Abstract
NDVR(Near-Duplicate Video Retrieve) 문제는 비디오 콘텐츠 성장으로 많은 관심을 끌고있으며, 이는 중복에 정도가 높은 것이 특징이다. 효율적 NDVR 접근법이 필요하며, CNN의 높은 성능에서 동기부여를 받아 새로운 layer-based feature aggregation을 통해 구한 global video representation 에 있는 CNN의 중간의 feature들을 이용한다. CC WEB VIDEO데이터셋을 이용하여 유명한 심층 구조를 평가하고, 제안된 방식이 SOTA를 달성함을 보였다.
Introduction
비디오 콘텐츠의 증가(성장)로 NDVR 문제가 중요해졌다. NDVR는 여러 의미로 정의가 되지만, 이 논문에서는 다음과 같이 정의가 된다.
near-duplicate videos are considered to be identical or close to exact duplicate of each other, but different in terms of file format, encoding parameters, photometric variations (color, lighting changes), editing operations (caption, logo, and border insertion), different lengths, and other modifications.
즉, 거의 복제에 가까울 정도로 동일하지만 파일 형식, 광도 변화, 편집 작업 등의 측면에서 차이가 있는 것으로 이해하면 된다.
CNN을 이용한 비디오 리트리벌은 있었으나, 중간의 CNN feauter를 NDVR에 이용하는 것은 처음이다. 중간 레이어를 NDVR에 이용하기 위해 max pooling을 각 레이어에 적용하여 layer-level feature descriptor를 추출하였다. 또한 두개의 layer를 합치는 기술을 제안하였다. (laeyr vector를 하나의 vector로 concat → layer-specific codebooks 계산 → 결과 bag-of-words representation 모음)
3개의 deep architecture에 평가를 하였고, 5가지 SOTA를 넘었다.
Related work
NDVR에 관하여….
- Video-level matching 비디오는 feature vector들의 모음, fingerprint나 해시 코드와 같은 global signature로 표현된다.
- Bounded Coordinate System(BCS): PCA의 확장
- Multiple Feature Hashing (MFH): 지도학습 기반. 다중 이미지 feature를 이용하고 비디오 keyframe을 Hamming space로 매핑하는 해시 함수그룹을 학습. video signatures는 keyfraame hash code의 조합으로 생성되며 비디오 데이터셋에서 비디오 representation을 구성한다.
- Frame-level matching 개별 프레임이나 후보 비디오의 장면을 비교함으로써 Near-duplicate videos를 결정한다.
- Douze et al. : SIFT와 CS-LBP로 descriptor를 추출하고 Hamming 임베딩을 위한 visual codebook을 생성한다. post-filtering을 이용하여 retrieval된 항목과 시공간적 제약 조건을 확인한다.
- Shang et al. : 비디오를 표현하고 수정된 inverted file index를 구성하기 위한 compact한 spatio-temporal feature를 도입했다. feature selection과 w-shingling 방식을 이용하여 시공간적 특성을 추출한다.
- Cai et al. : K-means clustering을 적용하여 color correlogram에 histovisual vocabulary를 학습하고, inverted file indexing을 이용해 후보 비디오를 빠르게 검색하여 대규모 데이터에 대한 접근 방식을 제안하였다.
- Hybrid-level matching
- Wu et al. : cluster에 계층적 filter-and-refine 방식을 적용하여 near-duplicate video를 클러스터링하거나 필터링한다. near-duplicate로 명확하기 분류할 수 없으면 비싼 local feature-based NDVR방식을 적용한다.
- Chou et al. : 패턴 기반 인덱싱 트리로 non-duplicated 비디오를 필터링하고, m-pattern-based dynamic programming과 time-shift m-pattern 유사도를 이용하여 후보 비디오에 순위를 매긴다.
Approach
Overview
심층구조의 중간 CNN layer에서 생성된 featuer를 이용하고, 각 비디오에 대한 bag-of-word representation을 얻기 위한 layer-based aggregation 방식을 도입한다. 효율적인 inverted file index를 이용하여 비디오의 bag-of-words representation을 저장하고 추출된 vector에 tf-idf weighted 버전의 cosine similarity를 이용하여 비디오 검색을 수행한다.
1. CNN based featuer extraction
pre-trained CNN 네트워크 C는 L개의 conv레이어(\mathcal{L}^1, \mathcal{L}^2,...,\mathcal{L}^L)를 이용한다. 이미지 I는 C의 forward propagate를 통해 L개의 featuer map들 \mathcal{M}^{l}(l=1,2,...,L)를 만들어낸다.
각 채널마다 1개의 최대값을 출력하고, single vector는 각 채널수의 크기이다. layer vector의 크기를 맞추기 위해 L2-Normalization을 적용한다. compact 하고 시간과 저장공간이 적게 필요하다는 장점이 있으며, AlexNet, VGG, GoogleNet을 이용하였고, VGG와 GoogleNet은 처음의 layer에서 나온 activation을 사용하지 않는다. (모두 ImageNet으로 pre-trained)
2. Feature Aggregation
vector aggregation과 layer aggregation 방식을 이용하여 frame-level의 histogram 생성→ sum →video-level histogram
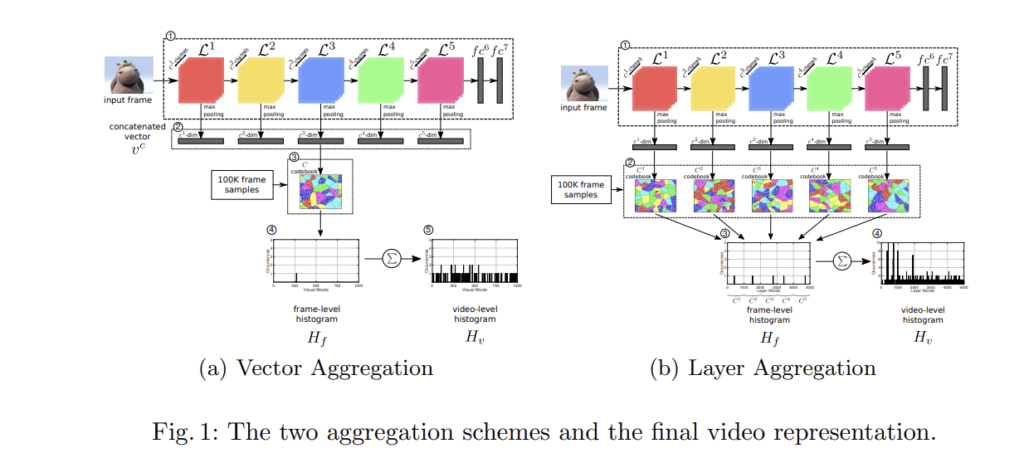
- Vector Aggregation layer feature들 concat→ bag-of-words ⇒ frame당 하나의 word로 할당, 모든 프레임들의 historgram 합쳐서 구함
- Layer Aggregation layer feature들마다 bag-of-words (각 레이어마다 codebook도 만들고 각각의 word 구함) ⇒ histogram concat
3. Video Indexing and Querying
tf-idf 가중치 계산을 이용하여 유사도 측정
w_{td} = { n_{td}·log|D_{b}|\over{n_{t}}}이때 w_{td}는 비디오 d에서 word t의 가중치, n_{td}는 비디오 d에서 t가 나온 횟수, n_{t}는 전체에서의 t가 나온 횟수, |D_b|는 비디오의 수 이다.
이후 cosine similarity로 유사도를 측정하여 랭킹을 정한다.
평가지표
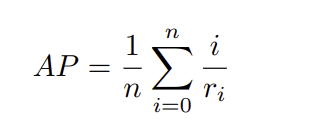
n은 쿼리 비디오와 관련된 비디오 수, r_i는 i번째 관련된 비디오의 랭킹을 의미한다.
Experiments
1. Impact of CNN architecture and vocabulary size
CC WEB VIDEO 데이터셋을 이용하였고, K는 word의 수이다.
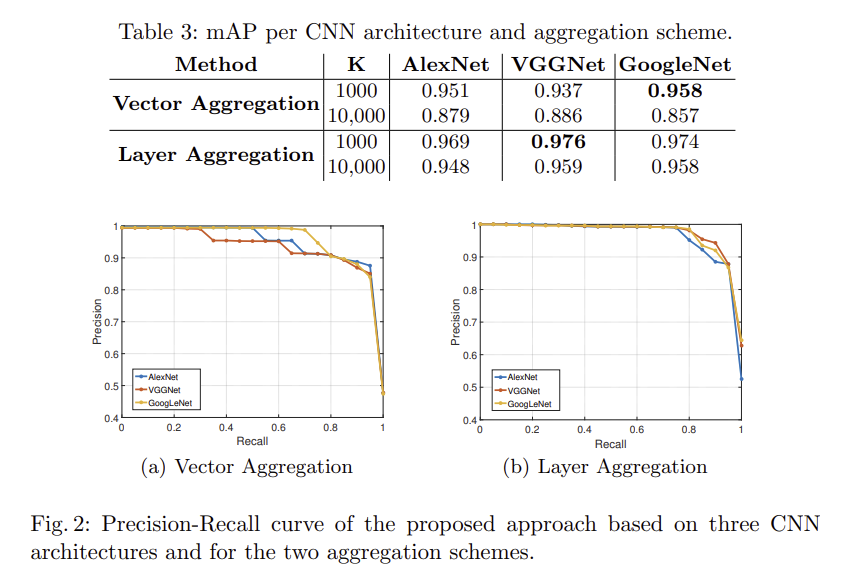
- Layer Aggregation 방식이 전체적으로 더 좋은 성능을 보였다.
- K=1000개를 사용할 경우 K=10000개를 사용할 경우보다 성능이 좋은 것을 확인할 수 있다.
또한 K의 개수가 10000개가 되었을 때 layer aggregation 방식이 성능 하락 정도가 낮은 것을 확인할 수 있고, K의 개수라는 파라미터에 덜 민감한 것을 확인할 수 있다.
** 이때 K의 수를 1000과 10000으로만 실험한 이유가 궁금하다. K=1000일때 좋은 성능일 경우 K가 조금 더 작은 경우(예를 들면 K=500)어떤 결과가 나오는 지 궁금하다.
==>이후 실험에서 K의 수를 vector aggregation과 layer aggregation에서 다르게 설정!
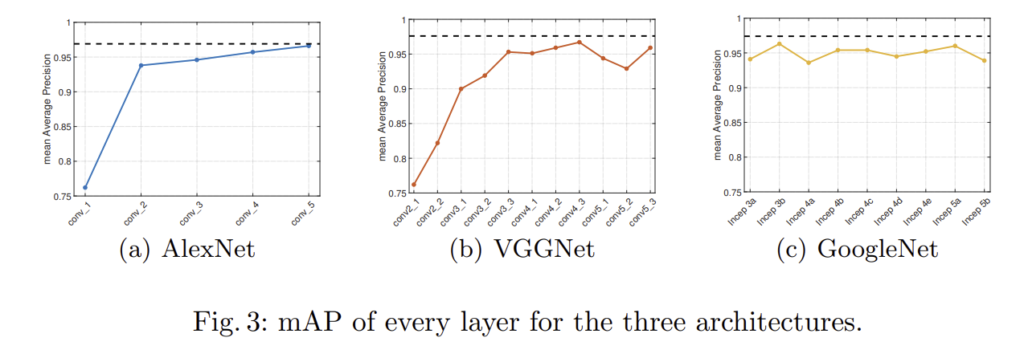
2. Performance using individual layers
각각의 layer vector를 이용했을 때의 성능을 나타낸 것이고 점선은 layer aggregation 성능을 나타낸다. layer aggregation의 성능이 가장 좋은 것을 확인할 수 있고, 각 레이어를 선택하여 이용하는 것 보다 모든 레이어를 합쳐 한번에 이용하는 것이 좋음을 알 수 있다. 또한, 이 실험을 통해 approach에서 1절에 설명한 AlexNet과 VGGNet에서 첫번째 레이어를 사용하지 않은 것으로 이해할 수 있다.
3. Performance per query
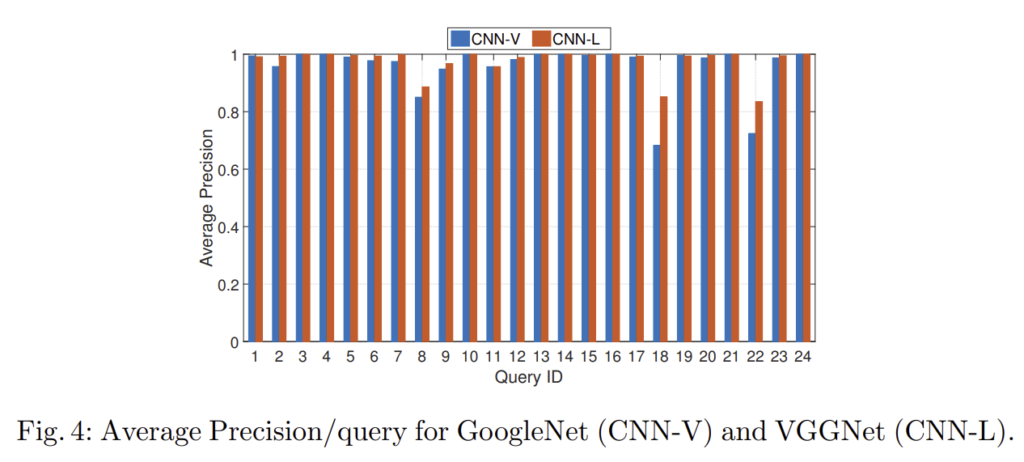
각 방식에서 최대 성능인 GoogleNet(CNN-V)와 VGGNet(CNN-L) (테이블 3의 볼드체 성능을 이용)의 쿼리별 성능을 확인하였다. 두 모델 모두 어려운 쿼리인 18번(Bus uncle)과 22번(Numa Gary)에서 낮은 성능을 보였고, 이에 대한 원인 분석으로 두 쿼리 비디오 모두 해상도/품질이 상대적으로 낮고 후보 비디오의 편집 정도가 심해 어렵다고 보았다.
추가로 전체적인 성능이 Layer aggregation 방식이좋은 것을 다시 한 번 확인할 수 있다.
4. Comparison against existing NDVR approaches

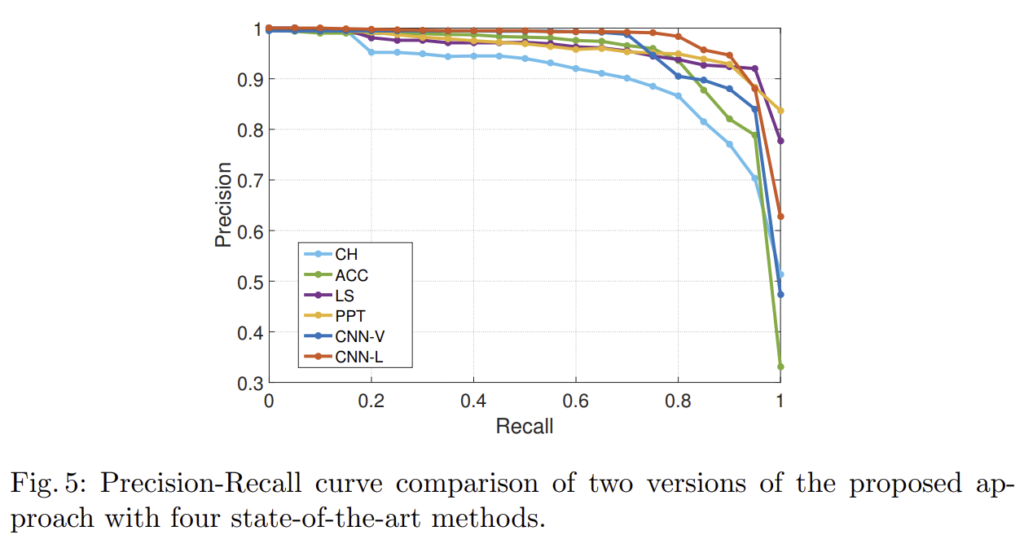
기존의 방법론과의 성능 비교.
bag-of-word 기반의 방법론들은 높은 recall(>90%)에서 낮은 정밀도를 가지고 있다. mAP 측면에서, 해당 논문이 제안한 layer aggregation과 vector aggregation은 모두 표 4에서 확인할 수 있듯이 SOTA와 비교하여 경쟁력이 있다. CNN-L은 최고 점수(mAP=0.976)를 달성한다
Conclusions and Future Work
CNN을 활용하는 Near-Duplicate Video Retrieve에 대한 새로운 비디오 레벨 표현과 CC WEB VIDEO 데이터셋에서 기존에 사용하던 방법론에 비해 상당히 개선된 성능을 보였다. 향후, C3D features를 사용하기 위해 우리의 방법에 필요한 수정을 적용할 계획이다.
** 추후 C3D를 적용한 방법론에 대한 연구를 보려 합니다.