Abstract
CNN feature를 이용한 이미지 representation 은 기존의 short-vector represnetation방식보다 좋은 성능을 낸다. 그러나 기하학적 정보가 필요한 re-ranking방식과 호환되지 않으며, 정확한 descriptor매칭, 기하학적 re-ranking, 또는 쿼리 확장에 의존하는 일부 벤치마크에서는 여전히 성능이 떨어진다. 이 논문은 CNN에서 나온 원시 정보를 활용하여 초기 검색 및 re-ranking에 활용하며, compact한 feature vector를 만들어 여러 입력을 넣을 필요 없이 이미지의 여러 영역을 인코딩한다. 또한 통합 이미지를 확장하여 conv layer activation에 max-pooling을 적용하여 효과적으로 일치하는 객체를 localize할 수 있다. bbox는 이미지 re-ranking에 사용되고, 본 논문은 결과적으로 존재하는 CNN 기반의 인식 파이프라인을 개선하였다.
Introduction
contribution은 다음으로 정리할 수 있다.
- conv layer의 activatiton으로부터 뽑은 compact한 이미지 representation을 제안. 다시 multi-input 을 넣지 않아도 되며, 특정 객체 검색을 목표로 한다. 초기의 repsentation이 초기 검색 및 re-ranking에서 모두 사용
- 일반화된 평균을 이용하여 max-pooling과 함께 전체 이미지를 이용할수 있다. 이는 CNN activation의 2D map에서 직접적으로 특정 객체의 localization을 위해 사용된다.
- localization 방식을 re-ranking에 사용하고 단순하지만 효과적으로 쿼리를 확장할 수 있도록 한다.
Background
pre-trained CNN을 이용하고, fc 레이어는 사용하지 않는다. 3D tensor를 2D feature 들의 집합 \mathcal{X} = \left\{ \mathcal{X_i} \right\} (i=1,2,...,K)으로 여기고 이때 K는 채널수이다. \mathcal{X}_i(p)는 i번째 채널의 위치 p에서의 값이다. 따라서 max-pooling에 의한 결과는 다음과 같다.
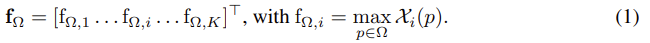
Maximum activations of convolutions (MAC)
K-차원 벡터들의 cosine similarity로 계산된다. MAC은 WxH인 전체 영역에 대한 max-pooling을 적용하므로, 위치를 인코딩하지 못한다. 이는 conv 필터의 local maximum을 인코딩하기 때문이다.

Encoding Regions Into Short Vectors
CNN conv layer의 activation으로부터 어떻게 image 영역들을 표현하였는지에 대한 설명이다. region vector들은 short signature를 만들어 이미지 retireval에서 filtering 단계에 사용된다.
Region feature vector
\bold{f}{Ω}는 이미지 I를 표현하는 featuer vector로 \bold{f}{Ω} = [f_{\mathcal{R},1}, ..., f_{\mathcal{R},K}]^T이고 f_{\mathcal{R},i}는 i번째 채널의 maximum activation이다.
R-MACregional maximum activation of convolutions
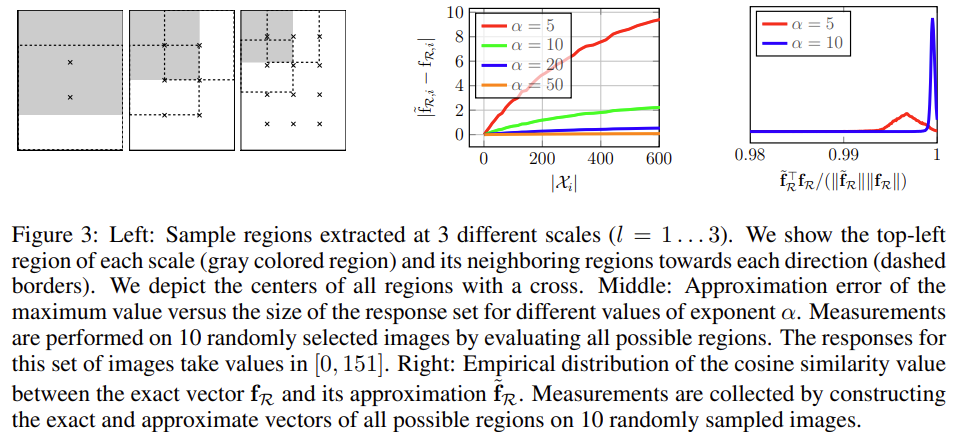
서로 다른 크기의 L개의 영역을 고려한다.가능한 가장 큰 크기의 영역을 l=1로 하고, 중복되는 영역이 40%정도가 되도록 영역을 균일하게 샘플링한다. 영역 l일 때 m로 영역은 l ×(l+m-1)로 샘플링한다. (Figure3 Left참고)
각 영역과 과련된 feature vector를 계산하고 l2-normalization, PCA-whitening(whitening이란 feauter들이 uncorrelated하게 만들어주고 variance를1로 만들어주는 것), l2-normalization을 수행해준다. feature vector들을 summing과 l2-normalization을 이용하여 이미지에 대한 single vector를 만들어준다.
Object Localization
효율적으로 2D feature의 집합 \mathcal{X}에 대한 approximate max-pooling을 수행하기 위해 통합 이미지의 확장을 제안한다.
Approximate integral max-pooling
\mathcal{X}i가 음이 아니므로(음의 값이 되지 않도록 relu를 적용함.) generalized mean [Dollar, Piotr, Tu, Zhuowen, Perona, Pietro, and Belongie, Serge. Integral channel features. In BMVC, 2009.]을 이용하여 f{\mathcal{R},i}를 근사시킨다. 다음 식을 이용.
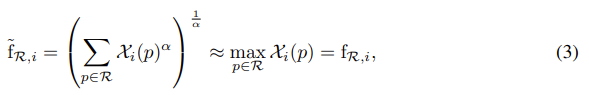
*** 수학적 의미에 대하여 잘 이해가 가지는 않지만,![]() 이 식을 그려보면 아래와 같은 그래프가 그려집니다. 아래의 그래프는 대략 4의 값으로 근사 된다고 합니다.
이 식을 그려보면 아래와 같은 그래프가 그려집니다. 아래의 그래프는 대략 4의 값으로 근사 된다고 합니다.
α>1이고, α→+∞가 될 때 \tilde{f}<em>{i} → f</em>{i}[]latex] 가 된다.</p> <p>figure3 middle이미지는 근사치의 오차로, α가 커질수록 오차가 0에 가까워지는 것을 확인할 수 있다.</p> <p>최대값 근사를 이용하여 통합 이미지를 영역의 featuer vector를 계산하는 데 사용할 수 있다. 특정 정사각형 영역 [latex]\mathcal{R}의 영역 featuer vector를 f_{\mathcal{R}}라 정의하자. 각 채널마다 2D tensor의 적분 이미지를 구성한다. 그 다음, (3)의 합은 4개 항에 의해 합으로 구해진다. →많은 영역에 대한 효율적 max-pooling 계산이 가능하다.
정확한 vector와 근사값의 cosine similarity를 계산하여 품질을 계산한 결과는 figure3의 right이며, 랜덤하게 선택된 10개의 이미지의 모든 가능한 영역에 대해 측정된다. α는 5에서도 높은 정확도를 보이지만 10일 때 더 높은 정확도를 가지기 때문에 모든 식에서 α는 10으로 설정하였다.(더 정확도가 높기 때문)
Window detection
하나의 객체로 이루어진 이미지 Q가 있다고 가정하자. q를 MAC feature vector라 하자. 이미지 I의 CNN activation \mathcal{X}에 정의된 2D 영역은 q와 similarity를 최대화하기 위해 다음 식으로 계산한다.

\hat{\mathcal{R}}는 원본 이미지I의 ({{W}\over {W_I}},{{H}\over {H_I}})픽셀로 매칭되어 Q의 객체에 대략적인 위치를 제공한다. max를 이용하므로 영상의 노이즈로부터 자유롭다.
AML: approximate max-pooling localization.
평가하는 영역의 수를 제한하고 간단한 heuristics으로 best영역을 local하게 refine한다.
- 후보 영역을 균일하게 샘플링한다. (search step이 t와 동일하게)
- aspect ratio가 쿼리 이미지의 s배 보다 큰 영역은 버린다.
- 좌표 하강 방식으로 최적의 영역 파라미터를 최대 3유닛 변경하고, 최대 5번 refine 과정을 수행한다.
Retrieval, Localization and Re-ranking
Initial retrieval
feature vector로 데이터베이스에 있는 모든 이미지에 대하여 유사도 계산. 유사한 query이미지에 대해 feature vector를 뽑음. filtering 단계에서 직접 query이미지와 데이터베이스의 feature vector 유사도 측정.
⇒ 최초 ranking 얻음
Re-ranking
상위 N개의 이미지에 대하여 수행하고 AML이 쿼리 및 데이터베이스 이미지에 적용된다. 쿼리 이미지에는 AML이 적용된 MAC vector로 나타내고, 데이터베이스에 있는 이미지들은 \mathcal{X}로부터 표현된다. 쿼리와 유사도가 가장 높은 영역의 점수를 이용해 re-ranking을 수행한다.
Query expansion(QE)
re-ranking을 거쳐 얻은 5개의 top-rank 이미지를 모아 query vector와 함께 합쳐 평균값을 구한다. 유사도는 이 mean vector를 활용하여 다시 한번 top N개의 이미지를 re-ranking한다.
Experiments
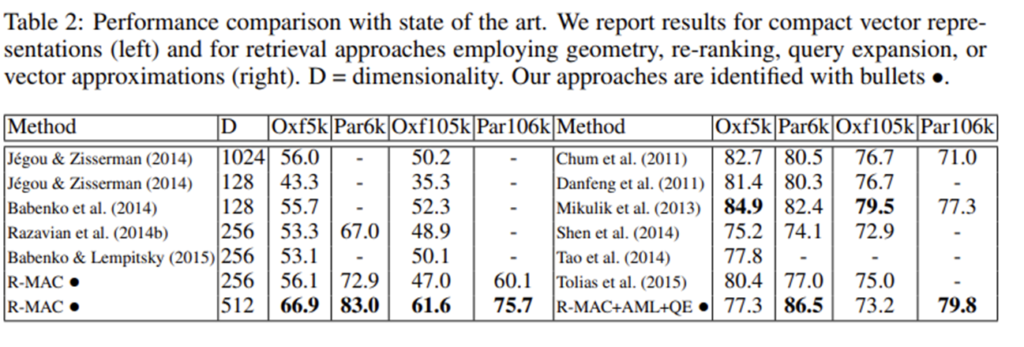
Oxford5k 쿼리 이미지와 대응하는 positive images 쌍들을 이용하였다. 처음에 이미지의 global한 영역에 대한 search를 수행한 후, 일부 region에 대하여 빠르게 detector를 적용하여 refine을 하였다. 성능은 IoU를 리포팅하였다.
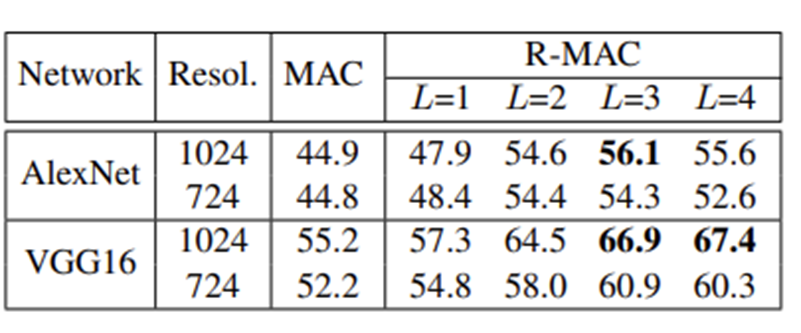
- Oxford5k 데이터셋에 대한 MAC과 R-MAC성능 비교
- Resol.은 해상도 의미
- R-MAC에서 확연한 성능 향상을 확인할 수 있음.

- 정량적 결과로, 왼쪽의 쿼리 이미지에 대하여 각 쿼리마다 윗줄은 initial raking의 결과이고, 아랫줄은 re-ranking의 결과이다.
- 아랫줄 이미지들의 아래에 있는 숫자는 [initial ranking에서의 랭킹]→[re-ranking이후의 랭킹]이다.
리뷰 잘 봤습니다. 질문드릴게 몇가지 있는데 먼저 리뷰 내용 중
“단일 셀에 대한 max pooling은 representation의 불변성을 준다.”에 대한 내용이 무엇을 의미하나요? 여기서 단일 셀은 무엇을 의미하고 왜 max pooling이 representation의 불변성을 줄 수 있는 것인가요?
두번째로는 리뷰 내용 중 “각 영역과 과련된 feature vector를 계산하고 l2-normalization, PCA-whitening(whitening이란 feauter들이 uncorrelated하게 만들어주고 variance를1로 만들어주는 것), l2-normalization을 수행해준다.” 에서 L2-normalization, PCA-whitening, L2-normalization을 진행한다는 것으로 보여지는데 L2-normalization을 그럼 PCA-whitening 전후로 적용해준다는 의미인가요?
우선 첫번째로 질문하신 내용은 제가 작성중에 이동 변환에 대한 불변성인데 해당 내용을 누락하였습니다.. 해당 내용은 보충해두도록 하겠습니다. 또한 단일셀이 의미하는 것은 maxpooling이 적용되는 kernel을 의미하는 것으로 이해하였습니다.
두번째 질문에 대해서는 이해하신 것이 맞습니다. PCA-whitening 전후에 L2-Normalization을 적용해준다고 합니다.
서로 다른 크기의 R개의 영역에서 R의 갯수는 이미지 크기에 따라 결정되나요? 또한 그림 2에서 유사성에 큰 영향을 주는 패치라고 했는데, 유사성이 가장 높은 패치는 어떻게 결정되나요?
L개의 다른 크기에 대하여, 다른 크기의 L마다 영역R에 대한 연산을 수행합니다. L은 1,2,3,4로 실험을 하였고, R의 개수는 이미지 크기에 따라 결정이 됩니다. 또한 쿼리와 database이미지 모두 각각 R-MAC을 수행하여 cosine similarity가 가장 큰 영역을 찾습니다.
좋은 리뷰 감사합니다.
contribution 의 1번에서 ‘multi-input 을 넣지 않아도 되며’ 라는 말이 있는데, 여기서 말하는 multi input이란 어떤 것을 의미하는 건가요?
그리고 R-MAC 에서 서로 다른 크기의 R개의 영역을 각각 Feature vector로 표현 했다고 했는데, 이는 기존의 MAC 방식에서 포함하지 못한 위치정보를 포함하기 위해 사용했다고 봐도 되나요 ?