
Text-to-Video Retrieval 을 위한 모델의 성능을 ‘추가적인 학습 없이’ 향상 시켜줄 수 있는 방법이라 읽게 되었습니다. 이전에 리뷰했던 TVR 방법론인 DRL 같은 경우도, 해당 프레임워크에 QB-NORM 을 적용해서 당시 sota 를 달성했었습니다. TVR 뿐만 아니라, 다양한 cross modal retrieval 에 대해 널리 쓰일 수 있기도 합니다. 리뷰 시작하도록 하겠습니다.
Cross modal Retrieval
우선, 논문의 제목에도 나와있는 Cross modal retrieval 이 무엇인지 설명하고 가겠습니다.
Modal : modality 의 약어. 데이터의 ‘양식’을 의미합니다.
- 예시 : text, image, audio, video
Retrieval : query 를 이용하여, dabatase 로부터 query 와 match 되는 samples 를 찾는 것을 의미합니다.
- 이때, 얼마만큼 match 되는 지에 대해 similarity (유사도) 값으로 나타낼 수 있고, 이를 이용하여 database에 있는 samples 에게 rank 를 매길 수 있습니다.
- 본 논문에서는 database 를 gallery 라고 표현하기 때문에, 이하 gallery 라고 쓰겠습니다.
Cross modal retrieval :
- query 와 database 가 서로 다른 모달리티인 경우 retrieval 을 수행하는 것을 의미합니다.
- 예시 : text-to-video, text-to-image, text-to-audio
모달리티가 서로 다를 경우, query 와 gallery 를 나타내는 차원의 형태도 다르고, 만약 같다고 하더라도 모달리티 간의 샘플들이 유사할 수록 가깝게 위치하게 나타내어지지도 않는 상태입니다. 즉, 둘 간의 유사도를 계산하여 학습을 진행할 수 없습니다.
Cross modal retrieval 에서는, 이를 위해 ‘Cross modal embeddings’ 를 널리 사용하고 있습니다. 이는 DNN 을 사용해 서로 다른 modality 의 samples 들을 동일한 vector space 에 위치하도록 만들어주는 방법입니다.
예를 들어 Text-to-video retrieval 을 예시로 들어 봅시다. 아래의 그림은 query modality m_q 인 Text 가 세모이고, gallery modality m_g 인 Video 가 동그라미인 상황입니다.
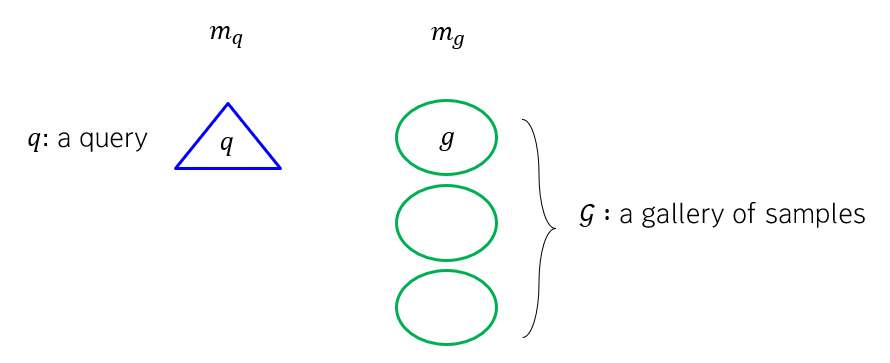
이때, 각각의 모달리티에 대해 학습된 encoder 인, \phi_{q}, \phi_{g} 를 각 샘플에 적용해서, 동일한 차원으로 인코딩합니다. (이때 이 두 개의 pair 인코더는, 서로 유사한 samples 들끼리 가깝게 위치하도록 학습된 인코더이고, 방법론마다 다릅니다.)
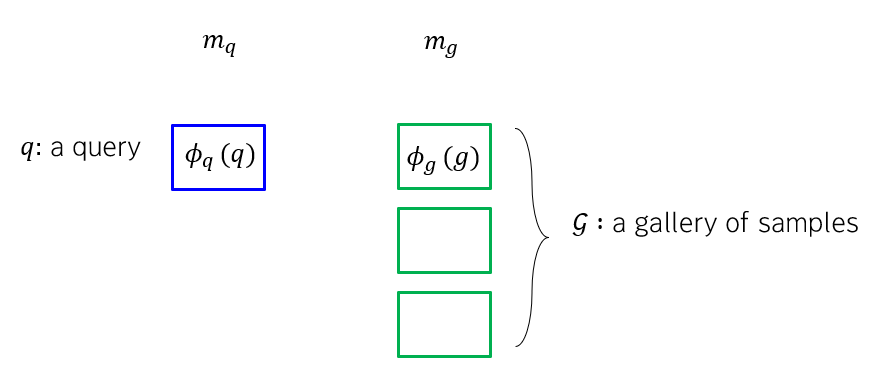
이때 네모는 동일한 vector space 에 나타나게 된 샘플들입니다. 따라서 서로 다른 모달리티의 샘플들 간의 거리를 측정할 수 있기 때문에, cosine similarity 등을 이용하여 similarity (유사도) 값을 계산할 수 있게 됩니다.
Hubness problem
앞서 cross modality embeddings 에 대해 살펴봤는데, 이러한 방법에는 치명적인 단점이 있습니다.
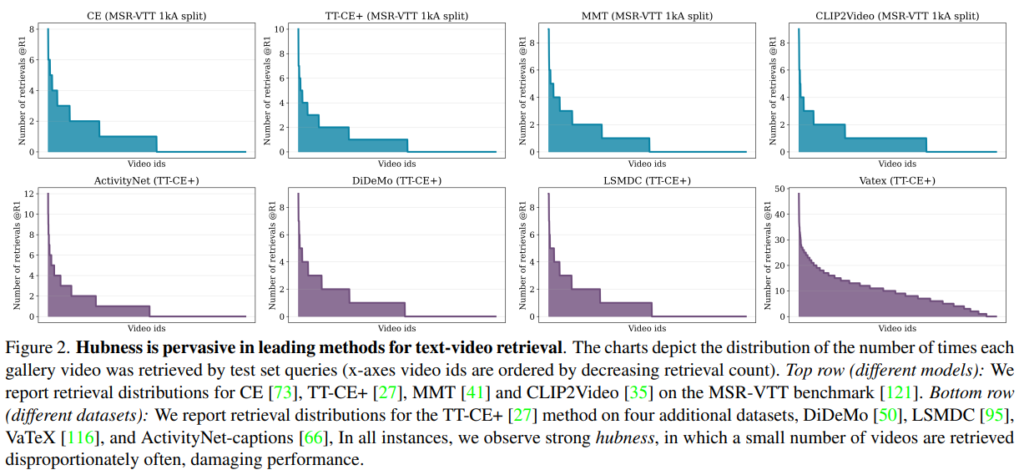
Fig 2는 test set 의 text query 를 이용하여 text-video retrieval 을 했을 때, 각 video 가 몇 번씩 검색되었는지를 나타낸 그래프 입니다. 하나의 query 당 video 한 개를 찾는, R@1 metric 으로 실험을 진행했습니다.
x 축이 video_id 이고 y 축이 검색된 횟수인데, 보시다시피 일부 video_id 는 많이 검색된 반면, 아예 검색되지 않은 video_id 들도 있었다는 것을 알 수 있습니다. (모두 옳게 검색되려면, 모든 video_id 가 1번씩 검색되어야합니다.)
이는 embedding space 에서 gallary samples 들의 일부가, 비정상적으로 많은 queries 의 nearest neighbours 가 되도록 위치 하기 때문입니다. 이 때문에 retrieval 에서 performance 의 하락이 이루어지는 것입니다. 그리고 이러한 samples 들은 “Hub” 라고 표현됩니다. 이 현상은 특정 모델이나, 데이터셋에서만 보이는 게 아니고, cross-modal retrieval 에 만연하게 퍼져있는 문제이기에, 본 논문에서는 이를 완화시키는 것이 목적입니다.
- 이전 연구에 따르면 hubness 는 여러 분야에서 언급되어 왔고, (NLP, biomedical statistics, music retrieval 등등..) high-dimensional embedding spaces 에서 많이 나타나는 경향이 있다고 합니다.
본 논문의 핵심은, Cross-modal retrieval 에서 hubness 를 완화시켜주는 프레임워크인 QB-Norm 을 제안하는 것입니다. 그리고 여러가지 Cross modal retrieval task 중에서, hubness 가 완화되었을 때 더 많은 이득을 볼 것이라 예상되는, 즉, high-dimensional embedding spaces 에 위치할, complex 한 natural language queries 를 이용하는 task 들을 위주로 실험을 진행하였습니다.
Querybank Normalisation
본 논문에서 제안하는 프레임워크인 QB-Norm 은 두 가지 구성요소를 갖습니다.
- Querybank construction 을 통해 만든 querybank 를 사용해서
- Similarity normalisation 을 수행합니다.
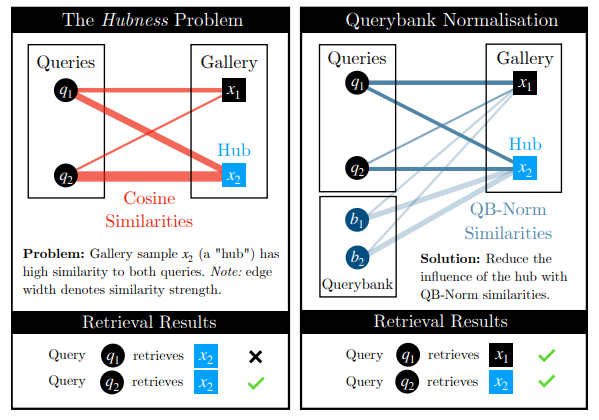
이를 통해 QB-Norm similarity 를 이용해 유사도를 계산하게 되는데, 이 simialarity 는 queries 에 대한 gallaries 의 유사도를 계산할 때, hub 의 영향력을 약하게 만들어주게 됩니다. 즉, hubness 가 완화됩니다.
Querybank construction
- a querybank : B = {b_1, ..., b_N}
- m_q 에 있는 N개의 samples 를 이용하여, querybank 를 생성합니다.
- (이후 이 querybank 를 이용하여, gallary samples 의 hubness 를 측정하게 됩니다)
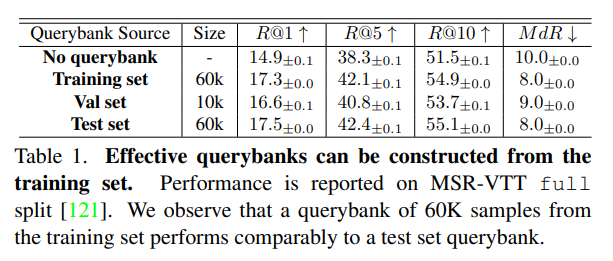
논문에 querybank 를 어떻게 생성하는지에 대한 언급이 없어서 supplementary 를 봤더니, 실험을 통해 training set 으로부터 만든 것이 test set 으로부터 만든 것에 대적할 만하여, training set 으로부터 만들어서 사용했다고 합니다. 이전 방법론 (IS) 에서는 test set 으로부터 생성하였었는데, test set 을 사용하지 않더라도 hubness 를 잘 완화할 수 있다는 게 해당 프레임워크의 장점 중 하나입니다.
Similarity normalisation
hubs 에 대한 similarity 를 normalise 하기 위한 구성요소 입니다.
앞서 생성한 querybank 를 이용하여, gallary 에 있는 모든 샘플들에 대한 유사도를 계산한, probe matrix 를 만듭니다. 그리고 이용하여, similarity normalization 이 수행됩니다.
우선, normalize 를 수행하지 않았을 때의 simialrity 를 먼저 계산해봅시다.
- a query : q
- a gallery : \mathcal{G}
- trained encoders : \phi_q, \phi_g : 특정 방법론에서 학습된 인코더들
- sim() : cross modal embedding space 에서의 similarity 를 계산하는 함수
- j \in \{ 1, ..., |\mathcal{G}| \} : gallary 에 있는 모든 elements 의 index
우선 어떤 query 와, j 번째 gallary samples 간의 유사도는 아래처럼 나타낼 수 있습니다.
- s_q (j) = sim(\phi_q(q), \phi_q(g_j))
Querybank 를 이용해서, normalization 을 하기 위한 함수를 생성합시다.
- a querybank : B = {b_1, ..., b_N} (Querybank construction 에서 생성됨)
- 각 g_i \in \mathcal{G} 에 대해, a probe vector sim( \phi_q(b_i), \phi_q(g_j)) 를 계산한다.
- p_j \in \mathcal{R}^N 가 stacked 되어서, a probe matrix P \in R^{| \mathcal{G} | \times N} 를 형성한다.
이를 통해, P 가 만들어졌습니다. 이를 통해 similarity 를 normalize 해줄 수 있습니다.
- similarity normalisation : \eta = QB-NORM(s_q, P) \in R^{|\mathcal|}
Fig 1. 에서도 잘 표현이 되어있는데, similarity normalisation 이 수행됨으로써, 즉, querybank 를 이용함으로써 gallary 에 있는 hub 들의 영향력이 약화되니까 이를 통해 hubness problem 로 인한 performance 저하가 완화됩니다.
Design choices
앞서 말했지만, NLP 분야에서 hubness 완화를 위한 여러 방법론들이 있었다고 합니다. 그 중 세 가지 테크닉이 있었는데, 이러한 방식들 또한, Querybank Normalisation framework 의 querybank construction 과 similarity normalisation 으로 나타내어질 수 있습니다. 그리고, 본 논문에서는 이보다 더 robust 한 새로운 테크닉을 제안합니다.
- Globally-Corrected (GC) retrieval
- querybank construction : test queries 의 full set 로부터 생성
- similarity normalisation : \eta_q(j) = -(Rank(s_q(j), p_j) - s_q(j)) \in \mathcal{R}
2. Cross Domain Similarity Local Scaling (CSLS)
- querybank construction : 모든 가능한 queries 로 초기 querybank 구축 후, 각 gallery sample 을 normalise 를 할 때 서로 다른 subset 사용
- similarity normalisation : \eta_q(j) = 2s_q(j) - {1 \over K} 1^T \hat{s}_q - {1 \over K} 1^T \hat{p}_j \in \mathcal{R}
3. Inverted Softmax (IS)
- querybank construction : 모든 가능한 queries 로부터 querybank 구축
- similarity normalisation : \eta_q(j) = {{exp(\beta \cdot s_q(j))} \over {1^T exp[\beta \cdot p_j]}} \in \mathcal{R} ( exp[\cdot] : elementwise exponentiation 이고, \beta 는 inver temperature 에 대한 hyperparameter)
NLP 쪽에서 넘어왔다는데, 이러한 접근 방식들이 있었다고 합니다…! 본 논문에서는 이런 방법론들도 다 QB-Norm framework 처럼, querybank construction 과 similarity normalisation 으로 나타낼 수 있다는 것을 보여주었습니다.
그리고 새롭게 제안하는 건, 이러한 기존 방법론들보다 더 robust 한, DIS 입니다.
Dynamic Inverted Softmax (DIS)
- 기존 방법론들은 (방금 언급한 1~3), querybank 가 gallery 를 포함하고 있는 space 를 충분히 cover 하지 못할 경우 오히려 performance 가 하락된다는 문제점이 있었다고 합니다. 즉, similarity normalisation 을 했는데 오히려 더 안 좋아지는 것이지요.
- 그래서 이 문제를 해결하기 위해서, a querybank matrix 에 ‘a gallery activation set’ 이라는 것을 precompute 해주었습니다.
- A = {j : i \in \overset{k}{argmax_l} s(b_i, g_l) , i \in {1, ... , N}}
- 이때, \overset{k}{argmax_l} f(l) 는 k-max select operator 라고 하는데, f(l) 을 최대화하는 l 에 대한 k values 를 return 하는 함수입니다. (k는 hyperparameter, l 은 gallery indices)
- 따라서, A 는, querybank probe 들이, “이것들은 hubs 일 것이다!” 라고 인식하는 gallery vectors 들의 indices 를 포함하는 집합이 될 것이라는 것을 직관적으로 알 수 있습니다.
- 즉, DIS 는, A 에 속하는 nearest neighbour 에 inverted softmax 를 이용해서 activating 을 해주는 함수입니다.
이때 DIS 는 IS 에서 조금 다른 형태입니다. 공식을 보면,
- similarity normalisation (IS) : \eta_q(j) = {{exp(\beta \cdot s_q(j))} \over {1^T exp[\beta \cdot p_j]}} \in \mathcal{R}
- similarity normalisation (DIS) :

따라서, argamx operation 말고는 다 똑같다는 것을 알 수 있습니다.
실험을 통해, DIS 가 다른 방법론보다 robust 하고, query selection 을 좀 안 좋게 하더라도 performance 가 손상되지 않았음을 보여주었습니다. (다른 방법론들은 query selection 을 어떻게 하느냐에 따라, 즉, querybank 가 gallery 를 포함하는 space를 충분히 cover 하지 못하면, performance 가 하락된다는 문제도 있었는데, DIS 는 이를 극복했습니다.)
Experiments
Dataset
hubness problem 해결을 통해 성능 상승이 많을 것으로 예상되는 text 를 query 로 사용하는 task 에 대해 진행합니다.
- text-video retrieval : MSR-VTT, MSVD, DiDeMo, LSMDC, VaTex, QueryYD
- text-image retrieval : MSCoCo
- text-audio retrieval : AudioCaps
- image-to-image retrieval : CUB-200-2011, Stanford Online Products
Evaluation Metrics
Retrieval tasks 에 대해 자주 사용하는 재현률, 중간 순위 값입니다.
- R@K : recall at rank K
- MdR : median rank
Querybank source distribution 에 따른 Normalisation 실험
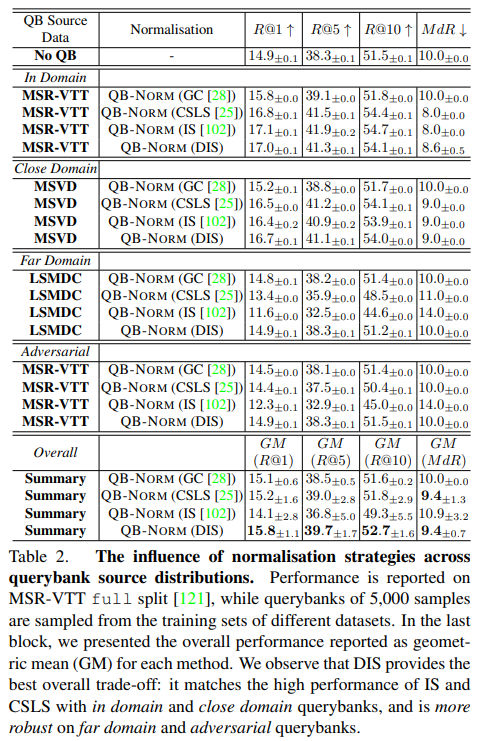
QB source 가 무엇인지에 따라 In Domain, Close Domain, Far Domain, Adversarial Domain, Overall 으로 나눴습니다.
각 domain 에 해당하는 데이터셋으로 querybank 를 생성하고, MSR-VTT test 로 retrieval performance 를 평가했습니다.
- In domain : MSR-VTT 의 training split
- 모든 querybank normalisation 에 대해, 적용했을 때가 적용하지 않았을 때 보다 성능이 좋았습니다.
- Close Domain : MSVD 의 training split
- Far Domain : LSMDC 의 training split
- Close 와 Far 을 통해 normalisation strategy 의 robustness 에 대해 평가하기 위함이었고, 이를 통해 더 close 한 domain 일 수록, 모든 방법에 대해 더 좋은 성능을 낸다는 것을 알 수 있었습니다. 또한 DIS 가 성능이 가장 좋았습니다. 그러나 far domain 이면, GC 와 DIS 를 제외한 모든 방법론에서, normalisation 을 적용하지 않았을 때보다 성능이 저하되는 모습을 보였습니다.
- Adversarial Domain : MSR-VTT 의 training set 중, retrieved 했을 때 적은 수의 비디오를 갖고 오게 되는 queries
- 같은 데이터셋에서 가져왔음에도 불구하고, DIS 를 제외한 모든 normalisation 에서 성능이 하락됨을 알 수 있었습니다.
- Overall Domain : 모든 것에 대한 성능을 평균을 낸 것
- DIS 가 가장 성능이 좋았습니다. 따라서, QB-NORM 의 normalisation 으로 DIS 를 선택하여 사용하였습니다.
QB-NORM 이 hubness 에 미치는 영향에 대한 실험

embedding space 에서의 ‘hubness’ 를 나타내는 척도로, ‘skewness of k-occurences distribution’ 이란 게 있다고 합니다.
즉, 검색되는 횟수에 대한 ‘비대칭도’라는 것인데 (위에서 봤던 그래프를 생각하면 될 것 같습니다), 이를 4개의 데이터셋에 대해 QB-Norm 적용 전, 후에 대해 측정하였더니, Table 3 의 결과처럼 나타났다고 합니다.
따라서, 모든 데이터셋에서 QB-NORM 을 적용하면 ‘hubness’가 줄었다는 것을 알 수 있었습니다.
SOTA 와의 비교
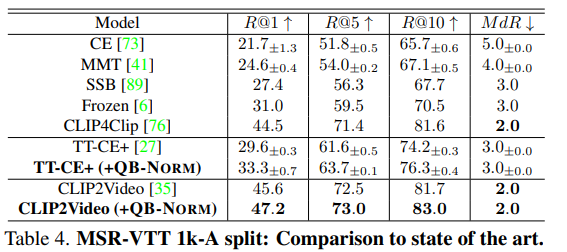
여러 cross-modal retrieval 에 대한 결과들 중, MSR-VTT 에 대한 text-video retrieval 결과를 가져왔습니다.
당시 SOTA 였던 모델들에 QB-NORM 을 적용했을 때, 성능 향상이 있음을 보여줍니다.
Limitation
QB-NORM 에서 사용하는 모든 normalisation 테크닉들은, 추가적인 pre-computation cost 가 들게 됩니다.
DIS 같은 경우, IS 에 비해 argmax 가 추가되면서, 추가적인 계산이 더 필요했었습니다.
또한, Domain 이 adversarial 인 경우, qb-norm 을 적용하게 된다면 오히려 성능이 저하된다는 단점이 있습니다.
Societal impact
cross modal search 는 유용한 면도 있지만, 정치적으로 악용될 수도 있다는 문제가 있다고 합니다.
예를 들어, social media content 를 검색해서, 어떤 문제에 대해 정치적으로 반대를 하는 지를 검색할 수도 있게 됩니다.
Conclusion
Cross modal retrieval 방법론에 대해 성능을 향상시킬 수 있는, Querybank normalisation 에 대한 논문이었습니다.
retrieval 시 일부 데이터만이 많이 검색되는, hubness 문제가 있었는데, 이를 완화시키고자 QB-NORM 을 제안했습니다.
Querybank normalisatoin 은 querybank construction 과 similarity normalisation 으로 이루어져 있습니다.
또한, 이를 이용하여 기존 NLP 방법론들도 동일한 구조로 해석할 수 있음을 보여주었습니다.
또한, 기존 방법들 보다 robust 한 similarity normalisation 기법인 Dynamic Inverted Softmax 을 제안하기도 하였습니다.
여러 retrieval 문제와, 데이터셋, 모델들에 대해 적용했을 시, 성능 향상이 있어 sota 를 달성하는 모습도 보여주었습니다.
결국은 데이터 불균형에 따른 문제로 보이는데, 이런 측면에서 해결하려는 노력은 없나요? 그리고 컨셉을 읽다보면 video id당 한번씩 검색되어야한다고 나오는데, 이건 모두가 공평하게 한번씩 이라는 말이 아니라 최소 한번씩은 검색되어져야한다는 뜻이겠죠? 문제 정의를 읽어보니 정도의 차이지 많이 검색되는 비디오가 당연히 존재할 것 같것 같아서 부가적으로 질문드립니다.
좋은 리뷰 감사합니다. ‘m_q 에 있는 N개의 samples 를 이용하여, querybank 를 생성합니다’라는 query bank 만들기 과정에서 m_q가 어떤 건지 궁금합니다.
m_q 는 modality of query 를 뜻합니다! 제가 말을 조금 어색하게 쓴 것 같기도 해서, ‘m_q 인 N개의 samples’ 라고 이해해주시면 좋을 것 같습니다.
학습할 때 사용하는 데이터셋의 query 들이 전부 m_q 인 samples 이고, 그 중 N 개를 선택하여 querybank 를 생성합니다.