
정말 오랜만에 엑스리뷰를 쓰게 되었네요. 오랜만에 돌아온 만큼, 지난 리뷰도 다시 상기시키면서 최신 방법론까지 익힐 수 있는 논문에 대한 리뷰를 해보려고 합니다. 바로 self-supervised leaning 분야의 MoCo v3 에 대해 리뷰해보도록 하겠습니다.
시작에 앞서 MoCo 에 대하여 간단하게 다시 돌아보고 리뷰를 하겠습니다. (자세한 리뷰가 궁금하신 분은 이전 리뷰(Moco v1)를 읽어보시는 것을 추천드립니다)
MoCo는 self-supervised learning의 대표 방법론 중 하나입니다. 2019년도에 FAIR 에서 발표하였고, Queue를 통해 Dictionary lookup 하는 것에서 모티베이션된 Contrastive learning 기반의 self-learning 방법입니다. dictionary lookup 이라고 하는 이유는 query를 요청하면 각 이미지를 대표하는 벡터 k 개의 Key로 구성된 queue (딕셔너리) 중 하나를 반환하는 것과 같다는 것에서 착안된 것입니다.
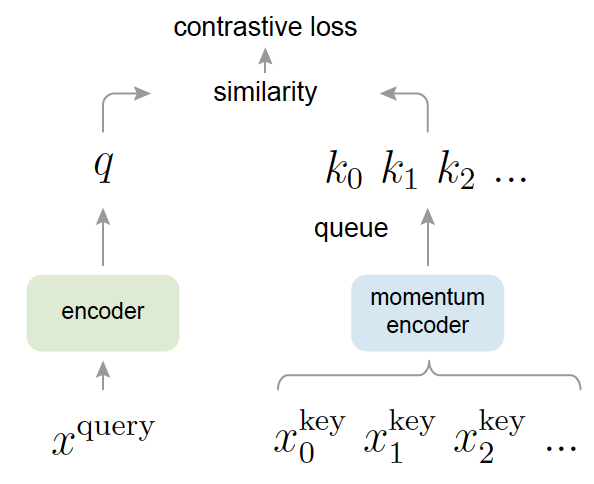
우선 하나의 이미지 x[\latex]에 대해서 서로 다른 augmentation을 수행합니다. 그럼 [latex]x_1, x_2가 나오겠죠. 이해하기 쉽게 배치 사이즈가 4라고 가정해봅시다. 그럼 총 8개의 이미지가 발생하게 됩니다. 이 때, 여느 self-learning처럼 같은 이미지에서 나온 한 쌍의 이미지만을 positive pair로, 서로 다른 이미지끼리는 negative pair로 가정합니다.
이렇게 두 개의 augmentation을 통해 나온 이미지는 q encoder 와 k encoder로 나누어 들어갑니다. (q 는 query encode k는 key encoder) . 이제 k encoder에는 4개의 이미지(배치가 4이므로)에 대한 feature를 뽑고 queue에 추가합니다. 그리고 q encoder에는 이미지를 하나씩 받아 feature로 변환하고 축적되어 저장되있는 queue의 feature들과 contrastive loss를 총 4번 계산합니다.
4개의 이미지에서 나온 loss를 모두 더해 최종 Loss를 바로 q encoder에 적용하여 역전파를 통해 업데이트를 수행하되, k encoder에는 q encoder와의 momentum을 계산하여 업데이트 하게 됩니다. 여기서 MoCo의 contribution 2가지가 나오는데요. 우선 momentum을 적용하여 아주 조금식 업데이트 되기 때문에 key encoder는 일관성있는 Feature를 추출할 수 있도록 업데이트가 되었다는 점(이를 적용하지 않으면 이미지마다 급작스럽게 encoder가 업데이트 될 수 있음). 그리고 queue를 사용하여 어마무시하게 큰 배치를 사용하지 않고도 많은 negative pair가 축적되어 고려되었다는 점이 있습니다. 디테일한 부분은 앞서 리뷰한 내용을 참고해주시기 바랍니다
Moco가 공개된 뒤, self-supervised learning의 양대산맥인 SimCLR가 발표되었고, 그 SimCLR에 사용한 방법론들을 MoCo에 추가하여 MoCo v2를 발표하게 됩니다. MoCo v2 에는 SimCLR에서 사용한 Head projection 를 추가시키고, augmentation을 추가하며 cosine learning rate schedule 을 추가하여 SimCLR보다 성능을 향상시켰습니다.
이번에 리뷰할 MoCo v3는 기존 MoCo v2에 ViT를 접목시켜 성능 향상을 가져온 논문입니다. (그래서 그런지 논문이 시작되는 가장 처음 문장에서도 “본 논문에서는 새로운 방법을 제시하는 게 아니다" 라고 하던게 굉장히 임팩트가 있었습니다..)
MoCo 에 대해 알아보았으면 이제 MoCo v3 리뷰를 시작하도록 하겠습니다.
An Empirical Study of Training Self-Supervised Vision Transformers

Introduction
시작부터 self-learning에 ViT를 적용하기 위한 (즉, 학습이 불안정한 self-learning에 마찬가지로 학습이 불안정한 Transformer를 적용하기 위한 베이스라인을 제공) 논문이라고 선전포고(?)를 합니다. 다시 말해, ViT가 가장 유행하고 최신(논문이 발표된 시점 기준) 방법론임을 감안하면 너무 당연한 확장이라는 것이죠. 따라서 본 논문에서는 MoCo를 포함한 Siamese networks에서의 Transformer 적용에 대한 연구를 보고하였습니다.
왜냐하면 CNN과는 달리 ViT를 다루는 학습법은 아직 확립되지 않았기 때문에, 배치 크기, 학습 속도 및 최적화를 위한 방법론에 대해서 다루게 됩니다. 또한 다양한 불안정성에 대해서도 다루게 됩니다.
결국 본 논문을 한 줄 요약하면. MoCo v2를 개선시키고, 다양한 실험을 통해 self-supervised ViT의 효과 및 성능을 확인하고, 결과적으로 Contrastive learning을 사용하는 self-supervised transformer가 좋은 성능을 보인다고 이야기할 수 있을 것 같습니다. 이제 리뷰 시작합니다.
MoCo v3
MoCo를 개선시킨 만큼 일단 MoCo 와 가장 큰 차이점에 대해 알아봐야할 것 같은데요. MoCo v3는 MoCo의 핵심 아이디어인 queue 구조의 dictionary를 없앴습니다. 그리고 4096이라는 아주 큰 배치 사이즈를 사용하여 배치 내부의 이미지를 nagative 로서 사용하였습니다. 또한 SImCLR에서 등장한 MLP기반의 projection head를 query encoder에는 추가하고, key eoncder 에는 추가하지 않은 채로 모델을 구성하였습니다. 여기까지가 MoCo v3 입니다.
(그런데 여기서만 봤을 때... 이걸 과연 MoCo V3이라고 할 수 있을지... 의문이랄까요 ... 결국 SimCLR와 BYOL을 기반으로 momentum update 만 추가한 것 같습니다만 ........? 결국 MoCo까지 SimCLR를 기반으로 개선되는 것 같습니다)

그리고 지금까지 설명드린 내용을 수도코드로 정리한 것입니다. 그래서 달성한 성능은 아래와 같습니다.

여기까지가 CNN 기반의 성능 개선을 가져온 MoCo v3 이었습니다.
Stability of Self-Supervised ViT Training
이제 이 MoCo v3에 ViT 를 적용하는 방법에 대해 말씀드리도록 하겠습니다. (ViT를 적용하게 된 이유는 뭐 다들 아시다시피, ViT가 떠오르고 있었고 현재 흐름에 따라 Contrastive 기반의 SSL에 적용하게 되었다고 하네요)
MoCo v3에 ViT를 곧바로 적용하게되면, 우선 ‘instability’ 문제가 발생하게 됩니다. 앞서 MoCo v3는 queue를 없애고 배치를 키워 성능 향상을 가져왔다고 하였는데요, 여기서는 이게 문제가 됩니다. 배치 사이즈를 키울수록 학습 정확도는 오히려 떨어졌다는 반대의 결과가 나온 것이죠.
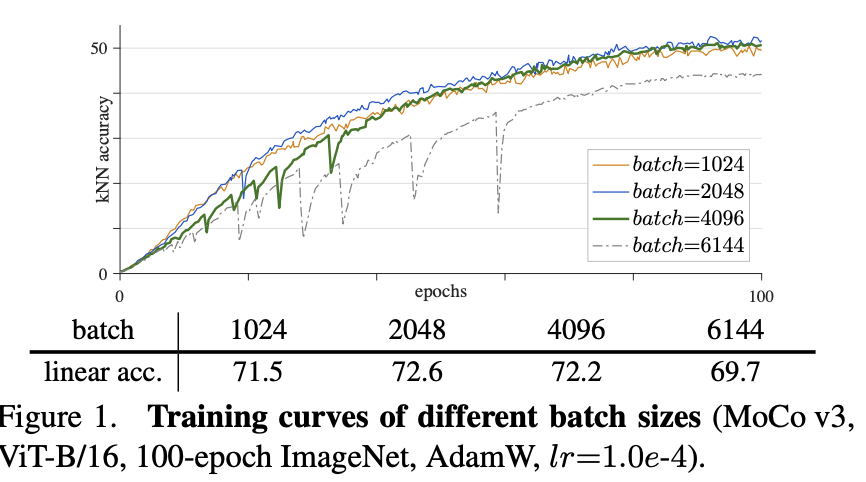
이를 분석하기 위해 kNN을 통한 결과를 epoch가 아닌 10 iteration 마다 확인했는데, 배치를 키울수록 kNN curve 에서 dips 가 많이 발생되었으며, 정확도 역시 줄어들었다는 결론을 내립니다. (위 그래프 중 batch가 2048일 때는 72.6% 의 accuracy와 kNN curve 역시 성능이 훅 떨어지는 dip이 덜 발견되고 부드럽습니다. 반면 배치 사이즈를 4096 이상으로 늘릴 수록 dips 가 많이 발생하는 것을 볼 수 있습니다)
이 문제를 lr, optimize을 바꿔가며 다양한 결과를 리포팅합니다.
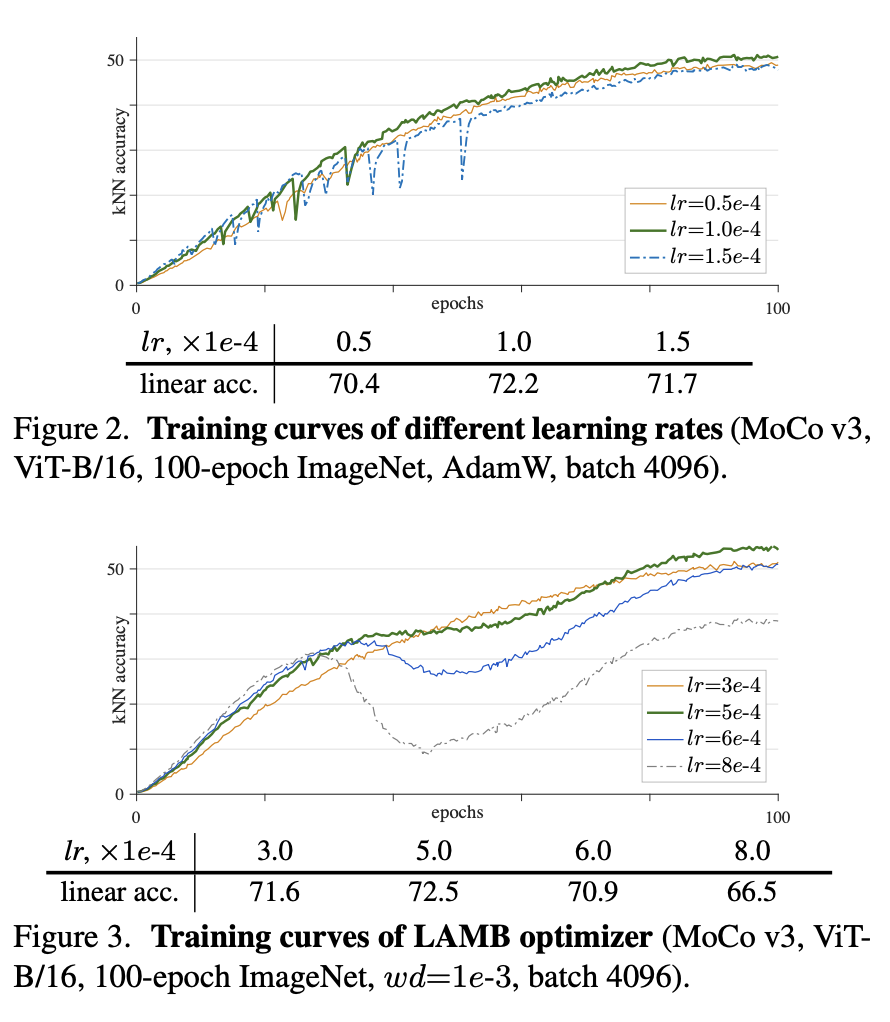
lr은 linear scaling rule(lr*batch_size/256)에 따라 결정하였다고 합니다. 그리고 lr을 조정해가며 다양한 실험을 하는데요, Fig2를 보면 lr이 커질수록 dips가 많아져 학습이 불안정하였다는 결과를 볼 수 있었습니다. 그러나 또 너무 작게하면 underfitting으로 인해 성능이 오히려 낮아졌다는 결과를 보였습니다. 따라서 적절한 Lr을 찾는 것이 중요하엿습니다. 그리고 optimizaer 도 AdamW와 LAMB 두 개를 바꿔보는데요, 저자가 말하기론 Fig 3처럼 LAMB가 더 민감했다고 하였습니다. 따라서 본 논문에서는 AdamW를 default optimizer로 사용하였습니다.
여기까지 ViT를 MoCo v3에 적용하였을 때의 불안정성에 대하여 알아보았습니다. 이제 뒤에서는 정말 왜 불안정한지를 알아보기 위해 Layer 별로 학습이 진행됨에 따라 gradient 곡선을 그려보는 분석을 합니다.
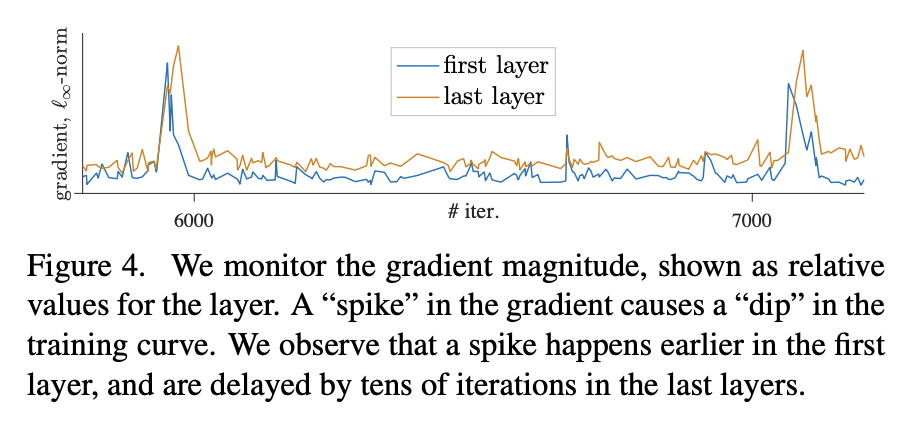
이 그림을 보면 첫번째 레이어에 gradient spike가 발생하고, 일정 Epoch 이후 last layer 에 Gradient spike가 발생하였다고 합니다. 이 결과를 통해 불안정성은 shallower layer에서 발생한 것이라고 분석하였는데요.. 이게 무슨 소리냐면, gradient가 급격하게 변하는 구간이 바로 kNN accuracy curve 에서의 dips를 발생시킨 것이고, 이러한 급격한 변화는 주로 첫번째 Layer에서 발생하여 뒤의 레이어로 전파되기 때문에 학습이 불안정한 것이라고 이야기하는 겁니다.
따라서 저자는 간단한 트릭으로 가정한 문제를 해결하고자 하였습니다. 바로 첫번째 레이어에서 불안정성이 감지되었으니, 이 가장 앞 단의 레이어인 patch projection layer를 freezing 시킨 후 학습을 진행하는 방법 입니다. 다시 말해 ViT에서 patch를 임베딩으로 변환해주는 레이어를 학습하지 않고 random patch projection을 수행한다는 트릭입니다.
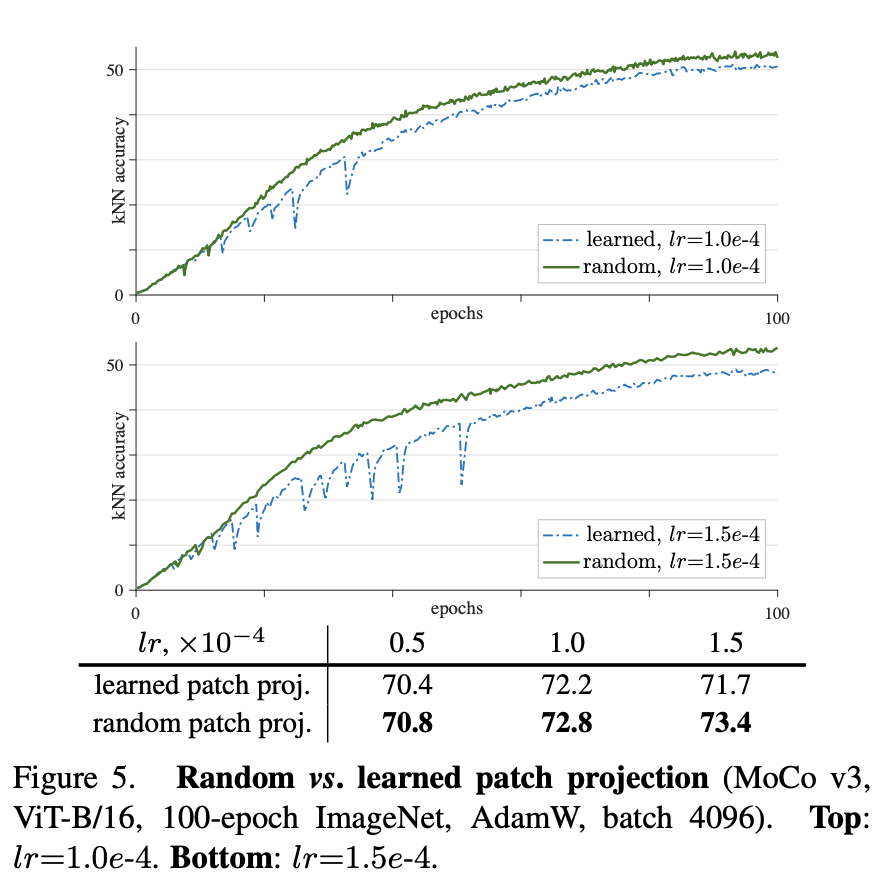
위 그림이 patch projection을 학습하는 것과 랜덤한 것을 비교한 것인데요, 그래프 중 상단에 위치한 초록색이 random 입니다. dips는 사라지고 학습이 안정적으로 진행되며 accuracy 역시 향상된 결과를 보였습니다. 게다가 lr을 조정해봐도 전반적으로 학습 과정이 안정적이었다고 합니다.
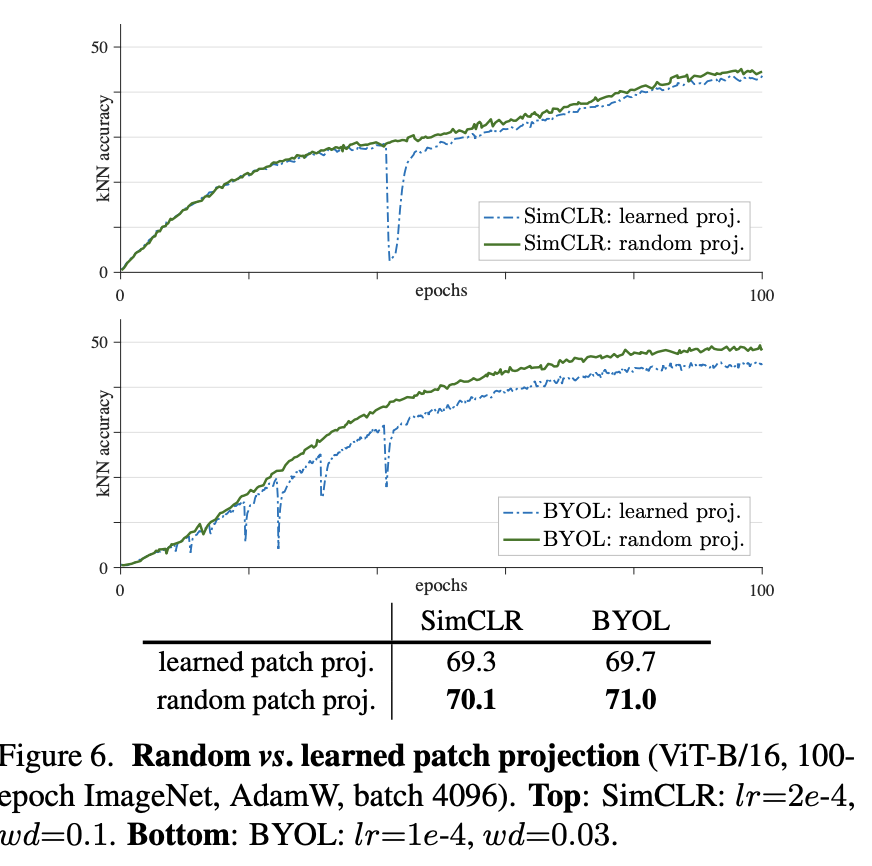
여기서 끝나는게 아니라 이 문제가 정말 맞는 지 확인하기 위해 SimCLR와 BYOL에도 ViT를 적용하고, random patch projection layer(즉, stop-gradient를 적용) 을 사용한 결과가 바로 위의 그래프입니다. 이를 통해 dips는 사라지고 학습은 안정화되었다고 합니다.
Experiment
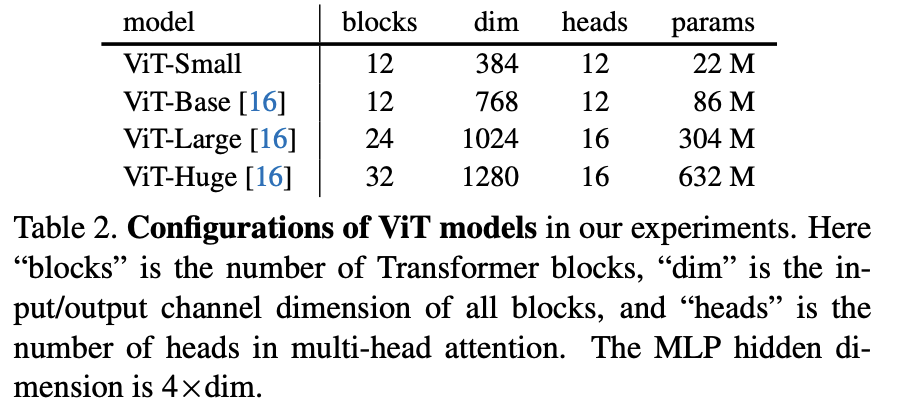
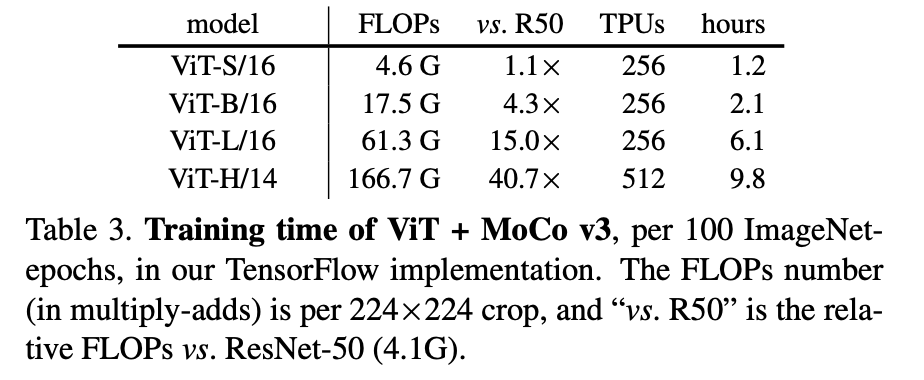
본 논문에서는 4가지의 ViT 모델을 통해 실험 결과를 보이는데요. 학습할 파라미터 수가 ResNet에 비해 훨씬 많아지므로 자원 역시 많이 필요하다고 얘기하는데.. 가히 충격적이어서 첨부하여습니다. (TPU 256개.....512개....... )

대표적인 SSL 모델에 viT를 적용하였을 때의 성능을 리포팅합니다. MoCov3, SimCLR, BYOL, SwAV랑 비교하는데요. CNN기반으로는 BYOL이 좋은 성능을 보였으나, ViT를 적용하면 MoCo v3가 가장 좋아집니다. 그리고 BYOL, SwAV와는 다르게 ViT를 적용했을 때 MoCo, SimCL에서 더 잘 작동하였다고 합니다.
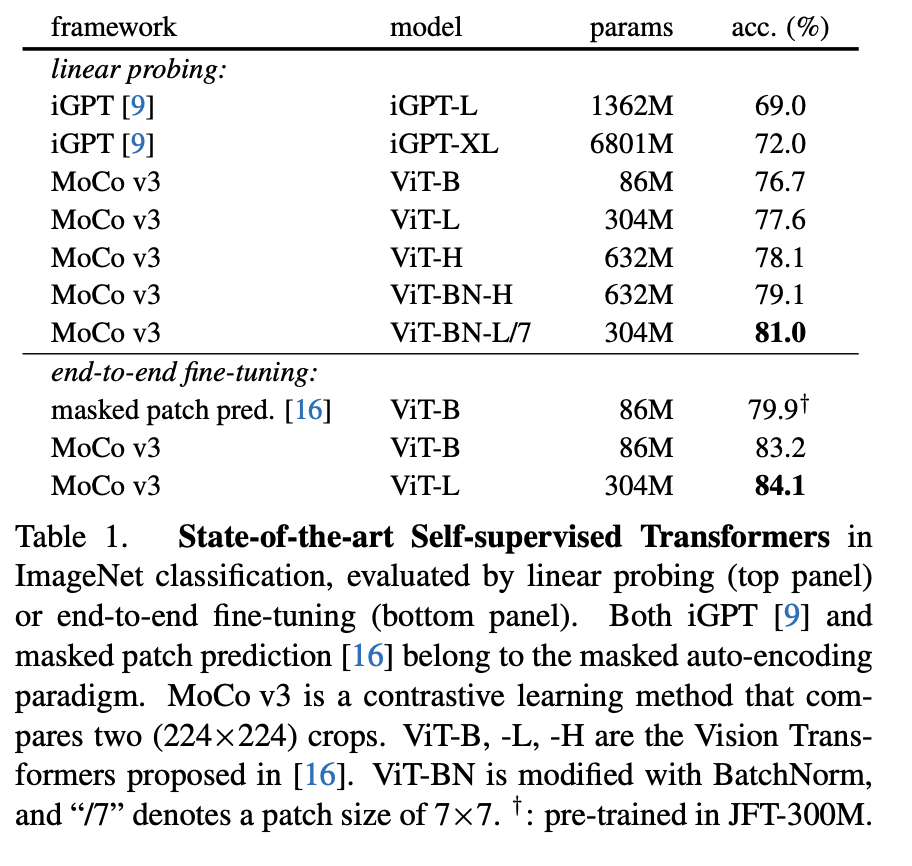
그리고 SSL을 통해 학습한 ViT은 ㅗ델이 커질 수록 좋은 성능을 보였습니다.
처음으로 ViT를 SSL에 적용한 논문으로, 학습의 불안정성을 어떻게 해결해야할지 고민하고 연구한 논문 같았습니다. 최신 방법론은 어떻게 연구되고 있는지, BYOL 같은 non-contrastive SSL 방법론에는 어떻게 ViT가 적용되는지 궁금해진 논문입니다. 그럼 리뷰 마치도록 하겠습니다.An Empirical Study of Training Self-Supervised Vision Transformers
좋은 리뷰 감사합니다
projection head 를 추가한 구조라고 하셨는데 기존 몇몇 논문에서 projection head 의 필요하지 않다고 다룬 논문이 2021년 이전 논문으로 있던것으로 기억합니다! 최신 논문임에도 projection head를 추가한 이유는 무엇인가요? 정확히 어떠한 이점이 있는지 혹시 분석이 추가되어 있나요?
감사합니다.