이번에 가져온 리뷰는 “Event boundary detection”입니다. CVPR 2022 논문들 중에서 딱 보이길래… 눈길이 가서 읽었습니다. 이 “Event boundary detection”는 일반적인 이벤트의 경계를 찾는 task입니다. CVPR 2021 챌린지에서 Long-form Video Understanding의 일한으로 “Generic Event Boundary Detection Challenge”라는 챌린지도 진행되었고 꽤 최근 시작된 연구로 보입니다. (이하 GEBD라고 부르겠습니다.)
Introduction
이 논문에서 가장 눈길이 갔던 부분은… 기존 연구들은 optical flow를 쓰기 위해 많은 연산량을 투입해서 계산하지만, 여기서는 그 optical flow를 MPEG-4의 압축 방법론으로 대체한다는 점이었습니다. 사실 Action 연구분야에서 “Action Recognition in Compressed Videos”라는 이름으로 이러한 연구들이 수행되어졌더라고요. 그럼 MPEG-4에서 어떻게 압축을 하길래 이런 방법론이 가능할까요? 먼저 GOP에 대해 알아봅시다.
MPEG-4의 GOP (group of pictures)
GOP는 말 그대로 사진들의 모음입니다. 비디오도 사진들의 모음이기 때문에 이렇게 부르는데, 비디오를 말 그대로 사진들의 모음으로 구성하게 되면 용량이 엄청 커지게 되겠죠? 그래서 압축을 수행합니다. 이 압축 방법론이 우리가 부르는 비디오 코덱이고, 이 코덱의 종류중 하나가 MPEG-4입니다.
그래서 GOP란 무엇이나면… I-프레임 / P-프레임 / B-프레임으로 구성된 이미지 묶음입니다.

- I-프레임 : GOP의 키프레임. 원본 이미지가 그대로 저장된 프레임
- P-프레임 : 순방향 예측 프레임으로 이전 I 프레임을 기준으로 변경된 부분만 예측하여 저장된 프레임
- B-프레임 : 양방향 예측 프레임으로, I와 P프레임 모두를 기준으로 변경된 부분을 예측하여 저장한 프레임
그리고 이 3가지 프레임은 위와 같이 구성되어 있습니다. 이 GOP는 이렇게 구성되어 있다는 것을 알고, 다시 논문 리뷰로 돌아가봅시다.
이제 여기서 “기존 연구들은 optical flow를 사용한다”는 부분을 집중하면 됩니다. 이 P-프레임은 기본적으로 I-프레임으로부터의 변경된 부분을 예측한다고 했죠? 실제로는 이 P-프레임은 motion vector와 residual이라는 것으로 나뉘어 저장되어있습니다.
하지만 이 feature들이 같은 embedding space에 있는 것은 아닙니다. 그래서 이걸 같은 공간으로 내리는 방법을 학습할 필요가 있습니다. 이 과정에서 I-프레임을 motion vector와 residual을 이용해서 정제합니다. 그럼 I-프레임과 P-프레임이 같은 feature space를 가지게 되어 학습에 사용할 수 있습니다. 물론… 이 방법이 속도면에서는 좋을 수 있지만, 여기서 event boundary를 예측하는 temporal contrastive module이 인간의 행동만 예측할 수 있다는 한계점도 있긴 합니다.
아무튼 4가지 컨트리뷰션을 정리하면 아래와 같습니다.
- GEBD를 위한 end-to-end 압축 비디오 표현 학습 방법론 제안
- motion vector와 residual을 활용해서 I-프레임의 feature를 효율적으로 사용할 수 있는 SCCE 모듈 제안
- 시간적 정보를 활용해서 event boundary를 예측하는 temporal contrastive module 제안
- CVPR’21 LOVEU Challenge SOTA에 근접하면서도, 4.5배 빠른 속도를 달성함
Method
기존 방법론들은 GEBD를 프레임 단위의 이진분류로 해결하고자 했습니다. 하지만 이 논문에서 제안하는 방법론은 비디오 클립 단위로 이 문제를 해결합니다. 기본적인 입력 수식은 V 는 video clip / N은 GOP의 묶음으로 표기되어 V = \{ I_i, P^1_i, P^2_i, ..., P^T_i\}^N_{i=1} 와 같이 표기됩니다.
앞에서 P프레임은 motion vector와 residual로 구성된다고 했죠? 그래서 motion vector는 M^t_i ∈ R^{2×H×W}와, residual은 R^t_i ∈ R^{3×H×W}를 압축된 비디오로부터 연산 없이 얻을 수 있습니다.
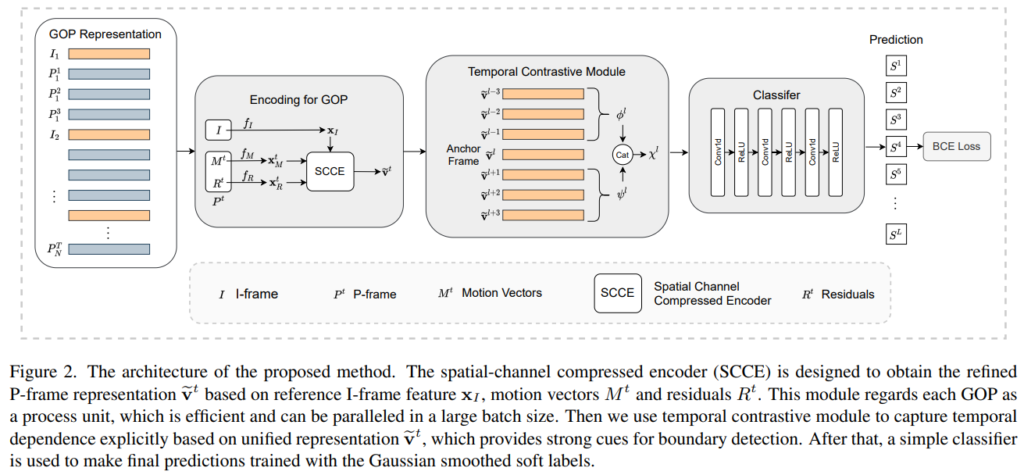
그래서 전체적인 아키텍쳐를 보면 위와 같습니다.
Spatial-Channel Compressed Encoder
이 부분을 이해하려면 코덱에서 사용하는 매크로 블록에 대한 이해도 필요합니다. 매크로 블록은 움직임을 예측하기 위해 여러 픽셀을 블록 단위로 묶어(16×16 크기라던가) 예측하는 단위입니다. motion vector는 이 매크로 블록 단위로 방향이 예측되어 기록되고, residual은 움직이는 물체의 경계에 대한 정보와, I-프레임의 중요 영역을 식별하는데 필요한 정보를 가지고 있습니다.
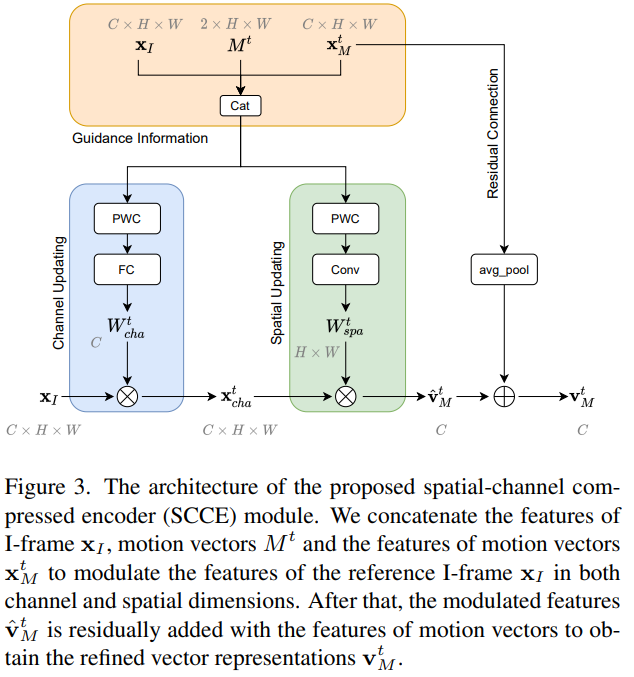
아무튼 코덱에서 이렇게 처리된다는 점을 알고, SCCE 모듈(Spatial-Channel Compressed Encoder Module)을 살펴봅시다. 먼저 I-프레임의 feature를 백본 네트워크를 통해 계산합니다. 그런 다음 P-프레임의 motion vector와 residual 또한 계산합니다. (코덱에 저장되어있음)
그런데 사실 문제가 있습니다. motion vector는 scene이나 object의 움직이는 패턴 정보를 저장하고 있고, residual은 compensation information을 제공해줍니다. 하지만 이 둘 중 어느것도 scene의 context information이 없다는 것입니다.
그래서 I-프레임에 I-프레임과 P-프레임의 정보를 바탕으로 만들어진 guidance information으로 attention을 channel축과 spatial축에 주는 형태로 되어있습니다.
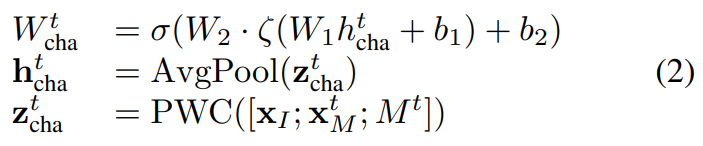
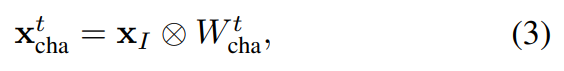
그럼 먼저 Channel Updating이 어떻게 되는지 봅시다. Channel updating과 spatial updating 모두 PWC-Net(Optical flow를 예측하는 가벼운 모델)을 이용합니다. 수식만 보면 복잡하지만… 결국은 I-프레임과 motion vector를 바탕으로 PWC-Net을 통해 optical flow를 예측하고, 이를 weight로 사용해서 I-프레임의 feature에 곱해주는 형태입니다. (motion 정보에 attention을 주는 방식)
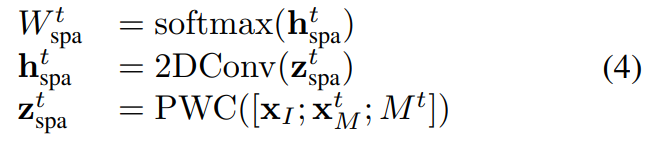
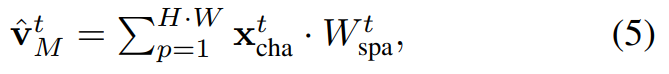
그리고 spatial updating도 동일하게 channel updating과 동일하게 작동합니다.
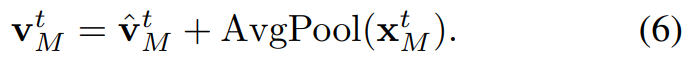

마지막으로 이렇게 구해진 feature에 그림을 보면 residual connection이라고 해서 motion vector의 feature와 I-프레임과 motion vector를 통계 계산된 refined motion vector를 더해줍니다. (Attention 방법론을 통해 I-프레임의 표현력을 증가시키기 위함) 최종적으로는 이 refined motion vector와 residual을 더해주는데요. 이 부분은 residual이 가지고 있는 compensation information을 더해주기 위함입니다. 추가적으로 이 과정들이 GOP 단위로 계산되기 때문에 병렬 처리가 가능해서 매우 빠르고 효율적이라고 합니다.
Temporal Contrastive Module
SCCE 모듈을 통해 만들어진 feature를 바탕으로 이제 이벤트의 경계를 예측하는 모듈이 이 모듈입니다. 경계를 예측할때는 프레임의 앞 뒤를 살펴보고 경계 프레임인지 아닌지를 구분합니다.
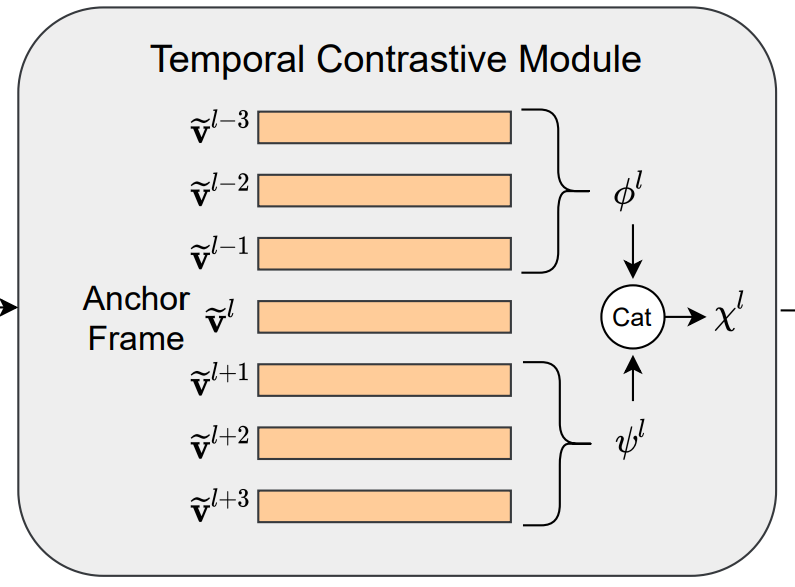
경계 프레임으로 예측된 프레임을 기준으로 이렇게 앞/뒤 프레임을 concat 해서 contrastive feature x^l을 만드는데요. 이 앞/뒤 프레임은 ϕ^l = \sum^k_{j=1}W_j \cdot \tilde{v}^{l-j}로 계산합니다. (프레임에 학습되는 weight를 곱해서 더해줌) 이렇게 모든 예측된 이벤트 경계 프레임의 contrastive feature를 만들어주는 것이 이 모듈의 역할입니다. (최종적으로는 \{ x^1, x^2, ... x^L \}과 같이 feature를 모읍니다.)
Loss Function
학습 과정에서 특정 프레임을 경계로 잡는 GT를 사용하게 되면 학습이 잘 안될 수 있습니다.

예를 들면 위와 같은 상황에서는 이진분류로 보면 그냥 틀린거지만, 실제로는 근접하게 경계를 예측한 경우가 됩니다. 이런 문제를 해결하기 위해, Gaussian kernel을 이용하여 GT를 가공해서 soft-label으로 바꾸어 사용합니다.
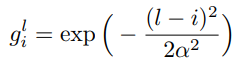
변환은 위와 같은 수식을 거쳐서 변환이 됩니다. (i=시간/l=시간에 해당하는 라벨/a=1) 이러한 과정을 통해서 보다 더 효율적으로 학습을 수행했다고 합니다. 최종적으로는 이 소프트 라벨에 classifier를 붙여서 예측 점수를 구하고, binary cross-entropy loss를 사용했다고 합니다.
Experiments
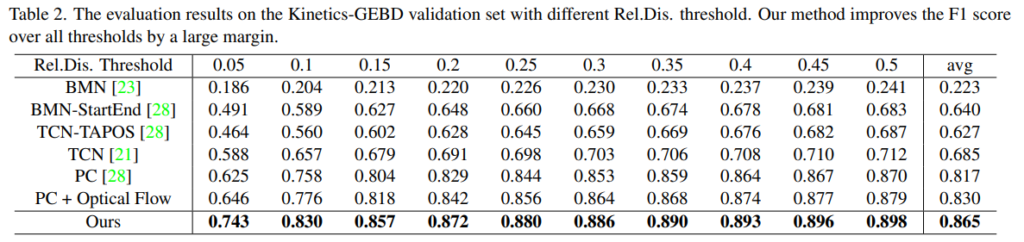
이 태스크 전용으로 나온 데이터셋인 Kinectics-GEBD에서는 SOTA 성능을 보이고 있습니다. PC 방법론이 페이스북에서 벤치마크로 제시한 성능인데, Optical Flow는 원래 성능에 없는데 논문 저자들이 입력으로 따로 줬다고 합니다. 이를 통해 Motion 정보를 보는 것이 성능 향상에 영향이 있다는 것과 저자들의 방법론이 효율적으로 작동했음을 보여줍니다.
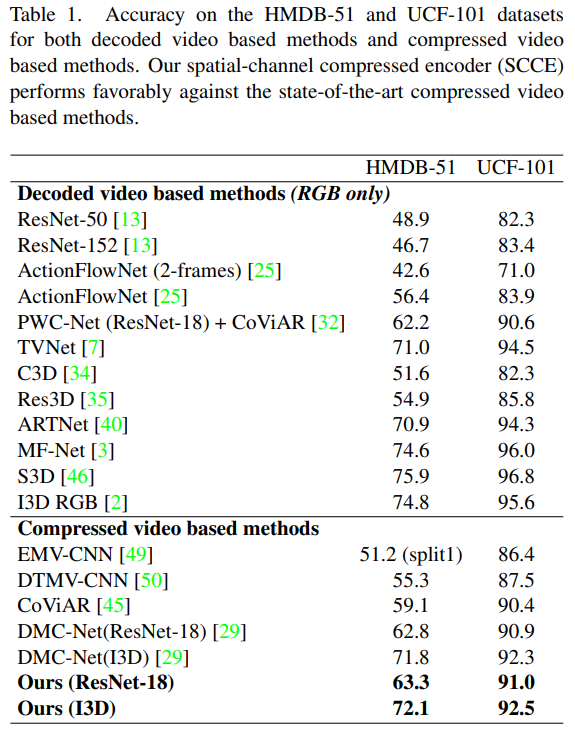
두번째로는 기존에 action recognition에 사용되던 데이터셋에서의 성능 비교인데요. 성능을 볼 때, 감안해야하는 것으로… 이 방법론 자체가 이벤트의 경계를 예측하는 것이지 action recongition task에 그렇게 적합하지 않으니 참고해서 봐달라고 하네요. 그럼에도 불구하고 압축된 비디오를 사용하는 다른 방법론들에 비해 약간의 성능 향상이 있음을 확인할 수 있습니다. 논문 저자들은 이러한 성능 향상이 SCCE 모듈이 P-프레임의 표현력을 향상시켰기 때문에 발생한다고 분석하고 있습니다.
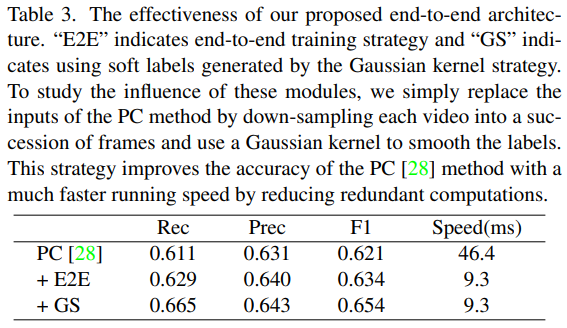
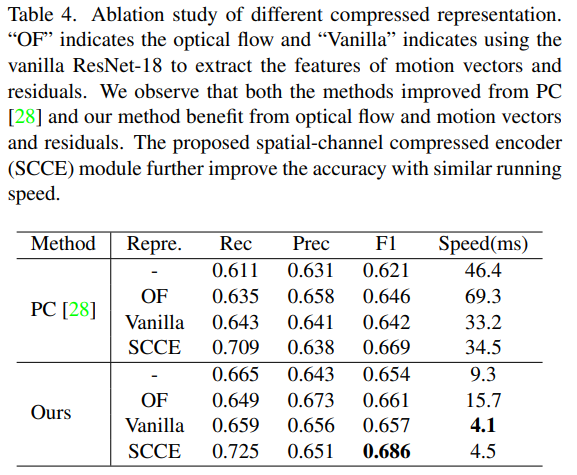
그리고 Ablation study로 두가지를 수행했습니다. 표3은 end-to-end 학습 방법론과 GS(가우시안 커널로 soft label로 학습하는 전략)을 기존 베이스라인 성능이었던 PC 방법론에 적용해본 결과 속도/성능 두 부분에서 모두 향상되었다고 합니다. 그리고 표 4는 여러 reprsentation에서의 성능과 속도를 비교한 부분인데요. motion vector를 사용하는 방법론들의 속도가 전반적으로 빨랐고, SCCE는 속도가 조금 떨어지기는 하지만 성능이 많이 올랐습니다.
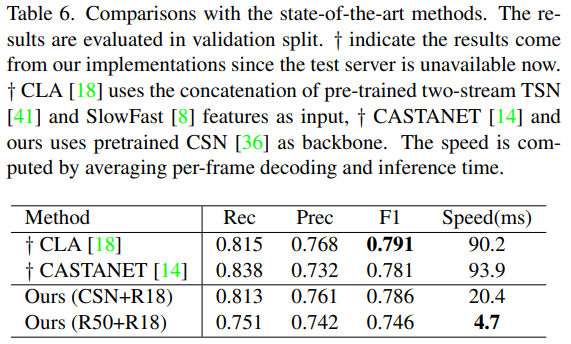
그리고 이건 CVPR 챌린지에서 SOTA 성능을 달성했던 방법론들과의 비교입니다. CSN이 CASTANET에서 사용한 백본이라 그 성능을 비교하면 되는데요. 비슷한 성능에 속도는 4배 이상 빠른 것을 볼 수 있습니다.
Conclusion
코덱 압축을 풀지 않고, motion 정보로 사용하는 방법론을 처음 봐서 매우 재밌게 읽었습니다.
리뷰 잘 읽었습니다. boundary detection은 평가를 어떤 기준으로 하나요?
이 논문에는 딱히 깊은 설명이 없어서 챌린지 사이트에서 가져왔는데요.
We use Relative Distance (Rel.Dis) to determine the correctness of each prediction. Rel.Dis is the error between detected and ground-truth timestamps, divided by the length of the whole video. Given a fixed threshold for Rel.Dis, we can determine whether a detection is correct (i.e. <=threshold) or incorrect (i.e. >threshold), then compute precision, recall and F1 score on the whole dataset.
라고 합니다. Boundary 포인트를 예상하고, 그 지점이 GT랑 threshold 이내면 맞춘거고 아니면 틀렸다고 판단하는 식으로 계산합니다.
리뷰 잘 읽었습니다.
1. 리뷰 내용 중 “event boundary를 예측하는 temporal contrastive module이 인간의 행동만 예측할 수 있다는 한계점도 있긴 합니다.” 라는 부분이 있는데, 해당 논문에서 성능 결과를 내기 위해 사용한 데이터셋 중 인간의 행동에 대한 게 아닌 데이터셋도 있나요?
2. 그리고 GOP가 I/P/B 프레임의 묶음인 걸로 이해하였는데, 기본 입력 수식에서 V가 I와 P로만 이루어져있고 B가 보이지 않아 질문드립니다. 이들 중 일부만 있어도 GOP 묶음인건가요?
데이터셋에 대해서는 이 논문에서는 없지만 다른 논문을 확인해보지는 않았습니다. 그리고 GOP는 I/P/B로 이루어지는 것이 맞는데, GOP를 하나의 묶음으로 볼때, B 프레임을 복원하려면 다음 GOP의 I 프레임이 필요합니다. 그래서 계산할 때 GOP 단위로 클립을 구성하기 위해 B프레임을 뺀 것 같네요.
Decoded base 방식과 compressed base 방식 각각의 장단점은 무엇인가요?
일반적으로 Decoded base 방식이 더 정확한 optical flow를 계산하기 때문에 더 성능이 좋은 것으로 이해했습니다. 그에 반비례해서 모델이 무겁고, 속도가 느리고요. 반면에 compressed base 방식은 코덱을 통해 motion vector를 계산하기 때문에 optical flow를 추가적인 연산 없이 계산할 수 있지만, 그렇게 정확하지는 않다는게 단점으로 이해했습니다.