
이번에도 Speech Emotion Recognition (SER) 관련 논문입니다. 음성 인식 분야에서는 노이즈(잡음)가 모델의 성능에 영향을 끼치는 중요한 요인 중 하나입니다. 본 논문은 ‘생성 모델’을 사용하여 만든 노이즈를 추가하는 방법으로, 학습 데이터를 증가시킴으로써, 노이즈에 강인한 모델을 만들었습니다. 이 때 노이즈를 만들기 위해 Mel-filterbank enery domain 을 고려한 것이 포인트인데, 이는 아래에서 좀 더 자세히 설명하도록 하고, 리뷰 시작하도록 하겠습니다!
Prior works
Speech Emotion Recognition (SER) 은 음성 데이터로부터 감정을 인식하는 문제입니다. 지난 20여 년 동안, 이 분야는 “주변 환경이 조용한, Clean 한 상태에서 음성 데이터가 수집 되었다” 라는 시나리오 아래에서 연구되어 왔습니다. 그 환경 아래에서 데이터로부터 hand-crafted low level descriptors 를 뽑아내고, 이에 대한 발화 레벨의 통계를 representation features 로 사용하고, Support vector machine 을 classifier 로 사용하는 게 흔한 접근 방식이었습니다.
그러나, 이러한 방식으로 설계된 모델은 앞서 말한 가정 때문에 실제 환경, 즉, 노이즈가 있는 환경에서 실증하였을 때 성능의 저하가 생깁니다. 노이즈 때문에 학습 환경과, 실증 환경 간의 간극이 발생한 것이지요. 때문에 이전 연구들에서도 SER 에서의 노이즈 문제를 해결하려는 시도들이 있었고, 어떤 level 에서 고려하느냐에 따라 세 가지 접근 방식으로 나눌 수 있었다고 합니다.
- Signal level : voice activity detector (VAD), non-negative matrix factorization (NMF), blind source separation (BSS)
- Feature level : feature compensation, denoising, enhancement
- Model level : model adaptation, multi-conditioning
이전 연구들이 이런 것들이 있었구나~ 하는 느낌으로 봤습니다. 관련 논문을 읽다보니까 계속 보이는 것들도 몇 개 있어서, 앞으로 읽어볼 생각입니다!
본 논문의 제목은 ‘Multi-Conditioning and Data Augmentation Using Generative Noise Model for Speech Emotion Recognition in Noisy Conditions’ 입니다. 즉, 생성 모델을 사용해서 만든 노이즈를 이용해서 학습 데이터를 다양한 환경(multi-conditioning)으로 만들고, 이로 인해 학습 데이터의 양 또한 증가하게 됨(data augmentation)으로써, 노이즈에 강인(robust)한 SER 시스템을 만들 수 있게 됩니다.
단순히 생각해보면 “원래 있는 노이즈 데이터셋 가져다가 쓰면 되는 거 아니야?” 라는 생각이 들 수 있는데, 해당 논문에서 원래 있는 Noisex-92 노이즈 데이터셋을 이용하는 방법과 본 논문에서 제안한 방법을 사용해서 EmoDB 와 IEMOCAP 이라는 speech 데이터셋에 비교 실험을 해본 결과, 후자가 noise 에 대해 더 robust 하다는 결과가 나왔다고 합니다.
Automatic Speech Recognition (ASR) 분야에서는 multi-conditioning 과 data augmentation 을 적용하는 방법론이 제안되기도 했었다고 합니다. 그러나 SER 에서는 이러한 측면이 고려된 적이 없었기에, SER 에서 noise robustness 를 해결하기 위해 본 논문에서는 아래의 프레임워크를 제안합니다.
Framework
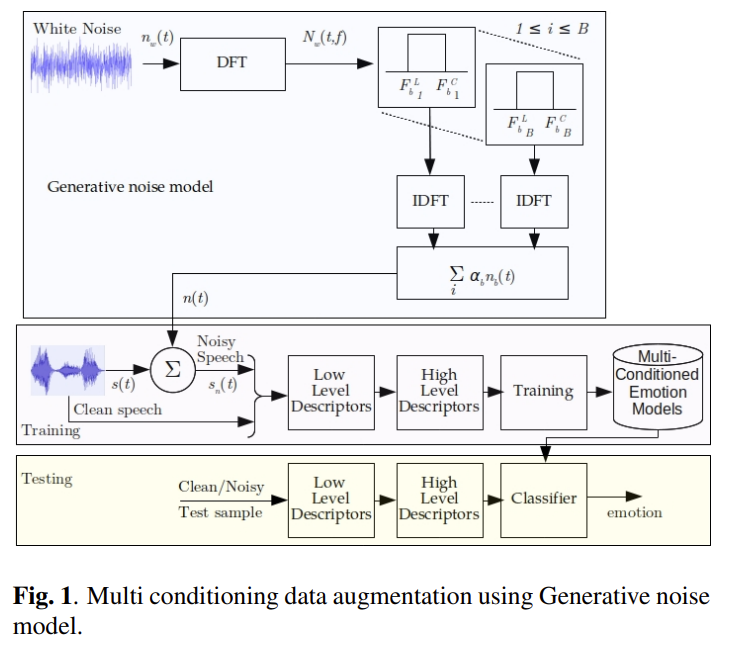
생성모델
생성 모델은 Mel-Filter Bank Energies (MFBEs) 를 고려하여 만들었습니다. [이전 리뷰] 에서 이 과정에 대해 설명을 했어서, 자세한 설명은 해당 리뷰를 참고해주시면 좋을 것 같습니다!

- Triangular filter bank
Triangular filter bank(TFB)는 이전 리뷰에서의 Mel-Filterbank 와 동일합니다. 해당 필터는 ‘사람의 목소리의 주파수 영역’을 자세하게 분석하고, 다른 영역은 덜 분석하기 위한 역할을 합니다. 아래의 공식을 사용하여 오디오 주파수(f) 에 TFB 의 각 필터를 이용하여 적용시킵니다. (TFB_b 는 TFB 의 b번째 필터)
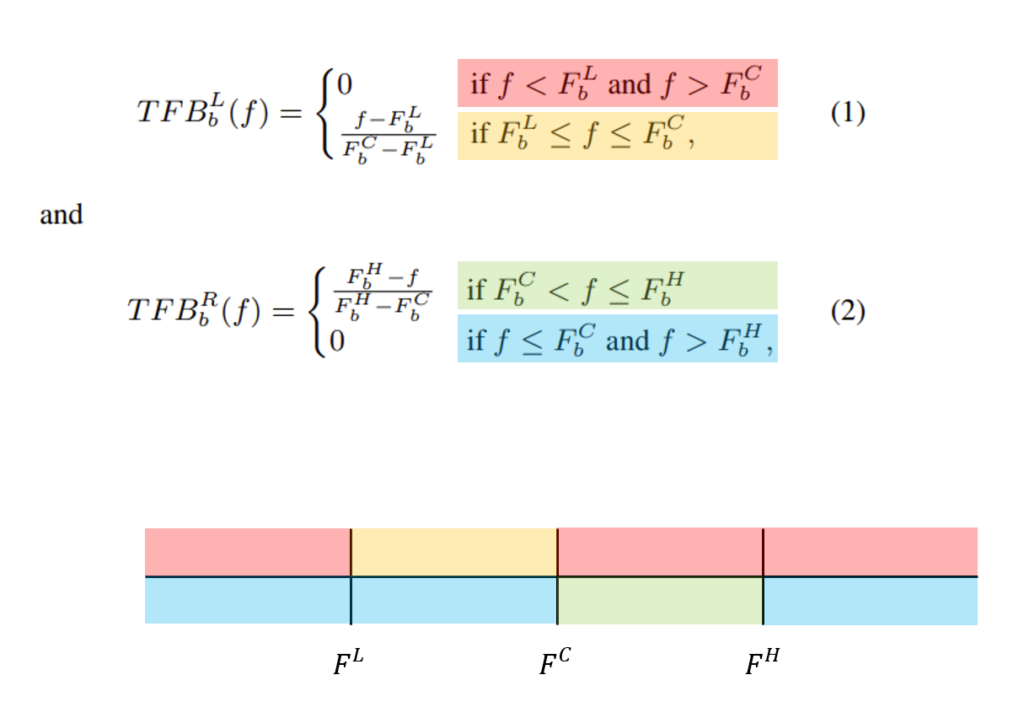
F^L, F^C, F^H 는 순서대로 low / center / high frequency 를 뜻합니다. TFB 는 L(왼쪽)과 R(오른쪽) 두 가지로 구성이 되는데, L은 TFB 가 강조해줘야하는 부분 중 왼쪽 영역을 강조해주고, R은 오른쪽 영역을 강조해주는 역할을 합니다.
2. SIFT mangitude
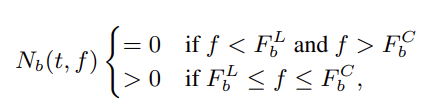
오디오 시그널의 t 번째 프레임, 주파수 f 에서의 SIFT magnitude 를 구하는 공식입니다. 즉, 이 부분만 보도록 제한하는 것이죠.
3. Mel-Filter Bank Energy
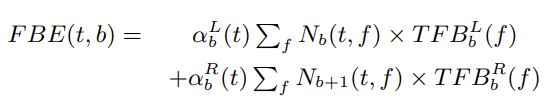
1과 2를 통해 TFB 를 overlapping 하며 사용하도록 구성된 공식인 FBE 를 이용하여, Mel-Filter bank enery 를 구할 수 있습니다. 이때 \alpha 는 filter magnitude response 이고, FBE >=0 인 일 때 결정되는 상수값입니다
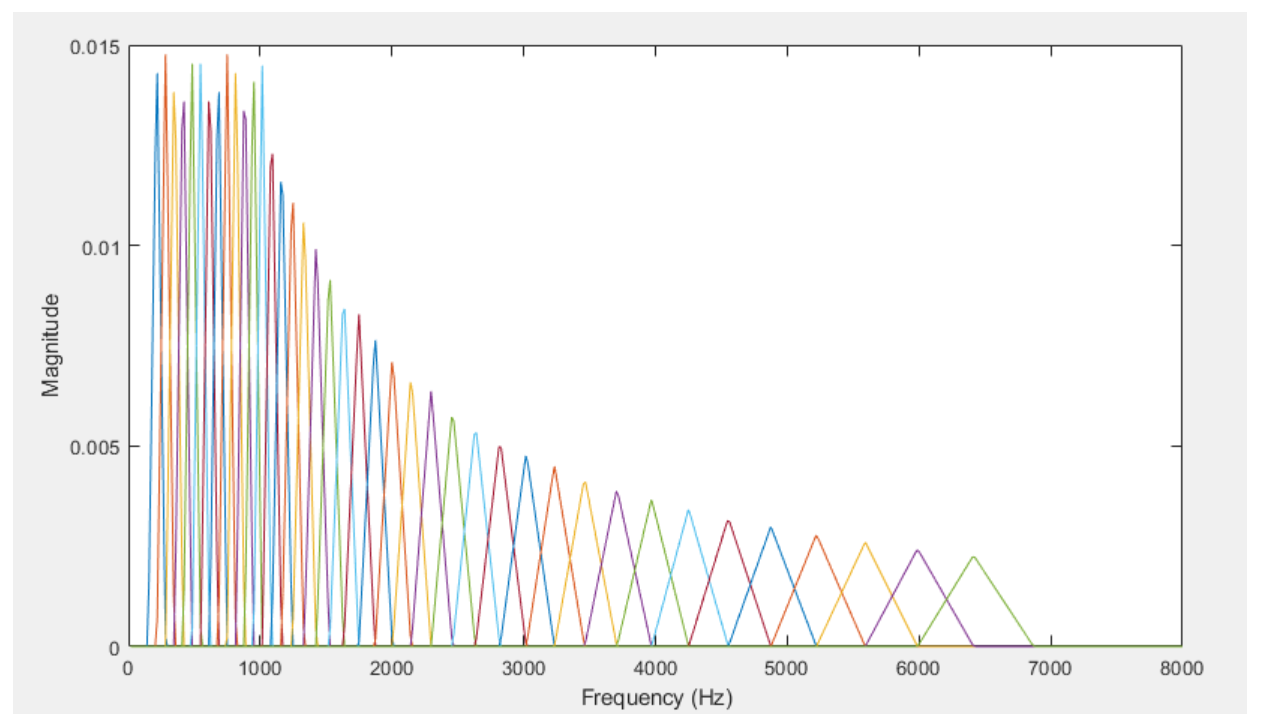
F^C_b = F^L_{b+1}, F^H_b = F^C_{b+1} 이 되도록 overlapping 하여서, FBE 의 전체 공간에 대한 영역을 넓힐 수 있습니다. 지금 보이는 것이 Mel-Filterbank Enery 이고, 위에 있는 함수를 보면 각 영역은 N 값, 그리고 N값으로부터 정해지는 알파값에 따라 달라지기 때문에, N 이 달라지면 다른 FBEs 를 생성할 수 있습니다. 즉, N 이 MFBE 의 전체 공간을 넓혀주는 일종의 변수가 되는 것입니다. 이를 생성모델에 이용하여서, signal N이 달라졌을 때 달라지는 FBEs 를 추가적인 노이즈 소스로 사용할 수 있게 됩니다.
4. Noise sampling
3. 에서 MFBE 를 만들었으니, 이로부터 노이즈를 어떻게 샘플링해내야할지에 대해 알아볼 순서입니다. 본 논문에서는, Nb(t,f) 의 magnitude 를 가진, 즉, 영역이 제한된 오디오 시그널을 n_b(t) 라고 정의하여 이를 사용하는데 집중했습니다. 해당 영역, 즉, white noise가 주어졌을 때 Nb(t,f) > 0 이 되는 F^L ~ F^H 범위는 통과시키고, 나머지는 막는 것입니다.
white noise 의 어떤 프레임 하나가 들어왔을 때, N_b(t,f) 의 frequency 범위에 따라 직사각형의 window 를 통과시킵니다. 모든 프레임들의 DFT 를 곱합니다. 그리고 overlap-add 방식을 사용하여, 끊어져있던 프레임들을 연속적인 시간-도메인의 시그널로 변환해줍니다. 따라서, TFB의 bands 의 갯수가 B개 일때, 총 B+1 개의 band가 제한된 시그널을 얻게 됩니다.
해당 논문의 실험에서는 24개의 noise base 를 사용해서, B = 24 인걸로 실험을 적용하였습니다.
각 노이즈 시그널 n 별로, magnitude response 인 N 이 있어야합니다.
따라서, n 에 따라 서로 다른 bases 가 있으면, 이에 대해 또 서로 다른 알파값들을 적용시키고 더해서 FBE 공식이 만들어집니다. 이때, 알파는 n 에 따라 정해지니까, FBE 공간에 제약을 걸 수 있습니다. 그럼에도 불구하고 여전히 많은 종류의 노이즈가 생성되긴 합니다. 그래서 알파들을 이용하여 서로 시간 도메인에서 일정한 간격의 연속적인 값이 되도록, 알파(t) = 알파(t+k) 가 되도록 제약을 겁니다. 이를 통해, 발화 레벨별로 세그먼트를 나누는게 가능해지는 것입니다. 즉, 발화 레벨에 대한 노이즈가 각각 만들어지는 것이죠. 그러나 실험을 통해 이는 성능을 오히려 하락시키는 모습이 보여졌는데, 이는 발화레벨로 고려하는 게 frame-level 의 피쳐를 사용하는 ASR 문제에서 제안된 것이었기 때문에, ferame-level 과 segment-level 의 피쳐를 사용하는 SER 문제에서는 적합하지 않았다는 것입니다. 따라서, 본 논문에서는 실험을 통해 적절한 알파를 찾았고, 이를 이용하여 데이터 증강을 적용시켜 생성모델로부터 노이즈를 만들고, 이를 set_C noises 라는 노이즈로 정의하였습니다.
멀티 컨디셔닝 (이미 녹음된 노이즈 데이터셋을 이용해서 다양한 환경 데이터 만들기)
Noisex-92 데이터베이스를 활용하여 clean 한 발화를 오염시키는 방식으로 멀티컨디셔닝, 다양한 환경의 음성을 만들었습니다. 9가지 종류 중에 5가지 노이즈 (set_A) 는 학습데이터를 오염시키는 데 사용하였고, 나머지 4가지는 테스트데이터를 오염시키는 unseen 노이즈로 사용하였습니다. 이는 학습-테스트 환경에 간극이 존재할 때 모델의 성능이 어떻게 되는지, 즉, 모델이 unseen 노이즈에도 강인하게 작동하는지 여부를 알려줄 수 있게 됩니다.
실험
데이터셋
- Berlin Emotion Database (EmoDB) : clean 환경에서, 7가지 감정 카테고리로 녹음된 535 개의 발화 데이터셋
- Interactive Emotional Dyadic Motion Capture Database (IEMOCAP) : 대본 유무에 따라, 4가지 감정 카테고리로 녹음된 데이터셋
데이터증강
- 데이터셋 사용 비율 : 학습 (80%), 테스트 (20%)
- 오염시키는 방법 : Set_A (seen), Set_B (unseen), Set_C (생성된 노이즈)
- Speech-no-noise(SNR) level : 0dB, 5dB, 10dB, 15dB, 20dB
학습 데이터셋을 오염시킬 때에는 Kaldi tool을 사용하였습니다.
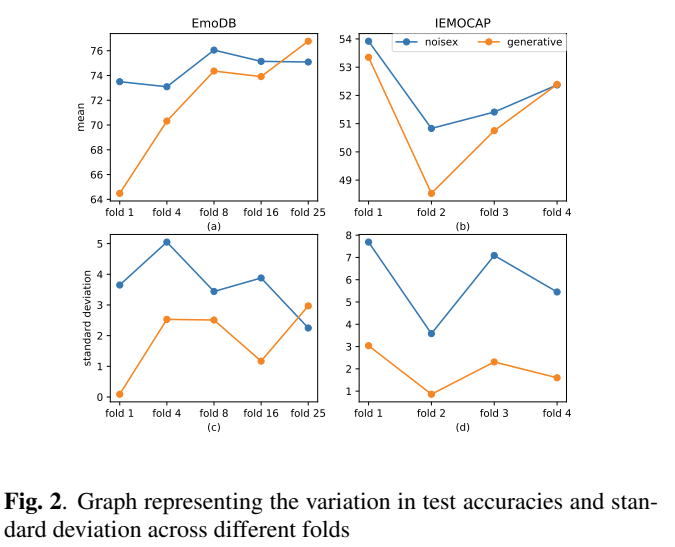
EmoDB 는 위의 방법을 이용해서 25배 증가시켰을 때, unseen noise에 대해서 생성모델로 만든 노이즈로 오염시켰을 때가, Noisex-92 노이즈로 오염시켰을 때 보다 성능이 능가하였기 때문에, 이를 사용하였습니다. 즉, 이 방식을 적용했을 때 학습데이터에 추가적인 다양성을 부과하기 때문에, data augmentation 측면에서 적합하다고 판단하였기 때문입니다.
IEMOCAP 는 augmentation 의 효과를 EmoDB 보다 못 봤고, 4배일 때 noisex 와 생성 노이즈가 비슷함을 보였습니다. 따라서, IEMOCAP 은 4배와 1배를 했을 때 적합하다고 판단했습니다. 그리고 이러한 경향성을 봤을 때, 4배 이상으로 늘리면, 성능이 더 오를 수 있을 것이라고 기대하였습니다.
오버피팅이 되지 않으면서도 학습이 잘되는 5개의 seen 노이즈 타입 & SNR 레벨의 최적의 조합을 찾기 위해, 여러 조합에 대해 실험을 진행하였다고 합니다. 이때 EmoDB 와 IEMOCAP 에 대한 결과가 달랐는데, 이는 IEMOCAP 의 학습 데이터 양이 이미 충분했기 때문이라고 분석하였습니다.
학습
- audio feature : 6552 차원의 feature vector (toolkit 사용)
- classification model : DNN (datat augmented 된 train data 의 20%를 이용하여 hyperparmeter tuning 됨
- 가장 좋은 성능을 내기 위해, 데이터셋 별로 DNN 의 레이어 유닛 수를 다르게 설정했습니다.
각각 세 가지 방법으로 모델을 학습시켰습니다.
- clean dataset 사용
- clean dataset + Noisex-92 로 augmented 된 dataset 사용
- clean dataset + 생성된 노이즈로 augmented 된 dataset
테스트
오염된 데이터셋을 사용했을 때 학습-테스트 상황에 대한 실험을 해보기 위해, 아래와 같이 세팅하였습니다.
- set_A 로 오염 (seen -> matched)
- set_B 로 오염 (unseen -> unmatched)
결과
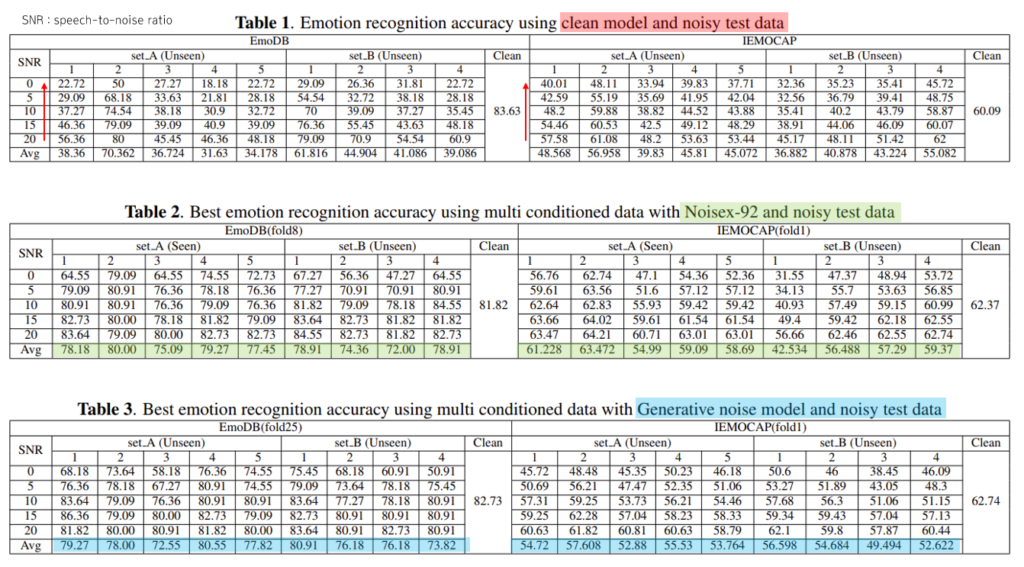
set_A 노이즈와, set_B 노이즈로 오염된 테스트데이터셋을 이용하여 감정인식 정확도 성능을 보여주는 결과입니다!
- Table 1 : 학습 시 clean 데이터셋 사용 했을 때, 테스트 데이터의 speech 비율이 적어질 수록, 즉, 노이즈가 늘어날 수록 성능이 떨어지는 모습을 볼 수 있었습니다.
- Table 2 : 학습 시 Noisex-92 노이즈 데이터셋으로 오염시켜 사용했을 때. Table 1 보다 성능이 좋음을 알 수 있었습니다. 노이즈에 좀 더 robust 한 모습을 보입니다.
- Table 3 : 학습 시 생성 모델로 만든 노이즈로 오염시켜 사용했을 때. Table 1보다 성능이 좋았고, seen 상황과 unseen 상황에 대한 모델의 성능의 차이가 Table 2 보다 작은 것을 알 수 있었습니다. 이는 데이터셋이 바뀌는 것에 대해, 즉, 환경에 대해 좀 더 robust 한 모습을 보입니다.
결론
MFBE 영역을 고려하는 노이즈를 생성 모델로 만든 후, 이를 이용하여 학습 데이터셋을 오염시키는 방법으로 학습데이터를 증강 시켰을 때, 노이즈에 대해 robust 한 음성 인식 모델을 만들어낼 수 있다! 라는 내용이 담긴 논문이었습니다.
비전 쪽에서 이미지를 transform 시켜서 데이터를 늘리듯이, 음성 쪽에서는 노이즈를 이용해서 늘리는 것이 비슷하다고 생각했습니다. 또한 pixel level, frame-level 을 고려하는 것처럼, 음성은 MFCC, MFBE 를 고려하기도 하는 게 비슷한 것 같습니다. 음성 데이터의 영역이 어떤 게 있는지 다 모르고 수식도 아직 헷갈리는 부분이 많아서… 다른 논문들을 읽을 때도 이러한 부분을 유심히 봐야할 것 같습니다. 이상으로 리뷰 마치도록 하겠습니다. 감사합니다.
좋은 리뷰 감사합니다. 이 논문에서는 음성인식 데이터셋에 노이즈를 추가하여 모델을 robust하게 만드는 연구였는데 반대로 노이즈가 있는 음성인식 데이터셋의 노이즈를 제거하는 처리를 한 후에 성능을 올리는 연구도 혹시 있는지 궁금합니다.
실질적으로 성능을 실험을 해보려면 생성 모델로 학습하고, noisex-92 데이터셋으로 오염시킨 경우에 대한 실험 결과가 있어야 할 것 같은데 이에 대한 내용은 없나요? 실제 환경에 대한 테스트의 경우에는 이 경우가 더 적합해 보이는데 말이죠.