

오늘 리뷰할 논문은 CVPR 2022에 accept된 논문 “Learning from Untrimmed Videos: Self-Supervised Video Representation Learning with Hierarchical Consistency” 입니다. 최근에 많은 self-supervised video representation은 trimmed video, 즉 짧은 길이면서 주로 하나의 contents만을 담고 있는 video를 대상으로 연구가 이루어져왔습니다. 데이터 셋에 존재하는 trimmed video 만을 그대로 사용할 경우 그 수만큼 contents에 대한 다양성이 제한되기 때문에, 어떻게 하면 contents 다양성의 폭을 늘릴 수 있을까라는 주제가 이 분야 연구의 여러 큰 획 중 하나였습니다. 이에 대한 하나의 예시로, CVRL이라는 방법론에서는 하나의 trimmed video에서 서로 다른 시간 대의 두 clip를 sampling 한 뒤, 이들에게 각각 서로 다른 spatial transform을 적용해 contents 다양성의 폭을 늘리고자 하였고, 그 목적을 이루어 좋은 성능을 보였습니다.
이뿐만 아니라 다른 연구들에서도 여러 방법을 시도해왔으나, 기존 연구들은 공통된 하나의 가정이 존재하였습니다. 그것은 모두 trimmed video로부터 얻은 clip을 사용하였다는 점으로, trimmed video는 하나의 contents만을 가지고 있는 특성 상 어떤 시간 대에서 추출된 clip 이든 시각적으로 유사해보이게 됩니다. 이러한 이유로 trimmed video만을 활용한 연구의 경우, contents 다양성 폭을 넓히는 데 있어 제약이 존재하게 됩니다.
반면, trimmed video에 대응되는 개념인 untrimmed video는 주로 다양한 contents를 포함하며, trimmed video 와 달리 sampling 된 두 clip 사이의 시간 축 거리가 멀 경우 두 clip이 시각적으로 유사해보이지 않을 수도 있습니다. 논문의 저자는 trimmed video로부터의 학습 대신 보다 다양한 contents가 많이 존재하는 untrimmed video로부터 학습하는 HiCo (hierarchical consistency learning framework)라는 방식을 통해 contents 다양성 폭의 제약을 완화시키고자하였습니다.
1. Hierarchical Consistency Learning
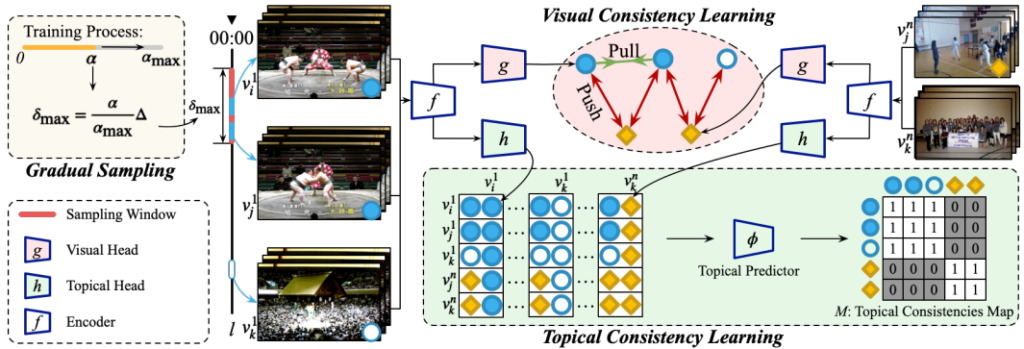
한 비디오에서 sampling 된 두 clip 간의 contrastive learning만을 고려하면 되는 trimmed video 기반 학습 방식들과는 달리 untrimmed video 기반 학습 방식은 두 가지를 고려해야합니다. 먼저, 1) trimmed video 기반 학습 방식에서와 유사하게 인접한 위치에서 sampling된 두 clip 간의 relation은 시각적으로 유사하다는 점과 (visually consistent), 2) sampling 된 두 clip 간의 거리가 멀 경우의 relation 은 시각적으로는 유사하지 않지만 그 video의 topic과는 유사하다는 점입니다. (topically consistent) 이러한 이유로 HiCo는 visual consistency learning(VCL)과 topical consistency learning(TCL), 두 종류가 hierarchy로 구성되었습니다. 또한, VCL과 TCL에서 clip의 효과적인 sampling 전략인 Gradual Sampling 방식을 제안하였습니다.
1.1 Visual Consistency Learning
VCL의 경우 visually consistent를 목표로 두기에 trimmed video 기반 학습 방식과 유사하게 인접한 위치의 두 clip을 sampling하고 SimCLR 방식으로 contrastive learning 하는 것으로 구성되었습니다. (SimCLR는 홍주영 연구원의 리뷰를 참고 부탁드립니다) 구체적으로, Mini-batch인 N개의 비디오에서 각각 v_i, v_j를 sampling하며 latent vector인 z로 projection 시킵니다. 그리고, 식 (1)과 같이 구성된 loss term으로 contrastive learning을 진행합니다. 여기서, s_{i,j} 는 v_i, v_j 의 latent vector들 간의 cosine similarity를 의미하며, \tau는 temperature parameter를 의미합니다.
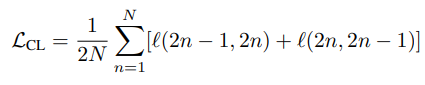
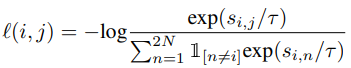
1.2 Topical Consistency Learning
TCL의 경우, Fig 2에서와 같이 시각적으로 유사하지않아 trimmed video기반 학습 방식이였다면 v_i, v_j 대비 negative 였었어야할 v_k가 비디오 topic으로는 v_i, v_j와는 동일하기 때문에, 이를 학습에 활용하고자 하는 목표를 가지고 있습니다. 그러나, 근본적으로 v_k는 시각적으로 상당히 다르기 때문에 VCL에서와 같이 invariant한 feature의 표현력을 목표로 둔 contrastive learning을 적용하는 것은 적합하지 않습니다. 이의 대안으로 TCL에서는 topic prediction이라는 pretext task로 이 문제를 해결하고자합니다.
우선 mini-batch N개 비디오에서 각각 v_i, v_j, v_k 를 sampling하고 backbone network와 projection head를 통해 topical representation t_i, t_j, t_k 를 추출합니다. 그 후, 식 (2)와 같이, Nx3개의 모든 topical representation을 one-by-one으로 concat하여 U를 생성합니다. 그 후, 생성된 U를 MLP인 \phi를 태워 topical prediction을 생성해냅니다. 이 때, supervised label G를 활용하고, 이는 단순히 concat된 두 topical representation이 같은 video인지 아닌지를 나타내는 binary label입니다. G를 통해 prediction의 loss를 계산할 때는 같은 video에 해당하는 label과 그렇지 않은 label의 수가 불균형하기에 식 (3)과 같이 focal loss 구조가 활용되었습니다.
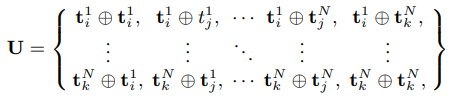
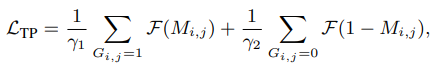
1.3 Gradual Sampling
앞선, VCL과 TCL에서 clip을 sampling 할 때 보다 효율적으로 학습이 진행되기 위해, curriculum learning에서 아이디어를 따온 Gradual Sampling 방식이 적용되었습니다. Curriculum learning이란, 사람이 학습할 때 처음에는 쉬운 문제를 풀다가 점점 문제의 난이도를 높여가는 전략을 취하는 것에서 motivate되어, 모델에게도 초기 학습 단계에서는 쉬운 sample을 주고 점점 난이도를 높여가는 학습 방식을 의미합니다. VCL과 TCL에서는 sampling 되는 시간의 위치가 가까운 v_i, v_j를 사용하는데, 주로 다른 연구에서는 일정 최대 거리 기준을 두고 그 사이에서 랜덤으로 clip을 sampling 하였습니다. 이와 달리 해당 논문에서 제안된 Gradual Sampling은 두 clip 사이의 시간적 거리가 가까우면 쉬운 sample, 멀면 어려운 sample로 가정하고 clip이 sampling 되는 최대 거리 기준을 학습이 진행되어감에 따라 점차 늘려가는 방식을 채택합니다. 이는 식 (4)와 같으며, 여기서 \alpha는 현재 epoch, \alpha_{max}는 최대 학습 epoch, \delta_{max}는 clip이 sampling되는 최대 거리 기준, \bigtriangleup는 \delta_{max}의 최대 범위를 의미합니다. 학습 초반에는 바로 인접한 clip이 주로 sampling되다가 학습이 되어갈 수록 시각적 유사도가 낮아지는 clip도 sampling되며 모델을 학습시키게 됩니다.
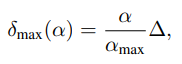
2. Experiments
2.1 Ablation Studies
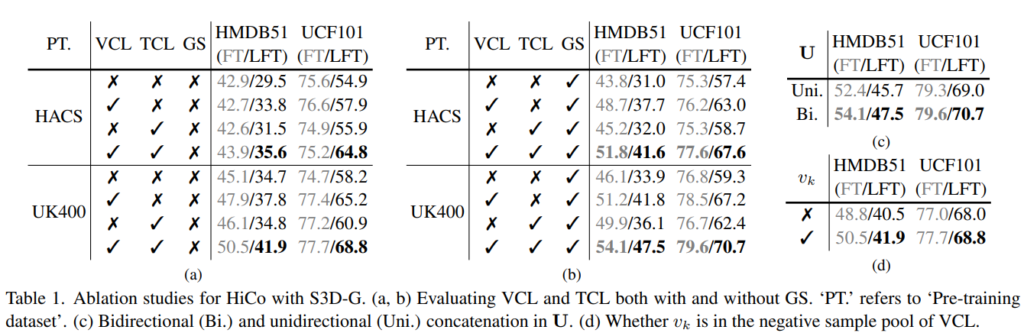
LT/LFT: fully fine-tuning/linear fine-tuning
Table 1은 HiCo의 ablation study를 나타냅니다. Table 1의 (a)는 Gradual Sampling (GS)를 사용하지 않는 상황에서 pretraining dataset (PT)이 다를 때와 VCL과 TCL이 각각/같이 사용되었을 때의 성능을 나타냅니다. TCL이 단독으로 사용되었을 경우 VCL에 비해 상대적으로 효과적이지는 못하였으나 같이 사용한 경우 상당히 많은 성능적 이득을 보였습니다. 이는 TCL이 VCL에 대해 상호보완적인 관계를 갖는 것을 의미합니다.
Table 1의 (b)는 GS를 사용한 경우의 성능입니다. 기본적으로 Table 1의 (a)에 비해 모든 변에서 성능 향상이 있었으며 이는 랜덤하게 sampling 하는 것보다 GS의 방식이 더 효과적임을 나타냅니다. 이론적인 증명에 대해서도 논문에서 소개하고 있으니 궁금하신 분들은 논문의 supplementary를 참고해주시길 바랍니다.
Table 1의 (c)는 U를 만들기 위한 concat을 할 때, 한쪽 방향으로만 concat할 지 ( {1,2} ), 양쪽 방향으로 concat할 지 ( {1,2}, {2,1} ) 에 대한 실험 결과 입니다. Table에 나타나있듯, 양쪽 방향으로 concat한 경우가 더 좋은 성능을 보이며, 이는 양쪽 방향으로 concat할 경우 prior가 더 많고, 해당 pretext task가 feature order와는 관계가 없음을 나타냅니다.
Table 1의 (d)는 TCL에서 사용된 시각적으로는 유사하지 않지만 같은 topic을 나타내는 clip v_k를 VCL 에서 학습시 negative pair에 포함시킬지 안시킬지에 대한 ablation study 입니다. 결과적으로 포함시켰을 때 더 높은 성능을 보였으며, 이는 시각적으로 다른 v_k가 invariant한 feature를 만들기 위한 negative sample pool에 추가적인 정보를 주었다는 것을 의미합니다.
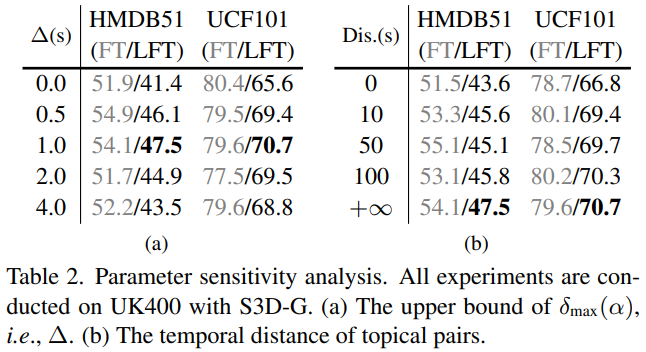
Table 2는 GS에 활용된 최대 거리 기준의 최대 범위 \bigtriangleup와 같은 topic을 나타내는 clip v_k를 선택하는 거리의 범위를 의미합니다. Table 2의 (a)에서 \bigtriangleup가 1초일 때까지는 약간의 난이도를 높여주며 모델이 더 높은 성능을 낼 수 있도록 이끌어준 반면, 그 이상으로 갈 경우 clip 간의 시각적 유사도가 많이 달라져 성능이 떨어지는 모습을 보입니다. 그리고 Table 2의 (b)에서는 범위를 넓힐 수록 같은 topic이지만 시각적인 변화도가 높은 clip이 sampling되어 더 높은 성능 향상을 이끌어내는 것을 보입니다.
2.2 Evaluation on action recognition task
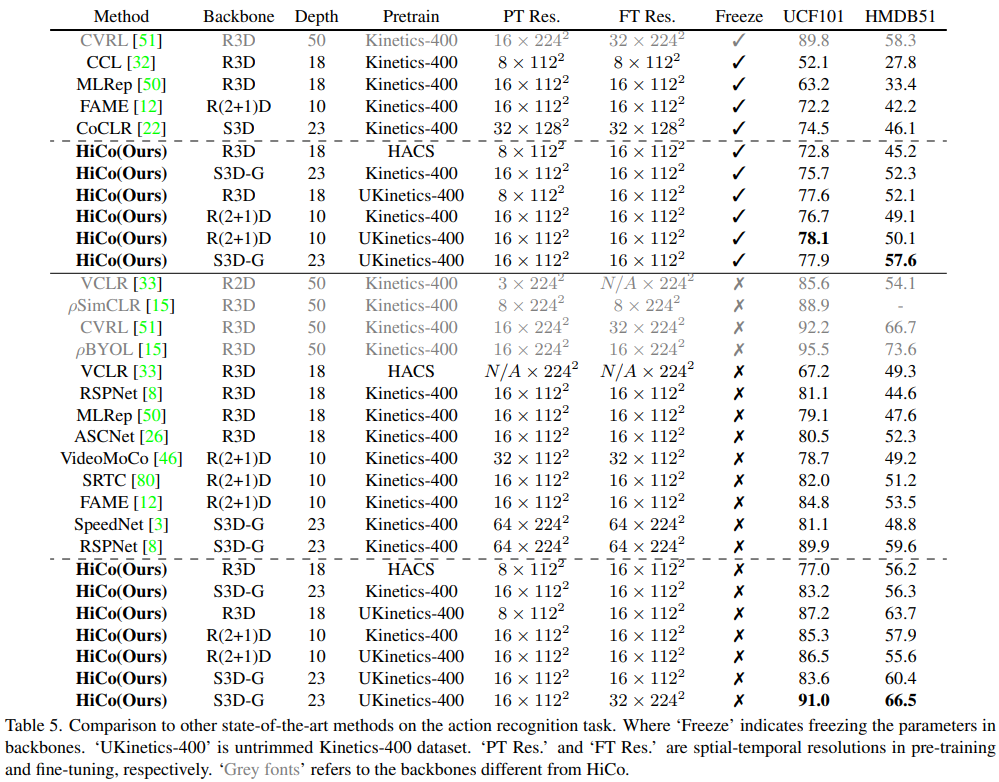
Table 5는 HiCo 방식으로 backbone network를 pretraining 한 뒤, UCF101과 HMDB51에서 action recognition task로 transfer learning한 결과입니다. 눈여겨봐야할 점은 본 논문의 저자가 Kinetics400을 기반으로 새로 만든 UKinetics400에서의 pretraining 효과가 Kinetics400에서보다 대체적으로 높은 경향을 보인다는 것입니다. 이는 본래 목표로 했던 untrimmed video에서의 효과적인 학습이 제대로 이루어지고 있음을 나타냅니다.
이외에도 appendix까지 이르는 여러 실험이 있으나 리뷰가 너무 길어져 지루해질 것을 막기 위해 본 리뷰에는 담지 않았습니다. 관심이 있으신 분들은 논문을 참고 부탁드립니다.
3. Reference
[1] https://arxiv.org/pdf/2204.03017.pdf
리뷰 감사합니다. Untrimmed video에서의 효과적인 Self-Supervised Learning 기법을 다룬 인상적인 논문인 것 같습니다.
해당 방법론의 pretrain 기법이 조금 궁금한데, 그냥 Kinetics를 사용했을 때와 Untrimmed Kinetics를 사용했을 때 다른점이 있나요?
좋은 리뷰 감사합니다.
untrimmed video의 경우는 몇몇 경우 유사한 위치가 동일한 contents임을 보장할 수 없는데, VCL의 경우 이러한 문제에 혹시 어떻게 대처하고 있는지 궁금하네요. 소수 케이스라 가정하고 고려하지 않는 편인가요?