최근에 읽고 있는 논문 시리즈의 마지막(?) 논문입니다. 최근 물체 중심 이미지 검색 논문들을 많이 보고있는데요. DELF → DELG → DOLG(Deep Orthogonal Local and Global feature fusion model)로 이어지는 논문입니다.
Introduction
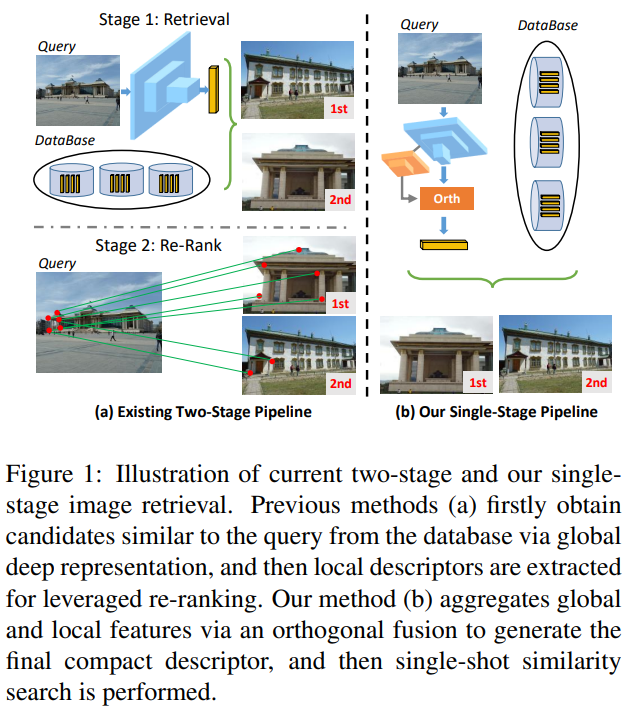
기본적인 목적 자체는 이전 논문들과 동일하므로, DOLG에서는 무엇이 추가되었는지를 알아보도록 하겠습니다. 말씀드렸다시피 이 논문들이 DELF→DELG→DOLG 순으로 나왔는데요. “DELF→DELG”에서는 end-to-end가 추가된 점이 가장 큰 발전입니다. DOLG에서는 two-stage 방법론을 one-stage로 변경한 것이 가장 큰 차이점입니다.
기존의 2-stage 방법론은 [그림 1]의 왼쪽 그림과 같이 먼저 Retireval을 수행한 다음에, keypoint를 매칭하는 방법으로 re-rank를 수행해서 검색을 수행합니다. 이제 DOLG는 이 re-rank 과정을 없애면서도 좋은 성능을 보이게 되었습니다.
어쨋든 contribution으로는 아래 3가지를 말합니다.
- Compact한 image descriptor를 만들 수 있는 orthogonal global and local feature fusion framework 제안 (One-stage)
- 특징적인 local feature를 추출하기 위한 multi-atrous convolution layers와 self-attention module
- SOTA
Methodology
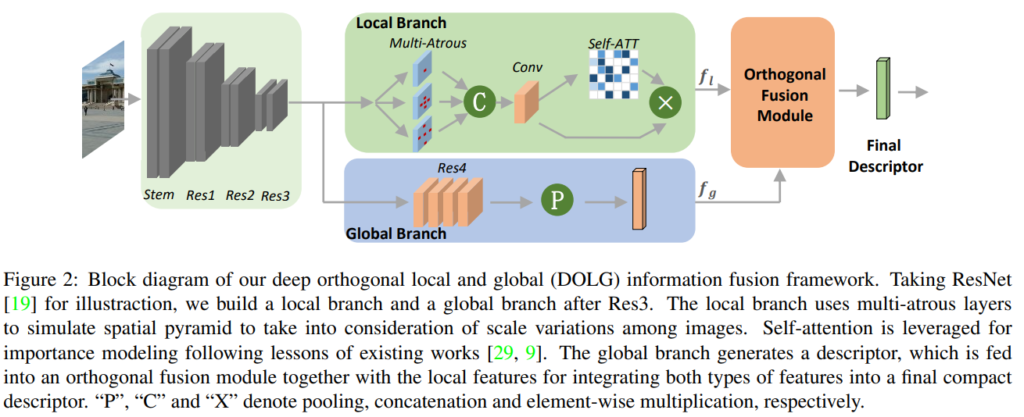
구조 자체는 매우 간단합니다. [그림 2]와 같은 구조를 가지고 있는데요. Loss는 DELG와 유사하게 ArcFace Loss만 사용합니다. 크게보면 global branch와 local branch를 통해 뽑혀진 global feature와 local feature가 orhogonal fusion module을 global feature에 통합된다고 보시면 됩니다. 그럼 순서대로 보겠습니다.
Global branch
Global branch는 기존의 Resnet의 구조에서 global average pooling을 GeM pooling으로 변경된 것 이외에는 동일합니다.
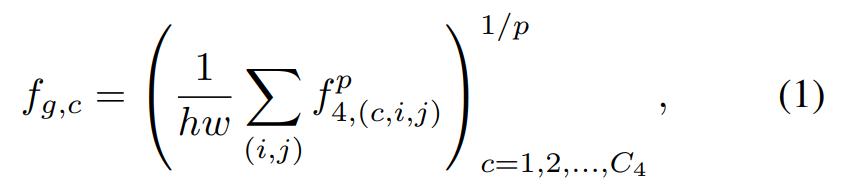
GeM은 [수식 1]에서 확인할 수 있습니다. 이미지 관련 모델에서 많이들 사용해서 어떤 효과가 있는지 더 찾아보니, 일반적으로 MAC이나 R-MAC같은 방법론들보다 더 성능이 좋고, global max pooling과 average pooling의 중간 정도의 효과를 가진다고 합니다.
Local branch
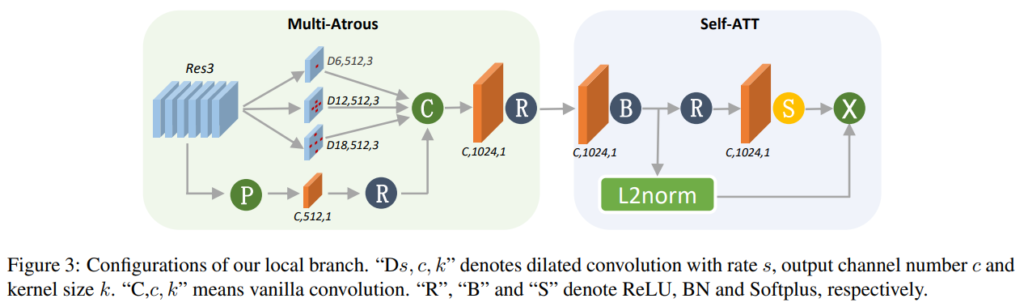
Local branch는 Global branch와 다르게 Resnet의 세번째 블록의 output을 입력으로 사용합니다. 이 Local branch는 [그림 3]에서 확인할 수 있듯이, Multi-Atrous라고 적힌 부분과 self-attention으로 구성되어 있습니다. Multi-Atrous 같은 경우에는 서로 다른 spatial receptive filed를 가지는 feature를 얻기 위해 3개의 레이어로 구성되어 있고, 각각 나온 feature를 최종적으로 conv layer를 태워서 사용합니다. 그리고 self-attention module은 중요한 local feature point를 선택하기 위해 있습니다.
Orthogonal Fusion Module
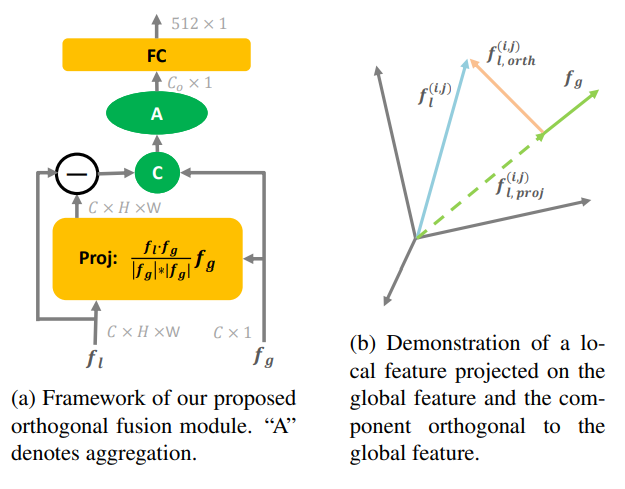
[그림 2]에서 확인할 수 있듯이 orthogonal fusion module의 입력으로 local feature와 global feature를 사용합니다. 이 모듈은 [그림 a]와 같이 구성되어 있는데요, 최종적으로는 local feature를 global feature로 projection 하는 것이 목표입니다.
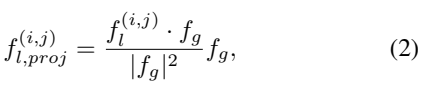
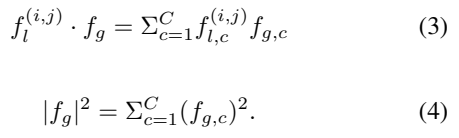
Projection은 [수식 2]를 통해 수행됩니다. 분모/분자에 해당하는 수식은 각각 [수식 3]과 [수식 4]를 보시면 알 수 있습니다. 수식이 좀 복잡해 보일 수도 있겠지만, orthogonal projection을 검색하셔서 수식을 보시면 달라진 것이 없습니다. 그 부분 감안하시고, 서로 다른 두 벡터. 여기서는 local feature와 global feature를 하나의 descriptor로 만들기 위해서 orthogonal projection으로 local feature를 global feature로 투영시킨다고 생각하면 될 것 같습니다.
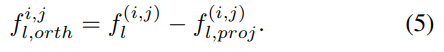
그래서 이 투영이 실제로 어떻게 되는지 [그림 b]와 [수식 5]를 통해 보여줍니다. projection된 vector에 orthogonal fusion을 취하게 되면 local feature와 동일한 값을 나타내는 것을 보여줍니다.
Training Objective
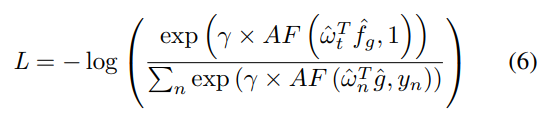
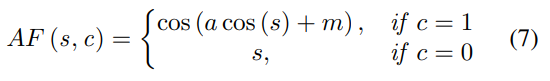
Loss는 DELG에서와 동일하게 ArcFace Loss를 사용합니다. 이 Loss는 L2 정규화된 N개의 예측값을 만들어내도록 학습합니다. 이전에도 간단하게 설명했었는데요, 이 ArcFase Loss는 Softmax 대비 좀 더 분별력 있는 feature를 만들수 있다고 합니다. End-to-End만 적용된 DELG에서는 2-stage 구조 때문에 3개의 Loss function을 사용했지만, 여기서는 one-stage의 간단한 구조기 때문에 이러한 부분에서도 이점을 본 것 같습니다.
Experiments
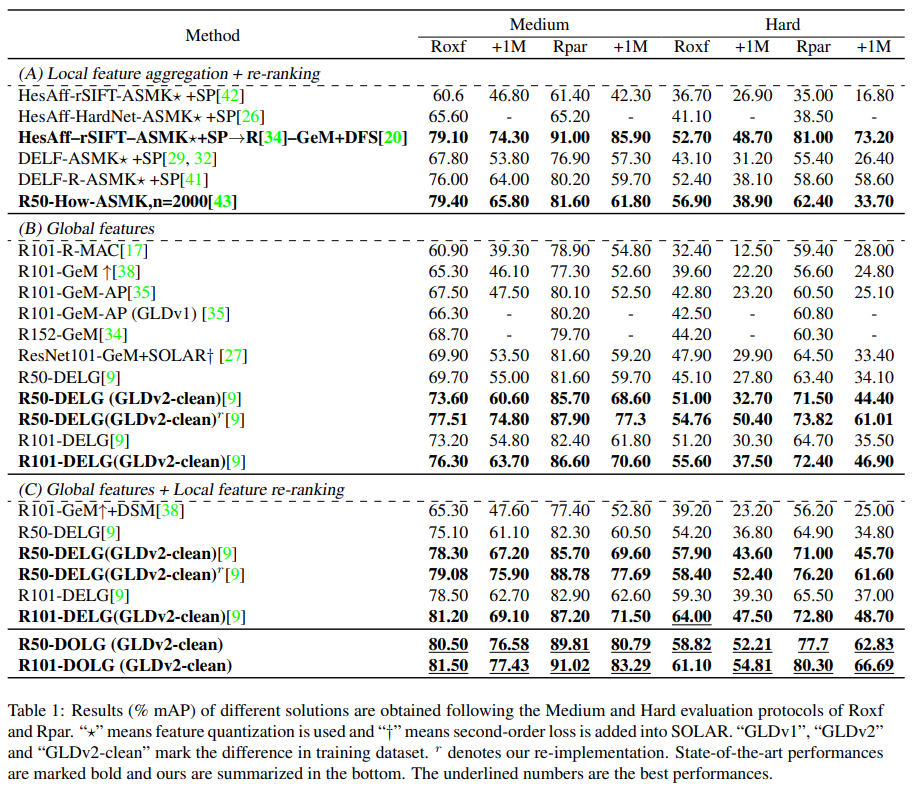
저도 모든 방법론을 알지는 않아서 중점적으로 볼 부분은 DELG와의 비교를 보면 좋을 것 같습니다. 특히나, “(C) Global features + Local featture re-ranking”의 DELG 방법론과 DOLG를 비교해보면 되는데요. reimplementation 성능이 오리지널 코드보다 전반적으로 성능이 높다는 점을 감안하고서 전반적으로 성능이 높은 것을 볼 수 있습니다. Roxf 데이터셋에서는 성능이 낮은데 그 이유가 없어서 조금 아쉽네요. 추가적으로 distractor 이미지가 추가되었을 경우 성능 차이가 더 커지는 경향성을 볼 수 있는데요. 이러한 부분에서 기존 방법론 대비 좀 더 robust한 feature가 만들어졌음을 볼 수 있습니다.
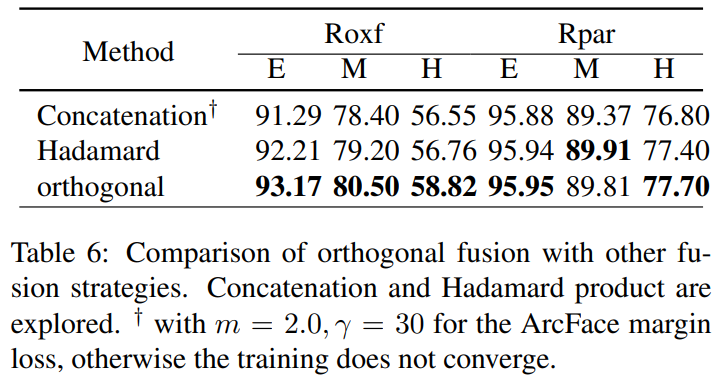
그리고 실험이 많은데… 이 논문에서 중점적으로 볼만한 부분은 orthogonal fusion이 성능에 영향을 미치는가입니다. local feature와 global feautre를 대충 합쳐도 이거 성능 오르는거 아냐? 라는 질문에 대해서 3가지 방법 (concat / element-wise multiplication == Hadamard / orthogonal)을 실험했을 때 orthogonal 이 가장 성능이 좋았다고 합니다.
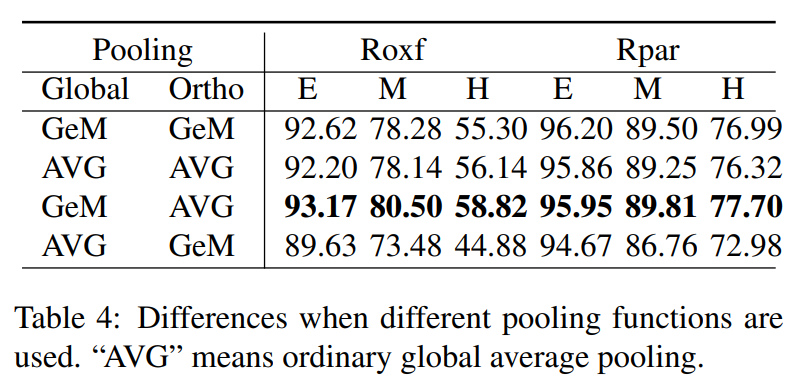
Pooling 레이어의 실험 결과도 함께 보여주고 있는데요. Global feature에서 논문 저자들이 주장한 부분이 잘 작동함을 보려면 가운데 두 성능을 비교해보면 됩니다. Global average pooling보다 GeM이 더 좋은 성능을 보이는 것을 볼 수 있습니다만 이 부분은 DELG에서도 똑같이 적용된 방법이라 특이한 부분은 아닌 것 같습니다.

마지막으로는 정성적인 결과인데요. 너무 체리피킹 아닌가 싶네요. 성능은 사실 1~2mAP 정도 차이가 나는데 Top10을 다 맞힌 경우랑 아닌걸 들고오니… 비교가 어렵지 않나 싶지만, 어쨋든 global feature로 retireval한 뒤에 local feature로 re-rank를 하는 것 보다 local한 정보들을 잘 찾아서 검색하는 것을 볼 수 있습니다.
Conclusion
학습 방법이 기존의 DELG 대비해서 많이 간단해지고, one-stage가 되었음에도 성능이 꽤 좋아서 잘 읽었습니다.
최근 이미지 검색 논문을 많이 읽으신 것으로 알고 있는데, 이미지 검색 분야에서는 서로 다른 뷰에서 촬영되어 이미지 상에서 상이한 모습을 나타내는 이미지 인스턴스를 식별하기 위해 어떤 방법들이 존재하나요?
다양한 각도의 이미지를 잘 식별하는 것이 결국은 검색 성능과 직접적인 영향이 있으므로 여러 방법이 있겠지만, DELF에서는 유의미한 keypoint를 attention을 통해 뽑아 local feature를 뽑는 방법을 선택했습니다. DELG에서는 이와 비슷하지만, 전반적인 시각적인 특성을 고려할 수 있는 global feature를 도입해서, 이를 통해 시각적으로 유사한 이미지를 검색하고, 포인트의 유사도는 local feature로 re-rank하는 방법론도 있습니다. DOLG는 이를 통합한 것이고요. 전반적으로 다른 뷰라고 한정지으면 공통적인 특징을 가지는 keypoint를 비교하는 방법으로 이미지를 식별하는 것 같습니다.