이번에 제가 리뷰할 논문은 6DoF 자세추정으로 단일RGB카메라만을 사용하여 6DoF pose를 추정하는 그런 논문입니다.
해당 논문은 2018 ApolloScape challenge에서 1등을 차지하였다고 합니다.

해당 데이터셋에서는 79개의 자동차 모델에 대한 3D 모델링 정보가 주어집니다. 개인적으론 자동차같은 물체는 클텐데 object mesh파일의 용량이 너무 커서 computation time을 증가시키는 것은 아닌지 궁금하네요.
인도어 상황에서 6DoF 논문들을 많이 읽어보다가 자율주행과 같은 아웃도어 상황에서는 어떠한 차이가 있을까 궁금하여 읽게 되었습니다.

먼저 해당 논문에서 제시하는 문제는 기존의 6DoF 를 RGB영상만으로 regression하는 경우에는 rotation과 class를 먼저 예측한 다음에 translation을 예측하는 방식으로 2스텝을 거치며, 이 과정에서 translation을 계산할때 앞에서 rotation과 class를 계산할때 생긴 error가 누적된다고 합니다.
구체적으로 기존에는 3D object의 센터좌표가 2D로 projection 되었을때, 2D상에서 bbox의 센터에 해당 센터좌표가 project된다고 가정을합니다.
그리고 object의 class와 rotation vetor를 올바르게 추정했다는 가정하에 translation에 대해서 계산하게 됩니다.
그러나 이러한 방식은 error가 이미 누적된 상태에서 translation을 구해야 하므로 좋지않은 결과를 가지고 왔다고 주장을하고 있습니다.
그래서 저자들은 이러한 문제를 해결하기위해서는 rotation과 translation을 동시에 해야함을 주장하였고, 자신들이 알기로는 monocular camera를 이용해서 rotation과 translation을 동시에 하는 것은 최초라고 주장합니다.
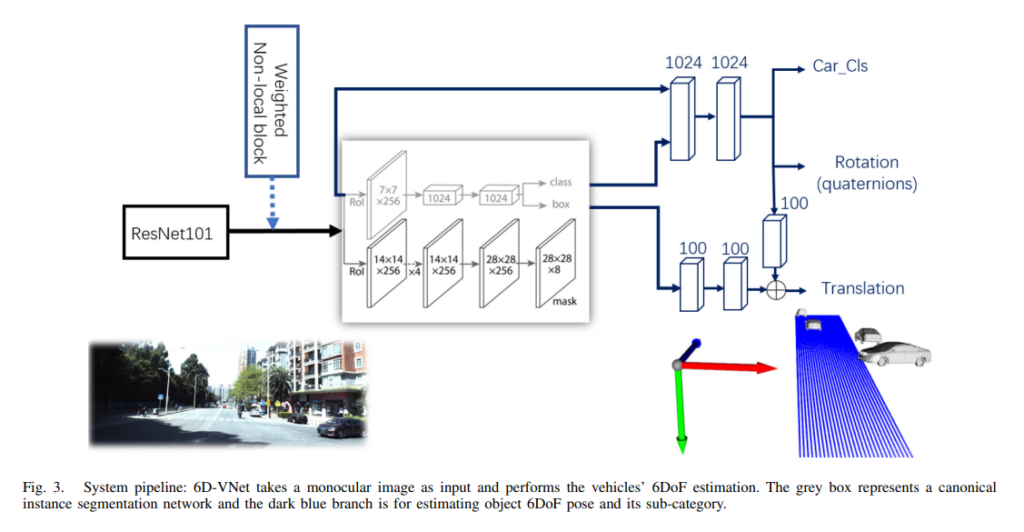
그렇게 저자들이 주장한 파이프라인은 위와 같습니다.
가운데 네모블록은 instance level로 segmentation을 해주는 네트워크와 RCNN계열로 detection을 해주는 블록이며 파란색선들은 해당 네모블록에서 나온 피쳐들로 6DoF pose와 classification을 하는데 사용됩니다.
특징으로 본다면, 기존에 2스텝으로 진행하면 단안카메라 6DoF pose estimation과 달리 해당 논문에서는 Rotation과 translation을 동시에 regression하였습니다.
일반적인 6DoF 방법론들과 마찬가지로 rotation을 representation하는 방법으로는 쿼터니온을 사용하였으며, 이는 Euler angle을 사용하면 발생할 수 있는 짐벌락 문제를 예방하기 위함입니다.
짐벌락문제는 김지원 연구원이 이전에 PoseNet을 다루면서 설명한적이 있는데 , 간단히만 말씀드리자면, Euler Angle에서는 x,y,z 축 회전으로 rotation을 나타냅니다. 그리고 x, y, z 에 대한 회전은 동시가 아닌 순차적으로 이루어집니다. 이때, 회전을 하다가 축이 겹쳐버리는 경우에 3자유도에서 2자유도로 자유도 1개가 사라지는 현상이 발생하며, 이를 짐벌락 문제라고 이야기합니다. 이를 해결하기위해 6DoF Pose estimation에서는 쿼터니온을 주로 사용합니다.
다시 파이프라인으로 돌아와서 논문에 대하여 이야기를 이어가자면, 사실 파이프라인은 그림이 직관적으로 잘 나타내주고 있습니다. 다만 그림상에 Weighted Non-local block이라는 부분이 무엇인지 궁금하실 것 입니다.
사실 내용적인 면으로는 저자도 레퍼런스를 걸어두고 디테일한 설명이 빠져서 리뷰에서도 설명해드리긴 힘들거 같은데요. 컨셉적인 면으로는 local한 영역에 attention을 부여하는 방식이라고 합니다. (softmax로 attention을 뽑아내는거 같네요)
기본적으로 저자는 해당 블록을 사용하면 아래와같은 효과가 있다고 주장합니다.
(i) non-local operations capture long-range dependencies directly by computing interactions between any two positions, regardless of their positional distance;
(ii) non-local operations maintain the variable input sizes and can be easily combined with other operations;
(iii) our proposed weighted operation renders it possible to associate the output maps with self-attention mechanisms for better interpretability.
글쎄요… formal 하게 잘 포장해두었는데 사실 여기까지만 들어보면 해당 block이 local한 영역에 주는 attention의 일종인데 사실 모델레벨에서 attention을 adaptive하게 주는것을 논리적으로 잘 설명하기가 쉽진 않은거 같습니다. 실험적으로 잘나오고 거기에 의미부여를 하는 느낌이 어느정도 있습니다.

그래서 저자도 이러한 부분을 의식해서 위에처럼 visualization 하여서 결과를 보여주었습니다. 역시 transactions 논문이라 다르네요.
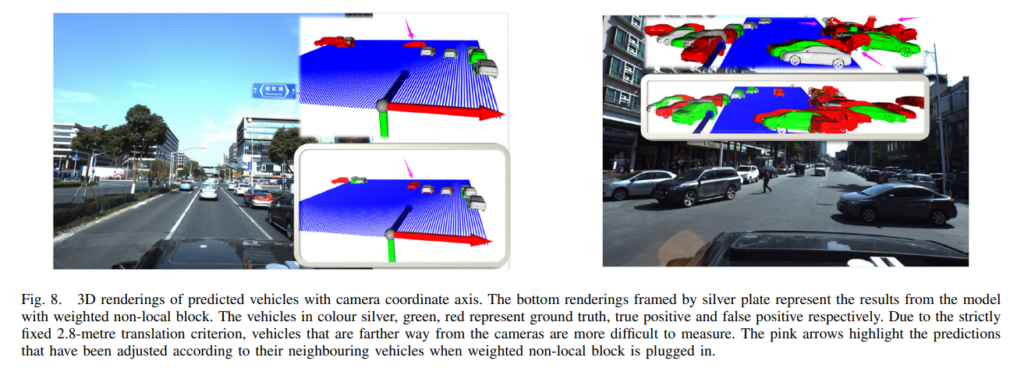
6DoF pose를 구하였으니 위와같이 랜더링도 가능합니다.
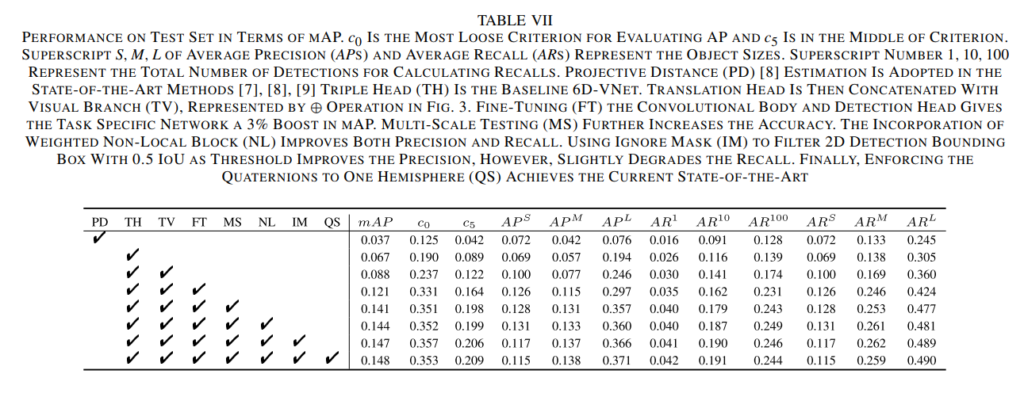
결과는 위와 같습니다.
음… 아마도 이제 앞으로는 쭉 6DoF 쪽이나 센서 구성논문 같은걸로 리뷰를 할 거 같은데요. 이번에는 특이하게 6DoF에서도 indoor아닌 자율주행쪽 논문을 맛보기로 읽어보았습니다. 사실 이번 주에 스케쥴이 너무 많이 겹쳐서 자율주행쪽으로 가벼운 마음으로 읽은논문이었는데 수식적인 내용이 많이 나와서 절대 가볍진 않았네요…(리뷰에 포함 못한 점 양해 부탁 드립니다) 어찌저찌 말이 길어지게 되었는데 리뷰 읽어 주셔서 감사합니다.
재밌는 논문인 것 같네요.
몇가지 궁금한 점이 있습니다. 차량의 외관은 굉장히 다양하게 구성되어 있습니다. 그럼 mesh map도 기종 별로 구성된 상태에서 영상 정보와 매칭된 데이터 셋인지 궁금하네요. (물체 측면에서의 6DoF와 동일한지에 대한 질문)
다른 세세한 질문은 아래와 같습니다.
1. 해당 논문에서 사용된 데이터 셋이 무엇인지
2. 클래스 구성이 차량 한대 뿐인지
3. Mesh map에 포함된 차량의 기종은 단일인지 궁금합니다.
본문에 젤 앞에 인용한 피규어4를 참고하시면 1~3번 질문에 대한 해답이 되리라 생각합니다.