요약:
해당 논문은 classification 구조를 갖는 task에서 class간 Hierarchical 구조를 고려할 수 있도록 설계된 Deep metric learning 방법론입니다.
배경 소개:
Deep Metric Learning(DML)이란 convolutional neural networks를 접목한 metric learning 분야이다. DML 분야에서는 모델 학습을 위해 주로 pair-based loss(contrastive loss, triplet loss) 혹은 proxy-based loss(proxy-NCA, proxy anchor loss)를 이용한다. pair-based loss는 데이터 셋의 샘플의 쌍(pair)의 유사도 등을 직접 비교하여 학습 시킨다. 반면 proxy-based loss는 데이터 샘플을 직접 이용하지 않고 proxies 라는 데이터 포인트의 집합을 학습하게 한다. clustering을 통한 classification 문제 해결 시 clustering centor를 이용하는 것과 같이 proxies를 이용한다. proxies는 일반적으로 데이터 셋의 샘플 개수(즉, 데이터 셋의 크기)보다는 작기 때문에 pair-based 방법론보다 연산 효율성이 높은 것이 특징이다. 두 타입의 loss 들의 특징을 더욱 자세하게 적은 것은 아래와 같다.
Proxy-based losses의 시초는 proxy-NCA다. 이는 pair-based loss의 느린 수렴 문제를 다루기 위해 도입되었다. proxy-NCA는 class에 대한 초기 proxy를 정의한 후 Neighborhood Component Anaalysis(NCA) loss를 이용해 데이터의 샘플들이 적합한 proxy에 가까워지도록 학습한다. Proxy anchor loss는 proxy를 단순히 데이터 샘플에 대한 목적(target)으로 사용한 것이 아니라 anchor로 사용하여 샘플 간의 관계를 적극적으로 사용하였다. 수식을 이용하여 더욱 자세하게 소개하면 다음과 같다. 먼저 Proxy-NCA에서 NCA loss는 (1)과 같으며 negative, positive와 같은 관계를 구성하지 않는다.
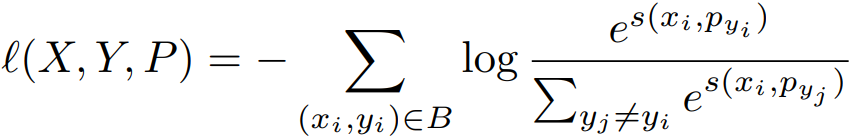
이와 다르게 proxy anchor loss는 positive set과 negative set을 구성하는 식 (2)와 같다.
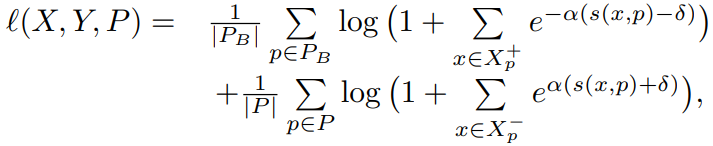
proxy based loss를 이용한 DML은 위와 같은 loss를 사용하여 유사도 함수인 S(▪)를 학습한다. 이러한 proxy 기반 방법론의 문제는 모든 DML 문제를 classification 문제로 다루도록 하며 결론적으로 class-discriminative한 정보에 집중하고 class간의 공유되는 정보에 대해서는 무시하도록 학습되는 경향이 있다는 점이다.
방법론:
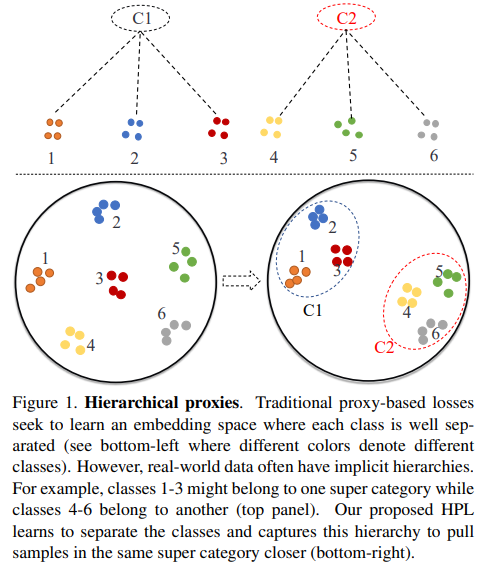
제안하는 Hierarchical Proxy-based Loss(HPL)와 기존 문제의 차이점은 아래의 수식으로 알 수 있다. 아래 수식에서 보듯이 프록시에 level을 의미하는 첨자 l이 있다. 즉 hierarchical 한 구조를 갖는 proxy를 설계하는것이 목적인 것이다.
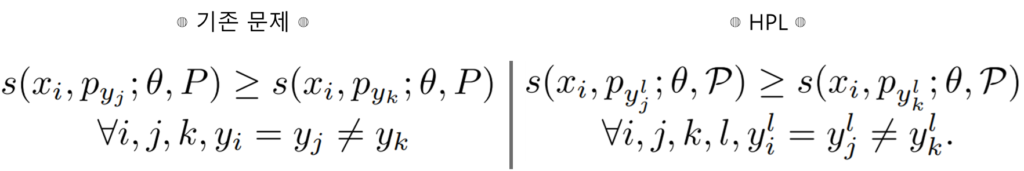
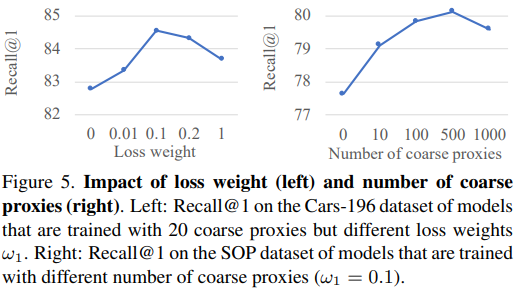
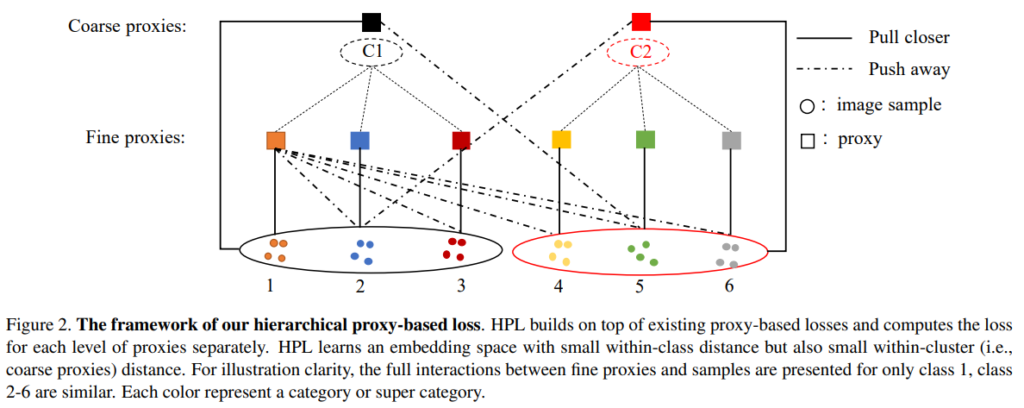
HPL loss의 구조는 다음과 같다. leval에 대한 가중치 w를 proxy-based loss(proxy-NCA, proxy anchor)에 l에 곱한 형태로 자연스럽게 hierarchical 구조를 이루도록 모델을 학습할 수 있다. 이렇게 클래스간의 포함구조를 허용하여 class-share information을 표현하도록 하여 기존 proxy based loss의 class discriminative 성질에만 집중하게 되는 문제점을 해결하였다. 이때 초기 계층 구조를 갖는 proxies를 구성하기 위해 unsupervised 방법론인 k-means를 사용하여 proxy를 묶어 그룹화 하였다. 이때 w는 하이퍼 파라미터이며 실험 결과 w0=1.0, w1=0.1 일때 가장 좋은 성능이였다. 이와 관련된 실험은 Figure5를 참고할 수 있다.
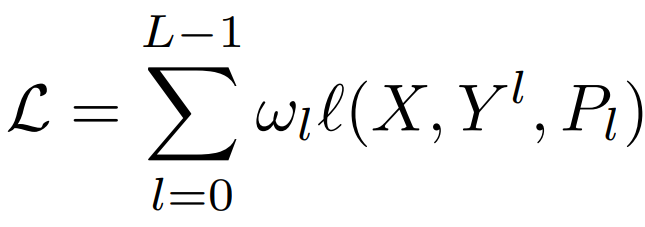
실험:
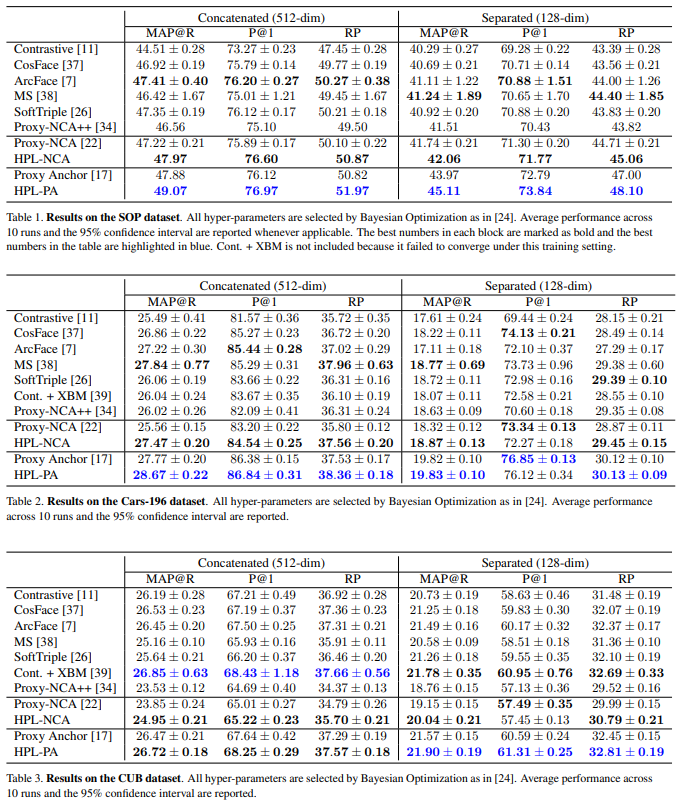
실험은 SOP, Car-196, CUB와 같은 metric learning 분야에서 자주 사용되는 데이터셋들로 이루어졌으며 기존 DML 방법론과 proxy-NCA를 기반으로 한 HPL, proxy anchor을 기반으로 한 HPL로 학습한 성능을 리포팅하였다.
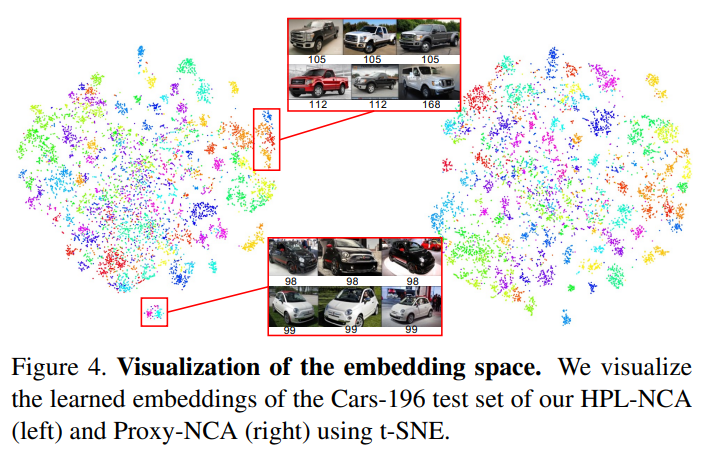
또한 feature space에 임베딩된 추출한 특징들을 t-SNE로 시각화 하여 제안하는 방법론이 기존 방법론보다 더 표현력이 높음을 보였다.
또한 파라미터에 대한 실험도 진행하였는데, 이는 아래와 같다. 왼쪽은 w1이 어떤 수로 설정되었을때 가장 효과적인지를 분석하기 위한 실험이며, 오른쪽은 coarse proxies(가장 상위 level의 proxies set)의 갯수에 대한 실험이다.