이번에 소개드릴 논문은 CVPR2022에 게재된 RFNet이라는 논문입니다. 해당 논문의 분야는 논문 제목에서도 확인하실 수 있듯이, Image Registration과 Image Fusion에 관한 논문인데, Image registration에 조금 더 초점이 맞춰졌다고 보시면 좋을 것 같습니다.
Image Registration?
논문 내용에 들어가기 앞서 Image Registration이란 무엇인가에 대해 간단하게 정리해보고자 합니다.(논문 내용에 관심있으신 분들은 아래로 내려가셔도 좋습니다.) 먼저 Image Registration은 김지원 연구원님이 예전부터 관련 분야에 관한 논문들을 리뷰로 작성해주시고 계셔서 아시는 분들은 아시겠지만, 말그대로 두 영상의 정합을 맞추는 작업을 의미합니다.
2대 이상의 카메라를 사용하게 되는 경우에는 당연히 두 카메라에서 촬영된 위치가 아무리 가깝다고 하더라도 픽셀 별로 비교하게 될 경우 차이가 있을 수 밖에 없습니다.(즉 A카메라에서 촬영한 영상의 (x, y)픽셀과 B카메라에서 촬영한 영상의 (x, y)픽셀이 동일하지 않다는 것이죠.)
이것을 해결하는 과정이 Image Registration 작업이며 해당 분야에서 접근하는 방법은 매우 다양합니다. 일반적으로 하드웨어 관점에서 alignment를 맞추는 방식도 있으며(카이스트 데이터 셋에서 빔스플리터를 사용하는 예시), 카메라 캘리브레이션 과정에서 취득한 카메라 외부 행렬을 통한 변환, 또는 두 영상의 공통적인 특징을 찾아서 이를 통해 정합을 위한 부수적인 정보를 생성하는 content based image registration이 존재합니다.
content based image registration은 또 크게 SIFT와 같은 local keypoint&descriptor를 추출하여 homography를 계산하는 방법이 존재할 수도 있으며, 또는 optical flow와 같이 pixel-level에서의 flow map을 계산하는 방법등이 존재하게 됩니다.
당연히 이 둘의 장단점은 명확하다고 볼 수 있는데, 먼저 호모그래피의 경우에는 두 변환되는 이미지들은 모두 평면이라는 가정이 존재하여 설계된 행렬이므로 실제 세상의 기하학적인 요소를 다루지 못해 영상 속 모든 물체에 대하여 정합을 맞추지 못한다는 단점이 존재합니다.
그래서 픽셀레벨로 alignment를 수행할 수 있는 flow 기반의 registration 방법론이 더 우세하다고 판단되지만 픽셀레벨로 학습을 시키기에는 GT도 구하기 너무 힘들뿐더러 실제 inference 관점에서 네트워크가 Encoder 뿐만 아니라 Decoder까지 함께 필요하게 되니 속도 측면에서 좋지 못할 것이라는 예상이 듭니다.
Intro
해당 논문에서는 Image Registration 뿐만 아니라 Image Fusion에 대해서도 다루고 있습니다. Image Fusion이란 쉽게 말해 서로 다른 두 도메인(또는 스펙트럴)의 영상에서 서로의 장점에 해당하는 부분의 정보는 살리고 그 외에 불필요한 정보들은 지워버리는 분야를 의미합니다.
저희 연구실에서 쉽게 생각할 수 있는 예시로는 Thermal image는 조도에 강인하지만 텍스쳐 정보 등 충분한 정보가 부족한 반면 RGB는 그와 반대되는 정보들을 모두 가지고 있죠. 그래서 이 두 영상의 정보를 적절히 조합하여 조도에도 강인하면서 텍스쳐 정보등도 잘 담고 있는 그럼 영상을 생성하는 그런 것이라고 보시면 될 것 같습니다.
아무튼 이러한 image fusion은 위에서 설명한 내용을 통해 아시겠지만 사전에 두 스펙트럴의 영상이 Image registration 과정이 선행되어야만 합니다. 두 영상이 misalignment가 있다면 아무리 fusion이 잘 된다고 하더라도 물체가 겹쳐보이거나 하는 문제 등이 발생하겠죠.
하지만 저자가 말하기로는 이전의 image fusion 방법론들은 모두 입력 데이터가 align이 맞다라는 가정하에 image fusion에만 집중하였다고 합니다. 하지만 Image fusion이 Image Registration 작업에도 충분히 도움을 줄 수 있기 때문에 이 둘을 한번에 진행하는 전체 framework가 필요하다고 주장하죠.
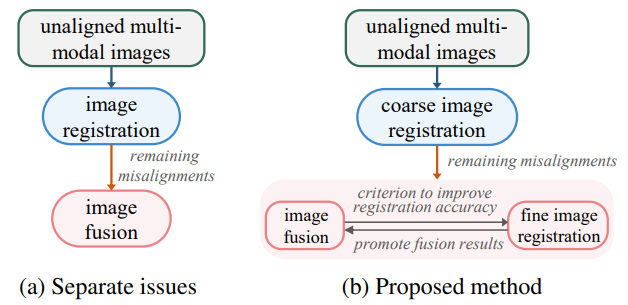
즉 기존의 연구들은 위의 그림a와 같이 image regisration과 image fusion을 따로 수행하였는데, 그것이 아니라 b처럼 Image registration과 fusion을 동시에 학습시킴으로써 이 둘의 성능 향상을 기대해볼 수 있다는 것입니다.
그렇다면 저자는 왜 image fusion이 image registration에 도움이 된다고 주장하는 것일까요? 저자가 말하는 이점은 크게 3가지가 있는데, 가장 먼저 image fusion은 두 도메인으로부터의 정보의 다양성을 완화시킬 수 있다고 합니다.
이 말이 무슨 말이냐면, 사실 Image registration 자체가 하나의 도메인에서 동작하는 것 조차도 그리 쉬운 일은 아닌데, 서로 다른 도메인(e.g. RGB & Thermal)에서는 서로 가지고 있는 정보가 다르기 때문에 둘의 공통점을 찾아 registration하는 content based registration 방법론은 상당히 어렵습니다.
이러한 관점에서 Image Fusion이라는 분야 자체는 두 도메인의 정보에 대해 너무 과잉되는 정보들은 제거하고 한쪽이 부족한 정보는 다른쪽에서 살리는 등의 분야이기 때문에 Registration 작업을 수행하는데 있어서 큰 도움이 될 수 있다고 말하는 것 같습니다.
그리고 두번째로는 Image Fusion이 잘되기 위한 선행 조건으로 Image Registration이 들어간다는 점입니다. 아까 위에서도 설명드렸다시피 Image Fusion에서는 사전에 입력 데이터들은 registration이 되었다는 가정으로 진행한다고 했었습니다.
즉 이 말은 Image Fusion의 결과 값이 부정확하다고 하였을 때 이를 Registration이 잘 되지 못했다는 하나의 평가 요소로 사용할 수 있다는 것입니다. 저자는 특히 Fusion 결과 영상 속 gradient가 매우 dense하게 나오는 상황등을 예시로 들었는데, 만약 Image Registration이 안된 영상으로 fusion을 하게 되는 경우에는 동일한 물체에 대해 다른 물체로 판단하여 두 도메인의 정보를 모두 보여버리는 상황(e.g. RGB 속 물체와 Thermal 속 물체가 겹쳐서 찍혀버리는 경우)가 발생할 수 있으며 이 경우에는 gradient가 상당히 촘촘하게 나오게 될 것입니다.
이러한 정보들을 registration 네트워크에 feedback 형식으로 반영을 할 수 있다면 Image Registration 결과를 좋게 할 수 있지 않을까 라는 것이 저자의 주장입니다.
Overall Framework
그럼 전체적인 흐름에 대해서 한번 살펴봅시다.
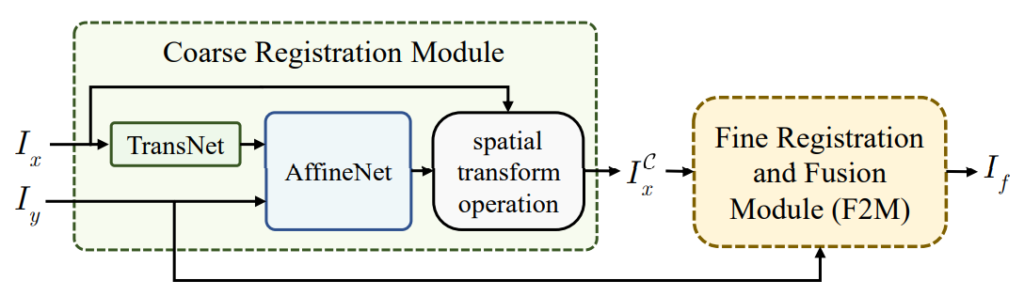
그림1은 저자가 제안하는 RFNet의 전체 파이프라인을 나타낸 것입니다. 먼저 Coarse Registration module을 통해 글로벌한 영역에 대하여 image registration을 수행하게 됩니다. 이렇게 warping된 I^{C}_{x}와 target image [/latex] I_{y}[/latex]가 서로 image fusion 및 registation을 수행하게 됨으로써 local 영역에 대한 registration까지 진행되게 됩니다.
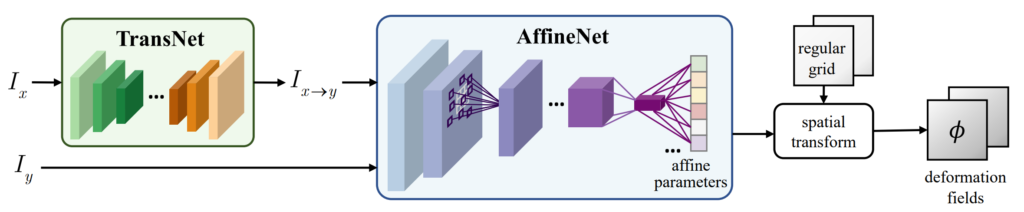
TransNet
먼저 그림2. Coarse Registration Module 속 TransNet에 대해서 살펴보도록 합시다. 해당 네트워크는 쉽게 말해서 x2y translation을 수행하는 네트워크라고 보시면 될 것 같습니다.
즉 AffienNet을 통해 x에서 y로 registration을 수행하기 전에 I_{x}를 I_{y}로 변환해주는 작업을 수행하는 것이죠.
아무래도 바로 I_{x}, I_{y} 입력을 넣어서 Affine matrix를 구하는 것보다는 최대한 x,y 두 도메인이 유사해지도록 입력을 변환시킨 다음 affine을 구하는 것이 더 좋다고 생각이 들 수는 있겠죠. 이때 TransNet은 일반적인 Image Translation network처럼 Encoder-Decoder 순서로 이루어져 있습니다.
저자는 인코더를 통해 I_{x}에 대한 content 정보를 추출한 후 이를 다시 디코더에 태움으로써 y 도메인으로 변환시키고자 합니다. 그러기 위해서 저자는 TransNet 학습을 위하여 다음과 같은 모델 구조를 사용합니다.
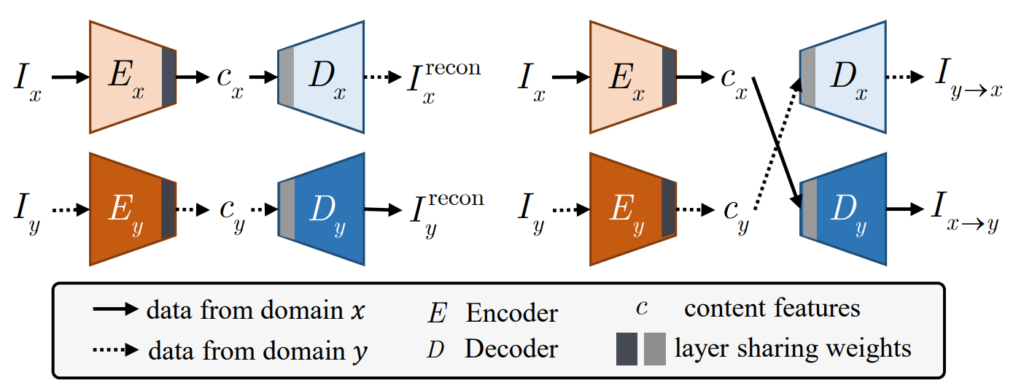
여기서 c_{x} 는 x이미지를 Encoder에 태웠을 때 발생하는 output 값으로 x이미지의 컨텐츠 정보를 담고 있다고 생각하시면 됩니다. 그리고 저자는 실제로 content 정보를 담게 하기 위해서 각각 다른 도메인의 인코더와 디코더를 나눈 후 한번은 동일한 도메인의 인코더와 디코더를 사용하는 방법을, 또 다른 방법으로는 다른 인코더와 디코더를 활용하는 방법으로 학습을 진행합니다.
예를 들어서 I_{x}를 x도메인의 인코더인 E_{x}에 태워서 나온 c_{x}는 x도메인의 디코더 D_{x}에 입력으로 들어가게 되면 입력 영상 I_{x}와 동일한 결과물 I^{recon}_{x}가 생성되게 됩니다.
반대로 c_{x}를 y 도메인의 디코더 D_{y}에 입력으로 넣게 될 경우에는 y 도메인의 정보가 담겨진 [/latex] I^{recon}_{y}[/latex]가 생성되게 되는 것이지요. 입력이 I_{y}일 때에도 위와 같이 동일하게 동작합니다.
이러한 과정을 통해 인코더는 최대한 영상의 컨텐츠를 살리려고 할 것이며, 디코더 과정을 통해 특정 도메인의 정보들이 담길 것이라는 내용인데 사실 이러한 컨셉은 제가 지난번에 소개드린 image manupulation 분야 논문들과 컨셉이 매우 비슷하기에 이해하는데 어려움이 없을 것이라고 판단됩니다.
아무튼 여기서 한가지 짚고 넘어갈 부분은 인코더의 마지막 레이어와 디코더의 시작 레이어 부분이 회색칠이 되어있는데, 이것은 어떤 도메인의 입력이 들어온다 하더라도 결국 인코더에서 타고 나온 결과 c가 동일한 임베딩 공간으로 투영되고자 해당 레이어 부분만 weight를 공유했다고 생각하시면 될 것 같습니다. (이러한 설명이라면 인코더는 납득이 되는데 사실 디코더에서는 굳이 layer를 sharing할 필요가 있는지 의문이 드네요.)
아무튼 이러한 TransNet의 학습 loss는 다음과 같습니다.
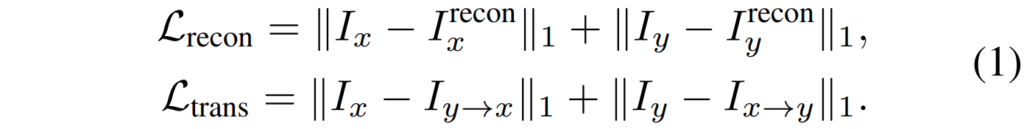
보시면 reconstruction loss와 translation loss로 이루어져있는데, reconstruction loss는 그림3 좌측편과 같이 입력 넣고 입력과 동일한 결과를 내도록 하는 학습 방식이고 trans loss는 그림3 우측처럼 translation 결과에 대한 비교라고 이해하시면 될 것 같습니다.
근데 사실 trans loss 부분이 이해가 가지 않는게 I_{x}와 I_{y \rightarrow x}는 분명 alignment가 맞지 않을텐데 어떻게하면 L1 loss로 비교가 가능한지가 잘 모르겠네요?(이놈들 이거 무슨 짓을 한거지…)
아무튼 TransNet은 위의 두 loss를 통해 학습이 진행된다고 합니다.
Affine Network
Affine Network는 엄청 단순합니다. TransNet에서 나온 x2y Image와 y image를 입력으로 3×3 affine matrix를 계산한다음 사전에 정의해둔 regular grid(1~H, 1~W크기 만큼의 값이 저장된 2ch tensor)에 곱하여 deformation field를 생성하게 됩니다.
이렇게 취득한 deformation field는 Spatial Transformer Network에 제안한 grid_sampling 기법을 통해 I_{x \rightarrow y} 이미지를 y 이미지와 coarse alignment가 맞도록 변환시킬 수 있으며 이렇게 변환된 이미지 I^{C}_{x \rightarrow y}와 I_{y}를 비교하는 방법을 통해 affine network를 학습시키게 됩니다.
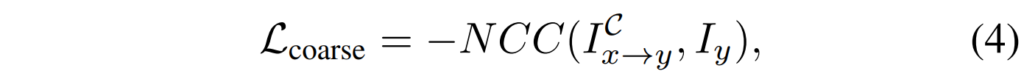
Affine network를 학습시키는 메인 loss는 위와 같습니다. TransNetwork처럼 L1 loss로 비교하는 것이 아닌 NCC 라는 Normalized Corss Correlation이라는 방법을 통해 loss를 계산하게 되는데 NCC는 다음과 같습니다.
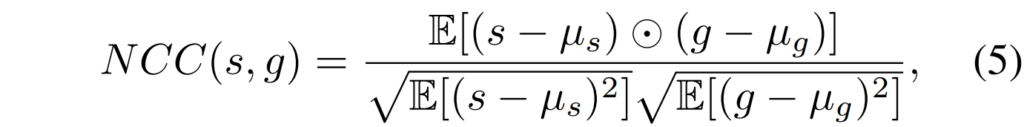
대충 각각의 영상에 대해 영상의 평균값들로 빼준 다음 이것들을 element-wise multiplication을 수행하는 것이 분자이며, 분모는 각 영상의 평균을 해당 영상끼리 빼주고 제곱*제곱근한 값에 대해 다시 평균을 계산하여 그 값들을 곱해주는 모습입니다.
참고로 E[x]는 다음과 같습니다.
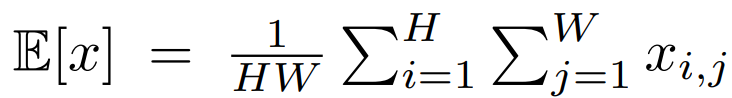
이렇게 학습을 통해 구한 deformation field는 translation이 된 결과가 아닌 I_{x}에도 적용되어 뒷단 네트워크의 입력으로 사용됩니다.
Mutually Reinforcing Fine Registration and Fusion Module(F2M)
이제 이 논문의 핵심인 image fusion과 fine registration 과정에 대해서 알아봅시다.
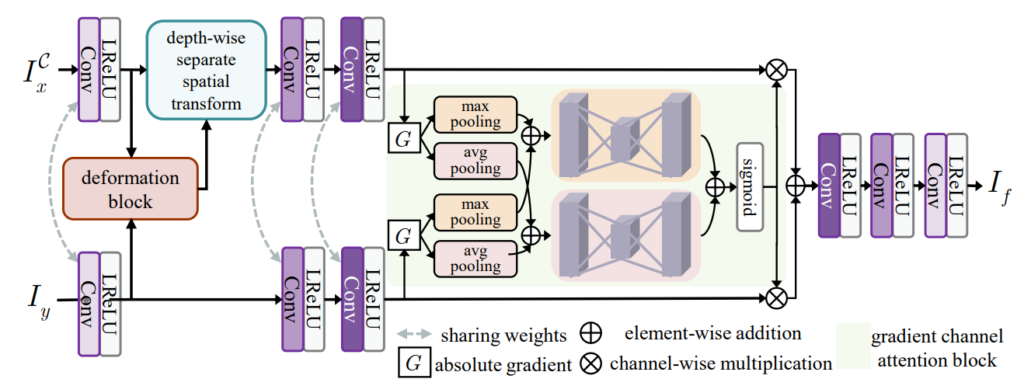
논문에서는 위의 과정을 크게 2가지로 나눕니다. 먼저 첫번째 phase는 image fusion을 위한 학습 과정을 수행하는데 해당 과정을 수행할 때에는 deformation field를 생성하는 등의 deformation block은 초기 파라미터만으로 deformation field를 생성하게 됩니다.(이 내용이 명확히 무엇을 의미하는지는 모르겠지만 아마 image fusion을 학습시키기 위해 deformation block 부분은 initial paramter만으로 꾸준히 진행된다는 것 같습니다.)
아무튼 Image fusion을 위한 레이어 및 모듈들은 다음과 같은 loss로 학습합니다.
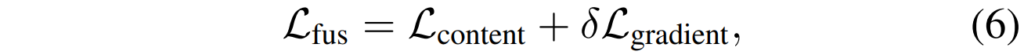
이때 L_{content}와 L_{gradient}는 또 다음과 같습니다.
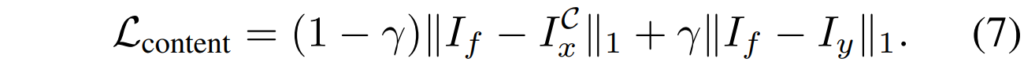
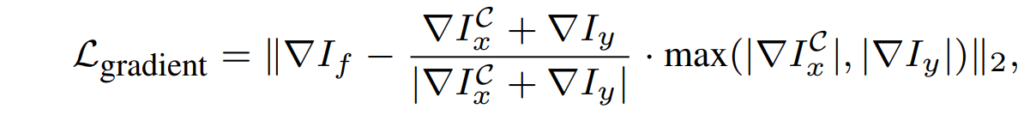
아마 해당 loss들은 Image Fusion에서 흔하게 사용되는 기본적인 loss라고 생각되어집니다. 역삼각형은 image gradient를 의미합니다.
아무튼 위의 loss를 통해 image fusion이 어느 정도 최적화가 되었다면 다음은 Image registration과 관련된 모듈들을 학습해야만 합니다. 이때는 deformation module을 학습해야하므로 image fusion과 관련된 모듈 및 레이어들은 freeze가 됩니다.
학습을 위한 loss 함수도 빠르게 설명드리겠습니다.
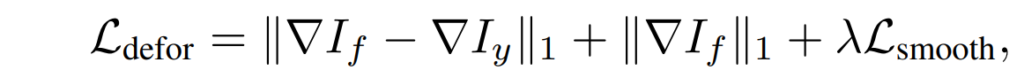
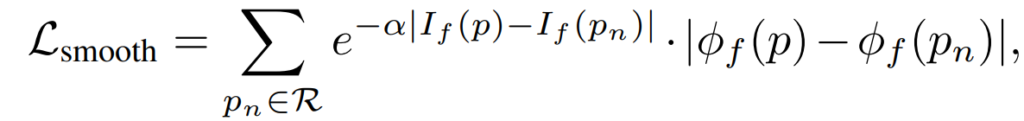
Fine Registration을 위한 loss term은 크게 3가지로 L_{defor}에서 보이는 항 3개를 의미합니다.
먼저 첫번째 항의 경우에는 fusion image와 reference image y의 gradient가 유사해야한다는 점인데, 이는 fused image가 분명 [/latex] I^{C}_{x}[/latex]에 대한 gradient 정보도 함께 가지고 있을텐데, 이때 deformation이 정상적으로 동작한다면 fused image는 y image(& x image)와 유사한 gradient 정보를 가지게 될 것이라는 것이 저자의 생각인 것 같습니다.
두번째 항은 만약 fused image 속에 misalignment가 있다면 x와 y 영상 속 정보들이 겹쳐서 보이기 때문에 gradient값이 크게 생성될 수 밖에 없으므로 이를 해결하기 위하여 fused image의 gradient가 적게 생성되도록 normalize하는 텀을 추가한 것입니다.
마지막은 이웃 픽셀들의 deformation 정보들은 유사할 것이다 라는 직관적인 컨셉을 반영한 것으로 flow map 자체를 smooth하도록 만드는 loss를 의미합니다.
Experiments
실험 섹션 다루고 리뷰 마치도록 하겠습니다.
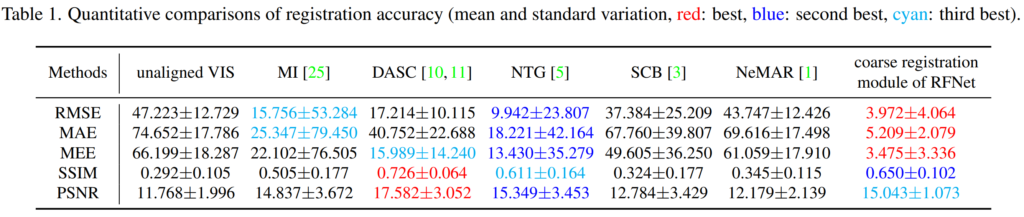
위에 표는 Image Registration 결과에 대한 정량적 표입니다. 제일 좌측은 alignment를 맞추지 않은 두 영상 즉 입력 영상들끼리 비교한 결과를 나타낸 것이고, MI, DASC, NTG, SCB는 딥러닝 기반 방법론이 아닌 traditional한 방법론을 의미합니다.
NeMAR이라는 방법론은 예전에 김지원 연구원님이 발표한 CVPR2020 Unsupervised multimodal image registration.. 관련 논문으로 유일하게? 딥러닝 기반 방법론입니다.
평가 요소로는 RMSE, MAE, MEE, SSIM, PSNR을 나타냈는데 먼저 RMSE와 MAE 그리고 MEE(median square error)의 경우에는 deformation한 source point와 target point 사이의 거리를 나타낸 것으로 보시면 될 것 같으며, PSNR과 SSIM은 말 그대로 영상 퀄리티를 비교하기 위해 deforamtion한 이미지와 target image에 대한 비교를 한 것으로 보입니다.(근데 아무리 registration을 잘 했다 하더라도 결국 NIR과 RGB는 엄연히 도메인이 다른데 왜 SSIM과 PSNR metric으로 평가했는지는 이유를 잘 모르겠네요?)
표1에서 전체적인 경향성을 보시면 point error기준으로는 모든 방법론들 대비 가장 좋은 성능을 달성하긴 했습니다. 다만 SSIM과 PSNR에서는 그렇지 못한 결과를 보였는데 이것이 아마 coarse registration module에 대한 성능만을 보였기 때문이지 않을까라는 생각이 듭니다. (그럼 왜 fine-registration 결과는 안보여주는거지..?)

그리고 위에는 정성적 결과입니다. 아무래도 affine 변환만을 진행하였기에 검정색으로 겹치지 않은 영역들이 제거되는 모습입니다만 체리픽인지는 몰라도 alignment가 잘 맞아보이는 듯 합니다. 근데 affine 변환이라서 결국 호모그래피처럼 foreground와 background 사이에 갭을 해결하지는 못할 것 같은데 정성적 결과 예시도 이런 것들을 알아볼 수 없게 평면 위주의 결과로 넣어놨네요..

물론 위의 그림처럼 coarse-registered와 fine registration 결과를 함께 보여주기는 합니다만 사실 우측은 정확하게는 fine registration & fusion result이기 때문에 F2M 덕분에 registration이 더 좋아졌다..? 라고 보기에는 참 애매하네요. 선명하게 보이는 것은 그저 fusion 결과때문에 그런 것 같기도 하구요.
결론
일단 해당 논문은 image fusion과 registration의 적절한 관계를 통해 좋은 결과를 냈다고 생각이 듭니다만, 아쉬운 점은 F2M에서 말하는 fine-registration의 효과를 잘 모르겠습니다. 논문에서도 정량적 결과나 정성적 결과 모두 Coarse-registration만 보여주고 fine-registration에 대한 비교 결과는 보여주지를 않는 것으로 보아 fine-registration의 효과는 미비한 것이 아닌지 또는 image fusion을 위해 fine-registration이 선행되는 방법이기 때문에 image registration 관점에서 접근한 방법론이 아닌 듯 합니다.
아 그리고 제가 registration에 관심이 있어서 해당 리뷰에서는 registration에 대한 결과만을 다루었습니다. 혹여나 Image Fusion에 관심있으신 분들은 해당 논문에 Fusion 결과도 나타나있으니 참고바랍니다.
멀티모달이라고 말해놓고 RGB-NIR 관계만 보인것은 아쉽네요.. 혹시 NIR을 사용하는 이유도 결국 조도가 약한 상황에서 사용하기 위함인데, 혹시 조도가 약한 상황에 대한 정량적 혹은 정성적 결과도 리포팅하고 있나요?