TransDSSL 논문을 작성하면서 다음 연구주제로 생각하고 있던 것은 Self-supervised 로 Depth estimation을 한 후, 예측한 Depth를 Pseudo-LiDAR로 사용해서 3D object detection을 하는 것입니다. 따라서 현재 3D object detection이 어떤 방식으로 되고 있는지 서베이 중 입니다.
서베이 하던 중에 CVPR2022 에 accept된 이 논문을 발견했으며 리뷰해보고자 합니다.
Monocular 3D object detection은 처음엔 3D 정보를 regression하는 것으로 시작해서, Pseudo-Lidar의 발표 이후 Depth 정보를 네트워크에 어떻게 줄지 연구하는 방향으로 발전되었습니다.
그림 1과 같이 영상으로부터 원하는 정보를 regression하는 방식으로 제안되었지만 이런 방식은 Depth 정보가 충분하게 들어가지 못해서 정확도가 매우 떨어졌다고 합니다.
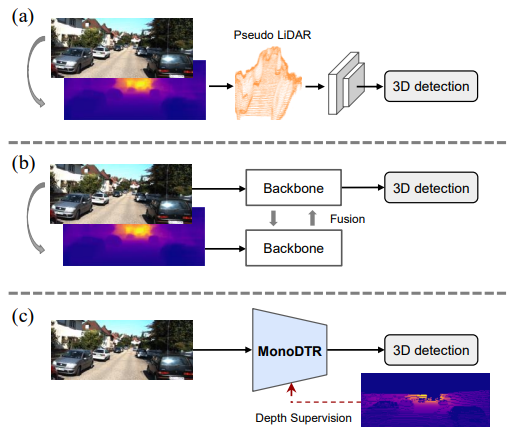
3D bounding box 예측은 현재 LIDAR에서 더욱 높은 성능을 보이고있는 상황이니 그림2-(a)와 같이 영상으로 부터 Depth를 예측한 후 그걸 Pseudo-LiDAR로 사용해서 3D object 를 예측하는 방법론이 나왔었습니다. 그후에는 RGB와 Pseudo-LiDAR 정보를 모델의 입력으로 사용해서 그 feature를 fusion해서 사용하는 방법론들 또한 제안되어 높은 성능향상을 보여줬습니다.
그렇지만 이렇게 Depth를 먼저 예측하는 방법론의 경우 추정된 깊이의 도움으로 물체를 더 잘 Localize 할 수 있지만 부정확한 깊이 맵에서 3D detection를 학습할 위험이 있습니다. 또한 높은 inference time을 소모해서 실제 application에 적용하는데 문제를 발생시킵니다
이 논문에서는 이러한 문제를 해결하기 위한 MonoDTR 방법론을 제안했으며 전체 Contribution은 다음과 같습니다.
- depthaware feature enhancement (DFE) module을 제안하며 이 가벼운 모듈을 통해서 LiDAR의 정확한 깊이 정보를 모델에 전달해줌
- 3D object detection에 Transformer를 처음 도입하며 이를 통해 context-aware한 예측을 가능하게 만듦
- Transformer에 정확한 깊이 정보를 encoding 하기 위한 depth positional encoding(DPE) 방법론을 제안함
- Method
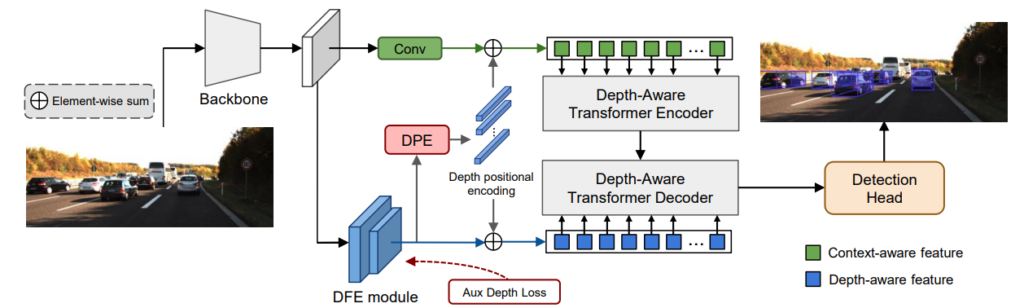
전체 아키택쳐는 그림 3과 같으며 backbone network, DFE module, DTR module, 2D-3D detection head 이렇게 총 네가지로 구성되어 있습니다.
백본 네트워크로는 DLA-102를 [1]에서 제안한 방식으로 사용했으며 H_inp x W_inp 입력 사이즈의 RGB 영상을 백본 네트워크의 입력으로 넣으며 HxW( H=H_inp/8 , W=W_inp/8 ) 크기의 feature를 backbone의 output으로 얻습니다. 이 feature를 DFE module와 Transformer의 입력으로 각각 넣어서 depth-aware와 context-aware를 전부 갖게됩니다.
Depth-Aware Feature Enhancement Module
최근 3D object detection 방법론들은 깊이 정보를 RGB로부터 예측한 후, 예측한 깊이 정보를 LiDAR와 같이 활용합니다. 그렇지만 이러한 방법론은 예측한 깊이가 정확하지 못해서 성능의 한계가 발생하며, inference 시간이 올래걸린다는 단점이 있습니다.
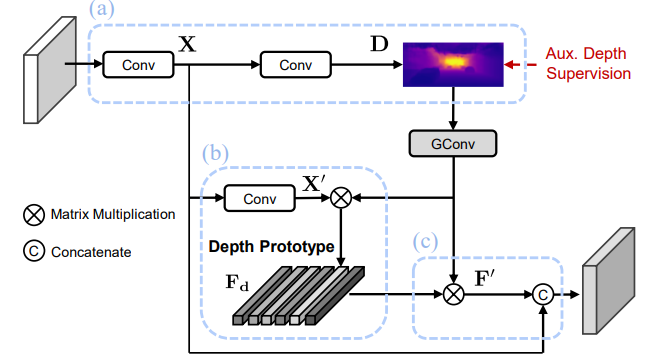
이런 문제를 해결하기위해서 이논문에서는 depth-aware feature enhancement (DFE)를 제안하며 그림 4에 나타나있다.
이 방식은 기존 방법론들보다 훨씬 가벼운 module임에도 LiDAR 정보를 loss로 사용하기 때문에 정확한 깊이 정보를 학습할 수 있다는 장점이 있습니다.
이 방식의 순서를 설명하면 다음과 같습니다.
- 입력으로 들어온 feature를 conv 2개를 거쳐 probability of discretized depth map D( DxHXW) 를 얻습니다. probability of discretized depth map 이란 깊이 map을 단순히 1 채널로 예측한 후 sigmoid 처리하는 것 아닌 D channel 로 예측해서 각각의 채널의 특정 깊이 값을 가진다음 모든 channel을 더해서 최종적으로 1채널의 깊이 map을 얻습니다.
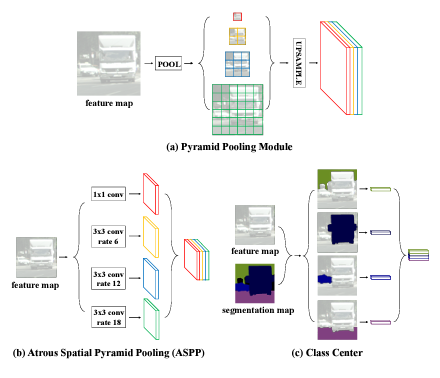
2. 예측한 깊이 정보를 더욱 정확하게 만들기 위해서 Depth prototype을 예측합니다. 이 Depth prototype을 위 그림과 같이 Segmenation에서 제안된 Class center 방식에서 영감을 받아서 제안되었습니다. 이 class center는 위 그림과 같이 segementation을 입력으로 받아서 각 클래스를 하나의 vector로 변경한 후 다시 segmetation에 곱해져서 attention을 합니다. Depth estimation 에서도 depth를 하나의 channel로 예측하는 것이 아닌 probability of discretized depth map로 D 개의 클래스와 같이 예측이 되니 동일한 작업을 할 수 있습니다. 따라서 class center와 동일하게 depth를 입력으로 넣고 Depth의 각 bin 에 대해 attention 할 수 있는 depth prototype을 예측합니다.
3. 마지막으로 예측한 depth와 곱해져서 예측한 depth를 더욱 정확하게 만듭니다.
이렇게 매우 작은 depth를 예측하며 실제 LiDAR와 비교해서 학습을 함으로써 3D detection model에 실제 depth 정보를 주게 되며 Pseudo-LiDAR가 필요없어지게 만듭니다.
Depth-Aware Transformer
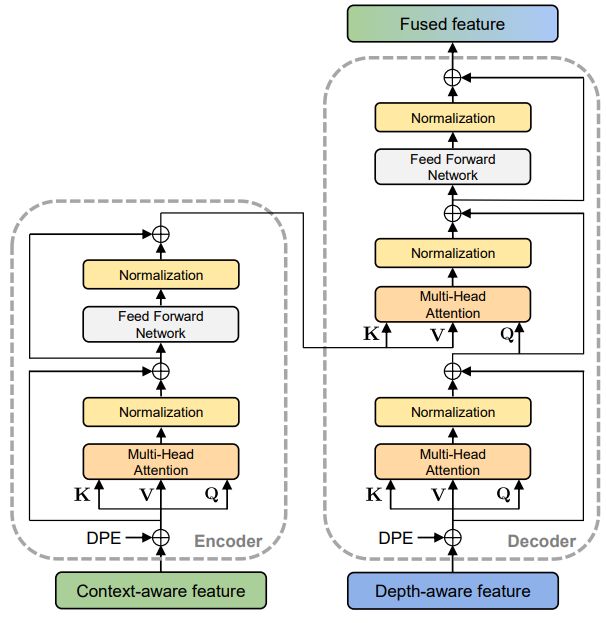
Transformer 는 위 그림과 같이 기존 ViT와 유사하게 사용했습니다. 이때 encoder의 입력은 단순한 CNN feature를 사용하고, decoder의 입력으로는 DFE를 통과한 depth information을 가지고 있는 feature를 사용합니다.
여기서 중요한 역할을 하는 것은 Depth positional encoding(DPE) 모듈입니다.
기존 Transformer에는 Positional encodeing이라는 과정이 있었습니다.
NLP에서는 문장에서 단어의 위치를 뜻했으며, vision에서는 각 픽셀의 위치를 뜻하며 성능 향상을 일으켜주는 역할을 했습니ㅏㄷ. 이 논문에서는 이 Positional encoding에 pixel 정보를 넣어주는 것이 아닌 pixel의 depth 정보를 넣어줘서 3D detection 성능을 향상 시켰습니다.
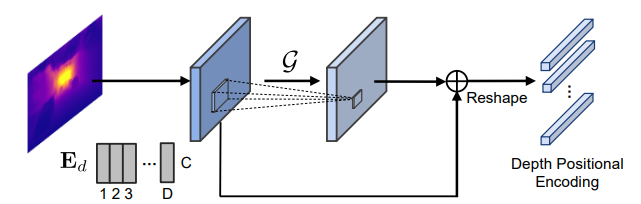
depth encoding 에 넣을 depth는 위 그림과 같이 생성합니다. DFE 모델을 통해서 예측한 depth를 conv 태워 vector로 변경후 transformer에 넣습니다. 이를 통해 transoformer가 각 pixel의 depth 정보를 더욱 고려하며 3D box를 예측하게 됩니다.
Loss
Loss는 M3D SSD[1]의 방식을 그대로 사용했으며 DFE계산하는 loss만 추가했다고 합니다. 이 M3DSSD에 대해서는 추후에 리뷰를 써볼까합니다.
Experiment
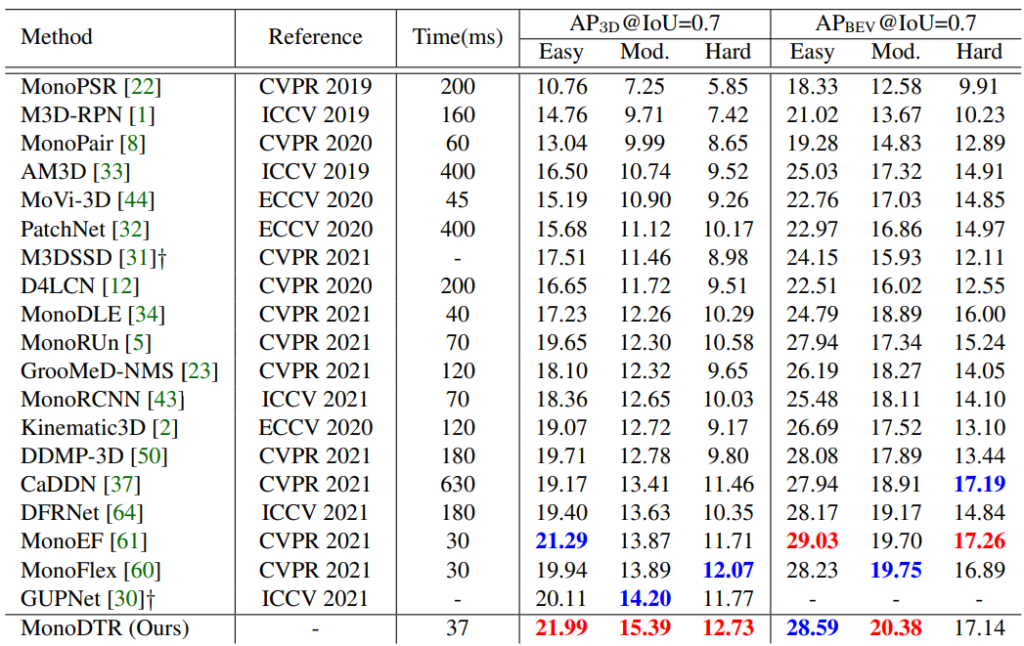
먼저 가장 중요한 KITTI Car test에서 성능 평가 입니다. 보면 가장 좋은 성능을 보이며, 다른 depth assitant 모델인 DFRNet [64], CaDDN [37] 와 DDMP-3D [50] 과 비교해서 높은 성능 향상과 속도 향상을 보입니다ㅣ.
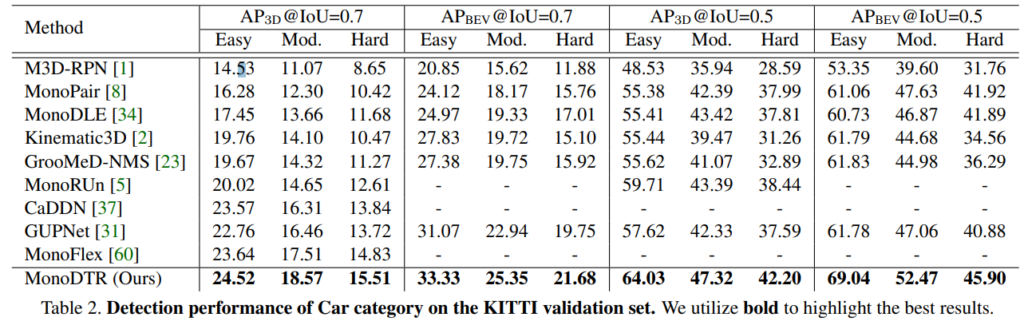
또한 validation에서도 모든 메트릭에서 SOTA 성능을 기록 했습니다.
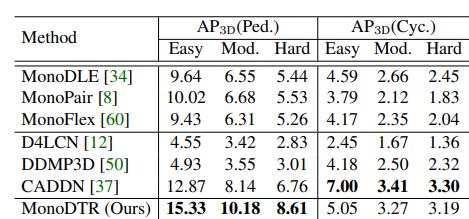
car category 뿐만이 아닌 pD와 Cyclist 에서도 좋은 성능을 보여줍니ㅏㄷ.

ablatio study 입니다. 각 방법론이 성능 향상에 뛰어난 결과를 보여주며 최종 방법론의 시너지를보여줍니다.

정성적 결과입니다. 기존 방법론들은 이렇게 3D를 그리는 것 자체가 어려운 경우가 많은데 괜찮게 나온다고 합니다.
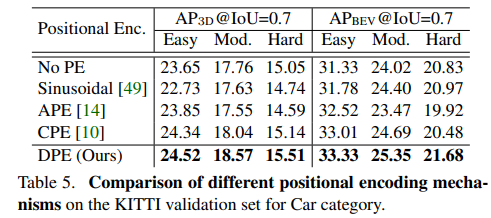
DPE를 다른 방법론으로 변ㅕㅇ헀을때 성능 평가 결과 입니다 .
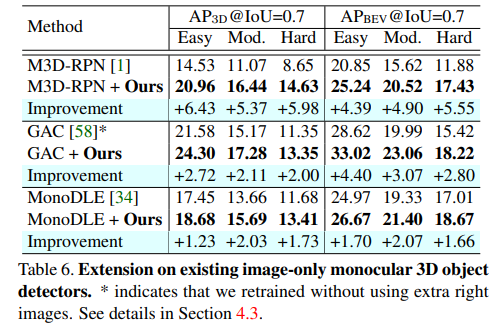
기존 방법론에 제안하는 방법론을 붙혔을때의 일반성을 입증했습니ㅏㄷ.
Reference
[1] M3DSSD: Monocular 3D Single Stage Object Detector
3D detection에서 mono카메라로 구한 depth와 instrinsic파라미터를 이용해서 pseudo-lidar로 활용하는 연구를 한다는 걸로 이해하였는데요. 하시려는 연구의 목적이 라이다 센서를 사용하지 않고 3D detection을 하기 위한게 아니라, LiDAR를 GT삼아서 pseudo-lidar를 얻는 과정을 좀 더 잘 학습하면, 전체적인 성능이 오르며, 이러한 것을 목적으로 하는 연구라고 보면되나요?
넵 후자라 생각하시면 됩니다. LiDAR를 GT로 삼을지는 미지수이지만 그래도 그림은 얼추 맞습니다