이번에는 DELF라고 부르는 물체 중심 이미지 검색에 관한 논문을 추천받아서 가져왔습니다.
Introduction
이미지 검색이 많은 다른 연구에서 다양하게 활용되는 기본적인 연구인 만큼 되게 중요한 연구입니다. CNN도 발전을 많이 했지만, 대용량 이미지 검색 시스템에서 CNN은 속도 문제로 사용하기 어려운 상태라고 합니다. 그래서 지금 이 논문에서 다루는 것과 같이 local descriptor를 이용하는 방법이 주목 받고 있습니다. 이와 더불어 기존의 데이터셋들이 너무 적은 쿼리 이미지를 가지고 있다는 것도 하나의 문제로 지적되었습니다.
그래서 이 논문의 컨트리뷰션은 2가지로…
- Google-Landmarks라는 이름의 대용량 데이터셋 제안했습니다.
- Attention을 포함한, CNN 기반의 local feature 제안(DELF)했고, 이를 통해 local descriptor와 keypoint를 한번에 뽑을 수 있게 되었다고 합니다.
Google-Landmarks Dataset
기존의 데이터 셋들의 쿼리 이미지의 갯수가 55~550개인 반면에… Google-Landmarks Dataset은 12894개의 랜드마크를 찍은 1060709개의 이미지와 111036개의 쿼리 이미지를 보유하고 있습니다.

또한, 기존의 랜드마크 중심 데이터셋들이 global descriptor가 잘 작동하도록 되어있는 반면에, 새로 만든 데이터셋은 다양한 장면들이 포함되어 있어 사실적입니다. 예시가 좀 많은데 대표적으로 위의 그림을 보시면, 실제 랜드마크도 아니고 안내책자에 그려진 랜드마크가 쿼리로 주어진 것을 볼 수 있습니다.
이것이 가능했던 이유는 역시 구글… 이 아니라, 이미지에는 GPS 정보가 들어있는데 이 정보를 이용해서 랜드마크 반경 25km에서 촬영된 이미지를 수집했기 때문에 이렇게 많은 이미지를 모을 수 있었다고 합니다.
Image Retrieval with DELF
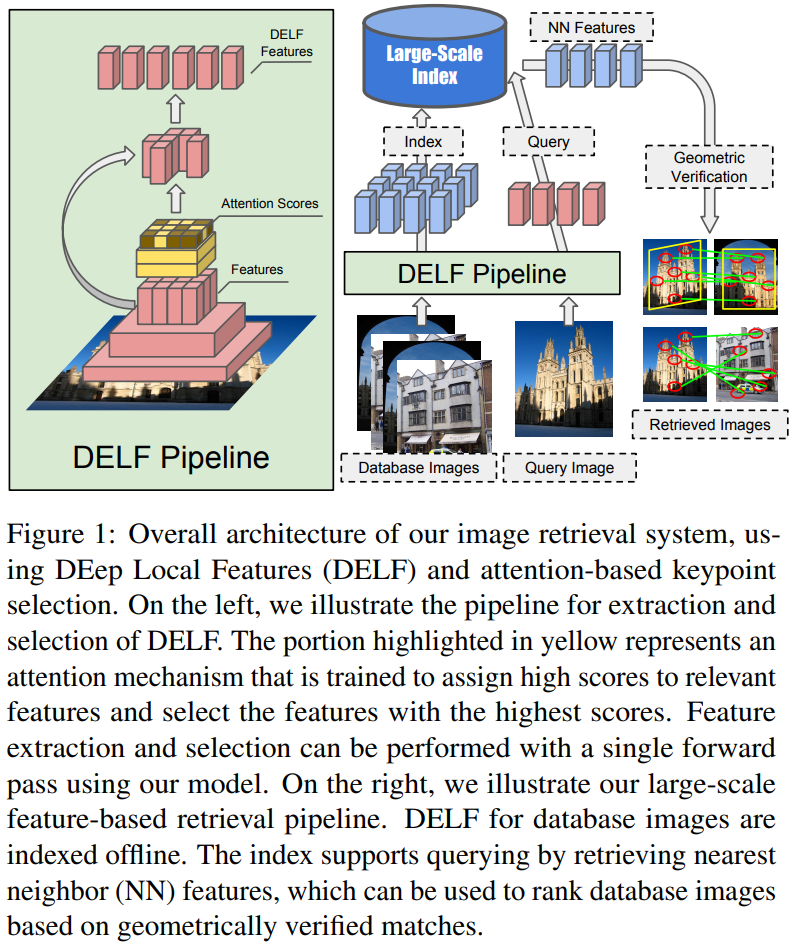
Dense Localized Feature Extraction
Imagenet으로 학습된 ResNet50을 백본으로 사용하고, conv4_x의 출력을 사용한다고 합니다. 거기서 이 논문에서는 학습 과정에서 이미지의 크기 변화에 대응하기 위해 image pyramid를 적용해서, 여러 크기의 이미지의 feature를 뽑는다고 합니다.
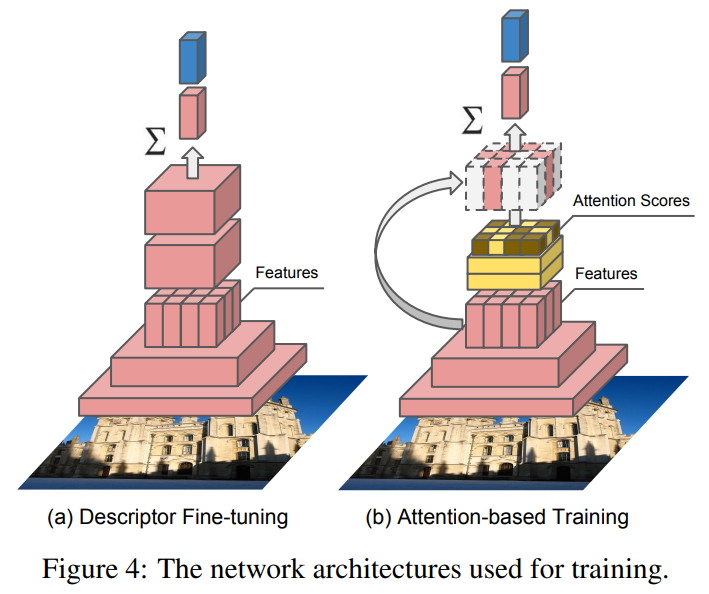
밑에서 나오는 내용이지만, 순서상 여기서 설명을 하겠습니다. DELF에서 학습을 할 때 이미지 레벨의 라벨로 descriptor와 attention model을 동시에 학습하는데, 유기적으로 학습하는데 문제가 있었습니다. 그래서 그림 4에서와 같이 descriptor를 학습하고, 다음으로 위에서 설명한 score function(Attention)을 학습하는 two-step learning 방법을 사용했습니다. 추가적으로 학습 과정에서 random rescaling을 추가적으로 적용해서 scale 변화에 조금 더 잘 대응해서 성능을 끌어올렸다고 합니다.
이 two-step learning에서 descriptor를 학습하는 것은 그림 4의 (a)에 해당하며 이렇게 뽑아진 local descriptor는 랜드마크 검색 문제에 관련된 표현력을 학습하게 됩니다. 학습은 랜드마크 이미지의 라벨만으로 수행됩니다.
Attention-based Keyframe selection
이 논문의 가장 큰 contribution으로 local descriptor와 keypoint를 한번에 뽑는다는 것에 있습니다. 여기서는 위에서 뽑은 dense한 feature를 keyframe을 뽑는데 바로 쓰는게 아니라 attention을 결합해서 사용하는데, 정확성과 효율성 면에서 불필요한 부분을 없애는 것이 중요했다고 합니다.
Learning with Weak Supervision
그림 4의 (b)가 이 학습에 해당합니다. 이 keyframe selection을 학습하기 위해 weighted sum을 바탕으로한 풀링이 쓰입니다.
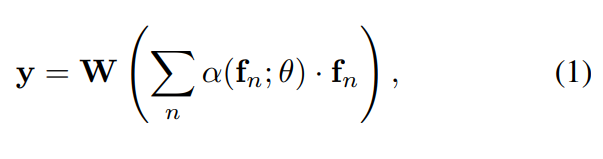
(1)번 수식에서 $f_n$은 d차원의 feature를 의미합니다. α(f_n; θ)은 score function을 뜻합니다. (W ∈ R^M×d) 그래서 위의 수식은 feature vector의 weighted sum이 되고, M 클래스를 예측하는 CNN의 FC 레이어의 weight를 나타내게 됩니다.
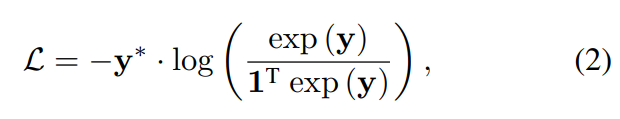
이를 바탕으로 학습에서 (2)번 수식과 같은 cross entropy loss를 통해 학습을 합니다. (y*은 GT) 추가적으로 α(⋅)가 음수가 되지 않도록 강제했다고 합니다.
Characteristics + Dimensionality Reduction + Image Retrieval System
Characteristics
기존의 SIFT와 같은 keypoint selection 방법론들과의 가장 큰 차이는, descriptor의 생성 순서입니다. 기존의 방법론은 keypoint selection 이후에 descriptor를 추출하지만, DELF는 반대입니다. 또한 이미지 검색과 같은 task에서는 object instance를 구별할 수 있는 keypoint를 선택하는 것이 중요합니다. DELF는 이것을 feature extract를 학습하는 과정(그림4-a)과 Attention을 학습하는 과정(그림4-b)를 통해 달성합니다.
Dimensionality Reduction
검색 효율을 위해 L2 정규화를 적용하고, PCA를 돌리고, 다시 L2 정규화를 수행하는 과정을 통해 차원 축소를 수행해주었습니다.
Image Retrieval System
본 논문에서는 PQ와 KD-tree가 결합된 nearest neighbor search 기반의 검색 시스템을 사용한다고 합니다. (KD-tree : 각 노드의 데이터가 공간의 K 차원 포인트인 이진 검색 트리)
Experiments
이미지 검색에서는 전통적으로 mAP를 사용해서 평가를 수행했습니다. 하지만 distractor 쿼리가 있는 데이터셋에 경우에는 이러한 평가 방법이 적절하지 않다고 판단했습니다.
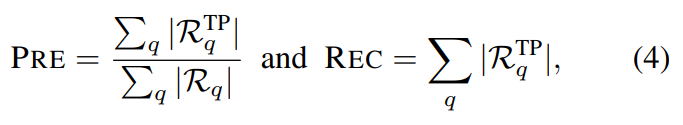
그래서 논문 저자들은 Precision과 Recall을 위와 같이 재정의하여 평가에 사용했습니다. 물론 mAP로의 실험도 수행했고요. 위 평가 메트릭에서 R_q는 전체 검색 결과이고, TP가 붙은 경우에는 Ture Positive를 의미하는데 이 평가 방식으로 제안한다고 합니다.
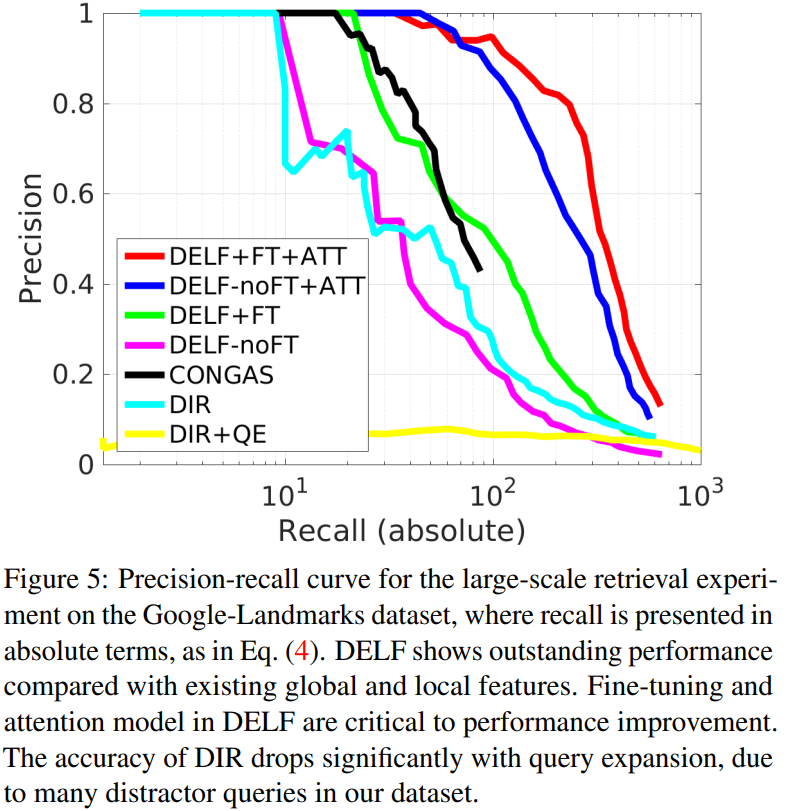
이 새로운 metric을 적용한 PR-curve는 위와 같이 그려집니다. 이 실험을 통해 DELF의 성능에 finetuning과 attention 둘 다 영향을 미치지만, 영향을 크게 미치는 부분은 attention이라는 것을 알 수 있습니다. 추가적으로 위 실험에서 비교한 DELF/CONGAS/DIR 모두 메모리 요구량은 동일한 상태라고 합니다. (동일한 메모리를 먹지만 성능은 저만큼 차이가 난다는 뜻입니다.)
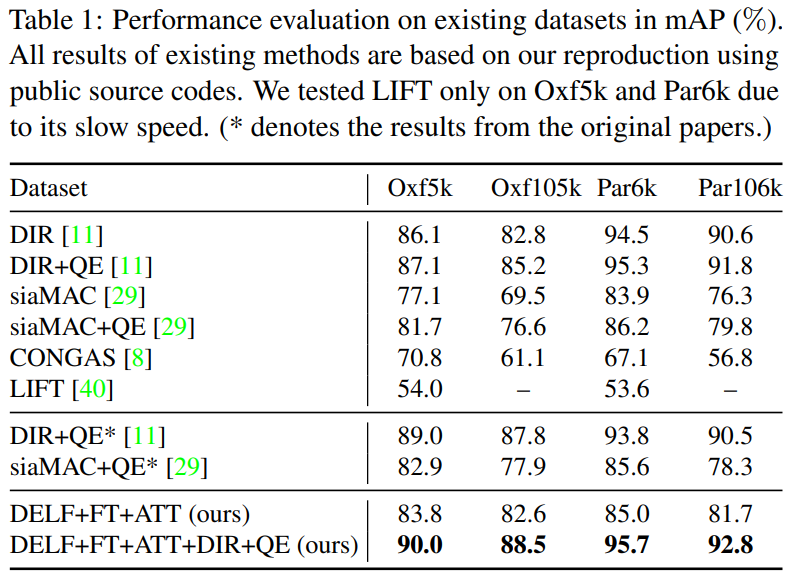
기존 데이터셋에서는 mAP를 이용해서 비교 실험을 수행합니다. 다만, DELF+FT+ATT의 성능이 다른 방법론들에 비해 그렇게 좋지 않습니다. 하지만 DIR과 결합했을 경우에는 성능이 매우 좋았습니다. 논문 저자들은 이 부분이 DELF global feature descriptor는 가지고 있지 않은 정보들을 encoding 할수 있음을 보여준다고 말합니다. DELF 단독으로는 왜 성능이 떨어지는지에 대한 내용이 없어서 좀 아쉽네요.
Conclusion
정성적 결과가 궁금하신 분들은 논문에 가셔서 구경해 보는 것도 좋을 것 같습니다. 사실 keypoint를 그래서 어떻게 뽑는 것인가 읽으면서 좀 궁금했는데… 학습 방법과 어디가 뽑히는지는 알겠는데 어떻게가 조금 어렵긴 하네요. 나중에 코드를 좀 둘러봐야 할 것 같습니다.
좋은 리뷰 감사합니다.
혹시 리뷰해주신 모델에서 이미지로부터 local descriptor, keypoint를 뽑는 과정에 대해 간단히 설명해주실 수 있나요?
SIFT와 다르게 descriptor를 먼저 학습한 후에 keypoint를 정한다는 것이 잘 이해되지 않습니다.
중간에 언급해주신 “dense한 feature를 attention 결합하여 사용” 부분을 제대로 이해하지 못해 혼동이 온 것 같네요.
(댓글에 그림을 넣는 방법을 몰라서, 직접 방문해서 답변드렸습니다.)
리뷰 잘 읽었습니다. local descriptor와 keypoint를 한번에 뽑을 수 있게 됨으로써 얻을 수 있는 장점은 무엇이 있나요? 기존의 방식과 반대되는 순서로 추출을 한다던데, 이로부터 얻게 되는 단점이 없는지도 궁금합니다.
기존의 방법론이 low-level feature에서 작동합니다. 그리고 이미지 검색과 같은 작업에서는 high-level feature에서 작동하고요. 근데 DELF는 high-level feature에서 작동합니다. 이러한 맥락에서 더 유의미한 키포인트를 뽑을 수 있다는 것 같습니다.
좋은 리뷰 감사합니다.
초반부에 ‘기존의 데이터 셋들의 쿼리 이미지의 갯수가 55~550개인 반면에…’ 라는 부분에서 제가 알고있는 쿼리의 뜻과 매칭이 잘 안돼서 질문 드립니다. 사용자가 검색을 위해 db 로 던지는 이미지를 쿼리 로 알고 있는데, 여기서는 다른 의미로 사용되는 것인가요 ??
그리고 제가 이해한 바로는 기존의 CNN 기반의 feature extraction 방식에다가 score를 지정하는 방식을 추가해서 relevant feature에 더 높은 점수를 할당하고 feature를 extraction 하는 방식으로 이해했습니다. 여기서 score를 어떤 식으로 지정하는지 간단하게 설명해 주실 수 있나요??
마지막으로 loss부분에서 ‘ weighted sum을 바탕으로한 풀링’ 이라는 것이 어떤 의미를 가지는 것인가요??
triplet 방식의 loss가 아니라, scoring 방식을 사용했다는것이 참신하게 다가왔습니다.
질문이 너무 길었습니다ㅎㅎ… 감사합니다.
쿼리 이미지에 대한 정의는 석준님이 이해하고 있는게 맞습니다. 다만 이 쿼리 이미지의 갯수도 중요한 것이, 많으면 많을수록 다양한 경우에 대한 평가가 포함되겠죠? 그래서 갯수가 중요하다는 뜻에서 저렇게 표현하였습니다. Score의 같은 경우에는 2레이어 CNN에 softplust activation 붙인 함수로 따로 계산합니다. weighted sum 바탕으로 풀링은 풀링 기법중 하나입니다. 더해서 풀링하는건데, 마지막에 가중치를 곱해준다고 생각하면 될 것 같습니다.