Before Review
이번 논문 리뷰도 Temporal Action Detection(Localization) 논문을 가져왔습니다. Temporal Action Detection 관련 연구를 할 때 고려할만한 요인들을 여러 가지 소개해주면서 이 Task 자체에 대한 깊은 고찰을 엿볼 수 있습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Temporal Action Detection 연구의 중요성은 날이 갈수록 더 중요해진다고 합니다. Temporal Action Detection은(이하 TAD) security surveillance, sports analysis 그리고 smart video editing 등 다양한 분야에서 응용이 될 수 있습니다.
하지만 이러한 Temporal Action Detection은 action의 추상적인 라벨을 예측함과 동시에 action 간의 temporal interval을 예측해야 하기 때문에 아직까지도 challenging 한 task로 여겨지고 있습니다. 그래서 많은 연구자들이 어떻게 하면 좋을까 많은 시도들이 있었지만 그중 모든 연구들이 공통적으로 하는 흐름이 있었습니다.
바로 End-to-End가 아니라는 점입니다. 비디오에서 정말 자주 사용하는 I3D나 TSN 혹은 비교적 최근이지만 Slowfast 같은 Backbone Network는 TAD를 수행하는 데 있어 Clip level의 feature를 추출하는 데 사용이 됩니다. 그런데 이 Clip level의 feature를 추출하는 Backbone들은 TAD 학습 과정에서 Gradient들이 전달이 되지 않습니다.
즉, 고정된 Back-bone feature를 사용했다는 것이지요.
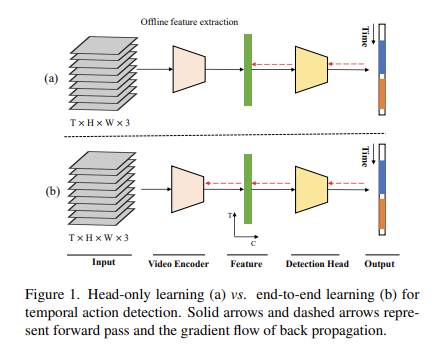
물론 이렇게 하면 학습 Process는 더욱 빨라지기 때문에 연구자들이 선호하는 경향이 있습니다. 왜냐하면 Backbone까지 Gradient들이 업데이트되려면 당연히 연산량이 훨씬 많아지겠죠. 하지만 이러한 흐름은 두 가지의 문제점을 가지게 됩니다.
먼저, Task inconsistency 문제입니다. 사전학습은 Classification으로 하고 down-stream task는 Localization이니 이러한 차이로 인한 performance drop입니다. 그다음으로는 data inconsistency 문제입니다. 사전학습에 사용되는 데이터셋과 down-stream task에 사용되는 데이터셋이 불일치하기 때문에 발생하는 performance drop입니다.
결국 위에서 언급한 두 문제를 해결하기 위해서는 Backbone Network 역시 학습 중간중간 업데이트가 되어야 한다는 점입니다.
근데 그렇다면 Temporal action detection 분야에서 End-to-End 방식 연구는 없었을 까요? 사실 있었다고 합니다. 하지만 충분하지 못했다고 하네요. 깊이 있는 분석이 담긴 연구가 없었고 이렇기 때문에 End-to-End 방식의 장점을 충분히 도출하지 못했다고 합니다.
그래서 저자는 처음으로 TAD task에 대한 End-to-End 방식의 다양한 분석을 내놓았으며 덤으로 성능도 SOTA를 달성합니다.
또한 저자는 단순히 성능만 고려할 게 아니라 속도(연산량)도 고려를 해야 한다 주장합니다. 연구 레벨에서만 머무르지 말고 실제 상용화가 될 수 있으려면 computation cost도 고려가 돼야 한다는 점입니다.
마찬가지로 그동안의 연구 중 computation cost에 대해서 제대로 다룬 연구들이 없었다고 합니다.
이에 저자는 연산량을 4배 줄이면서 성능은 SOTA를 달성할 수 있는 End-to-End 방식의 베이스라인을 제공합니다. 그뿐만이 아니라 End-to-End 방식의 장점, 설계 디자인 등에 대한 다양한 분석을 내놓습니다.

저기 나와있는 MUSES나 AFSD는 CVPR2021에 나온 방법론입니다. 그런데 살펴보면 mAP와 FLOPs 측면에서 작년 SOTA들을 넘어서는 것을 보여주고 있습니다. 상당히 흥미로운 점은 Optical flow를 안 쓰고도 SOTA를 달성했다는 게 참 대단하네요.
아무튼 간에 본 논문에 대한 간략한 설명이었고 지금부터는 저자가 제공하는 다양한 분석에 대해서 알아보도록 하겠습니다.
Experimental Setup
본격적인 실험과 분석을 먼저 얘기하기 전 실험 세팅부터 알아보도록 하겠습니다. 실험의 양이 워낙 많기도 해서 한번 정리를 해야 할 것 같습니다.
Video Encoders
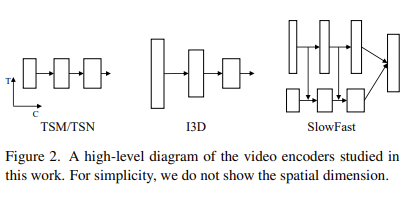
비디오 인코더의 선택도 중요합니다. 본 논문에서는 4가지의 Encoder를 가지고 실험을 진행했다고 하네요.
- TSN : 단순한 2D CNN 인코더입니다. 프레임을 독립적으로 처리하기 때문에 temporal context를 반영하기에는 한계가 있습니다.
- TSM : 처음 보는 구조이긴 합니다. Feature map의 temporal dimension에 대해서 몇 가지 shift를 일으켜서 temporal information을 capture 하는 데 용이하게 한 구조라고 하네요.
- I3D : 구글의 Inception network를 3D로 변경한 구조입니다. 비디오 분야에서 가장 많이 사용되는 Encoder 이기도 합니다.
- SlowFast : slow pathway와 fast pathway를 이용하여 비디오 프레임으로부터 sparse 한 정보와 dense 한 정보 모두를 capture 하는 encoder입니다.
Temporal Action Detection Heads
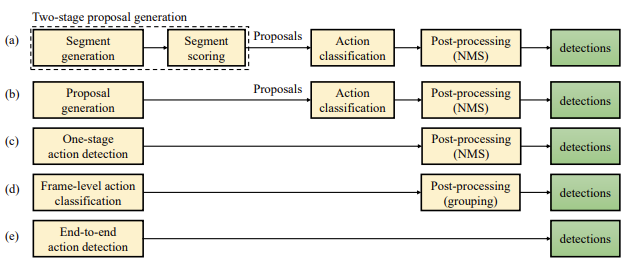
Backbone Network 말고도 Temporal Action Detection Head도 다양하게 선택할 수 있겠죠. Temporal Action Detection 방식이 크게 세 가지로 분류될 수 있는데 1) anchor-based , 2) anchor-free , 3) query-based 방식이 있습니다. 각각의 방식에 해당하는 SOTA 방법론을 가지고 실험을 진행했다고 합니다.
- G-TAD : 논문을 읽어보진 못했지만 anchor 기반의 TAD task에서 항상 SOTA 방법론으로 비교되는 연구입니다. 비디오를 하나의 그래프로 보고 각 노드들은 비디오의 클립(snippet)으로 정의하는 참신한 구조를 사용하는 방법입니다. 이러한 노드들은 action의 potention을 가지고 있는 부분에서 sampling 되고 노드들의 연결이 anchor가 되는 방식입니다.
- AFSD : 마찬가지로 논문을 읽어보지는 못했습니다. Object Detection에서 사용되는 anchor-free 방식에서 동기를 얻어 제안된 연구입니다. 각 프레임마다 action boundary의 distance를 측정한다는 데 정확히는 저도 잘 모르겠습니다. 나중에 논문을 읽어보면 내용을 조금 더 보충하도록 하겠습니다.
- TadTR : 이 Head는 정말 처음 봐서 찾아보다가 알게 된 사실이 있는데 저자가 본 논문을 쓴 사람과 동일 인물이라는 것입니다. CVPR에 냈다가 억셉이 안된 것 같지만 본 논문에서는 이 방법론을 베이스로 저자가 제안하는 베이스라인을 구축했습니다. 콘셉트 자체는 최초로 Transformer를 가지고 End-to-End Temporal Action Detection을 수행할 수 있는 방법론입니다.
End-to-End Learning
일단 원래의 Backbone Encoder에서 Classifier를 제거하고 마지막 global pooling layer를 spatial axis에 대해서만 작동하도록 수정했다고 합니다. 그러고 나서 Detection Head를 이어서 붙이면 unified network를 만들 수 있습니다.
그래서 이제 Loss로부터 만들어지는 Gradient들이 학습 모든 Process에 관여를 하게 되며 보다 더 temporal action detection에 최적화된 network를 얻을 수 있습니다.
Datasets
THUMOS14 dataset : 원래는 101가지의 action class를 가지는 데이터셋이지만 그중 20개의 class에 대해서만 temporal annotation을 제공합니다. 200개의 validation video로 학습을 진행하고 213개의 test video로 평가를 한다고 합니다. 200개의 비디오만 사용한다고 해서 task의 난이도가 쉬운 것은 아닙니다. 왜냐하면 비디오의 길이가 평균 4분 정도이기 때문이죠. 또한 action의 영역이 굉장히 sparse 하기 때문에 action과 background 간의 imbalance가 조금 심한 데이터셋입니다.
ActivityNet dataset : 200가지의 action class를 가지고 있는 데이터셋으로 temporal action localization benchmark를 위해 등장한 데이터셋입니다. 평소에는 test data에 대해서 평가를 할 수 없고 activitynet challenge 기간에만 평가 서버가 열려서 test data에 대해서 평가할 수 있습니다. 이러한 제한적인 상황 때문에 보통 연구를 할 때는 10024개의 train 데이터로 학습하고 4926개의 validation 데이터로 평가를 진행하다고 합니다
Results and Analyses
The Effect of End-to-End Learning
- Head only vs End to End
저자의 핵심 주장인 End to End 학습 방식의 장점입니다.
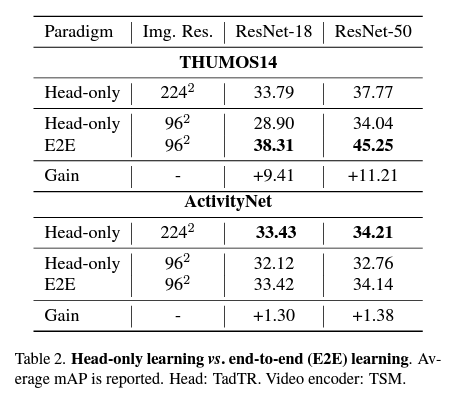
먼저, End to End 학습 방식은 두 가지 데이터셋인 THUMOS14와 ActivityNet에서 모두 성능을 향상했습니다. 그리고 역시 TSM ResNet-18과 ResNet-50일 때 모두 성능을 향상하는 것을 확인할 수 있습니다.
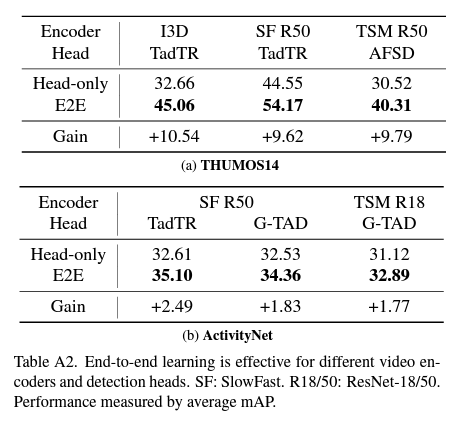
자 그렇다면 TSM encoder 뿐만 아니라 다른 encoder에서도 general 하게 작동하는지 살펴봐야겠죠? 결론적으로 말씀드리면 I3D, Slowfast 모두 성능적인 측면에서 큰 이득을 확인할 수 있습니다.
다음의 내용이 저는 조금 인상 깊은데 Head only 방식을 사용하면 입력 해상도를 낮추었을 때 성능이 떨어지는 반면 E2E 방식으로 학습하면 해상도를 낮췄을 때도 더 높은 성능을 보여주고 있습니다. 이것은 E2E 방식의 효율성을 입증할 수 있을 것 같습니다. 해상도가 낮아지면 당연히 연산량도 줄어들기 때문에 Inference 속도적인 측면에서 이득을 얻을 수 있습니다.
그다음의 분석은 THUMOS14 데이터셋 같은 경우는 성능 이득이 큰 반면, ActivityNet에서는 효과가 조금 미비한 측면이 있습니다. 저자는 이에 대해서 두 가지 분석을 내놓습니다.
- Detector가 class에 상관없는 localization만을 수행하기 때문이라고 합니다. 사실 저는 이 부분은 제대로 이해를 못 했습니다. 그래도 일단 논문의 설명을 그냥 적어보자면 Action Detection은 Localization + Classification으로 구성이 되어있지만 E2E 방식으로 Localization만 최적화시키니 성능 향상이 적다는 주장입니다. 아마 저자가 실험에 사용한 Action Detector들이 class-agnostic localization을 하는 detector라 그런 것 같습니다. 정확히 이해가 되지 않아 일단 설명은 여기까지 하도록 하겠습니다.
- 애초에 ActivityNet과 THUMOS14는 다른 성격의 데이터셋이다. THUMOS는 상대적으로 action의 구간이 짧고 background가 긴 반면 ActivityNet은 action의 구간이 길고 action의 category가 200개로 상당히 많습니다. 이러한 데이터셋의 차이가 만들어내는 결과라고 주장합니다. ActivityNet이 좀 더 어려운 데이터셋이기 때문에 단순히 E2E로만 바꿨다고 해서 성능이 좋아지지 않는다라고 보면 될 것 같습니다.
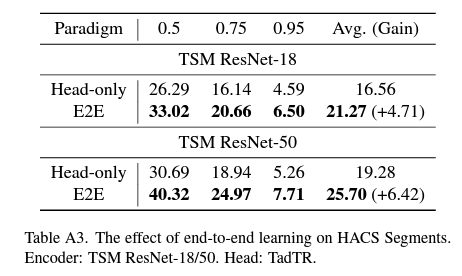
Supplementary를 보면 ActivityNet이랑 비슷한 데이터의 분포를 가지는 HACS 데이터셋에서의 성능도 리포팅되어 있는데 이 데이터셋에서는 또 잘 동작하는 것을 볼 수 있네요.
- Image Augmentations
다음으로는 Image Augmentation에 대한 간단한 실험입니다. 보통 비디오에서 사용하는 Augmentation은 Random cropping이나 Random flipping 정도를 사용했는데 그것 말고도 Random rotation, Random distortion과 같은 strong augmentation도 실험을 해봤다고 합니다.
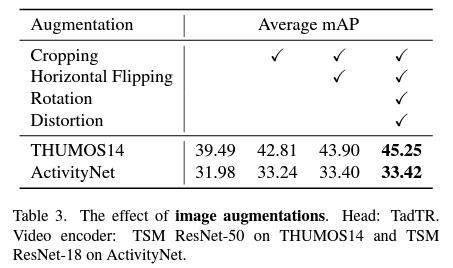
THUMOS14에서는 성능 향상이 뚜렷하지만 ActivityNet에서는 미비하네요. THUMOS14는 학습 데이터가 200개밖에 존재하지 않기 때문에 Augmentation의 효력이 발휘할 수 있지만 ActivityNet은 그래도 꽤나 large-scale의 데이터셋이기 때문에 효과가 크지 않는 것이라고 합니다.
Evaluation of Design Choices
이제는 Detection Head와 Video Encoder에 대한 분석 실험입니다.
아마 Detection Head들은 각각 연구자들이 직접 고안해서 더 좋은, 더 참신한 방법론들이 계속 나오고 있는 상황이니 본 논문에서 비교하는 벤치마크는 그냥 그렇구나 정도로 받아들이면 될 것 같습니다. 하지만 Video Encoder는 조금 얘기가 다르죠. 보통은 이미 구현된 것을 가져다가 사용을 하기 때문에 본 논문에서 제시하는 분석들을 잘 이해하고 본인 연구에 활용하면 좋을 것 같습니다.
- Detection Heads
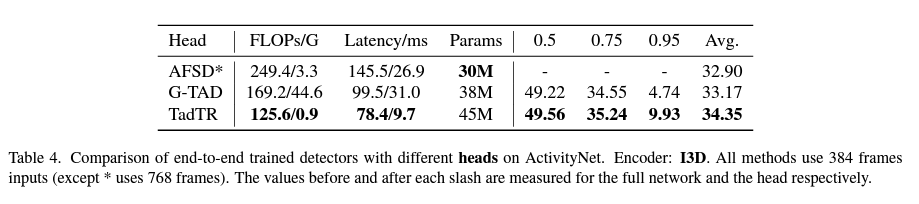
TadTR이라고 하는 Detector가 가장 좋은 성능을 보여줍니다. 사실 TadTR은 본 논문의 저자가 연구한 또 다른 논문인데 이렇게 좋다고 본인이 쓴 다른 논문에서 이렇게 좋다고 하는 게 조금 인상 깊네요. 성능이나 연산량은 TadTR이 비교적 좋은 편인데 모델 사이즈 자체는 AFSD가 더 좋은 상황입니다. Small model size를 요구로 하는 task에는 AFSD가 적합할 것이다 저자는 이렇게 얘기하고 있습니다.
- Video Encoders
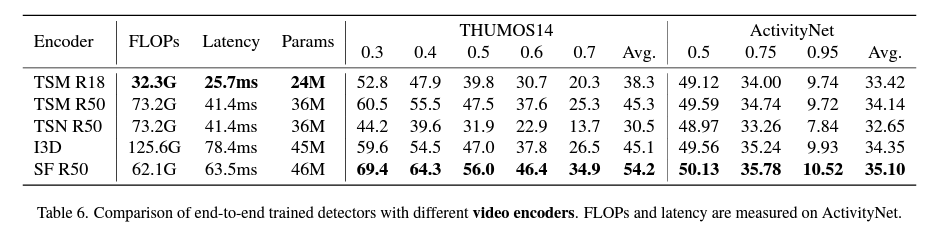
주목해서 봐야 할 부분은 세 가지입니다.
- TSM의 모델 사이즈를 줄이니 Localization 성능이 많이 떨어지더라(45.3->38.3)입니다.
- TSM ResNet50 모델이 I3D와 비슷한 성능을 보여주지만 더 빠른 지연 시간(Latency)을 보여준다는 것입니다. Localization 정확도는 거의 비슷하지만 속도가 Inference 속도가 더 빠르다고 하니 TSM R50은 I3D를 대체할 수 있을 것 같습니다.
- SlowFast가 두 가지 데이터셋 모두 최적의 성능을 보여주고 있습니다. 특히나 THUMOS14에서 폭발적인 성능을 보여주고 있는데 그 이유는 THUMOS14에서는 비교적 짧은 action이 많이 등장하는 데 있는 SlowFast 구조 중 fast pathway가 특히 강한 부분이라 이 정도의 성능 향상을 얻을 수 있었다고 합니다.
- Temporal Resolution
자 구조적인 측면 말고 이제는 하이퍼 파라미터이지만 비디오에서는 중요한 frame rate입니다. Temporal 차원에 대해서 어느 정도로 바라볼 것인지 결정하는 요인입니다.
아래의 그림은 TadTR이라는 Head를 가지고 input frame rate를 다르게 했을 때의 성능과 속도를 비교하고 있습니다.
Input frame rate라는 것은 비디오에서 얼마의 간격으로 frame을 sampling 할 것인지 결정하는 요인입니다. 10 FPS라는 것은 1초에 10 frame을 sampling 한다는 것이라 보면 됩니다. 이 부분 역시 성능에 관여를 하기 때문에 저자가 실험을 한 것으로 보입니다.
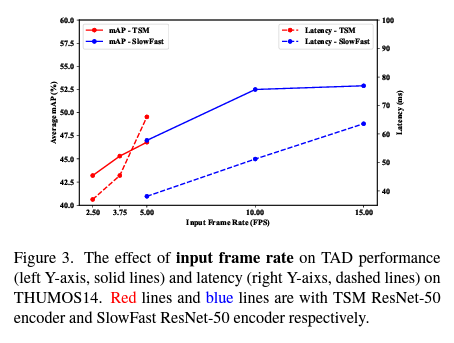
우선 frame rate를 높일수록 Latency가 증가하는 것은 어쩔 수 없습니다. 들어오는 정보량이 많으니 처리하는 시간이 더욱 필요하겠죠. 이는 직관적으로 받아들일 수 있습니다.
그리고 또한 frame rate를 높였을 때 mAP가 증가하는 것을 볼 수 있는데 길이가 긴 action에 대해서 적은 FPS로 sampling 하는 것은 그렇게 큰 문제가 되지 않습니다. 예를 들어 2.5 FPS로 길이가 10초 구간의 action을 sampling 하면 25개의 frame이 입력으로 들어옵니다. 어느 정도 커버할 수 있다는 소리이죠. 하지만 2.5 FPS로 길이가 0.5초 구간인 action을 sampling 하면 1~2개의 frame만을 가지고 action을 detection 해야 합니다.
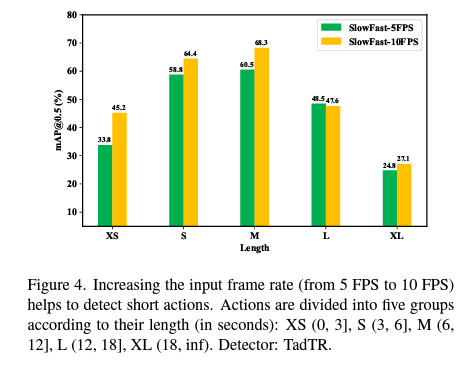
즉, short action을 detection 하기 위해서는 어느 정도 높은 frame rate로 sampling을 해야 한다는 것을 시사합니다.
10 FPS와 15 FPS는 큰 차이가 없기 때문에 10 FPS가 성능과 속도적인 측면에서 괜찮은 비율이라는 것을 확인할 수 있습니다. 실제로 대다수의 논문에서도 10~15 FPS로 sampling 합니다. 위의 그래프를 보면 x축은 action의 길이입니다. action의 길이가 짧아질수록 10 FPS로 sampling 하는 것이 성능이 더 좋은 반면 action의 길이가 길어지면 성능 차이는 그다지 벌어지지 않게 됩니다.
- Image Resolution
그리고 다음으로는 이미지의 해상도입니다. 시간 차원에 대해서 얼마나 촘촘하게 sampling 할 것인지 이것도 중요하지만 프레임 자체의 공간 차원에 대해서는 어느 정도의 정보량을 사용할 것인지 역시 중요합니다. 새삼 느끼는 것이지만 비디오 연구는 참으로 고려할 게 많네요.
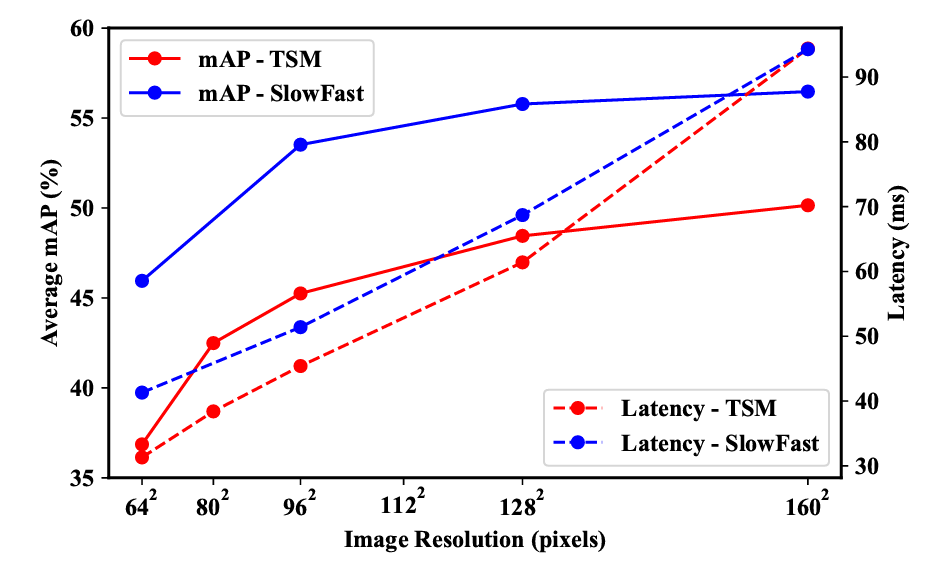
결론적으로 말씀드리면 이미지 해상도를 높이면 당연히 성능이 증가하지만 다른 부분에서의 Cost는 증가합니다. Latency가 거의 성능의 이득만큼 증가하기 때문이죠. 저자가 얘기하는 핵심은 이미지의 해상도보다는 적절한 Video Encoder와 Detection Head의 선택이 더 중요하다고 얘기합니다.
TSM Encoder에서 160 by 160의 이미지를 사용했을 때의 성능이 SlowFast에서는 96 by 96에 추월되기 때문이죠. 뭐 논문에서 벤치마킹을 할 때는 동일한 비교를 하기 위해 다른 방법론들과 동일한 해상도와 Encoder를 써야겠지만 이를 가져가다 어떠한 플랫폼에 사용할 때는 고려할만한 요소가 될 것 같습니다.
Comparison with State of the art Methods
- Detection Performance
마지막으로 빠질 수 없는 벤치마킹입니다.

우선 가운데 기준선을 기준으로 위에는 E2E가 아닌 방법론들이고 아래는 E2E인 방법론들입니다.
- 저자가 제안하는 베이스라인이 SOTA를 달성했습니다. 저자가 간접적으로 얘기하지만 이는 강력한 Video Encoder와 Detection Head 덕분이라고 합니다. 아마 SlowFast가 워낙 성능이 좋아서 이득을 받은 것 같지만 본 논문의 main contribution은 아니니 저자도 간단하게만 언급하고 넘어갑니다. 아마 다른 방법론들도 SlowFast Encoder 쓰면 저 Baseline 성능은 넘을 수 있지 않을까 예상을 해봅니다..
- 다음으로 저자는 Optical flow를 쓰지 않아도 Detection을 잘할 수 있다고 주장합니다. 이 주장의 근거는 AFSD-RGB의 성능이 E2E가 아닌 대다수의 방법론들보다 더 높은 성능을 보여주기 때문이라 얘기합니다. 하지만 이는 조금 과장된 주장이라고 생각이 드는 게 당장 테이블만 봐도 flow를 사용하는 게 대체적으로 성능이 다 좋습니다. AFSD도 flow를 쓰면 성능이 boosting 되는 것 역시 사실입니다. 개인적으로 RGB frame 정보만으로는 motion 정보를 capture 하는데 한계가 분명하기 때문에 optical flow는 필수 불가결하다는 것이 저의 개인적인 생각입니다.
- Computation Cost
이번에는 저자가 중요하다고 얘기한 Computation cost입니다. 분명히 Temporal Action Detection은 application level에서 활용될 여지가 높은 연구 분야이기 때문에 단순히 성능만을 추구하면 안 된다고 저자는 주장했습니다. 따라서 Computation cost에 대한 실험 역시 제공합니다.
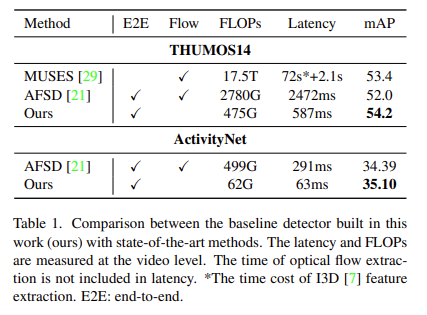
리뷰 초반에 설명했지만 다시 하도록 하겠습니다. 저자가 제안하는 베이스라인 방법론이 다른 SOTA 방법론들에 비해 훨씬 적은 FLOPS와 Latency를 가집니다. 본문에는 나와있지 않고 Supplementary에 그 이유가 나와있는데 요약하면 다음과 같습니다.
(1) 우리는 더 작은 이미지 해상도를 사용했기 때문이다.
(2) Convolution 방식이 다르다고 합니다. 이 부분은 정확히 이해를 못 해서 자세히 설명은 하지 않겠습니다.
(3) 우리가 사용한 Encoder인 SlowFast와 Head인 TadTR이 다른 방법론들에 비해서 효율적으로 설계가 되었다.
그런데… 이것 역시 저는 Encoder의 역할이 크다고 생각이 듭니다. 더 작은 이미지 해상도를 사용해도 성능이 좋았던 이유는 SlowFast의 도움이 컸을 것입니다. 그리고 SlowFast는 성능도 좋지만 FLOPS도 I3D보다 2배 이상 낮기 때문에 Cost도 줄일 수 있네요. 아마 MUSES나 AFSD도 SlowFast로 Feature를 비슷해지지 않을까 생각이 듭니다.
Conclusion
우선 저자가 설명하는 Limitation은 다음과 같습니다. End to End 방식의 장점을 쭉 설명했지만 이는 GPU 메모리가 많은 곳에서만 연구가 용이하다는 한계가 있습니다. 당연히 Video Encoder까지 학습에 추가가 되니 더 많은 GPU 메모리가 필요하겠네요. 따라서 저자는 future work도 더욱 보완적인 end-to-end feature를 고안하는 것이 목표라고 합니다.
이렇게 폭넓은 분석을 제시하는 논문은 처음 읽어보는 것 같습니다. 정말 많을 것을 배울 수 있었던 것 같네요. 코드가 공개가 안됐는데 어서 빨리 공개가 돼서 저자의 코드 디테일을 조금 참고하고 싶네요.
이상으로 리뷰 마무리하도록 하겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰를 읽으니 해당 task가 굉장히 활발하게 연구되고 있다는 것이 느껴지네요.
benchmark 성능 표에서 저자도 언급했듯 각자 사용한 encoder에 따라 성능 차이도 클 것 같은데 TadTR에만 SF R50을 encoder로 사용한 이유가 있나요?
다른 end to end 방식을 head로 사용하고, SF R50을 encoder로 사용하여 측정한 mAP와 computational cost 비교 분석은 없는지 궁금합니다.