Abstract
해당 논문은 어려운 상황(외관적 변화가 큰 경우)에서 신뢰도 있는 pixel-level의 대응점 찾기를 해결하기 위한 논문이다. 이 논문은 단일 CNN을 이용하여 dense feature descriptor 역할과 feature detector 역할을 수행하고자 한다. keypoint 탐지 과정을 뒤로 미룸으로써 low-level structure로 keypoint를 얻었던 방식보다 안정적으로 keypoint 를 추출할 수 있고, 대응점 추출 과정을 학습할 수 있다고 한다.
Introduction
기존의 sparse local feature방식은 keypoint detector에서 corner나 blob과 같이 작은 이미지 영역의 low-level의 이미지 정보를 활용하였다.하지만 descriptor는 large patch를 이용하여 high-level structure를 인코딩한다. low-level 정보를 활용하는 detection 과정은 픽셀의 밝기값 변화와 같은 외관 변화에 취약했다. 그러나 descriptor의 경우 keypoint를 안정적으로 감지하지 못해도 잘 작동할 수 있다는 것이 관찰되었고, 따라서 detection 단계 없이 dense descriptor를 이용하는 것도 잘 작동되었다. 하지만 이는 시간과 연산량이 많이 필요하다는 단점이 있었다.
따라서 해당 논문에서는 challenging한 환경에서 강인하고, 효율적인 연산과 저장이 가능한 sparse한 feature를 얻는 것을 목표로 하였다. CNN을 이용하여 feature map을 계산하고, 특정 모든 위치에서 descriptor를 계산하고 keypoint를 탐지(local feature의 maximum)한다. descriptor와 detector가 결합되도록 함으로써 detector는 high-level 정보를 활용할 수 있게 된다.
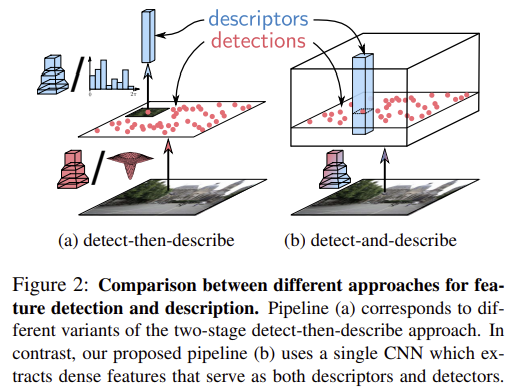
Joint Detection and Description Pipeline
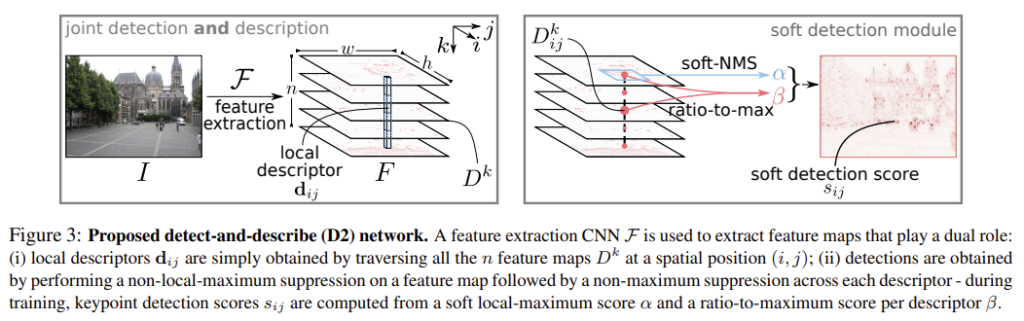
CNN 모델 \mathcal{F}는 이미지 I를 입력으로 이용하여 3D tensor F=\mathcal{F}(I)를 얻는다.
1. Feature Description
\mathbf{d}_{ij}는 (h,w)=(i,j)에서의 descriptor vector이다. 학습 과정에서 descriptor는 외관 변화가 있어도 동일한 지점이 유사한 descriptor를 생성하도록 조정되며, descriptor는 L2 normalization을 통해 정규화가 적용된다.
2. Feature Detection
\mathcal{F}로 추출된 3D tensor F는 n개의 서로 다른 feature detector \mathcal{D}^k(k=1,2, … ,n)로 뽑은 2D map D^k의 집합이다. \mathcal{D}^k로 뽑은 raw score는 keypoint 위치를 찾기 위해 후처리된다.
Hard feature detection
기존 feature detector와 다르게 다중 detection map이 존재하며, 여러 map 중 어느것에 대해서도 탐지가 가능하다. 따라서 keypoint (i, j)를 얻기 위해 가장 좋은 detector \mathcal{D}^k를 선택하여 대응하는 map D^k에 local maximum이 있는지 확인한다.
Soft feature detection
학습을 하며 hard detection 과정은 back-propagation에 적합하도록 부드러워진다. soft local-max는 식 (4)로 정의되며, 이때 \mathcal{N}(i,j)는 (i,j) 픽셀 주변의 (i,j)를 포함한 9개의 주변 값이다.
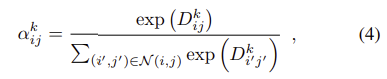
이후 채널별 non-maximum suppression을 모방하여 descriptor당 ratio-to-max를 계산하는 soft channel selection을 정의한다.
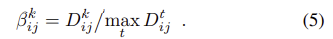
그 다음 모든 feature maps k에서 두 점수(α와 β)를 곱하여 최대값을 구하여 하나의 score map을 얻는다.
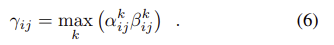
마지막으로 soft detection score s_{ij}는 이미지 레벨의 정규화를 통해 얻는다.
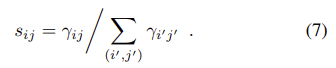
Multiscale Detection
CNN descriptor는 scale 변화에 불변성을 가지지 못하여 view-point가 크게 변하는 경우 매칭에 실패하는 경향이 있다. 따라서 객체 검출기에서 많이 사용되는 이미지 피라미드를 사용하는 것을 제안한다.(test 과정에만) 입력 이미지 I에 대해 해상도 ρ가 0.5,1,2가 되도록 하고 각 입력에 대해 feature map F^ρ를 얻는다. 이후 다음의 방식을 통해 저해상도 feature map에서 고해상도 feature map으로 이미지 구조가 전파된다.
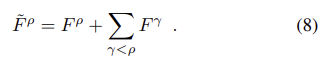
이때 크기가 다른 feature map을 합치기 위해 bilinear interpolation을 수행하여 해상도를 맞춘다. detection은 앞서 설명한 후처리를 통해 융합된 feature maps \tilde{F}^ρ를 이용하여 수행한다. 이때 다양한 크기에서 detection을 수행할 때 re-detection이 되는 것을 막기 위해 저해상도에서 찾은 포인트들은 upsampled되어 다음의 해상도에서는 해당 영역에서의 탐지는 무시되도록 하였다.
Jointly optimizing detection and description
1. Training loss
단일 CNN을 이용하여 detection과 description을 학습하기 위해 적절한 loss가 필요하다. detector은 view point 변화나 조명 변화가 있어도 동일한 keypoint를 찾고자 하고, descriptor는 설명자가 구분되어 잘못 매칭되지 않도록 하는 것을 목표로 한다. 이를 위해 triplet margin ranking loss를 확장하여 적용하는 것을 제안한다.
논문에서 제안하는 triplet margin ranking loss는 이미지쌍 I_1, I_2의 대응하는 descriptors \hat{\mathbf{d}_{A}}^{(1)} 와 \hat{\mathbf{d}_{B}}^{(2)}의 거리가 가까워지도록 한다. 이때 각 이미지의 주변 sample 중 hardest negative인 N_1,N_2에 대한 \hat{\mathbf{d}_{N_1}}^{(1)} 와 \hat{\mathbf{d}_{N_2}}^{(2)}의 거리는 멀이지도록 한다.(N1과 N2는 다음 식(11)을 통해 구해진다.
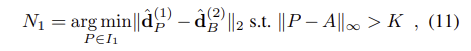
수식적으로 확인하면
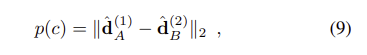
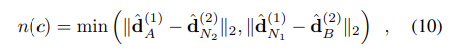
이고, triplet margin ranking loss다음식으로 정의된다.
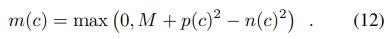
여기에 detector를 위한 항을 추가하여 다음의 loss 식으로 확장을 제안한다.
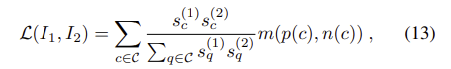
이때 s_c^{(1)}와 s_c^{(2)}는 위의 식(7)을 이용하여 구한다.
Experimental Evaluation
1. Image Matching
HPatches 데이터셋을 이용했다. 다양한 데이터셋에서 수집된 116개의 사용 가능한 시퀀스 중 108개를 골랐다. 각 장면은 점점 밝아지는 6개의 이미지로 구성된 동일 view-point의 52 시퀀스 또는 조명 변화 없이 view-point가 변하는 56개의 시퀀스로 구성된다.
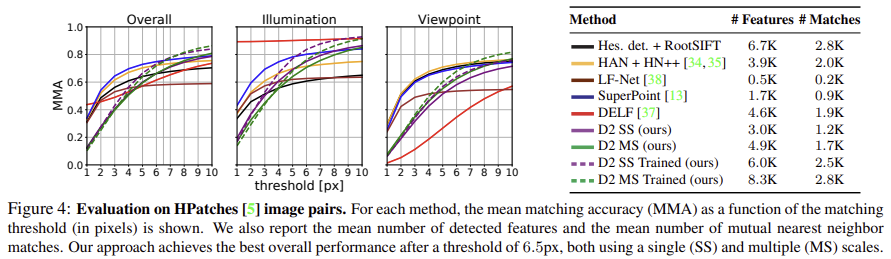
- 조명 및 view-point 변화에서의 평균 정확도에 대한 결과
- 이미지당 탐지된 평균 feature 수와 가장 가까운 neighbor를 리포팅하였다.
- D2 방법론은 threshold가 낮을 때는 detection 후 descriptor를 이용하는 방식보다 성능이 좋지 않다.
- view point 변화가 있는 시퀀스의 성능이 저하된 것은 훈련 데이터 세트의 편향 때문인 것으로 분석하였다. 학습과정의 90% 이상의 데이터셋은 20° 이하의 변화가 있기 때문이다.
- multiscale detection은 view point 변화에 강인함을 향상시키지만 descriptors에 모호함을 주어 조도 변화에는 부정적인 영향을 주었다.
2. Localization under Challenging Condition
Day-Night Visual Localization
Aachen Day-Night 데이터셋을 이용한다. 98개의 야간 이미지에 대해 카메라 pose 정보가 있는, 관련된 주간 이미지 (최대 20개)가 제공된다. 각각에 포함된 낮 이미지셋과의 feature matching 이후 3D 정보를 이용하여 위치 정보를 알아낸다.
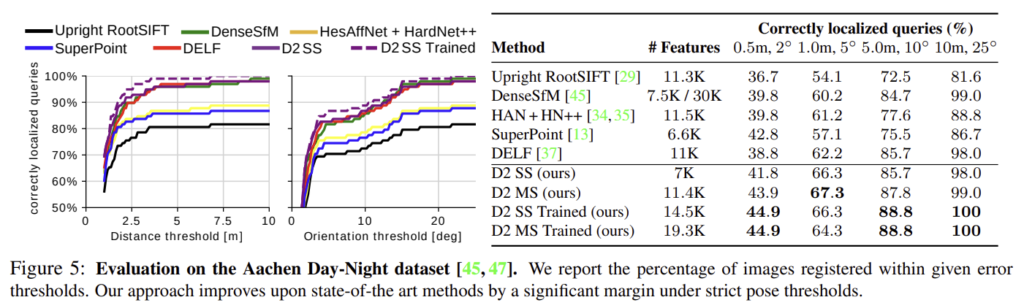
- 표의 m, °는 오차 거리 및 각도의 한계
- 다른 방식들과 비교했을 때 describe-and-detect 방식이 더 좋은 성능을 보이는 것을 확인할 수 있음.
Indoor Visual Localization.
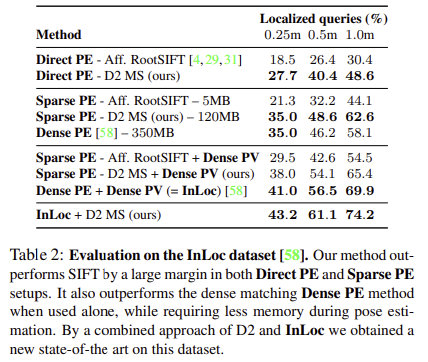
InLoc 데이터에 대해 실험을 진행함.
Soft feature detection 에서 soft channel selection 가 nms 를 모방했다는데, nms 와 비교하였을 때 어떠한 장단점이 있나요? 본 논문에서 nms 를 사용하지 않고, 해당 방법을 정의한 이유가 궁금하여 질문 남깁니다.