Before Review
이번에도 Weakly Supervised Temporal Localization 논문입니다. Weakly Supervised Temporal Localization을 주제로 이제 깊게 파보려고 합니다. 때문에 최신의 논문만 읽는 것이 아니라 아이디어가 제안되던 초기의 논문을 읽는 것도 중요하겠다 생각이 들어 Weakly Supervised Temporal Localization의 초기 방법론인 논문을 읽게 됐습니다.
최근 22년도, 21년도에 나온 방법론들에 비하면 간단한 수준이지만 당시에는 이것이 활발하게 연구가 되지 않았기 때문에 그러한 점으로 인해 CVPR에 Publish가 되지 않았나 싶습니다.
그럼 리뷰 시작하도록 하겠습니다.
Introduction
논문의 Introduction은 간단합니다. Video Temporal Localization은 비디오를 이해하는 데 있어 중요한 task이지만 대다수의 연구들이 대용량의 어노테이션에 의존하는 경향이 있다. 우리는 이러한 문제를 해결할 수 있는 novel deep-learning framework를 제안했다 라고 얘기합니다.
제가 최근 Weakly Supervised Temporal Localization 논문들을 리뷰할 때 항상 설명했던 개념이 있었습니다. Class Activation Sequence라는 것인데, 그것이 여기서 처음으로 제안이 되었다고 하네요. 18년도에 제안되고 아직까지 사용될 정도면 아이디어가 정말 General 하고 성능이 좋아서 사용이 되는 것 같습니다.
본 논문에서는 이를 Temporal Class Activation Map(T-CAM)이라 정의하였습니다.
방법론을 이해하는 데는 어렵지 않았고, 저는 이 논문을 읽으면서 실험하는 데 있어 필요한 디테일한 요소들 그것들을 좀 중점적으로 살펴봤습니다. 왜냐하면 여기서 사용된 Implementation detail 들이 후속연구에 계속해서 사용이 되기 때문입니다.
그럼 우선 방법론에 대해서 알아보도록 하겠습니다.
Proposed Algorithm
구조 자체는 간단합니다. Loss도 두개의 term만 사용해서 정의가 되고 있고 우리가 평소에 너무 잘 알고 있는 형태라 이해하는 데 어려움을 없을 것 같습니다. 우선 비디오에 대해서 전체 구간에 대해서 T개의 segment를 sampling 하여 Backbone Encoder 통해 Segment level의 feature를 기술 합니다. 아래의 그림을 보면 T개의 segment를 가지고 attention module을 통과 시킵니다.
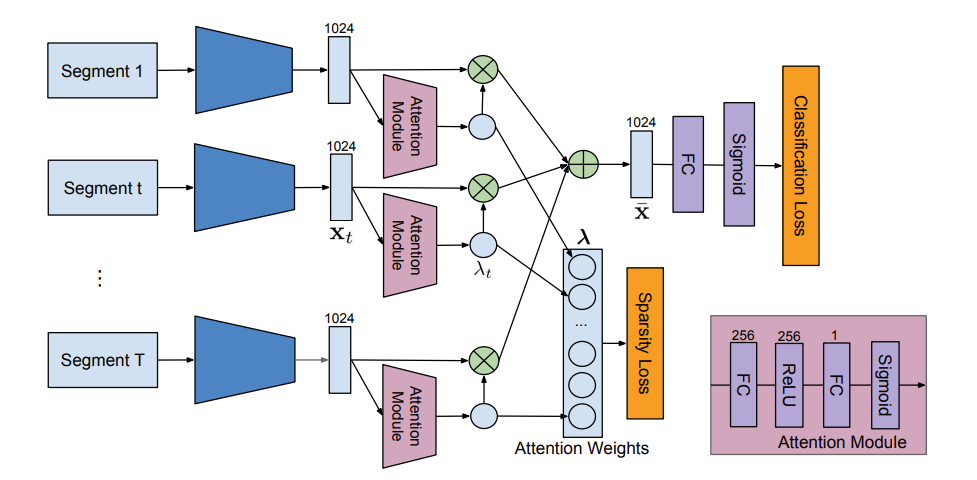
자 그럼 여기 attention module의 역할이 무엇인지 설명을 드리면 Segment 중 중요한 segment를 고르겠다는 의미입니다. Untrimmed Video에서는 비디오의 모든 부분이 중요하지 않죠. 그러다 보니 저자는 특별한 Class에 관계 없이 Localization을 하는 데 있어서 중요한 region을 고를 수 있는 attention을 고안합니다.
그런데 단순히 저렇게 FC Layer 두 겹 쌓는 다고 해서 그 목적이 이루어지기는 힘들 것 입니다. 그래서 저자는 Sparsity Loss를 추가 합니다. 여기서 정말로 진짜 action에만 attention을 줄 수 있게 attention weight의 분포를 조금 수정해야할 필요가 있습니다. 진짜 action인 구간에만 큰 값을 가지고 background에는 작은 값을 가질 수 있게 해야겠죠.
L1-regularization은 특정 값을 줄이고 특정 값을 키우는 정규화를 수행하여 parameter마다의 영향력을 늘이고 줄일 수 있습니다. 딱 우리의 목적과도 동일하네요. action 구간에 해당하는 attention weight를 키우고 background 구간에 해당하는 attention weight를 줄일 수 있다면 L1-regularization을 통해 sparsity 문제를 해결할 수 있습니다.
그래서 sparsity loss는 그냥 Attention Module에 대한 L1-Regularization Loss 입니다.
그리고 Classification은 어떻게 수행을 하냐면 우리가 뽑은 T개의 Segment Feature가 있습니다. 여기에 attention weight를 각각 곱해주고 모두 더해줍니다. 수식으로 보면 아래와 같습니다.
- \bar{x} =\sum^{T}_{t=1} \lambda_{t} x_{t}
여기에 FC Layer를 태우고 Sigmoid를 태운 다음 Video Level의 Classification이 수행됩니다. 단순히 Classification 문제이기 때문에 우리가 흔히 아는 Cross Entropy Loss를 가지고 학습을 진행할 수 있습니다. 그래서 최종 Loss는 아래와 같습니다.
- L_{class}+\beta L_{sparsity}
이것이 Model Architecture의 전부 입니다. 상당히 간단하죠? 학습 코드 자체만 보면 빡세게 코딩해서 원복할 수 있을 것 같습니다.
Experiments
실험으로 넘어가겠습니다.
Dataset
THUMOS14 dataset : 원래는 101가지의 action class를 가지는 데이터셋이지만 그 중 20개의 class에 대해서만 temporal annotation을 제공합니다. 저는 몰랐는데 보통 200개의 validation video로 학습을 진행하고 213개의 test video로 평가를 한다고 합니다. 200개의 비디오만 사용한다고 해서 task의 난이도가 쉬운것은 아닙니다. 왜냐하면 비디오의 길이가 평균 26분 정도이기 때문이죠. 그래도 보통 경향성을 볼때는 ActivityNet 보다는 THUMOS로 보는 편이긴 합니다.
ActivityNet dataset : 200가지의 action class를 가지고 있는 데이터셋으로 temporal action localization benchmark를 위해 등장한 데이터셋 입니다. 평소에는 test data에 대해서 평가를 할 수 없고 activitynet challenge 기간에만 평가 서버가 열려서 test data에 대해서 평가할 수 있습니다. 이러한 제한적인 상황때문에 보통 연구를 할때는 10024개의 train 데이터로 학습하고 4926개의 validation 데이터로 평가를 진행하다고 합니다.
우선 THUMOS14 데이터셋에 대한 benchmark를 먼저 보도록 하겠습니다.
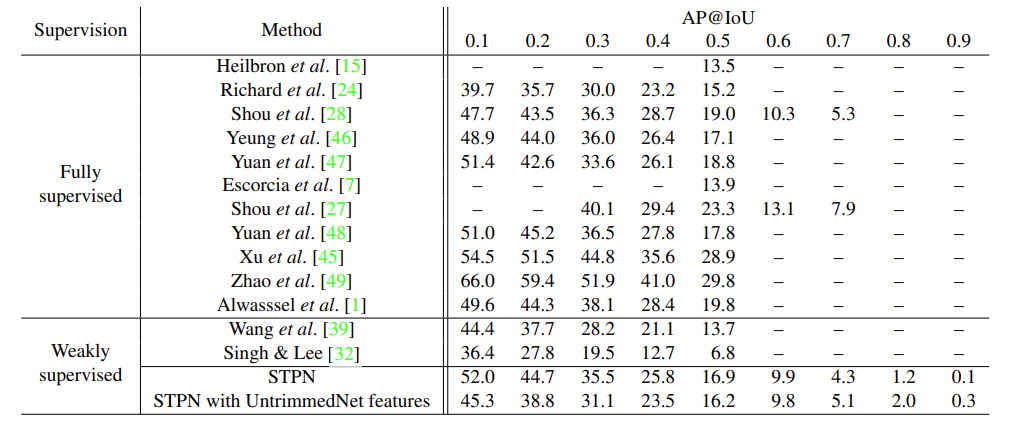
일단 Weakly Supervised 분야에서는 가장 높은 성능을 보여주고 있습니다. 당시에는 연구가 활발하지 않아 비교군이 많지는 않았지만 그래도 성능 향상폭이 이전 연구에 비해 상당한 것을 보여주고 있습니다. 꽤나 파격적으로 성능이 오른탓에 당시에 몇몇 Supervised Benchmark를 이기는 모습을 보여주고 있네요.
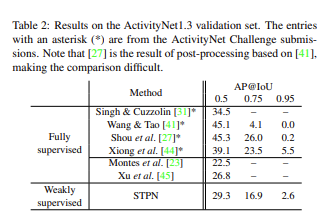
다음으로는 ActivityNet에 대한 benchmark입니다. 이전에는 ActivityNet으로 Weakly Supervised Temporal Localization을 평가하는 경우가 없어서 이번 논문이 처음이라고 합니다. STPN의 저 성능은 계속해서 후속 연구들의 benchmark로써 작용하고 있으니 많은 연구자들이 자신들의 방법론이 어느정도 인지 판가름하는 데 도움을 줬을 것 같습니다. 확실히 ActivityNet에서는 당시 Supervised method에 비해서는 떨어지는 성능을 보여주네요.
다음으로는 정성적 결과입니다. Untrimmed Video에서 볼 수 있는 4가지 케이스를 분석하였는데 꽤나 흥미롭습니다.
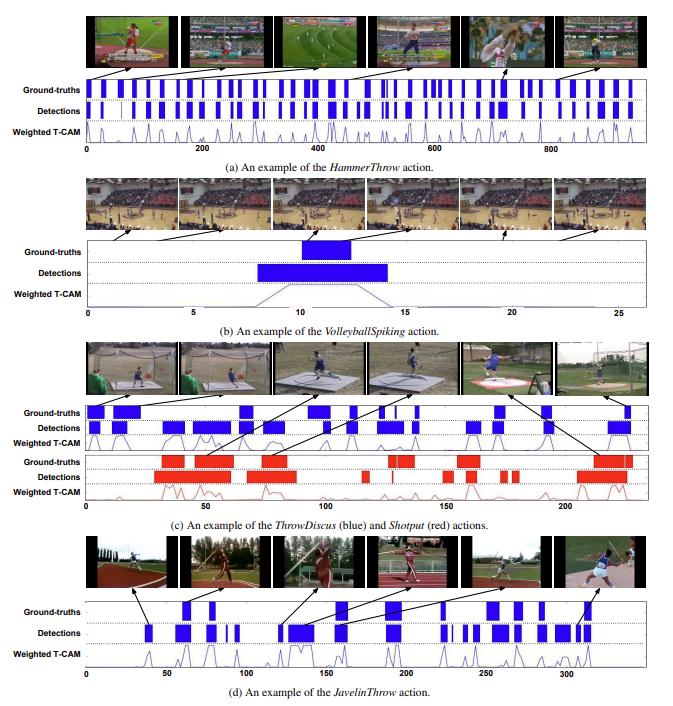
가장 위에 (a)를 보면 HammerThrow action에 대한 영상입니다. GT를 보면 상당히 많은 action 구간이 존재하고 있습니다. 본 방법론이 정확하게 까지는 예측하지 못하지만 pinpoint 정도는 잡고 있다는 것이 꽤나 흥미롭습니다.
(b)를 보면 원래의 GT구간보다 더 넓은 영역을 예측하고 있습니다. 그런데 사실 GT 구간과 아닌 구간이 상당히 시각적으로 비슷하기 때문에 모델이 저렇게 예측을 한 것 같네요. 저런 경우는 조금 애매한 것 같네요. 못했다고 해야할 지 잘했다고 해야할지…
(c)를 보면 하나의 영상에 두가지 action이 있는 상황입니다. 여기서는 Localization 정확도가 조금 떨어지지만 그래도 category는 꽤나 잘 예측하는 것을 보여주고 있습니다.
마지막으로 (d)를 보면 꽤나 많은 false positive를 볼 수 있습니다. 그런데 저자는 이에 대한 반박(?)으로 Javelin Throw action에 대해서 GT가 조금 이상하다는 점을 주장합니다. 그림을 자세히 보면 분명 action인 장면인데 action이 아닌 background라고 라벨링이 되었기 때문에 맞게 예측을 해도 false positive라 평가가 되고 있는 상황입니다.
실제로 몇몇 논문에서 보기로 ActivityNet의 temporal annotation이 조금 부정확한 경우가 있다고 들었습니다. 저자는 이를 꼭 집어서 얘기를 했네요.
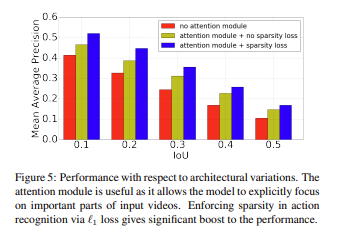
Ablation Study 입니다. 본 논문의 제안된 모듈이 많지 않다보니깐 간단하게 느껴질 수 있습니다. 결론적으로 얘기하면 Sparsity Loss와 attention module을 둘 다 사용한 것이 가장 좋은 성능을 보여주고 있습니다.
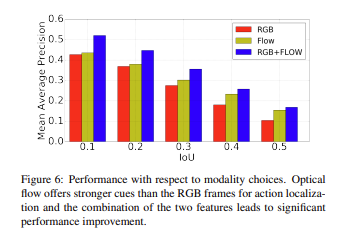
다음으로는 Modality에 대한 실험 입니다. RGB와 Optical Flow를 둘 다 무조건 사용해야 하는 이유를 보여주는 그래프 입니다. 실제로 action recognition 분야에서도 optical flow를 같이 사용했을 때 성능이 boosting 되는 것처럼 마찬가지로 localization에서도 먹힌다는 것을 보여주고 있습니다.
RGB frame은 시각적인 정보를 capture하는 데 도움이 될 수 있고 optical flow는 action이나 motion에 대한 정보를 capture하는 데 도움이 될 수 있습니다.
Conclusion
Weakly Supervised Temporal Localization이 연구되던 초반에 나온 논문이라 방법론적인 측면에서는 크게 참신하지는 않지만 그래도 실험적인 디테일한 부분에서 몇가지 알아갈 수 있었던 논문인 것 같습니다.
본 논문에서 제안된 Sparsitiy Loss가 후에 발전되어 [CVPR 2021] Action Unit Memory Network for Weakly Supervised Temporal Action Localization 여기서도 다시 등장하니 최신 연구들만 보는게 아니라 종종 예전 연구들도 확인을 해야할 필요가 있는 것 같습니다.
Code가 Tensorflow로 작성되어 있지만 구조 자체가 워낙 간단해서 Pytorch로 연습삼아 원복해보는 것도 나쁘지 않을 것 같다는 생각이 들었습니다. 아무래도 이쪽으로 계속 연구를 하려면 이 Task에 대해서도 코드를 다루는 데 있어 연습을 해야하기 때문이죠.
아무튼 이상으로 리뷰 마치도록 하겠습니다.
여기서 말하는 segment-level feature의 segment는 고정 길이의 짧은 clip에 가깝나요 혹은 가변 길이의 shot에 가깝나요
좋은 리뷰 감사합니다.
논문의 implementation detail이 이후 연구에도 사용되고 있다고 하셔서 리뷰를 읽은 뒤 무슨 내용인지 살펴보았습니다. 학습할 때 sampled segment의 data augmentation을 위해 ‘stratified random perturbation’을 수행한다고 되어 있는데, stratified random perturbation이 대략적으로 어떤 과정인지 설명해주실 수 있나요?
좋은 리뷰 감사합니다.
해당 논문과 task에 관해 궁금한 것이 있어서 질문을 남깁니다.
방법론이 weakly supervised 방식이라 하셨는데 Untrimmed 비디오에 대해 행동이 있는지 없는지 여부만을 라벨링 하여 weakly supervised 방식인 것인가요??