요약:
본 논문은 self-supervised의 발전을 이끈 contrastive learning의 positive, negative pair의 구성에서 False Negative의 존재에 대해 집중한 논문이다.
Introduction:
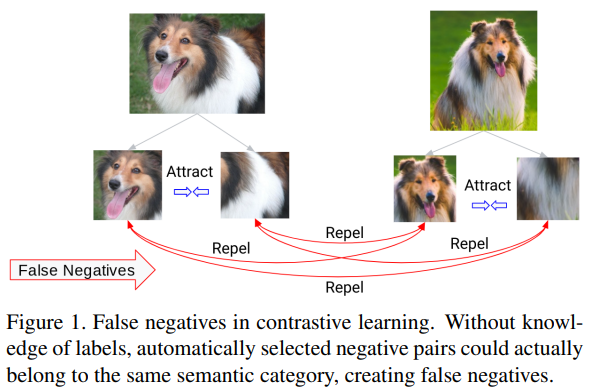
False negative 란 그림에서 보는 repel 관계이다. 그동안 self-supervised를 이끈 수많은 연구는 contrastive learning을 기반으로 발전하였다. 해당 연구들은 대부분 이미지 자신을 augmentation 하여 positive pair를 구성하고, 랜덤으로 negative pair를 구성하는 방식으로 진행하였다. 이러한 방식의 문제점은 다른 instance지만 실제 의미가 같은, 예를 들어 Fig.1의 두 강아지 그림과 같은 pair들도 negative로 묶일 수 있다는 것이다. 이렇게 negative로 묶인 두 pair를 False Negative라고 하며, 이를 해결하기 위한 연구를 해당 논문에서 진행하였다.
Method:
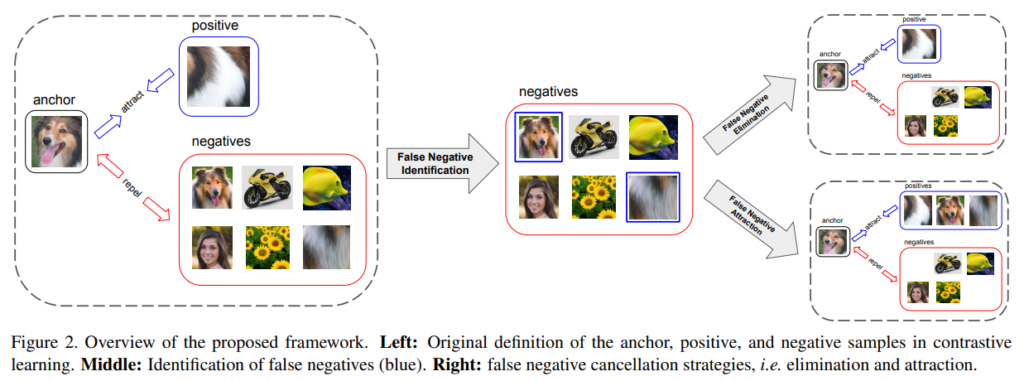
본 논문에서 false negative를 해결하기 위해 구성한 네트워크는 다음과 같다. 1) False Negative Elimination과 2) False Negative Attrection으로 구성되었다. 이름 그대로 contrastive learning을 위한 negative pair에서 false negative라고 예측되는 instance를 제거하고(false negative ellimination), 이를 오히려 positive pair로 이용해(false negative attrection) 모델의 학습을 돕는 구조이다.
다음은 제안하는 모델의 false negative identifying 방법이다.

이처럼 1) 각 anchor에 대한 support set을 생성하고, 2) negative sample과 anchor의 각 sample간의 유사도를 계산한다. 3) 이후 유사도의 평균을 계산하고 4) 해당 aggregated score가 가장 큰 smaple을 false negative samples로 한다. 이런식으로 구분한 false negative를 이용하여 contrastive learning을 진행한다. 이때 support set은 그림3에서 볼 수 있듯이 원본 이미지를 augmentation한 결과이다.

Experimental:
- Ablation Studies
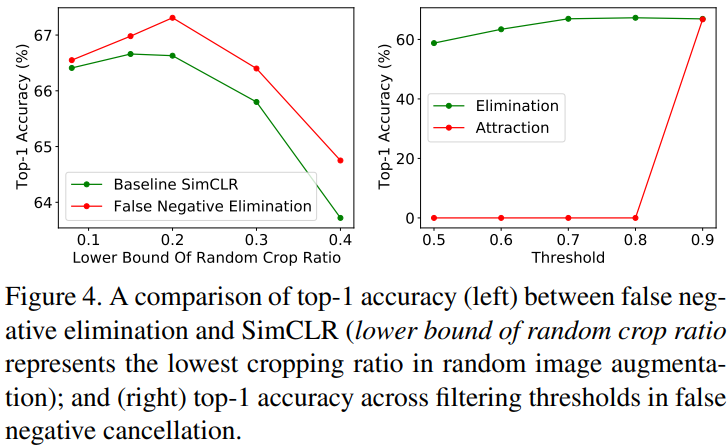
Figure4는 Ablation studies이다. 왼쪽의 그림을 통해 baseline인 SimCLR에 False Negative Ellimination stage를 적용했을 때 성능향상이 있음을 확인할 수 있다. 총 8190개의 negative samples에서 무시할 수 있을 정도의 false negative 후보를 제거하여 얻은 성능향상이라고 한다. 오른쪽의 Ellimination stage와 Attraction stage를 비교한 결과를 봤을 때 false negative를 예측하는 identification stage의 성능이 영향이 큰것은 Attraction이라는 것을 알 수있는데, Attraction의 경우 false negative에 대한 정확도가 낮을 경우 효과가 없음을 알 수 있다.
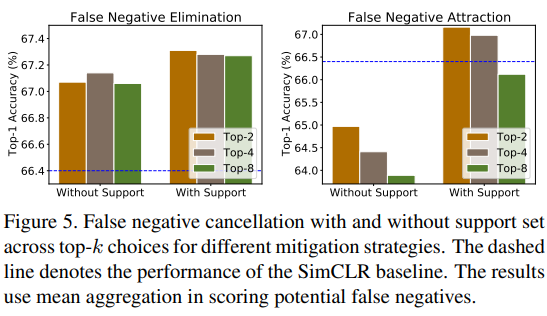
또한 Fig.5에서는 제안하는 구조에서 support set의 사용 여부가 각 stage에 미치는 영향을 분석했다. 분석 결과 support set의 사용 여부는 attraction에 더욱 영향을 미침을 알 수 있으며 즉, false negative 검출 정도가 attraction 전략에 큰 영향을 미침을 다시한번 확인할 수 있다.
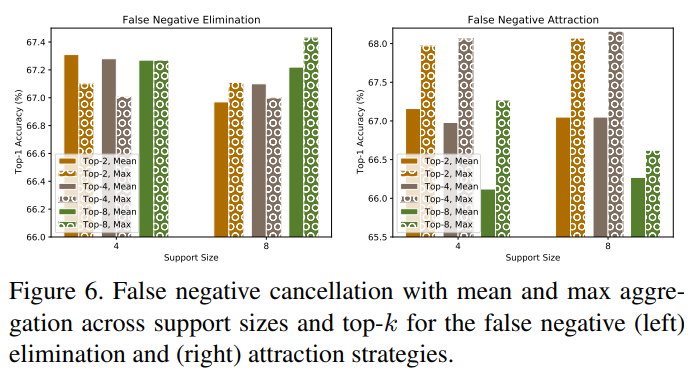
유사한 관점에서 Fig.6의 실험도 해석할 수 있는데, support set을 이용한 유사도 계산 과정에서 mean을 사용하는 경우와 max를 사용하는 경우를 비교한 실험이다. max를 사용하였을 때 attraction 전략의 성능이 비교적 높은데, 그 이유는 max를 사용하였을 때 검출하는 false negative의 정확도가 높아져 attraction에 사용될 positvie pair의 정확도가 높아지기 때문이다. 여기서 attraction stage의 false negative identifying의 정확성의 중요도가 높음을 다시한번 확인할 수 있다.
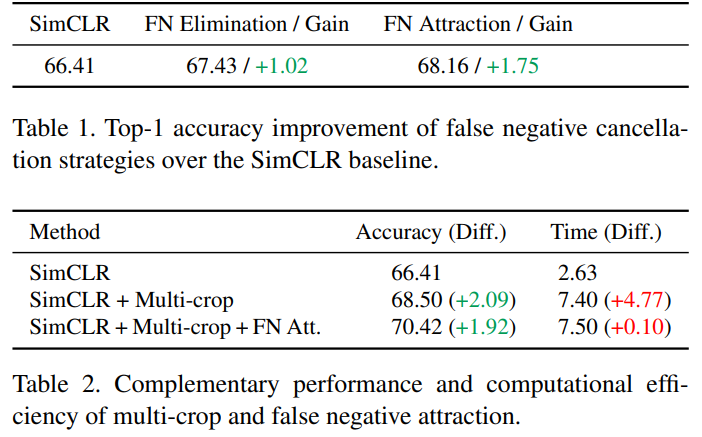
ablation studies를 표로 정리한 결과는 아래와 같다. False Negative Elimination과 False Negative attraction은 Top-1 accuracy에서 SimCLR(baseline)대비 각각 1.02, 1.75의 성능향상을 보였으며, support set 생성에 multi-crop을 이용하였을 때 성능향상은 Table2에서 확인할 수 있다.
2) Comparison with State-of-the-Art
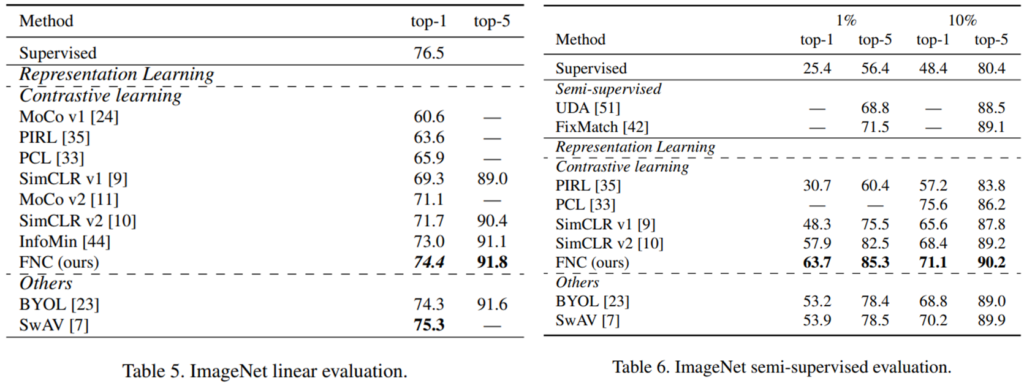
최신 방법론과 비교한 결과는 다음과 같다. 우선 fine-tuning을 따로 거치지 않은 linear evaluation의 결과는 왼쪽, ImageNet 데이터 중 1%, 10%의 labeled data를 사용한 semi-supervised 방법은 오른쪽과 같다.
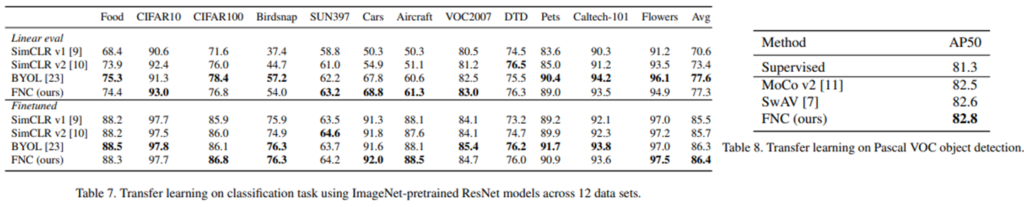
또한 다른 task로 transfer learning 했을 때에 대한 성능도 Table7, 8에 리포팅하였으며 기존 방법론보다 전반적으로 높은 성능을 보였다.
좋은 리뷰 감사합니다.
처음 제가 contrastive learning 논문을 읽었을 때 생긴 “하나의 이미지에서 발생한 두 개의 augmentation 이미지만 Positive면, 배치 내에 같은 강아지 이미지가 2장 있더라도 이건 서로 다른 class로 볼텐데, 성능 저하가 발생되지 않을까?” 라는 의문점에 대해 연구한 논문같습니다.
결국 FN 인지를 알아차리는 것이 본 논문의 핵심인 것 같습니다. 이에 대한 성능이 좋지 않으면 오히려 Negative pairs가 줄어들어 성능 드랍을 가져오지 않을까 라는 생각이 드는 것처럼요, 아마 ablation study에서 본 논문이 주장하는 방법론의 성능 향상을 증명하려는 것 같은데, 이해가 가지 않는 부분이 있어 질문드립니다. 혹시 ablation study 가장 처음에 등장하는 attraction이 정확히 무엇인지, 어떻게 구하는 지를 설명해주실 수 있을까요?