이번에 소개드릴 논문은 Optical Flow 관련 논문입니다. 해당 논문은 2017년도에 나온 논문이기도 하며 제목도 Optical Flow를 Unsupervised 방식으로 학습한다는 것을 미루어보았을 때 매우 기초가 되는 논문으로 판단이 됩니다. 실제로도 학습 방법이라던지 그런 부분들은 기존의 방법론들이 많이 활용하는 방법(Photometric Loss, Spatial Transformer Network 등..)을 사용하는 것이기에 그리 흥미롭지 않으실 수도 있습니다.
다만 해당 논문을 읽게 된 이유는 최근에 Optical Flow 방법론들을 잠깐 사용해야할 일이 있었는데, 이때 네트워크가 추정한 Flow 값이 실제 Groudn Truth 기반의 Flow map과 어떤 차이가 있는지(스케일 값) 등 여러 궁금증이 존재하였기에 가장 기초가 되는 논문부터 살펴보려고 합니다.(학습 방식과 프레임워크에 대해서는 기존 Self-supervised depth estimation과 유사한 것 같은데 또 막상 코드 레벨에서 보니 잘 모르겠더군요.)
아무튼 비교적 옛날 논문에 해당하다보니 컨셉 자체는 쉬운 것 같아서 가볍게 읽어보실 분들은 읽어보셔도 좋을 듯 합니다.
Intro
해당 리뷰 뿐만 아니라 예전에 저가 고전적인 기법부터 Supervised Optical Flow 방법론(FlowNetv1, v2)에 대해서도 리뷰를 작성했었습니다. 그래서 Optical Flow에 대해서 잘 모르시는 분들은 제가 기존에 작성한 리뷰를 보시고 오셔도 좋을 듯 합니다.
Optical Flow에 대해 간략하게 설명만 하자면, 두 연속적인 프레임의 이미지가 존재할 때 이전 프레임 영상에서 다음 프레임 영상으로 각각의 픽셀 값들이 어느 방향으로 향하는지를 픽셀 레벨로 예측하는 분야입니다.
즉 Object Tracking이 객체 단위로 진행되는 거라면, Optical Flow는 픽셀 단위로 trakcing을 수행한다고 보시면 이해가 편하실 듯 합니다. 픽셀레벨의 예측이라고 한다면 가장 대표적인 것이 바로 Semantic Segmentation이 존재하겠죠? 이 Semantic Segmentation의 경우 픽셀레벨로 class를 예측하다보니 당연히 GT를 만드는 것이 기존의 다른 분야들과 비교하여 매우 힘든 축에 속합니다. 그래서 Unsupervised/Semi Supervised로 해결하고자 하는 방법론들이 꾸준히 연구가 되고 있구요.
마찬가지로 Optical Flow 역시 픽셀레벨에서 각각이 어디로 이동하는지에 대한 값을 GT로 가져야만 하기 때문에 단순히 한장의 프레임만 보는 Semantic Segmentation과 비교하여 더더욱 GT를 구하는 것이 어렵습니다. 그렇기에 Unsupervised Optical Flow에 대한 연구도 꾸준히 진행되고 있는 것으로 알고 있습니다.
서론이 조금 길었는데, 그래서 해당 논문에서는 아래와 같은 frame work를 통해 비지도학습으로 모델을 학습한다고 합니다.

두 연속적인 프레임을 concat하여 Localization Layer에 태우게 되는데 이때 Localization layer는 그 당시 유행하던 Supervised optical flow 방법론인 FlowNet과 유사한 구조를 활용했다고 합니다.
이렇게 Localization layer에서 타고 나온 flow map은 sampling layer를 통해 frame2를 frame1으로 warping하게 되는데 이때 Sampling layer는 Spatia Transformer Network에서 제안한 grid_sampling 방식을 그대로 활용합니다. 이렇게 warping된 frame2 이미지는 frame1과 비교하는 loss를 계산하고 Flow map 자체에 대해서도 Smooth term Loss를 활용하여 모델을 학습하게 됩니다.
Localization Net & Sampling layer
그럼 각각에 대해서 조금 더 자세히 다뤄보도록 하겠습니다.

먼저 입력으로는 두 frame의 영상이 concat되어 들어가게 되며 flow map 자체는 decoder의 각 stage별로 multi-scale로 추출이 됩니다. 그리고 이렇게 추출된 flow map들에 대하여 Loss를 계산하게 되는데 해당 loss는 밑에서 다시 설명하겠습니다.
한가지 눈여겨볼 점은 기존의 방법론들은 그저 decoder에서 점차 입력 영상과 동일한 해상도의 결과를 뽑기 위해 bilinear interpolation을 하거나 deconvolution을 점진적으로 수행하는 과정을 거치게 되는데, 해당 방법론에서는 그렇게 진행하지 않고, spatial transform을 활용하여 크기를 넓혀갔다고 합니다. 여기서 말하는 spatial transform이 flow map으로 영상을 warping하는 그런 무언가로 저는 알고 있는데.. 이걸로 어떻게 flow map 자체에 대하여 upsampling을 했다고 하는지 잘 모르겠네요?
아무튼 저자는 기존의 방식과 다른 spatial transform을 통한 upsampling 기법을 통해 네트워크의 연산량 및 구조의 단순화에 대한 이점을 볼 수 있다고 합니다.
Loss Function
Loss 함수 역시도 상당히 간단합니다. Loss function으로는 크게 Data term loss와 Smooth term loss가 존재하는데, Data term loss는 다음 수식으로 구성되어있습니다.
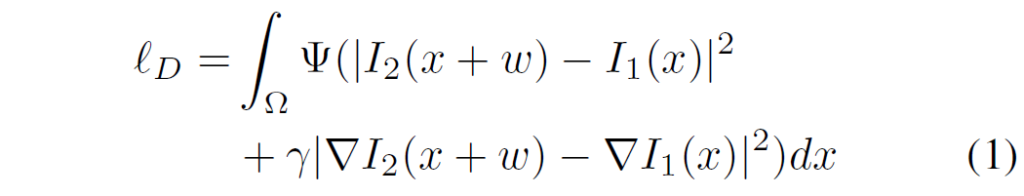
여기서 Ψ(s)는 \sqrt{(s^{2} + 0.001^{2}} 로 단순히 L1, L2 loss처럼 적용하는 것이 아닌 추가적으로 어떠한 margin 값을 더해주는 형식으로 구성된 함수입니다. 아무튼 쉽게 말해서 I2를 flow map을 통해 warping 시킨 결과와 이에 대응되는 I1 끼리 픽셀레벨로 비교하게 되는데 이때 명도값 뿐만 아니라 gradient 값까지 비교하는 방식으로 구성됩니다.
Smooth term loss의 경우는 아래 수식처럼 표현되는데, 말그대로 flow map 자체에 대해 gradient 값을 계산하여 그 값 자체들이 더 커지지 않도록 하는 수식입니다.

Experiments
그럼 이제 실험 섹션에 대해서 다뤄보겠습니다. 일단 논문에서 실험에 사용한 데이터 셋은 다음과 같습니다.
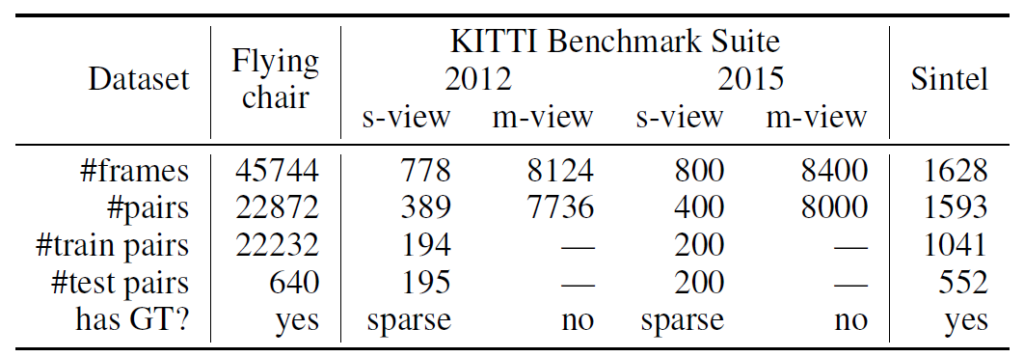
여기서 Flying chair 데이터 셋은 합성 데이터 셋으로 GT를 구하기 어렵다보니 기존의 supervised optical flow 방법론들이 이러한 합성 데이터로 학습을 한 뒤, KITTI 또는 Sintel과 같은 real dataset에 대해서 평가를 하곤 했습니다.
물론 Sintel 데이터 셋의 경우에는 KITTI처럼 실제 차량 환경 등이 아닌 애니메이션 영상에서 추출한 GT flow를 가지고 있습니다.(애초에 데이터 셋 자체가 만화 영화?임)
그 외에도 데이터 개수나 GT 여부 등에 대해서 참고해보시면 좋을 듯 합니다.
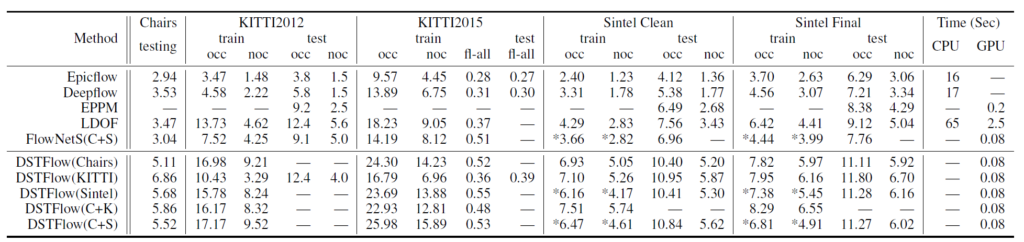
위에 표는 각각의 데이터 셋에세 대하여 다른 방법론들과의 정량적 비교 결과 표를 나타냅니다. 일단 EpicFlow와 Deep Flow의 경우에는 딥러닝 기반 방법론이 아니기 때문에 속도 측면에서 다른 방법론들 대비 느린 것을 확인하실 수 있습니다.(제일 우측 time 컬럼 참고)
그 외 가장 대표적인 Deep learning 방법론인 FlowNetS의 경우 타 방법론들 대비 0.08ms의 속도를 가지고 있으며 성능은 기존의 handcraf 방법론과 유사한 성능을 볼 수 있습니다. 지금보니깐 epic flow 방법론이 성능이 상당히 좋네요.
아무튼 해당 논문의 주인공인 DSTFlow의 경우 확실히 비지도학습 기반의 방법이기 때문에 모든 데이터 셋과 비교하여 성능 차이가 큰 것을 확인하실 수 있습니다. 아 참고로 평가 방식은 EPE(error point estimation) 실제 GT flow와 예측한 flow 간의 유클리디안 거리를 계산하여 평균을 구한 것이라고 이해하시면 될 것 같습니다.
결국엔 에러값이기 때문에 값이 낮을수록 정확하다고 볼 수 있는데, KITTI2015 데이터 셋보면 FlowNet(C+S) 대비 성능 오차가 크긴 합니다.(14.19 vs 25.98) 그래도 KITTI 데이터로 학습하여 평가하게 되면 16.79로 EPE가 크게 개선되는 것을 볼 수 있는데, 확실히 GT를 취득하기 어렵다는 이슈로 합성 데이터 등을 활용하더라도 애초에 real data와의 갭이 크다는 것을 확인할 수 있으며 비교적 GT의 필요성에서 자유로운 unsupervised 방법론의 필요성이 크게 부각되는 모습입니다.
결론
사실 unsupervised optical flow 방법론의 시초이기 때문에 실제 GT flow와 예측한 flow 간의 스케일 차이? 등에 대해서 어떤식으로 다루면 좋을지에 대한 내용들을 논문에 담아주는 줄 알았는데 아쉽게도 그런 내용은 전혀 없었네요.. 비록 제가 원하는 내용은 찾지 못했지만, 앞으로 다른 unsupervised optical flow 방법론들을 읽을 때 현재 논문 대비 성능이 얼마나 발전되고 있는지 확인할 수 있을 듯 합니다.
좋은 리뷰 감사합니다. 실험 결과 표 중에 KITTI benchmark 밑에 있는 s-view와 m-view가 어떤 차이로 구분이 되어있는 건가요?