Before Review
오래간만에 논문 리뷰입니다. 지난 아듀 세미나에서 소개했던 Temporal Localization과 관련된 논문입니다.
논문의 컨셉 자체는 제목에도 적혀있지만, Temporal Action Localization Task를 위한 비지도 학습 기반 사전학습 방법입니다. 당연한 방향이기도 하고 저도 작년에 막연하게 생각만 하고 있었는데 다른 누군가 연구를 해서 논문을 완성시켰네요.
리뷰 시작해보도록 하겠습니다.
Introduction
비디오 분야에서 Representation Learning이 요즘 많은 연구가 되고 있습니다. 논문도 활발하게 나오고 있는 상황인데 대다수의 연구들이 Video Classification 레벨에서의 Representation Learning 만을 연구하고 있었습니다.
좀처럼 Temporal Action Localization에 대해서 Self-Superivsed 기반의 Representation Learning 연구가 진행되고 있지 않다가 이번에 처음으로 Temporal Action Localization을 위한 Self-Supervised pretext task 제안한 논문이 처음 등장하게 됐습니다.
결국 저자가 주장하는 핵심은 Classification으로 사전학습을 시키는 것은 Temporal Localization task에 있어서는 Sub-optimal 하다라는 것 입니다. 두 task의 성격이 다르다 보니깐 sub-optimal 하다는 것인데 정확히 어떤 것이 다른지는 뒤에서 좀 더 자세히 설명하도록 하겠습니다.
이에 저자는 Temporal Action Localization을 위한 새로운 사전학습 기법을 제안하였습니다.
저의 지난 리뷰였던 TSP라는 Temporal Action Localization을 위한 사전학습 피쳐가 있지만 이것은 Supervised 방식이라는 한계가 있습니다. Supervised 방식은 항상 Annotation이 정확히 완료된 데이터셋을 요구로 하기 때문에 다양한 상황에서 사용되기는 쉽지 않습니다. 기존에도 Temporal Action Localization을 위한 사전학습 방법론들이 있지만 모두 Supervised 기반이었습니다. 이에 저자는 처음으론 Self-Supervised 기반의 Temporal Localization 사전학습 방식을 제안합니다. 이것이 본 논문의 핵심이지요.
또한 저의 지난 리뷰였던 BSP라는 논문이 있는데, 이 논문의 컨셉과 유사합니다. 핵심은 Large-Scale의 Temporal Action Classification용 데이터셋인 Kinetics라는 데이터셋을 이용하여 Temporal Boundary를 찾는데 적합한 데이터셋으로 새롭게 만들어주는 것이 핵심입니다. BSP는 서로 다른 두 action Video를 Cut-Paste 하는 방식으로 진행이 되었는데 여기서 비디오가 어떤 action category인지 알아야 한다는 점이 있어 Classification label 정보를 알아야 한다는 한계가 있습니다.
이에 저자는 비슷하지만 우리는 어떠한 label 정보 없이 Self-training이 가능하다는 것을 강조하고 있습니다. 저는 본 논문이 가지는 의미가 조금 크다고 생각하는 게 비디오 진영에서 특히나 Temporal Localization 용도의 어노테이션은 상당히 Labeling Cost가 큽니다. 그렇기 때문에 다양한 도메인에서의 활용이 쉽지 않은 상황인데, 이렇게 어노테이션의 제약으로부터 벗어나게 한다면 다양한 시스템에서 활용될 수 있는 방향을 제시하기 때문입니다. 저자는 다른 방법론들과의 비교를 위해서 Kinetics라는 action classification 용도의 대용량 데이터셋을 이용하였지만 방법론을 읽어보면 다른 도메인에서도 충분히 활용 가능하다는 것을 느꼈습니다.
무튼 서론은 이쯤으로 하고 본격적으로 저자가 어떤 방법을 제시했는지 같이 알아보도록 하겠습니다.
Methods
논문 저자의 가장 큰 고민은 “Action Classification과 Action Localization의 본질적인 차이는 무엇인지” 였습니다. 자 예를 들어 축구에 해당하는 비디오 하나가 있을 때 action의 영역이 원래는 2초부터 5초였는데 조금 변형이 가해져서 7초부터 10초로 변경되었다고 가정해보겠습니다.
이럴 때 Action Classification은 동일한 결과를 반환해야 합니다. 둘 다 축구에 대한 영상이기 때문에 예측 Video Category는 축구여야 하죠. 즉, Action Classification은 Temporal Transformation에 Insensitive 한 성질을 가지게 됩니다. action의 구간이 어디인지는 상관없이 비슷한 feature representation을 얻는 것이 목적입니다. 그리고 지금까지의 video representation learning은 다 저러한 방법으로 학습이 진행됩니다.
하지만 Action Localization 입장에서는 얘기가 조금 달라집니다. 둘 다 축구 영상이긴 하지만 여기서는 정확한 구간을 예측해야 하기 때문에 다른 결과를 반환해야 합니다. 첫 번째 영상은 2초부터 5초 두 번째 영상은 7초부터 10초 이렇게입니다. 즉, Action Localization은 Temporal Transformation에 Sensitive 한 성질을 가져야만 합니다. 이것이 핵심입니다. 이렇게 두 task에 근본적인 차이가 있고 이것이 Temporal Localization task에 맞는 사전학습을 진행해야만 하는 이유입니다.
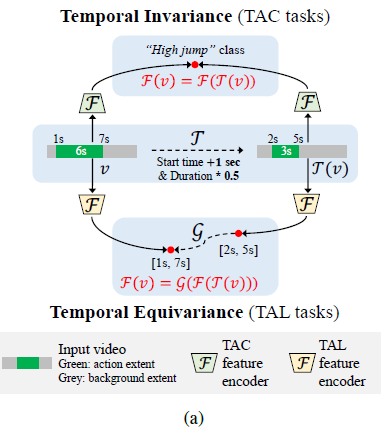
그림의 위쪽을 보면 Temporal Action Classification에 해당하는 그림 설명입니다. 원래 action의 구간이 1초부터 7초였는데 여기서 변형을 조금 가해 시작 시간이 1초 늦어지고 전체 길이가 절반이 되는 transformation이 적용된 비디오에 대해서 동일하게 Feature encoding을 했을 때 representation이 같아지도록 하는 것이 목적이죠.
- F(v)=F(T(v))
그림의 아래쪽을 보면 Temporal Action Localization에 해당하는 그림 설명입니다. 원래 비디오 v 는 1초부터 7초가 action 구간입니다. 여기서 Temporal Transformation이 가해진 비디오 T(v)는 2초부터 5초가 action 구간입니다. 이렇게 둘이 먼저 encoding을 했을 때 두 feature는 서로 다른 temporal 한 성질을 가져야 합니다. 즉 v 의 연속적인 clip feature들은 1초부터 7초 구간에 action 정보가 강해야 하고 T(v)의 연속적인 clip feature들은 2초부터 5초 구간에 action 정보가 강해야 합니다.
이를 위해서 Temporal Localization Encoder인 F 를 잘 학습시켜야겠죠. 근데 여기서만 끝나면 Temporal Sensitivity를 잘 capture 할 수 없습니다. 여기서 등장하는 것이 Equivariance Trasnformation 함수 G 입니다.
F(T(v))의 연속적인 clip feature들은 2초부터 5초 구간에 action 정보가 강하다고 얘기했는데 여기서 feature level에서 역변환을 가해 F(v)와 비슷해지게 만드는 것이죠. 2초부터 5초로 변형이 가해진 부분을 다시 역변환을 가해 1초부터 7초로 feature level에서 만드는 것입니다. 이 역변환을 결국 잘하기 위해서는 Temporal Sensitivity를 모델이 제대로 이해해야 가능하겠죠. 저자는 이것을 노린 것입니다. 그래서 원래 기본 TAL의 encoder F 와 역변환 encoder G 를 학습하는 과정을 통해 저자는 Temporal Localization에 중요한 Temporal Sensitivity를 제대로 학습할 수 있다고 얘기합니다.
그럼 이제 어떻게 해서 그 과정들이 이루어지는지 살펴보겠습니다.
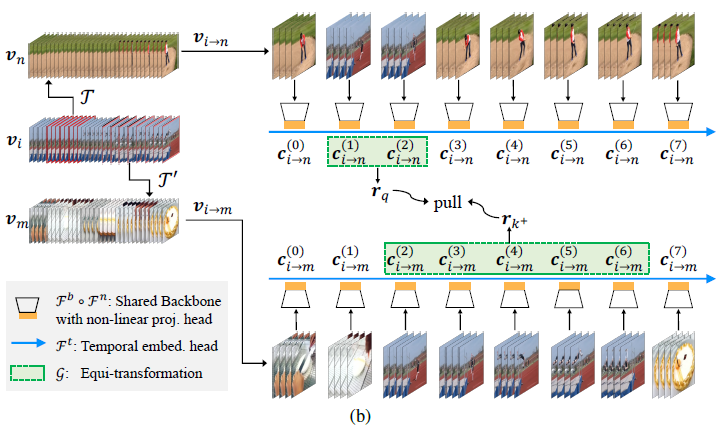
일단 새로운 데이터를 만들 예정인데 우리의 방법은 Trimmed Video로 만든다는 가정을 가지고 시작합니다. 즉, 비디오에는 action 밖에 존재하지 않고 다른 background는 없다고 가정하는 것이지요. 그리고 이러한 가정을 바탕으로 Pseudo Action Video를 선정합니다. 그림으로 보면 v_{i}에 해당합니다. 여기서 random 하게 두 구간을 임의로 선정합니다. 그리고 다른 두 Background 비디오를 랜덤 하게 선정해서 임의로 선정한 action 구간에 Temporal Transformation을 가해줘서 Copy Paste 해줍니다. 아래의 그림을 보면 무슨 소리인지 이해할 수 있습니다.
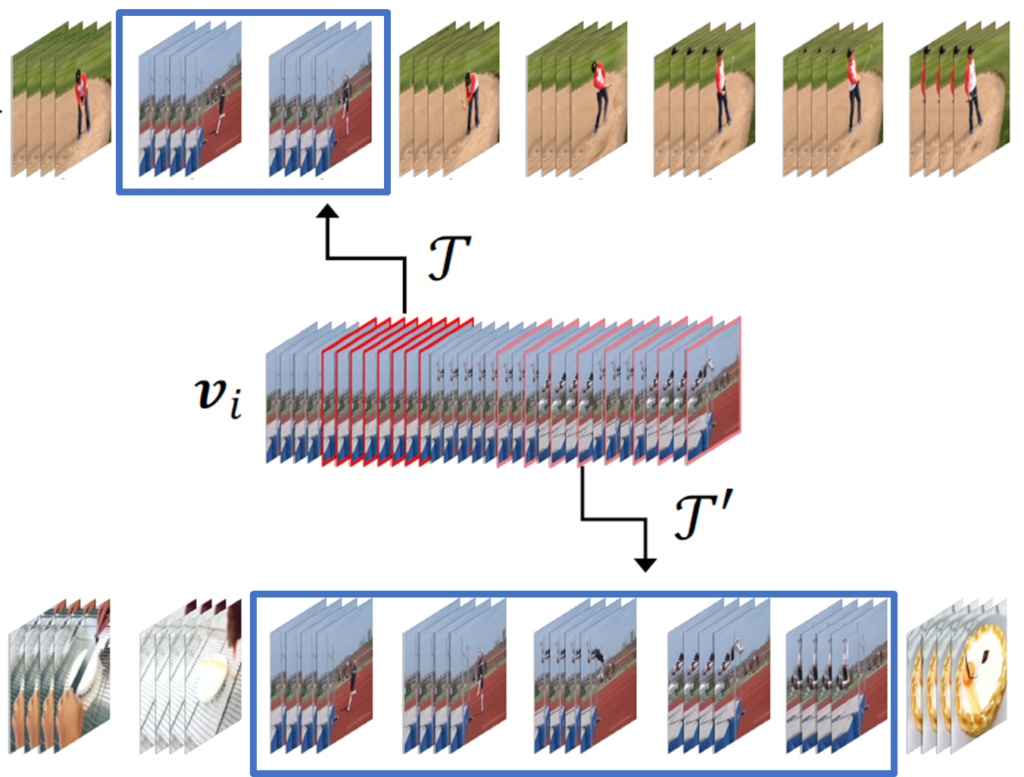
Trimmed Video에서 구간을 조금 자르고 붙인 것이기 때문에 그 구간은 반드시 action 영역을 포함하고 있습니다. 그래서 우리는 이것을 Pseudo action region이라고 정의합니다. 이러한 상황에서 아까 위해서 우리는 F 와 G 를 학습해야 한다고 했습니다. 그래서 크게 두 가지의 Task를 가지고 학습이 진행이 됩니다.
우선 Localization의 기본이라 할 수 있는 합성된 데이터로부터 pseudo action 구간을 찾는 것입니다. 그림으로 보면 파란색 부분이겠죠. 여기서 F 가 학습이 됩니다. 기타 다른 Temporal Action Localization이랑 비슷하다고 보면 됩니다. Clip 단위로 feature를 인코딩하고 가장 마지막에 Clip들끼리의 연속적인 temporal information을 capture 하기 위해 temporal 차원으로 temporal convolution이 진행됩니다.
다음으로 G를 학습하게 됩니다. 눈치 채신분들도 있겠지만 저기 파란색으로 칠해진 부분은 결국 같은 action을 나타내는 구간입니다. 따라서 역변환은 저 두 구간의 feature representation을 같아지도록 만들면 되겠죠. 그래서 Contrastive Learning이 등장합니다. 같은 Pseudo action video로부터 합성된 데이터끼리의 pseudo action region feature 끼리는 Positive pair를 이루고 서로 다른 Pseudo action video로부터 합성된 데이터끼리의 pseudo action region feature 끼리는 negative pair입니다. Loss는 가장 흔하게 사용하는 InfoNCE Loss를 사용해주었다고 합니다.
이것이 저자가 제안한 방법입니다. 비디오를 Copy-Paste 하는 과정에서 조금 테크닉이 들어갔지만 augmentation 적인 얘기기도 하고 저의 이전 리뷰인 BSP와 완전히 동일한 방식으로 진행했기에 이번 리뷰에서는 다루지 않겠습니다.
Experiments
실험입니다. 실험 내용이 그리 많은 것은 아니지만 인상 깊은 부분이 하나 보입니다. 우선 먼저 공개된 데이터셋으로 하는 Benchmarking 실험입니다. 실험에 사용된 데이터셋은 1) ActivityNet 1.3 , 2) Charades-STA , 3) THUMOS’ 14입니다. 본 논문의 방법은 어디까지나 사전학습에 관한 연구이기 때문에 down stream task에 대해서는 각각 유명한 방법론들로 대체하였습니다.
무슨 소리냐면 예를 들어 Temporal Action Detection에서는 G-TAD라는 방법론이 SOTA Benchmarking으로 자주 등장합니다. 그렇기 때문에 본 논문에서 제안된 방식으로 pretrain 된 feature를 얻고 G-TAD라는 방법론에 pretrain 된 feature를 넣어 fine-tuning 시켰다는 의미입니다. 본 실험에서는 3가지 Down-Stream Task에 대해서 실험을 진행합니다.
- Temporal Action Detection(TAD) : Temporal Action Localization이랑 같은 용어입니다. Untrimmed Video에서 Action의 구간을 찾고, 그 구간에 해당하는 Action category를 예측하는 작업입니다.
- Action Proposal Generation(APG) : TAD와 비슷하지만 Action의 구간 만을 찾는 작업입니다. 그 구간이 어떤 action인지는 예측하지 않는 것이죠.
- Video Grounding(VG) : Text Query에 해당하는 비디오 영역을 찾아주는 것입니다. 예를 들어 “줄넘기하는 남자”라는 Text가 들어오면 실제 비디오에서 남자가 줄넘기하는 영역을 찾아줘야 하는 것입니다.
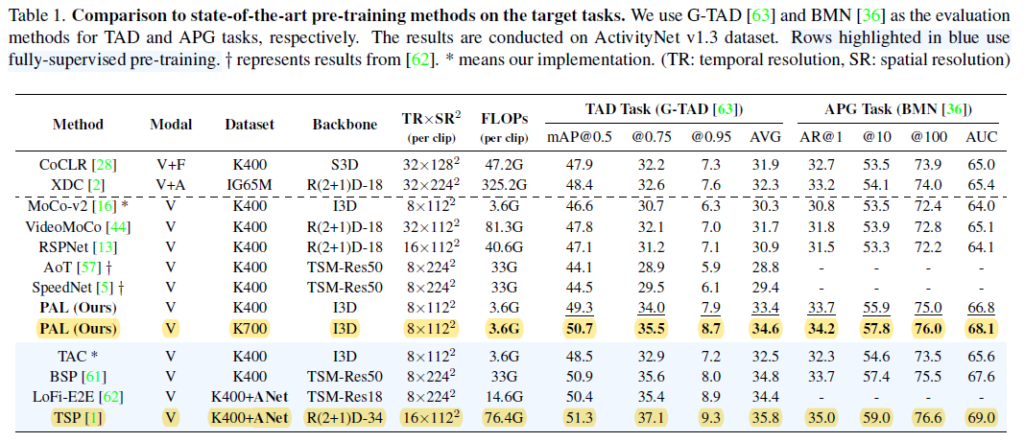
먼저 ActivityNet 1.3에서의 성능입니다. 두 가지 포인트로 바라보면 됩니다.
- Unsupervised 방식으로 사전 학습된 방법론들과 비교했을 때는 SOTA의 성능을 보여주고 있습니다. FLOPS도 작은 것이 인상적이네요. 기존의 Unsupervised 사전학습은 모두 Action Classification 용도로 사전학습이 되어서 Localization task에 적합하지 않음을 보여주는 것입니다.
- Supervised와 거의 유사한 성능을 보여줍니다. 심지어 TSP는 사전학습을 할 때 Supervised로 진행될 뿐만 아니라 사전학습에 ActivityNet 자체가 사용이 됩니다. 반면에 본 논문에서 제안된 방법론은 Kinetics만을 이용해서 사전학습을 진행했는데 TSP라는 방법론과 거의 근접한 성능을 보여줍니다.
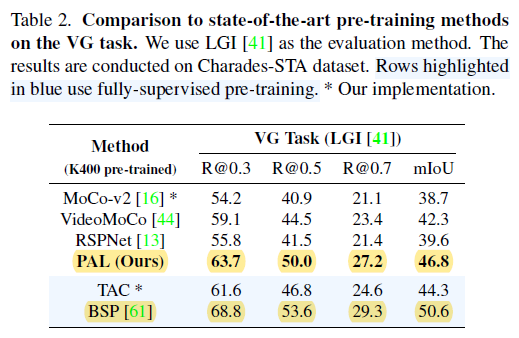
Video Ground 작업에 대한 성능입니다. 여기서는 이제 BSP라는 supervised 방식과는 조금 차이를 보여주지만 저자는 그래도 우리가 FLOPS(3.6G vs 33G)는 훨씬 적다는 것을 포인트로 본인들의 방법론의 우수함을 주장합니다. 당연히 Unsupervised 끼리의 비교에서는 SOTA를 찍어주고 있습니다.
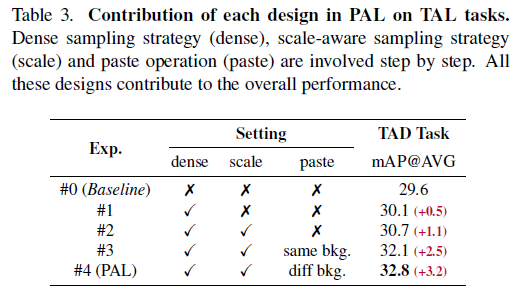
다음으로는 Ablation Study입니다. 세 가지 Module에 대해서 Ablation을 진행하였습니다. 단계적으로 성능이 증가하는 게 인상 깊네요. 하나씩 설명해보겠습니다.
- Dense Sampling strategy (dense) : 합성 비디오를 만들 때 영역을 하나의 clip이 아니라 여러 개의 clip으로 샘플링하여 합성하는 것을 의미합니다.
- Scale-aware sampling strategy (scale) : pseudo action region을 생성할 때 다양한 stride를 가지고 샘플링하는 것을 의미합니다.
- Paste operation (paste) : Background video를 이용해서 복사된 영역을 만드는 것을 의미합니다.
정리하면 Baseline은 아무것도 하지 않은, 비디오에서 단 하나의 Clip 만을 랜덤 하게 샘플링하여 Clip-level의 Contrastive learning만을 한 것을 의미합니다. 같은 비디오끼리는 Positive 다른 비디오끼리는 Negative 이런 식으로 말이죠.
우선 Dense Sampling strategy (dense)를 이용하면 0.5%의 향상을 얻을 수 있습니다. 더 많은 temporal clue가 활용되기 때문입니다. 그다음 Scale-aware sampling strategy (scale)를 추가하면 1.1%의 향상을 얻을 수 있습니다. 학습 과정에서 일종의 randomness를 부여해 더 다양한 representation을 얻을 수 있다고 합니다. 마지막으로 Paste operation (paste)을 추가하여 총 3.2%의 개선을 확인할 수 있습니다. 이는 서로 다른 두 Background video를 이용하여 달라진 background에 대해서도 비슷한 region feature를 생성하기 때문에 Background-insensitive 한 feature를 얻을 수 있어서 발생한 이득이라고 합니다. Action Localization을 수행하는 데 있어 Background에 sensitive 한 것은 좋지 않죠.
다음으로는 Hyperparameter 실험입니다.

Table4는 Temporal embedding head의 개수에 따른 성능 변화인데, 개수가 몇 개일 때 최대 성능이다 이런 것보다는 Temporal embedding을 하지 않은 것과 한 것의 차이를 주목하면 됩니다. Temporal embedding이란 연속적인 Clip feature 간의 temporal information을 fusion 하는 것을 의미합니다. 시간적인 정보를 알아야 action 근처에 있는 background와 action 간의 경계도 좀 더 잘 encoding 할 수 있기 때문입니다.
다음으로 Table5는 그냥 paste를 할 때 clip을 단순히 복사 붙여 넣기 하는 것보다는 조금 더 부드럽게 픽셀 값들을 섞어주면서 paste 하는 것이 성능이 더 좋더라 이렇게 받아들이면 됩니다. 자연스럽게 넘어가야 모델 입장에서도 더 자연스러운 representation을 학습할 수 있겠죠.

Action Classification에서의 성능입니다. 가장 높지는 못하지만 2등을 기록했네요. 다른 방법론들은 Action Classification을 위해서 사전학습 방식이 고안되었기 때문에 성능이 높지만 본 논문에서 제안된 방법론은 Action Localization 용도로 제안되었지만 Action Classification에서도 준수한 성능을 보여주는 것을 보아 Task를 가리지 않는 Generality를 보여주는 것 같습니다.
마지막으로 흥미로운 시각화입니다. 체리 피킹이라는 생각이 들긴 하지만 그래도 보면 꽤나 흥미롭습니다.
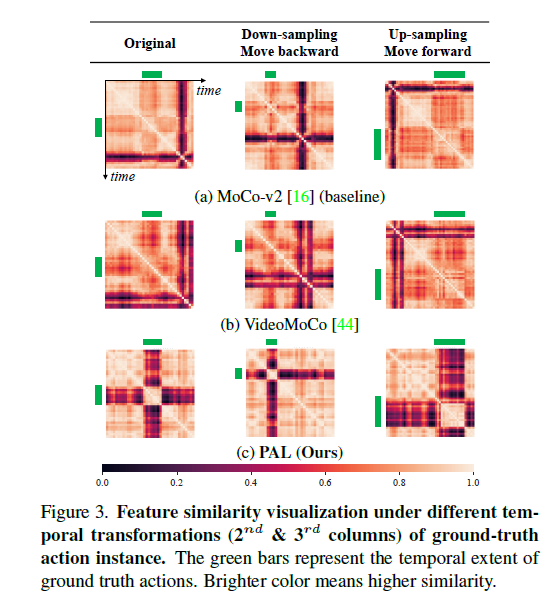
저 simarility map은 feature 끼리의 유사도를 나타내는 것입니다. 예를 들어 비디오 하나의 Clip feature들이 8개씩 나왔다면 저 simarility map은 8 by 8이 되겠네요. 보면 색깔이 어두운 부분이 있습니다. 어둡다는 것이 유사도가 낮은 것입니다. Action과 Background의 유사도는 낮은 것이 이상적이겠죠. 자 이제 저 similarity map이 가지는 의미에 대해서 알아보았으니 제대로 해석을 해보겠습니다.
가령 Untrimmed Video가 하나 있다고 가정했을 때 원래 action의 영역이 6~12초라 가정하겠습니다. 여기서 이 action의 영역에 대해서 Temporal Transformation을 가합니다. 저기 초록색으로 칠해진 부분이 action 영역이라 보면 됩니다.
- Orginal : 6초~12초
- Down-sampling move backward : 6~12초 -> 3초~6초
- Up-sampling move forward : 6초~12초 -> 12초~24초
이렇게 Temporal Transformation을 가했을 때 Localization을 잘하려면 feature도 이러한 변화에 민감해야 합니다. 왜냐하면 정확한 위치를 알아야 하기 때문입니다. 그런데 보면 (a) , (b) 방법론들을 보면 이러한 변화에 민감하게 대응하지 못합니다. 왜냐하면 그들은 temporal-invariant 하게 학습이 되었기 때문에 Temporal transformation이 가해져도 같은 feature representation을 가지게 됩니다.
하지만 제안된 방법은 모두 변화에 잘 대응하여 feature 끼리의 유사도가 제대로 나오는 것을 확인할 수 있습니다. 그리고 이것은 Temporal Localization을 하는 데 있어 중요한 성질입니다. 저자가 주장한 것처럼 feature들이 잘 encoding 되었나 봅니다.
Conclusion
Method를 이해하는 데 조금 어려움이 있었지만, 그래도 꽤나 fresh 하면서 simple한 방법론을 제안한 논문이지 않나 싶습니다. 하나 제가 생각했을 때 이 논문의 한계점을 조금 생각해보면
사전학습에 사용되는 데이터셋은 Trimmed Video라는 가정이 있어야 한다는 것입니다. 비디오 데이터는 대다수 untrimmed 이기 때문에 untrimmed video로도 사전 학습할 수 있다면 정말 더욱더 다양한 시스템에 활용될 수 있다고 생각이 드네요. 아마 다음 방향은 Untrimmed video를 가지고도 Self-Superivsed 방식으로 Temporal Localization task에 대해서 사전 학습할 수 있는 방법론일 것이라는 조심스러운 예측을 해봅니다.
코드가 지금은 공개가 안된 상태이기는 한데 나중에 공개가 되면 action dataset 말고도 다양한 도메인의 dataset에 대해서도 좋은 성능을 보여주는지 실험을 해볼 예정입니다.
리뷰 읽어주셔서 감사합니다.