

오늘 리뷰할 논문은 이번 CVPR 2022에 게재승인된 “Hierarchical Self-supervised Representation Learning for Movie Understanding”이라는 논문입니다. 영화와 같이 길이가 길고 여러 이벤트가 얽혀있는 비디오에 대해 self-supervised learning 기반 feature representation을 목표로 하는 논문입니다. 제가 연구를 하면서 비디오 쪽에서도 특히나 long-term representation과 self-supervised learning에 관심있게 보고 있었는데, 이 두 키워드를 동시에 다룬 방법론인 듯하여 읽고 리뷰하고자합니다.
1. Hierarchical SSL for Movies
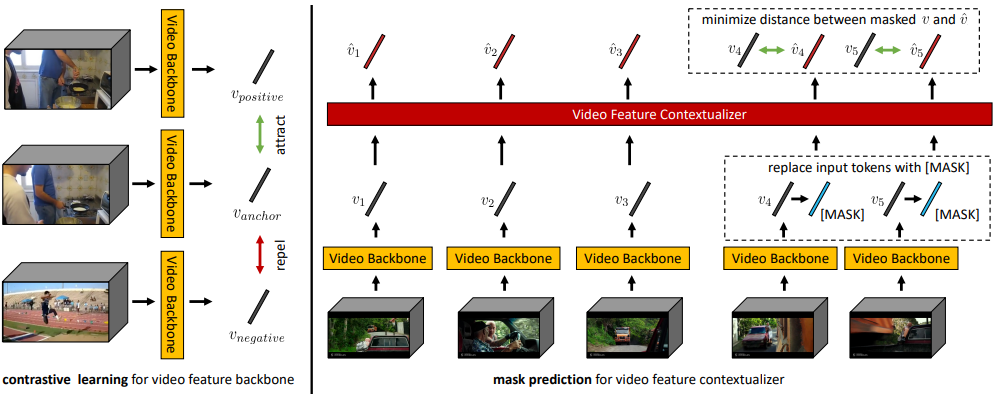
해당 연구 이전, CVPR 2021에 게재된 논문 “Visual semantic role labeling for video understanding”에서는 movie understanding을 위해 low-level backbone feature로 시작해서 high-level transformer contextualizer로 이어지는 hierarchical model을 제안하였습니다. 본 논문은 구조적으로 이를 따라하되, backbone과 contextualizer를 self-supervised learning 방식으로 바꾸었습니다.
1.1 Hierarchical model for movie understanding
방금전 언급했듯이, 해당 논문의 방법은 기존 논문 “Visual semantic role labeling for video understanding”의 구조를 따릅니다. 먼저, low-level video feature를 추출하기 위한 backbone으로는 SlowFast의 한 pathway인 Slow-only를 사용하고, 2초의 clip마다 feature로 embedding합니다. 이렇게 추출된 low-level video feature를 token으로 두고, Transformer encoder (TxE)와 Transformer decoder (TxD)의 프로세스를 순차적으로 거칩니다. Transformer encoder는 low-level video feature으로부터 self-attention이 적용된 feature들을 얻어내는 역할을 하며, Transformer decoder는 self-attention이 적용된 feature로부터 downstream task를 다루는 역할을 합니다. 이 두 프로세스의 구조는 온전히 앞선 CVPR 2021 논문에서의 구조와 동일하게 사용하였다고 합니다.
1.2 Video backbone: contrastive pretraining
이전 CVPR 2021 논문과 구조적으로 동일한 상황에서, 어떻게 self-supervised learning 방식으로 바꾸었는지 설명드리고자합니다. 우선, backbone의 경우, 기존 Self-supervised learning 방법론인 CVRL 방식과 MoDist 방식으로 실험하였다고합니다. CVRL은 같은 비디오에서 서로 다른 시간대의 clip 두 개를 positive로, 다른 비디오의 clip을 negative로 둔 뒤, spatial transformation을 적용하여 contrastive learning하는 방식으로 Self-supervised video representation 분야의 대표적인 연구입니다. MoDist는 Motion input (Flow)과 Visual input (RGB frame)이 있을 때, Motion input의 정보를 Visual input 쪽으로 distillation 시켜 motion-sensitive한 feature를 만들고자한 방식이며, CVRL을 상회하는 성능을 보이고 있습니다. 이 두가지 학습 방식을 차용하여 backbone network가 self-supervised learning 방식으로 변경되었습니다.
1.3 Contextualizer: mask prediction pretraining
그 다음으로 Transformer encoder를 self-supervised learning 방식으로 어떻게 바꿨는지에 대해 설명드리겠습니다. 참고로 Transformer decoder를 바꾼 방식은 supplement에 나와있다고 하는데, 아직 CVPR 2022 paper들이 publication되지 않아 찾아볼 수 없는 상황이므로 encoder에 대해서만 다루겠습니다. Encoder는 NLP 분야의 BERT에서 사용한 Mask prediction task를 차용하여 self-supervised learning 방식으로 학습되었습니다. 이는 크기가 m인 마스크 (m은 1부터 전체 토큰 수 사이의 랜덤)를 시작지점 s (s는 1부터 전체 토큰수-m+1 사이의 랜덤)를 기준으로 설정합니다. 그리고 masking 전 feature들과 후 feature들이 서로 가까워지도록 positive로 두고, 사전에 미리 만들어둔 distractor pool의 feature를 negative로 둡니다. 이 과정은 일부가 가려져도 나머지 토큰들을 통해 가려진 부분을 예측할 수 있어야 한다는 전제하에 설계된 방식으로 Transformer encoder를 annotation 없이 학습할 수 있게 만들어줍니다.
2. Experiments
본 논문에서는 앞서 설명한 방식으로 영화에 대해 representation learning을 한 뒤, 여러 downstream task에서 성능을 보입니다. Downstream task로는 semantic role prediction과 event relation prediction, verb prediction, 그리고 LVU task로, 네 task가 본래 제 관심 분야가 아니여서 생소하기에, 이들 중 앞선 두 task에서 해당 방법론으로부터 얻어진 영향에 초점을 맞추어 설명드리겠습니다.
2.1 Semantic role prediction
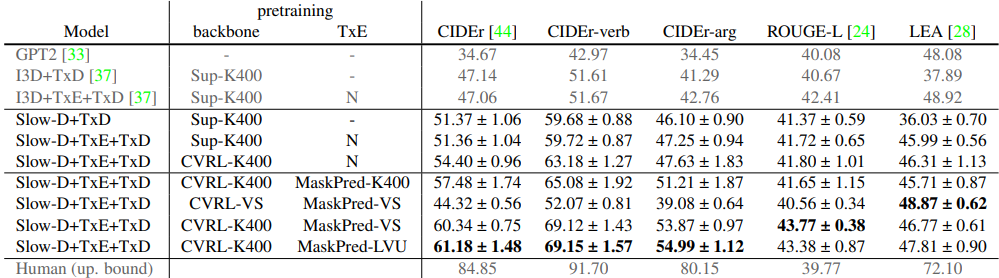
해당 task는 특정 장면과 그곳에서 일어나는 말들의 semantic한 역할을 예측하는 것을 목표로 둡니다. VidSitu라는 데이터 셋에서 실험이 진행되었습니다. Table 1의 5행과 6행 사이에서는 backbone 의 학습 방식을 CVRL로 바꾸었을 때 모든 경우에서 성능향상이 있음을 보실 수 있으며, 6행과 7행 사이에서는 self-supervised learning 기반의 Transformer encoder를 활용하여 self-attention을 적용하였을 경우에도 마찬가지로 대부분의 경우에서 성능향상이 있음을 확인할 수 있습니다.
2.2 Event relation prediction
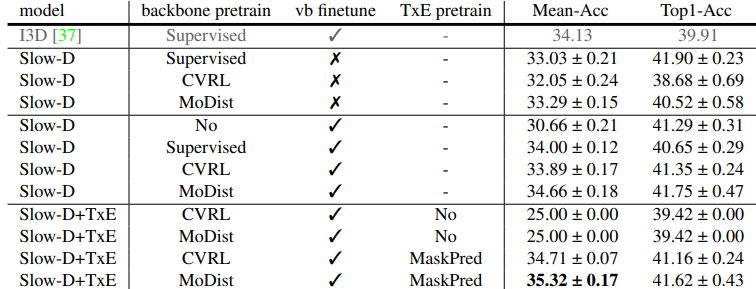
해당 task는 “A is enabled by B”, “A is a reaction to B”, “A causes B”, 그리고 “A is unrelated to B”와 같이 네 가지의 경우로 Event A와 B 사이의 관계를 예측하는 것을 목표로 두며, 마찬가지로 VidSitu에서 실험이 진행되었습니다. Table 2를 보았을 때, VidSitu에서 verb prediction task를 통해 finetune (vb finetune) 을 하든 안하든, backbone을 self-supervised learning 방식으로 바꾸었을 때 성능이 supervised learning 방식보다는 약간 낮은 모습을 볼 수 있습니다. 그러나 label을 필요로 하지 않은만큼, 충분히 효율적이라고 볼 수 있습니다. 또한, Transformer encoder 까지 사용한 경우에는 추가적인 성능향상까지 보여주었습니다.
2.3 Ablation studies in semantic role prediction
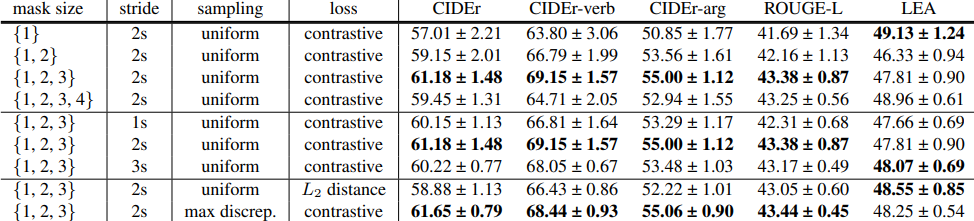
Ablation study는 semantic role prediction task를 기준으로 파라미터가 존재하는 Transformer encoder에서만 진행되었습니다. Table 3에서 볼 수 있듯이, 먼저 mask size는 총 4가지 경우 {1}~{1,2,3,4}를 실험하였으며, 중간 크기인 {1,2,3}일 때 성능이 가장 높았습니다. 그리고 token의 길이에 해당하는 stride의 경우, 2초일 때 가장 성능이 높아 사용하였다고 하며, 마지막으로 loss의 경우, 단순 L2 loss로 positive 관계의 feature들을 가깝게 하는것보다 contrastive loss인 InfoNCE loss가 더 높은 효과를 보였다고 합니다.
3. Reference
[1] https://arxiv.org/pdf/2204.03101.pdf