최근에 object centric image retireval 논문으로 DELF를 읽었는데요. 물체 중심 이미지 검색 연구들을 찾아보니 DOLG라는 연구도 있고, 그 연구의 앞선 연구로 DELG라는 논문을 찾았습니다. 읽어두면 도움이 될 것 같아서… 읽게 되었습니다.
Introduction
논문 이름에서는 드러나지 않지만, 논문에서 제시한 프레임워크 이름에서 알 수 있듯이 DELF의 영향을 많이 받은 논문으로 보입니다. DELG(deep local and global features)는 기존 DELF가 two-stage 학습 방식을 취하고 있는데, 이 부분은 one-stage로 변경하고 end-to-end 학습이 가능하게 변경했습니다.
일단 기존의 시스템이 어떻게 작동하는지를 알아야합니다. 일단 이미지 검색에서 사용하는 global feature는 매우 다른 전경에 대한 유사도를 학습할 수 있습니다. (일반적으로 recall이 높음) 그리고 local feature를 기반으로한 geometric verification은 이미지의 유사도를 잘 나타탭니다. (일반적으로 precision이 높음)
이러한 이유 때문에, 기존의 이미지 검색 시스템에서 global feature를 통해 retireval을 하고, retreival 결과를 바탕으로 local feature를 이용해서 re-rank 과정을 거치는 것도 이러한 특징과 관련이 있습니다.
어쨋든 이 논문에서는 이러한 부분들을 고려해서 One-stage / end-to-end 학습 구조를 가진 DELG를 제안합니다.
- DELG라고 부르는 local feature와 global feature를 통합한 모델 제안
- low-dimensional local descriptors를 학습할 수 있는 convolutional autoencoder를 제안 (PCA 대체)
- image-level supervision을 활용해서 end-to-end 학습이 가능하도록 설계함
DELG
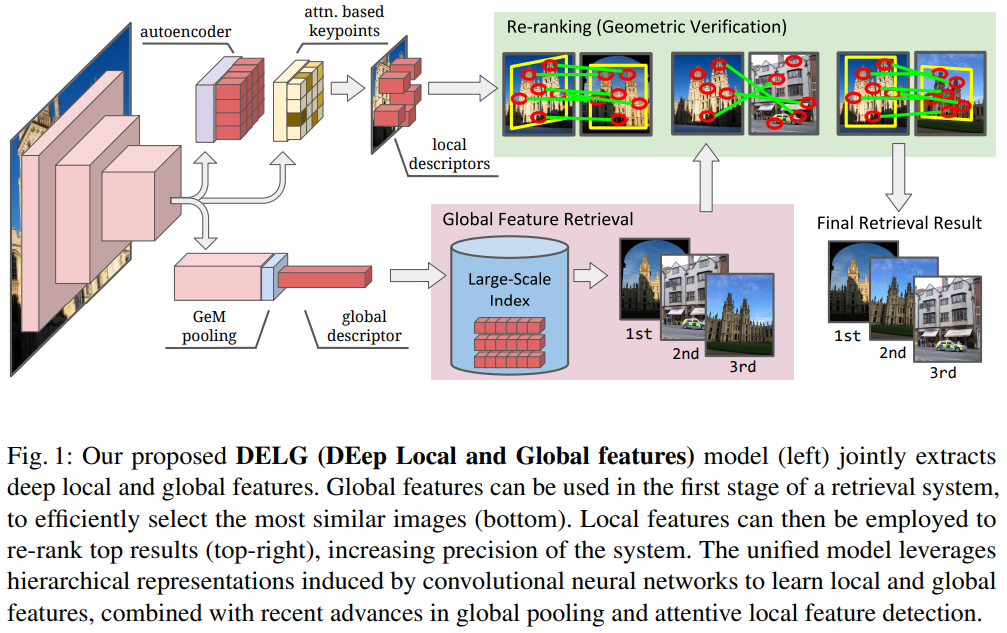
그래서 이 DELG의 구조도는 위와 같습니다. 기본적으로 Retireval → Rerank하는 과정은 똑같지만, global feature와 local feature를 학습하는 방법이 다릅니다. 기본적으로는 CNN의 계층적인 표현 구조를 이용하는데요, 이는 레이어가 깊어지면 global feature에 도움이 되고, local feature는 지역적인 정보에 더 적합하기 때문입니다.
그럼 이 과정에서 global feature는 어떻게 만들어지는가…
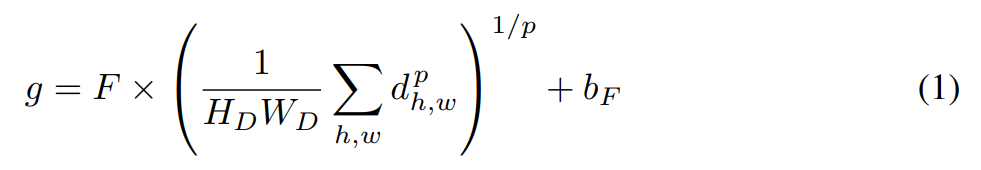
먼저 global feature를 효율적으로 병합하기 위해 generalized mean pooling(GeM)을 사용합니다. 그리고 whitening을 하기 위한 FC 레이어를 모델에 붙여 사용합니다. 그래서 GeM과 FC레이어가 합쳐진 수식을 (1)에서 확인할 수 있습니다.
다음으로 local feature에서 중요한 것은 matching을 효율적으로 하기 위해 유사한 부분을 선택하는 것이 중요합니다. 이 작업을 잘 하기 위해서 본 논문에서 local feature에서 차별적인 특징이 있는 부분을 강조해주는 attention module을 사용했습니다. 이와 더불어 많은 local feautre가 사용되는데 있어서 compact함을 추가하기 위해서 일반적으로 PCA와 같은 방식을 도입하는 대신에 small convolutional autoencoder를 도입해서 모델을 구성했습니다.
Training
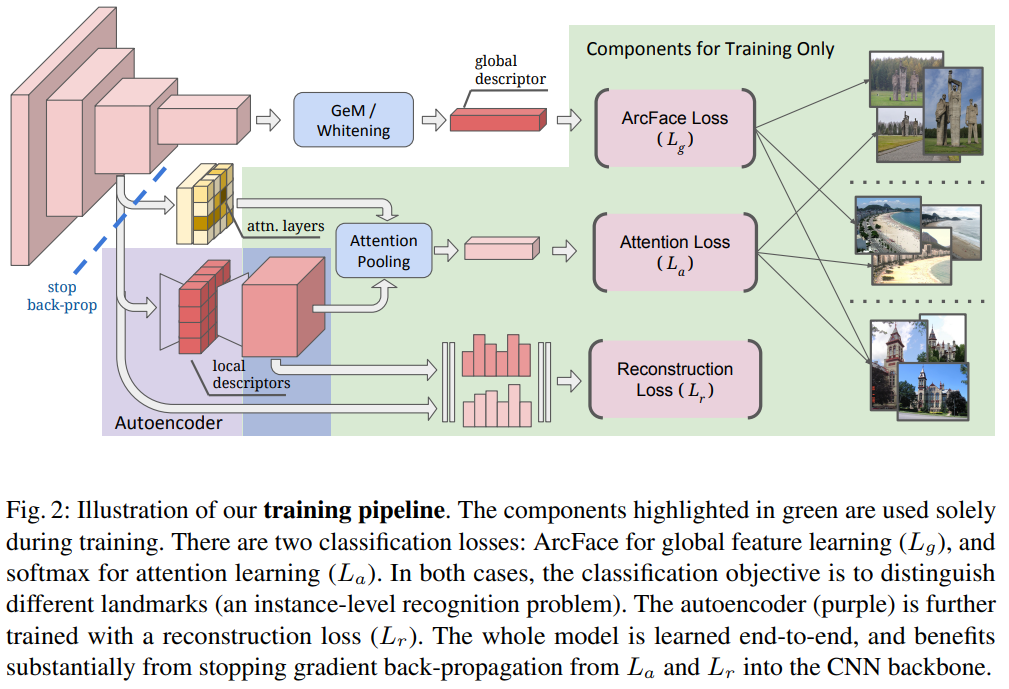
학습 과정을 보면 위와 같습니다. 이 논문의 컨셉이 “End-to-End”와 “One-stage”를 반영한 학습 구조입니다. 자세히 보면 Loss는 3가지를 사용하고 있는데요.
Global Feature를 기반으로 사용되는 ArcFace Loss 먼저 보겠습니다. ArcFace Loss는 얼굴인식 쪽에서 제안된 Loss로 Softmax 대비 모델이 좀 더 분별력이 있는 embedding을 학습할 수 있게 하는 Loss입니다. 본 논문에서는 global feature를 학습하는데 있어서 적은 intra-class variance를 가져서 사용했다고 합니다.
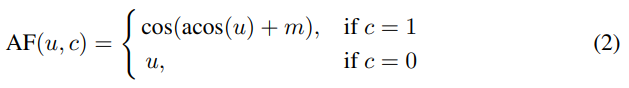
이 ArcFace Loss는 (2)번 수식과 같이 구성이 되는데요. u는 cosine similarity를 의미하고, m은 ArcFace margin, c는 같은 class인지 아닌지를 나타내주는 값입니다.
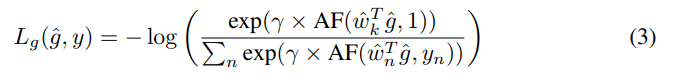
그래서 이 ArcFace Loss는 softmax norm과 함께 cross entropy loss로 최종적으로 만들어집니다.
Local Feature는 두개의 Loss에서 사용됩니다. Reconstruction Loss와 Attention Loss인데요.
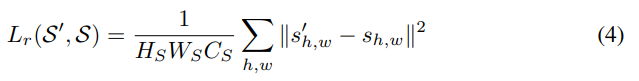
Reconstruction Loss는 MSE를 기반으로 작동합니다. s가 원본이고 s’가 복원된 버전이라고 할때 위와 같은 Loss를 가집니다. 이 Loss는 모델 그림에 있는 autoencoder를 학습시킨다고 보면 됩니다.

다음으로 Attention Loss가 있습니다. 위의 수식을 보면 a와 s’이 있는데요. a는 attention feature를 나타내고, s’는 autoencoder의 첫번째 풀링된 값을 의미합니다. (그림2의 Attention Pooling이 이 부분입니다)
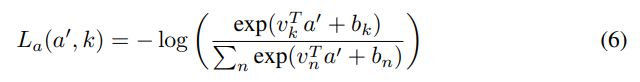
Attention된 결과 a’일때, k는 GT를 나타냅니다. (v=weight, b=bias) 최종적으로는 구별력을 가진 feature의 attention weight를 증가시키는 방향으로 cross-entropy classification loss를 학습하게됩니다.
마지막으로 “stop back-prop”이 그림에 있는 것을 볼 수 있는데요. 이 부분은 단순하게 3개의 Loss를 backprop을 던지면 local feature가 sematic한 정보를 많이 학습하는 경향이 있었다고 합니다. 그래서 Local feature를 사용하는 두개의 loss는 백본 네트워크에 backprop을 하지 않도록 수정해서 이 문제를 해결했다고 합니다.
Experiments
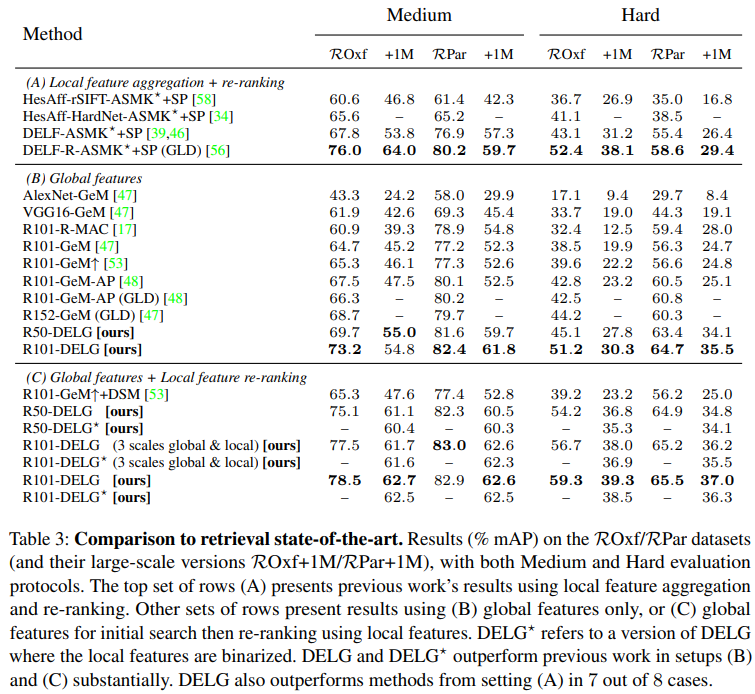
물체 중심 이미지 검색에서 주로 사용하는 데이터셋인 Oxford, Paris 데이터셋의 revisited annotation 버전을 사용했습니다. +1M이 붙은 경우에는 R1M dataset이라고 distractor가 추가된 경우입니다. 표3의 경우에는 SOTA 모델들과의 비교 실험이었는데요. 제안된 DELG 모델이 모든 경우에서 성능이 좋은 것을 볼 수 있습니다.
Ablation
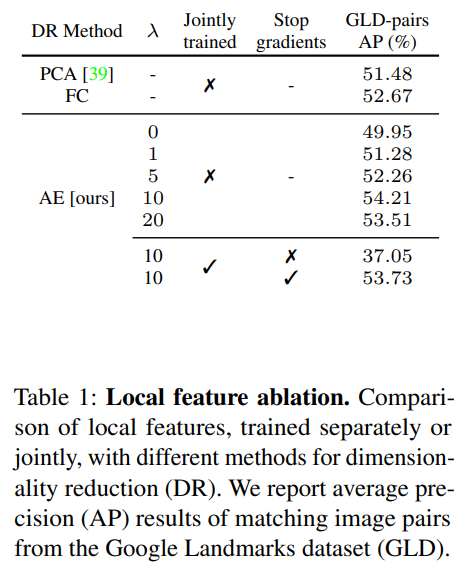
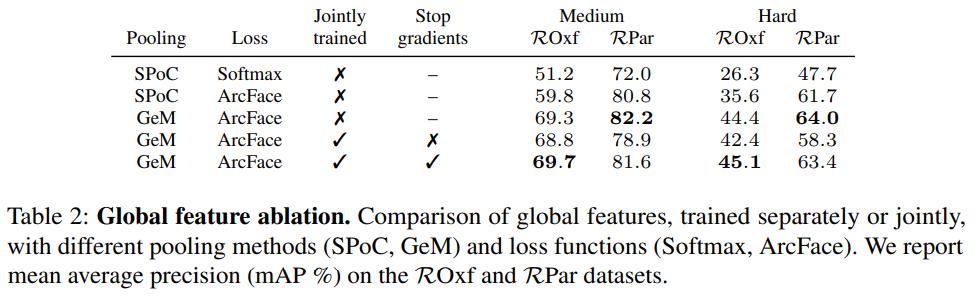
위 두표는 Local feature에 적용된 방법론들과 Global feature에 적용된 방법론들에 대한 ablation study입니다. 표 1에서 주목할만한 부분은 stop gradient의 유무에 따른 성능 차이가 심한데요. 논문 저자들이 주장한대로 local feature와 global feature가 각각 필요한 부분을 학습하는 것이 중요하다는 점을 드러냅니다. 그리고 표 2에서는 풀링 방식과 Loss에 대한 실험이 이어집니다. 의외로 Joint trained를 하지 않았을 때의 Paris에서의 성능이 약간 높은 것을 볼 수 있는데요. 그래도 성능 폭을 비교했을 때 joint trained + stop gradient를 쓰는 것이 좋았다고 판단한 것 같습니다. 사실 이 경우에는 당연한 것이 global feature와 local feature가 따로따로 최적화 될 것이므로, end-to-end로 만들기 위해서는 감수해야할 부분 같습니다.
Conclusion
설명이 약간 불친절 한 것 같은… 논문이었네요. 기호를 좀 더 친절하게 적어줬으면 이해가 더 쉬웠을 것 같습니다. 논문은 결국 DELF를 end-to-end로 바꾸기 위해서 많은 노력을 한 것 같습니다.