이번에 제가 가져온 논문 주제는 바로 “Image Rectangling”입니다. 해당 분야에 대해서 매우 생소하게 생각하실 분들이 많다고 생각합니다. 저 또한 해당 논문을 읽기 전까지는 이러한 분야가 있는지 조차도 몰랐습니다. 해당 분야를 모르셔도 “Image Stitching” 분야는 다들 한번씩 들어보셨을 겁니다. 즉 Image Rectangling은 Image Stitching에서 한발자국 더 나아간 분야라고 이해하시면 될 것 같은데 자세한 설명은 바로 아래서 시작하겠습니다.
Intro

먼저 Image Stitching은 서로 겹치는 영역과 겹치지 않은 영역이 각각 존재하는 영상 두개에 대하여 겹치는 영역끼리 자연스럽게 이어붙이는 분야입니다. 저희 휴대폰에 있는 파노라마 영상 촬영이 이와 동일하다고 생각하시면 될 것 같습니다.
이미지 스티칭을 직접 해보신 분들이라면 아시다시피 스티칭이 완성된 이미지의 경우 그림1-(b)처럼 결과 영상 자체가 기존의 이미지처럼 직사각형 또는 정사각형을 유지하지 못하고 경계면이 불규칙하게 튀어나오게 됩니다.
뭐 서로 다른 각도에서 촬영된 영상들에 대해 서로 겹치는 영역들끼리 이어붙이려고 연산하다보니 결국 겹치지 않은 영역들에 대해서는 이러한 현상이 발생할 수 밖에 없는 것이어서, 옛날부터 영상 경계면이 튀어나오는 현상들에 대해서는 어쩔 수 없었다? 정도로 생각하고 넘어갔습니다.
만약 사각형의 이미지를 구하고 싶다면 그림1-(b)에 영상을 crop하여 그림1-(c)와 같은 형태로 재가공했습니다. 하지만 이렇게 단순히 crop을 하게 되면 결국 저희가 충분히 확인하고 볼 수 있는 FOV를 제거하는 것과 마찬가지입니다. 이는 Image Stitching의 목적인 “서로 다른 뷰에서 촬영한 영상들을 이어붙여서 FOV를 넓혀보자”와는 결을 달리하는 행위라고 볼 수 있습니다.
그래서 또 다른 해결책으로는 Image Completion이라는 기법을 활용할 수 있다고 하는데, 사실 Image Completion에 대해서는 저도 정확히 알지 못하여서 자세히 설명은 못드리겠습니다. 다만 그림1-(d)를 살펴보시면 결과 영상을 사각형으로 만들기 위하여 실제로는 존재하지 않는 영역을 무언가 새롭게 만든 것을 확인할 수 있습니다.(영상의 좌측 하단 및 우측 상단 부분)
그리고 새롭게 만드는 과정에서 얼핏보면 자연스럽게 표현된 것 같다고 볼 수도 있겠으나, 마치 GAN을 통해 새로운 영상을 생성한 것 같이 현실적으로는 부자연스럽고 왜곡현상이 제법 보이는 것 같습니다. 그래서 이러한 방법 역시도 스티칭 된 결과물의 신뢰성을 중요하게 판단해야하는 자율주행과 같은 분야에서는 Image Completion 기법이 적절치 못하다고 저자는 주장합니다.
그렇다면 영상 속 컨텐츠 자체가 손상되지 않은 체로 사각형의 결과 영상을 얻기 위한 방법으로는 무엇이 있을까요? 여기서 바로 Image Rectangling 분야의 방법론들이 사용됩니다. 즉 Image Rectangling은 이미지를 스티칭하는 것 뿐만 아니라 결과 영상이 실제 이미지처럼 사각형 모양으로 잘 생성되도록 하는 것이죠.
전통적인 Image Rectangling 방법론들은 대부분 mesh deformation을 통해 스티칭된 영상을 사각형으로 만들게 됩니다. 하지만 기존 방법론들은 빌딩이나 창문, 박스 등 직선 모양의 물체들에 대해서만 온전히 그 구조 자체를 유지했으며 비선형 물체들에 대해서는 매우 부자연스러운 이음새가 생성된다고 합니다. 그림1-(e)를 살펴보시면 붉은 색 화살표로 표시된 영역들에 대해서 왜곡 현상이 일어난 것을 확인하실 수 있습니다.
게다가 기존의 Image Rectangling 방법론들은 초기 매시를 찾은 다음에 targe mesh로 최적화하는 방식으로 동작하기 때문에 2stage로 동작한다고 합니다. 이러한 2stage 방식은 병렬적으로 동작하는데 있어 어려움이 있다고 저자는 말합니다.
그러므로 저자는, 사전에 정의한 rigid target mesh에 학습을 통해 예측하는 initial mesh를 잘 결합하는 방식 동작하는 프레임워크를 제안하며 이는 CNN 기반의 one-stage 방식으로 동작하기 때문에 병렬 연산적인 측면에서 매우 효율적이라고 주장합니다. 또한 자신들의 방법론은 linear 뿐만 아니라 non-linear한 구조들에 대해서도 올바르게 스티칭 결과를 유지한다고 합니다.
Traditional Baseline vs Learning Baseline
아무래도 Image Rectangling이라는 분야가 생소하다보니 저자는 친절하게? 기존의 방법론들과 자신들의 방법론들에 대해 차이점을 비교해주고 있습니다.
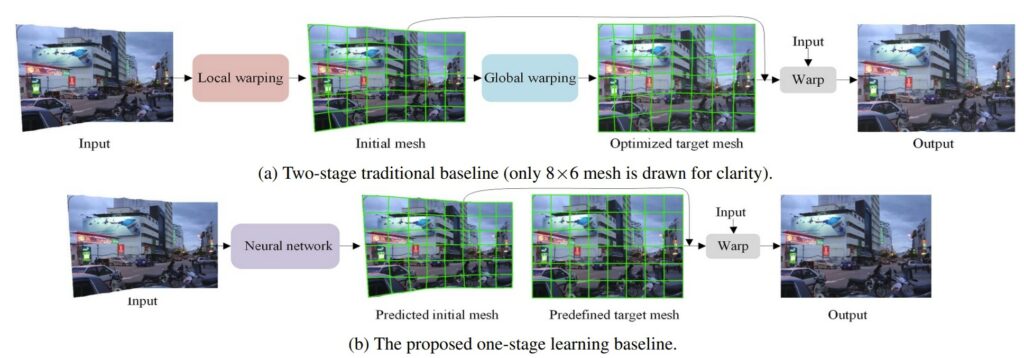
먼저 그림2에서는 전통적인 2-stage 기반의 방법론(a)과 논문에서 제안하는 one-stage learning baseline(b)을 보이고 있습니다. 먼저 traditional baseline의 경우 첫번째 스테이지를 local stage라고 명칭합니다. 해당 부분에서는 사각형의 이미지를 획득하게 위해 seam carving 알고리즘을 활용하여 풍부한 seams?을 스티치된 영상에 삽입한다고 합니다.
해당 알고리즘을 거치게 되면 스티치된 영상에 불규칙한 바운더리를 위한 initial mesh를 구하기 위해 일반적인 mesh가 사각형의 이미지에 놓이게 되며 모든 seam들은 제거된다고 합니다.
이렇게 초기 mesh를 계산하였다면 그 다음엔 global stage 단계를 수행합니다. 해당 단계에서는 최적의 target mesh를 구하기 위해 energy function을 최적화하는 과정을 거친다고 합니다. 이러한 최적화 가정은 straight line과 같은 제한적인 인지 특징들을 보존할 수 있다고 합니다.
최종적으로 initial mesh로부터 target mesh로 스티치된 영상을 warping함으로써 rectangular image를 생성할 수 있다고 합니다. 여기까지가 traditional baseline입니다.
그 다음은 learning baseline에 대해서 살펴보도록 하겠습니다. learning baseline의 경우 오직 신경망을 통해 컨텐츠 기반 초기 mesh를 예측하는 것에 집중합니다. 그리고 target mesh는 그저 사전에 정의해둔 rigid shape을 가지게 됩니다. 이러한 rigid mesh shape은 행렬 연산을 통해서 backward interpolation을 사용할 수 있다고 합니다.
아무튼 rectangular image는 traditional baseline과 동일하게 예측한 inital mesh를 사전 정의한 target mesh로 스티치된 영상을 warping함으로써 구할 수 있게 됩니다.
Network Structure
그러면 전체적인 과정에 대해서 조금 더 자세하게 알아보도록 하겠습니다.
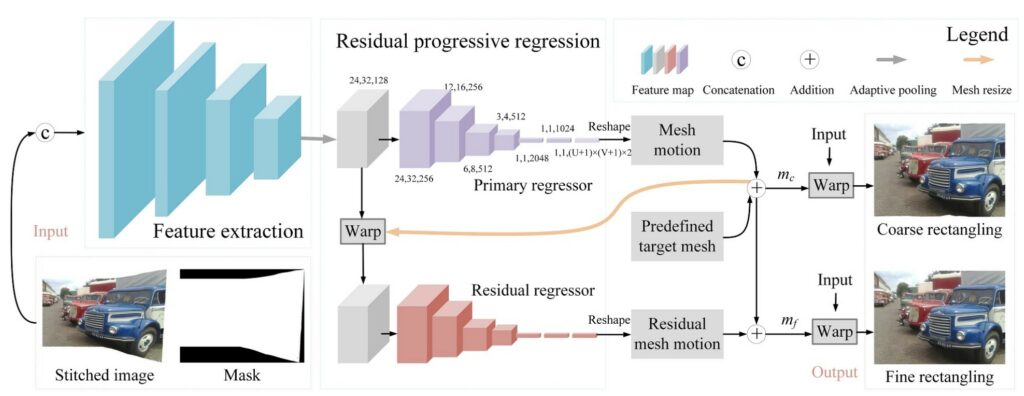
그림3은 Image rectangling의 전체적인 과정에 대해서 보여주고 있습니다. 먼저 네트워크는 크게 Feature extraction과 Mesh regressor로 나뉘게 됩니다. Feature extraction은 그냥 컨볼루션 레이어와 max pooling이 겹쳐서 나오는 매우 흔한 CNN구조라고 이해하시면 될 것 같습니다.
참고로 Feature extraction의 입력으로 들어가는 입력이 stitched image 외에도 Mask가 함께 concat되어 4채널 입력으로 들어가게 됩니다. 해당 마스크는 stitched image에서 픽셀 값이 있는 영역은 1 없는 영역은 0 으로의 이진 분류 형식으로 마스크를 생성할 수 있을 듯 합니다.
아무튼 이렇게 4채널 입력을 통해 24x32x128 짜리 feature map을 구했다면 그 다음에는 Primary regressor라는 것을 통과합니다. 제가 여기서 신기하게 생각했던 점은 decoder를 통하여 mesh regressor가 입력 해상도와 동일한 해상도의 mesh map을 생성하는 것이 아닌 입력 해상도와 동일한 크기의 vector를 생성한다는 점입니다.
그렇게 할 수 있었던 이유는 predefined target mesh가 입력 해상도와 동일한 해상도의 mesh이기 때문에 해당 mesh에 regressor를 타고 나온 mesh 값을 더해줌으로써 새로운 mesh 맵을 생성할 수 있게된다는 점이죠.
물론 이게 끝은 아닙니다. 지금까지 구한 과정은 primary regressor에서 coarse 레벨에서의 mesh map을 생성한 것이며, 저자는 첫번째로 구한 mesh를 다시 feature extractor에서 추출한 24x32x128짜리 feature map에다가 적용시키게 됩니다.
그냥 Coarse rectangling된 결과물을 다시 mask 구해서 feature extraction에 태워도 되겠지만, 그렇게 하게 될 경우에는 너무 많은 모델 연산량이 들어가기 때문에 중간 단계의 feature map을 다시 재활용하는 방식을 채택한 것입니다.
아무튼 mesh map으로 와핑된 feature map을 Residual regressor(붉은색 네트워크)의 입력으로 넣게 됩니다. 이때 Residual regressor는 Primary regressor와 동일한 구조를 가지고 있으며 단지 weight는 공유하지 않는 별개의 모델로 이해하시면 될 것 같습니다.
아무튼 이를 통해 구하게 된 mesh를 residual mesh motion이라고 지칭하며, 이는 초기에 구했던 primary regressor에다가 다시 더해주어 마치 gradient boosting 기법처럼 에러의 잔차를 계산한다고 보시면 될 것 같습니다.
Objective Function
다음은 모델 학습에 사용된 loss term입니다.
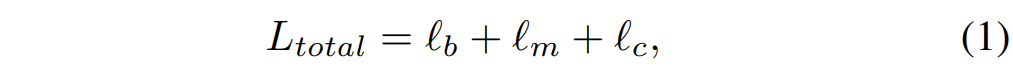
모델을 학습시키는데 사용한 loss는 크게 3종류로 왼쪽부터 차례대로 boundary term, mesh term, 그리고 content term에 해당합니다.
Content term
Content term 안에는 또 크게 Appearance loss와 Perception loss로 나뉘어집니다. 먼저 Appearance loss는 다음과 같습니다.
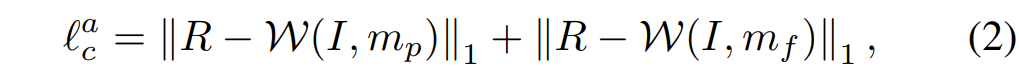
여기서 W는 warping operation을 의미하며 I는 입력 이미지, m_{p}, m_{f} 는 각각 primary regressor와 residual regressor를 타고 나온 mesh 결과입니다. 즉 warping한 결과와 R을 비교함으로써 학습이 된다고 이해하시면 될 것 같은데, 여기서 R이 rectangling label이라고 되어있네요. 즉 supervised 형식으로 모델이 학습되는 것 같은데, 이 supervised label은 어떻게 구했는지에 대해서는 논문의 또 하나의 기여도로 나타나있습니다.
그 다음은 Perception loss입니다. Perception loss는 딱 이름만 들어도 아시다시피, 픽셀 레벨에서의 비교가 아닌, feature level에서의 비교입니다. Image Translation이나 Image Generation에서 많이들 사용하는 loss 중 하나이죠.
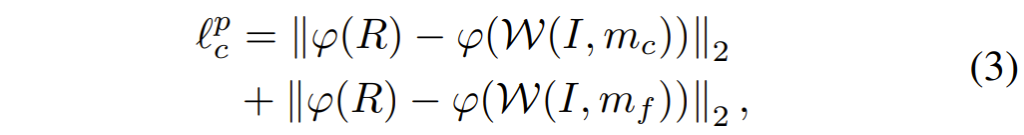
여기서 저 꼬불한? 파라미터는 feature extractor를 타고 나왔다는 표식이며 논문에서는 VGG19 네트워크의 conv4_2를 사용했다고 합니다.
Mesh Term
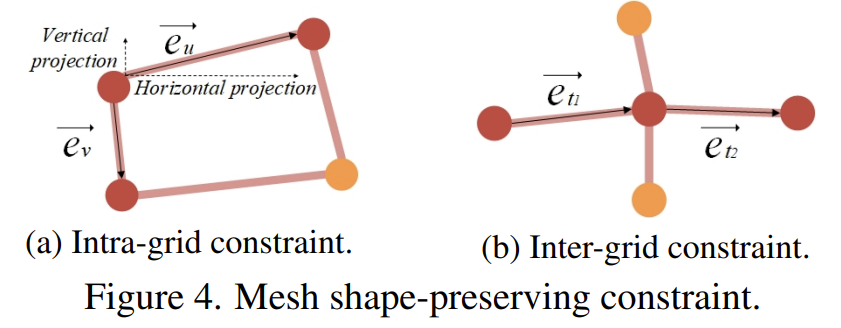
rectangular image를 생성할 때 컨텐츠 왜곡이 발생하는 것을 막기 위해서는, 예측된 mesh가 입력 영상을 너무 과장되게 변형시키면 안됩니다. 그래서 저자는 intra-grid constraint와 inter-grid constraint를 제안하여 deformed mesh의 모형을 유지시켰다고 합니다.
먼저 Intra-grid constraint에 대해서 알아보겠습니다. 어떠한 그리드 안에서 저자는 그리드 엣지의 방향과 크기에 대하여 어떠한 제약조건을 설정하였습니다. 그림4-(a)에서 볼 수 있듯이, 저자는 수평 엣지의 projection 방향이 우측을 향하도록 하면서 동시에 해당 벡터의 norm 값이 일정 threshold보다 더 크도록 하였습니다.
즉 수평면에 대한 패널티는 다음과 같이 표기할 수 있습니다.
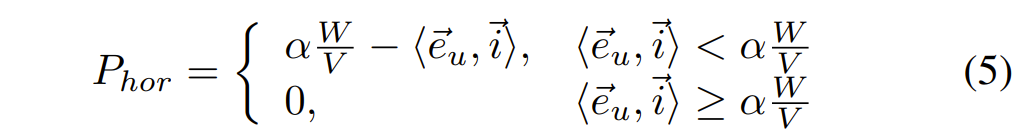
그리고 또한 vertical edge에 대해서도 동일하게 패널티를 주게 됩니다.
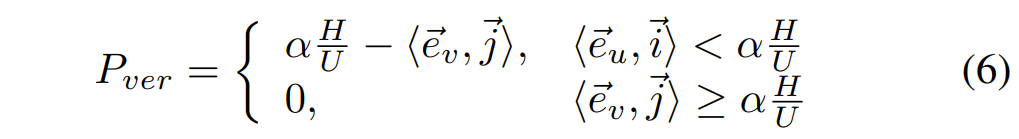
최종적으로 수식5,6을 종합하면 다음과 같은 intra-grid loss를 계산할 수 있습니다.
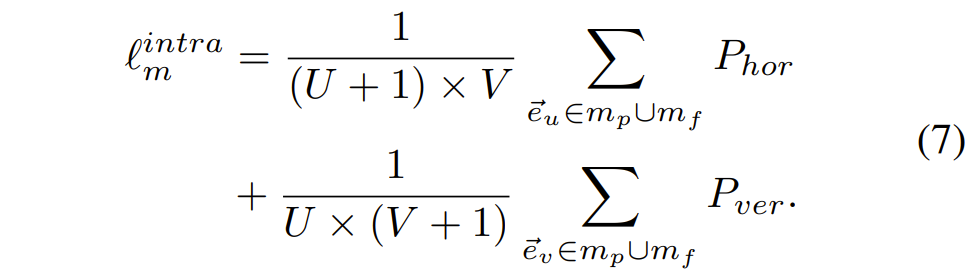
이번에는 Inter-grid constraint에 대해서 알아보도록 하겠습니다. 해당 제약 조건은 주변 이웃 그리드가 일정하게 변환되도록 만드는 loss 입니다. 그림4-(b)를 살펴보시면 두 개의 deformed grid edge는 co-linear 되도록 학습이 진행됩니다.
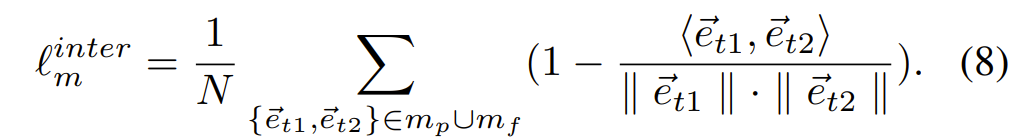
위의 수식에서 N은 mesh 속 2개의 연속적인 에지의 튜플 개수를 의미합니다.
Boundary Term
마지막으로 Boundary Term에 대해서 알아보도록 하겠습니다. 해당 loss는 예측된 mesh 대신에 mask에 대해 loss를 계산하는 것인데, stitched image의 이진 마스크에 대하여 저자는 마스크를 warp 시킨다음에 warping된 마스크가 one matrix 와 유사하도록 하는 loss를 추가하였습니다. 즉 image rectangular의 결과물에서는 해상도 영역에 대하여 모두 온전한 값이 있어야만 하기에 mask 역시도 값이 가득 차야만 하는 것이죠.
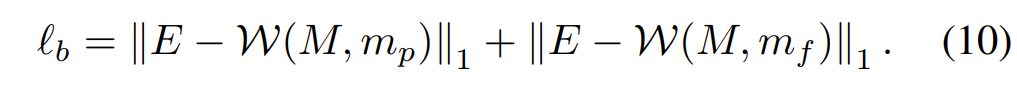
Experiments
마지막으로 실험 섹션에 대해서 다룬 후 리뷰 마치도록 하겠습니다.
실험에 사용한 데이터 셋은 DIR-D 데이터 셋으로, 이는 논문에서 제안하는 image rectangular 전용 데이터 셋입니다. 리뷰가 너무 길어지는 것 같아서 데이터 셋 구축 방법에 대해서는 다루지 않았기에 관심 있으신 분들은 논문을 직접 참고해주시면 감사하겠습니다.
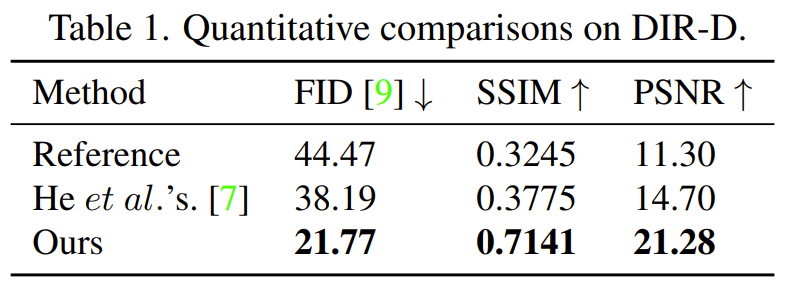
supervised 형식으로 모델을 학습했기 때문에 평가 메트릭도 SSIM과 PSNR 등 target image와의 비교 방식으로 평가하였습니다. 그 결과 제안하는 방법론이 SSIM 기준 너무 압도적인 수치로 좋은 모습을 보여주게 되었습니다. 아무래도 해당 분야의 연구가 너무 부족하기도 하고 제가 보았을 때 논문에서 제안하는 방법론이 처음으로 딥러닝 기반의 방법론인 것 같아서 전통적인 기법의 He 방법론과 비교하여 성능 차이가 큰 것 같습니다.


다음은 정성적 결과입니다. (a) 같은 경우에는 비교적 linear structure가 주를 이루는 영상들에 대해서 기존의 전통적인 기법과 자신들의 방법론을 비교하였으며 (b)는 사람의 얼굴과 같이 비선형적인 물체들이 메인을 이루는 영상에서의 결과를 나타낸 것입니다.
앞서 언급했다시피 전통적인 기법의 경우 선형적인 물체들에 대해서는 그나마 구조를 잘 보존하기에 비교적 자연스러운 결과를 볼 수 있겠으나 비선형적인 물체에 대해서는 매우 왜곡 현상이 심한 것을 정성적으로 확인할 수 있습니다.
반면 제안하는 방법론의 경우 매우 깔끔하다고 볼 수 있네요. 근데 정서적 결과를 보니 실제 Label과 놓고 보았을 때 그냥 Label 그 자체인 것 처럼 매우 똑같이 학습이 된 것 같은데 신기하네요.
결론
원래는 Image Stitching 방법론인 줄 알고 해당 논문을 읽어보려 했던 것인데, 알고보니 stitching된 영상을 어떻게 잘 네모네모 하게 만들지에 대한 방법론이었더군요. 그래도 이런 분야가 있구나 + mesh에 대한 개념?에 대해서 조금은 알아가게 된 것 같습니다.
게다가 mesh라는 것을 저도 한번 써보고 싶은데 하필 공개된 코드가 텐서플로우라서 파악하기가 어렵네요ㅎㅎ..