소개
본 논문[pdf]은 non-parametrically 한 방식으로 unlabeled image의 psuedo label을 생성하여 학습하는 semi-supervised learning논문이다. labeled image로 구성된 support samples를 이용해 pseudo label을 생성하고 이를 학습에 사용하여, labeled pair를 직접적으로 사용하지 않아 적은 labeled 데이터에 대한 과적합을 막고 효율적으로 학습을 진행한다.
방법론
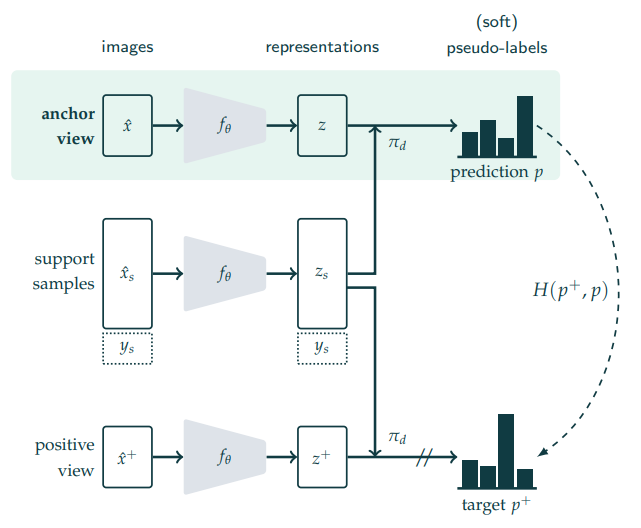
방법론은 SwAV와 비슷하다. 이미지 x(anchor)에 image transformation(multicrop)을 통해 다른 view(positive)를 만들고 두 이미지를 인코딩 벡터가 유사해지도록 학습한다. 이때 PAWS는 psuedo labeling을 통해 object function을 구성하며, pseudo label을 할당하는 방식이 조금 특이하다. 기존 방법론은 일반적으로 classification 문제를 기반으로 각 class 일 확률 예측한 확률 벡터를 이용해 labeling을 진행하였다. 그러나 해당 방법론은 labeled data로 support samples을 구성한 후 해당 support samples들을 마치 cluster point 처럼 사용하여 각 샘플 간의 유사도 를 통해 pseudo label을 생성한다. 이후 anchor와 positive의 pseudo label이 가까워지게 학습하여 semi-supervised learning을 진행한다. 위와 같은 방식으로 pre-training을 진행한 후, labeled data만을 이용하여 fine-turninnig을 진행했다고 한다. 기존 semi-supervised 방법론의 경우 일반적으로 fine tuning을 진행하지 않았기 때문에 실험에서는 해당 과정을 진행하지 않은 성능 또한 리포팅하였다.
실험
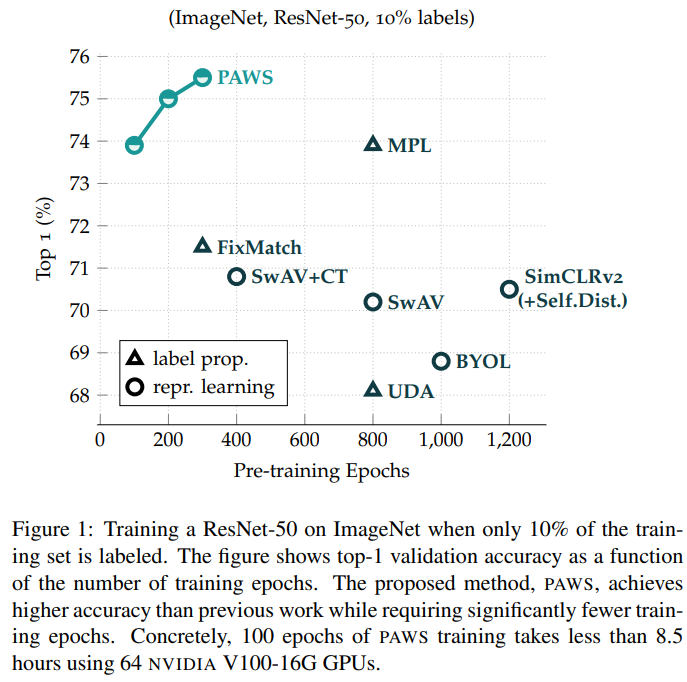
실험1) 기존 방법론과의 비교
실험 1을 통해 기존의 방법론과의 성능 비교를 진행하였으며 fine turning을 진행하지 않더라도 기존 방법론에 대해 경쟁력 있음을 보였으며 특히 학습 epoch수가 적어 매우 효율적임을 알 수 있다.
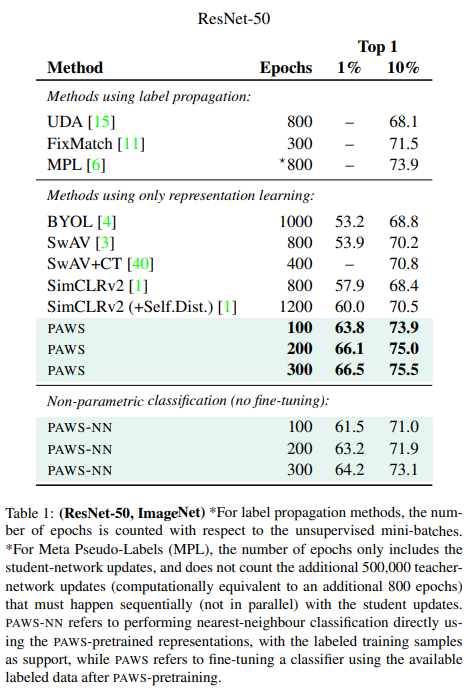
실험2) 다른 ResNet architecture의 사용
또한 다른 아키텍처를 feature extract을 위해 사용하였을때도 기존 방법론에 비해 경쟁력 있는 성능을 보이며 아키텍처에 대한 의존성을 갖는 학습방법론이 아님을 보였다.
Loss의 구성과 ablation study
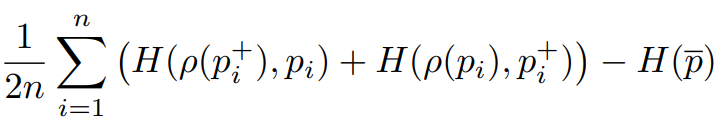
목적함수는 2개의 term이 -로 연결되어 있다. 위의 식에서 좌측이 pseudo label을 유사하게 하기 위한 목적함수이고, 우측의 함수는 예측된 pseudo label의 entropy 를 maximize하여 mode collapse를 막기위한 term으로 ME-Max regularization term이다. 해당 term에 대한 ablation study는 아래와 같다.
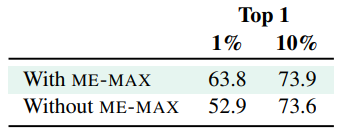
좋은 리뷰 감사합니다! 정말 언급해주신 대로 SwAV와 비슷한 방법론을 사용하는 것 같습니다.
혹시 해당 방법론을 베이스라인으로 잡는데에는 리소스적인 한계는 문제 없을까요?
그리고 해당 방법론은 학습할 때 labeled-data를 support sample로 구성한다고 하셨는데 이것은 어떻게 설계되는지 궁금합니다.
문제가 있지만 기존 방법론보다 적은 편 입니다
학습 시 batch내 포함된 labeled data를 모두 support sample로 씁니다
리뷰 감사합니다. non-parametrically 한 방식이 정확히 무엇을 의미하는 것인가요?
pseudo label을 생성하기 위해 모델을 이용한 것이 아닌
유사도 함수를 이용해 유사한 labeled data와 유사하게 피처 임베딩 하도록 학습 한 것 입니다