이번 리뷰에서 소개드릴 논문은 LiDAR를 GT로 사용하는 Supervised Monocular Depth Estimation에 관한 논문입니다.
일단 이 논문을 이해하려면 최근 Supervised 에서 Depth를 정의하는 방식부터 이해하셔야합니다.
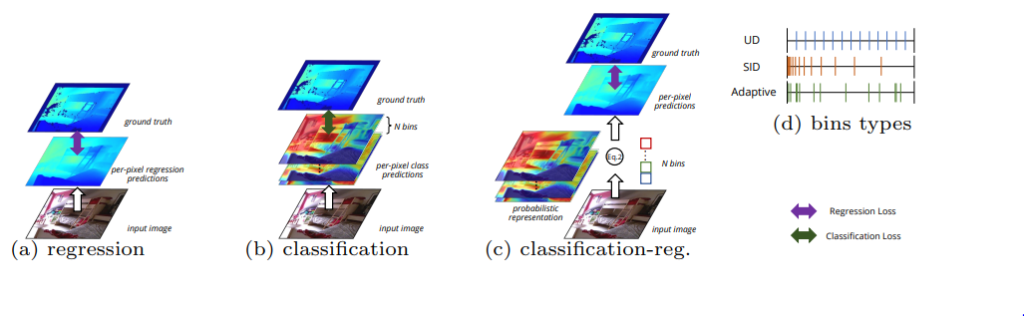
DPT나 TransDepth 와 같이 단순히 Depth를 Regression 하는 방법론이 (a), 그리고 Depth를 (d) 와 같이 histogram 처럼 나누고 classificastion하는 (b), Depth를 histogram 처럼 예측하지만 예측된 정보를 아래 식으로 1채널의 depth로 변경한 후 regression 하는 (c) 로 depth를 정의하는 방식을 이해하시면 됩니다.
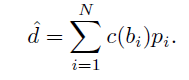
c의 경우 만약 DDV 라는 논문을 아신다면, 그 논문 속 DDV module 과 동일하게 생각하시면 됩니다.
Introduction
이 논문에선 기존 CNN 방식의 Supervised depth estimation의 문제점으로 Global 한 정보를 예측못한다는 것을 단점을 꼽습니다.
Supervised Depth estimation에서 사용되고 있는 CNN은 비록 네트워크를 깊게 쌓으면 쌓을 수록 receptive field가 늘어나서 커널이 영상을 보는 범위가 늘어나지만 고해상도 입력이 들어가면 CNN의 역할은 떨어지게 됩니다.
두번째 문제로는 현재 SOTA 방법론들의 학습 방식은 입력 데이터의 depth distribution 을 고려하지 않는 다는 것입니다. 기존 방법론들은 (b)와 같은 방식으로 학습을 진행하는데 이때 classification 하기 위한 Depth 정의를 (d) 속 UD 나 SID 같은 방식을 하나 정해서 사용합니다.
하지만 그림 1 GT depth histogram을 보면 입력에 따라서 depth의 histogram 분포가 달라지는데 histogram을 표현 하는 방식이 고정적이라면 입력에 따른 histogram을 표현할 수 없게 된다고 합니다.
따라서 위 두가지 문제를 해결하기 위해 이 논문에서는 두가지 방법론을 제안합니다.
- Global estimation을 위한 Transformer 사용
- Static bin(depth distribution) 이 아닌 adaptive bin 방식
이렇게 두가지로 작년까지는 KITTI와 NYU 데이터 셋에서 SOTA를 달성했었습니다.
Method

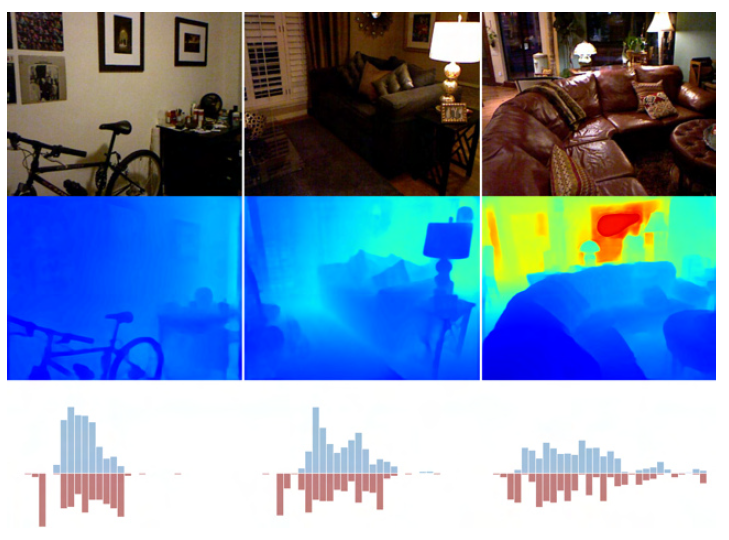
전체 아키택쳐는 그림 2 와 같습니다. EfficientNet-B5 를 DenseNet의 backbone으로 변경해서 영상으로부터 hXwxCd의 decoder feature를 얻습니다. 그 다음 mini VIT(mViT) 에 거쳐 Depth bin 의 widths b와 Range Attention map 을 얻은 후 곱해서 h/2xw/2×1 인 depth map을 얻은 후 bilinear upsampling을 해서 hxwx1의 최종 depth map을 output으로 갖습니다. 기존 방법론들은 Encoder와 decoder 사이에 mVIT 모듈을 넣지만 실험을 통해서 high resolution 에 Mvit를 넣는 것이 더우 좋은 결과를 나타냈으며 Adabin 컨셉을 위해서 decoder 까지 다 거친 후에 mViT를 적용한 것 같습니다.
mini ViT
mini ViT모듈을 위 그림과 같습니다 기존 ViT 방법론을 아래와 같이 파라미터를 줄어서 사용했으며 이를 통해서 global-context information을 강화했습니ㅏㄷ.

이렇게 ViT가 아닌 mini로 한 이유는 ViT가 계산 속도도 느리고 파라미터도 커서 그렇습니다. 그리고 아마 encoder feature에 ViT를 하는게 아니라서 resolution이 크기 때문에 그렇다고 할 수 있습니다.
Bin-Widths & Range attention maps
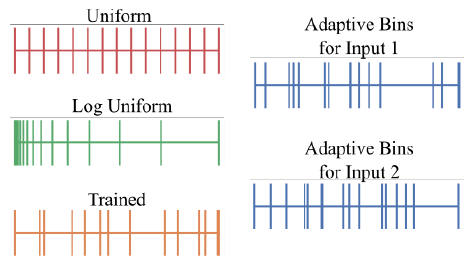
기존 방법론들은 왼쪽, 제안하는 방법론은 오른쪽입니다.
보면 Depth 가 min과 max 가 있다했을때, 일정 간격으로 나눈 것을 Uniform, log 스케일로 나눈 것을 log uniform 이 두개는 이렇게 고정해두고 사용합니다. 그다음으로 Trained는 학습 과정에서 나누는 값을 학습한 결과입니다. 이 방식은 학습이 끝나면 저 형태로 고정해서 inference 에서 사용됩니다. 하지만 이 논문에서 제안하는 방식은 영상에 따라서 나누는 기준을 다르게 하며 저 나누는 기준(bin)에 해당하는 histogram 또한 매 이미지 마다 계산해서 보다 정확한하며 linear한 깊이 추정이 가능해집니다.
그래서 이 논문에서 제안하는 방법론에서는 min과 max를 나누는 기준인 bin b 과 그에 해당하는 Range attention maps.을 예측합니다.
두 요소는 mViT를 통해서 예측되며 그림 2 와 같은 순서로 예측됩니다.
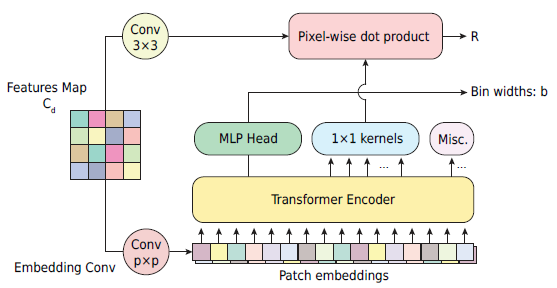
ViT 모듈을 통해서 예측된 b와 R은 아래 식으로 합쳐져서 Depth map 이 됩니다 .
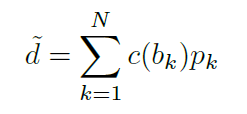
Loss function
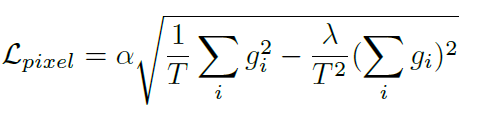
introduction에서 설명것과 같이 이 논문은 depth를 classification과 같이 정의하지만 Loss는 regressionloss 를 사용합니다. 이 때 사용하는 loss는 SILogloss며 이 loss는 Supervised 에서 거의 원툴로 사용되고 있는 loss로 보시면 됩니다.
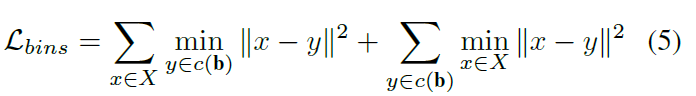
이 로스는은 bin의 분포가 ground truth의 깊이 값 분포를 따르도록 권장합니다. bin이 실제 ground truth 깊이 값에 가깝고 그 반대가 되도록 권장합니다. x=b, y=value of ground truth
Results
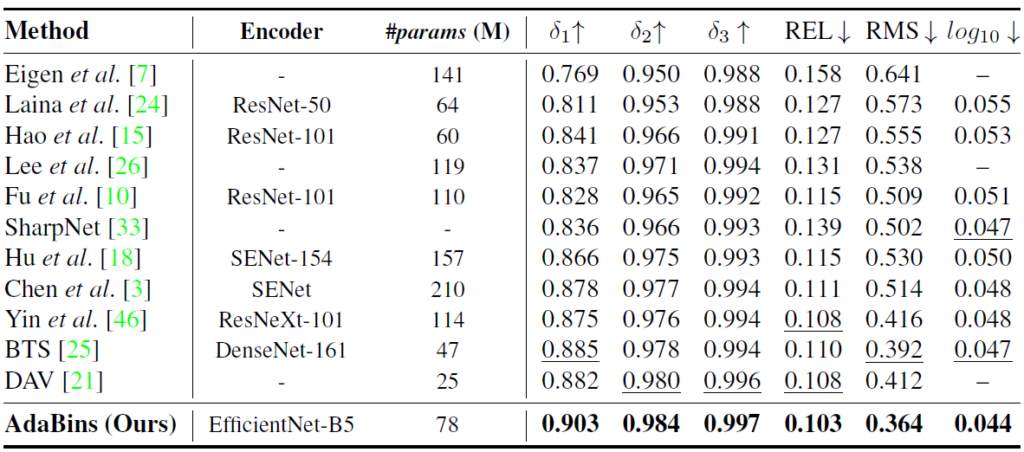
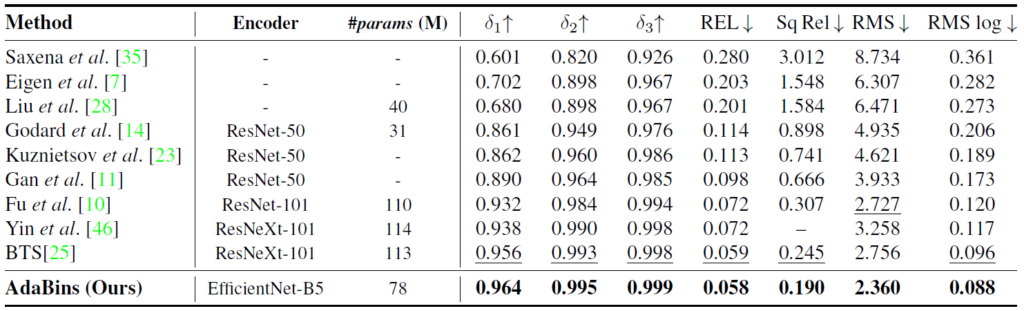
정량적 결과입니다. NYU는 실내 KITTI는 실외로 보시면 됩니다.
그당시 모든 방법론과 비교해서 파라미터는 중간정도 되지만 매우 높은 성능 향상을 이룬 것을 볼 수 있습니다.
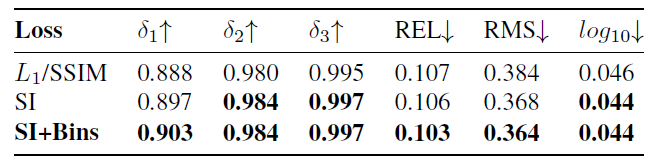
Loss에 따른 성능 평가입니다. 실내 데이터 셋이라서 L1과 SSIM을 쓴 것 같습니다. 그때 제안한 loss 가 가장 좋은 것을 볼 수 잇습니다.
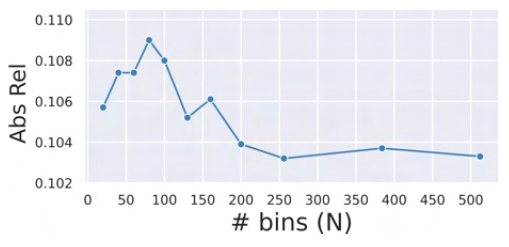
bin의 개서에 ㄷ따른 성능 평가 입니다. bin이 많은면 좋으며 어느 수준이 되면 상관 없어지는 것 같습니다.
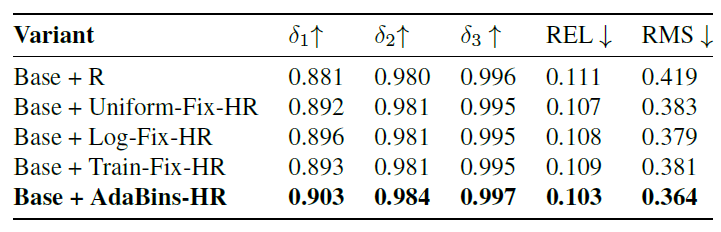
마지막으로 Depth를 정의하는 방식에 따른 결과입니다. 확식이 제안하는 방식이 좋네요
ablation study에서 Transformer에 대한게 빠진게 아쉽네요
리뷰 잘 봤습니다.
한가지 궁금한 점은 Adabin은 그림1(c)처럼 최종적으로 1채널로 합쳐짐으로써 깊이를 추정하는 것으로 이해했는데 그림2-(b)의 경우에는 채널축으로 합치는 것이 아닌 가장 확률이 높은 빈 하나를 선정해서 이를 깊이로 보는 것인가요?
그리고 수식 5번에 가장 중요하다고 판단되어지는데 수식5가 설명이나 수식 표현만으로는 이해가 조금 어렵네요. 시그마와 min 아래에 있는 x, y가 각각 좌측항과 우측항이 서로 바뀌어있는데 이것이 무엇을 의미하는건가요?
리뷰에서는 “bin이 실제 ground truth 깊이 값에 가깝고 그 반대가 되도록 권장합니다” 라고 하셨는데 그 반대가 되도록 권장한다는 것은 무슨 의미죠?
일단 classification 방식은 저도 찾아봐야 알 것 같습니다.
그리고 음… 그 수식에 대한 이해는 GT와 분포가 유사해지도록 학습한다고 생각하시면 될 것 같습니다.