위로 옮기는 것에 영향을 받고, sad 는 입꼬리를 아래로 내리는 것에 영향을 받는다.
따라서 해당 시각화를 통해, MESM 이 6가지 감정 카테고리에 대한 regions of interest 를 대부분 잘 포착할 수 있다는 것을 검증하였습니다.
- audio
acoustic modality 은 각 emotion label 의 관점에서 attention 을 분석하기 어렵다. audio data 에 대한 attention maps 의 일반적인 visualization 을 Figure 4 로 보여주었습니다.

모델은 early attention layer 에서는 high sepctrum values 의 영역에 집중하고, cross modal attention layers 를 거쳐감으로써 points 들이 점점 걸러지는 것을 알 수 있다.
Nucleus Sampling 의 효과
MESM 에서 Nucleus Smaping 의 효과에 대해 깊이 이해하기 위해 0~1 범위의 p 값을 0.1 간격으로 조정해가면서 실험을 수행하였습니다.
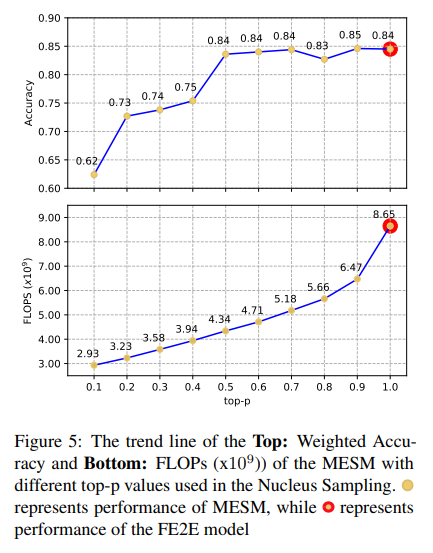
경험적으로, top-p 값이 작아질 수록 computaiton 의 양이 줄어드는 것을 볼 수 있었습니다.
p가 0.9 에서 0.5로 감소해도, 성능 drop 이 없었음을 알 수 있었다. 그런데 0.5 ~ 0.1 에서는 성능이 떨어지는 것을 볼 수 있었습니다. 즉, emotion recognization 을 위한 유용한 정보가 사라졌다는 뜻입니다. 그러므로 top-p 값이 0.5 일때, MESM 은 FE2E 와 비교했을 때 feature extraction 에서 절반 정도의 FLOPs 으로, 비슷한 성능을 얻을 수 있었습니다.
Ablation study
본 논문보다 modality 의 수가 많거나 적은 이후 연구들이 비교할 수 있도록, ablation study 를 수행하였습니다.
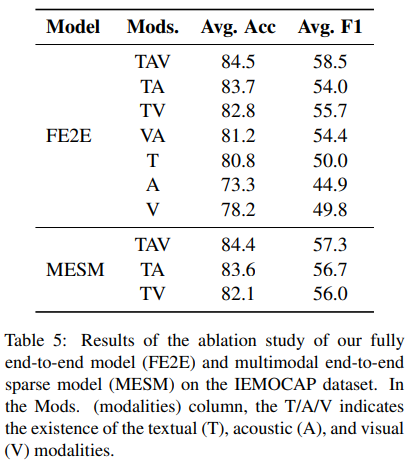
1. modality 개수가 많을 수록 성능이 높다.
2. single modaltiy 로 할 때는 textual modality 가 제일 좋았다.
이것은, 본 논문에서 제안한 모델의 cross-modal attention mechanism 에서 T 를 사용해서 A 와 C 에 attention 을 주는 것이 합리적인 선택이었음을 보여줍니다.
3. two modality : MESM 이 FE2E 와 비벼볼만한 성능을 달성했다.
결론 및 요약
multimodal emotion recognition tasks 에서 two-phase pipeline 과 fully end-to-end (FE2E) 를 비교했습니다.
이를 통해 FE2E 에서 있었던 computational overhead 를 줄이는, 새로운 multimodal end-to-end sparse model (MESM) 을 제안했습니다.
현존하는 두 개의 데이터셋을 reorganize 해서, FE2E 방식으로 학습시킬 수 있도록 만들었습니다.
실험을 통해, FE2E 방식이 two-phase pipeline 방식의 sota 모델을 능가함을 알 수 있었습니다.
또한, feature extraction 에 대해 FE2E 의 절반 정도의 computatinal cost 가 들면서도, 성능은 유지하는 모습을 보여주었습니다.
visual / acoustic data 에 대한 cross modal attention map 의 시각화를 제공했고, 이를 통해 해당 방법론이 각 감정에서 어느 부분에 집중하는지 설명가능함을 보였습니다.
또한 MESM 에서 모달리티의 개수가 많아질수록 emotion recognition 의 성능이 높아지는 모습을 보였으며, 이를 통해 더 많은 모달리티가 추가 되어 더 높은 차원의 공간에서 emotion 에 대한 유의미한 정보가 sparse 하게 존재하더라도, 해당 방법론이 이에 대해 잘 대처할 것이기 때문에, 성능이 향상될 것이라는 잠재력을 확인하기도 하였습니다.