오늘 리뷰 논문은 김지원 연구원이 슬랙-테크에 소개해준 논문이기도 하며, 다양한 환경(day/night, overcast, smoggy, strong light etc.)에서 촬영된 멀티스펙트럴 데이터 셋과 detection을 위한 visible-infrared fusion model을 제안한 방법론입니다.
Intro

멀티스펙트럴 영상쌍을 이용하는 해당 방법론의 최종적인 목적은 2가지 입니다. 하나는 visible image와 infrared image를 영상 레벨에서 융합한 영상을 출력하는 것과 해당 영상을 이용한 물체 검출을 수행하는 것 입니다.
앞선 설명으로부터 몇몇 분들은 저희 연구실에서 진행하고 있는 멀티스펙트럴 보행자 검출과는 다른 부분이 있다는 것을 눈치 채실 겁니다. feature 수준에서 융합을 진행하여 검출을 수행하는 저희 연구실의 문제 해결 방법과는 다르게 해당 논문에서는 infrared and visible image fusion (IVIF)라는 멀티스펙트럴 퓨전 영상(fig 6 참고)을 생성하여 물체 검출을 수행하는 것을 목적으로 합니다.
IVIF는 서로 다른 장점을 가진 멀티스펙트럴 영상 쌍을 효율적으로 융합하기 위해서 각 도메인의 장단점을 적절하게 융합해야한다고 주장합니다. 컬러 영상은 조도가 적절한 상황에서는 풍부한 공간적 해상도 정보와 컨텐츠 정보를 가지고 있다는 장점이 있으나, 적당한 조도가 없으면 정보량이 급격하게 줄어든다는 문제가 있습니다. 반면에 열화상 영상은 조도 변화에 덜 영향을 받으며, 타겟 물체가 방출하는 열정보를 토대로 타겟의 구조, 형태를 강조해서 얻을 수 있다는 장점이 있으나, 컬러 영상 대비 컨텐츠 정보가 부족하다는 단점이 있습니다. 그렇기에 IVIF는 컬러 영상의 백그라운드와 열화상 영상 속 타겟들을 융합한 Fig 6과 같은 IVIF 영상들을 생성함으로써, 두 모달리티의 장점들을 결합하고자합니다. 영상 수준에서 결합하여 영상 분할, 물체 검출 등 다양한 컴퓨터 비전 분야의 알고리즘을 적용할 수 있으며, 사람의 직접적인 인식에도 도움이 된다는 장점을 가질 수 있게 됩니다.
저자는 컬러 영상의 백그라운드와 열화상 영상의 타겟 형태가 고려된 융합 영상을 만들기위해 하나의 생성 모델과 두개의 적대 모델을 가진 융합 모델을 제안합니다. 또한 다양한 벤치마크에서 다른 모델 대비 융합 모델의 우수성을 증명합니다.
++ 물론 영상을 융합하는 또다른 네트워크가 필요함으로써, 실시간성이 떨어진다는 문제가 발생합니다. feature 기반의 융합과 영상 레벨의 융합 둘 중 누가 더 좋은지에 대해서는 보다 깊은 고민이 필요할 것 같습니다.

하지만 기존의 IVIF 알고리즘들은 대부분 영상을 잘 생성하는 것에만 집중 하였습니다. 즉, 실질적으로 이용할 분야를 고려하지 않고 생성하기에 태스크에 대비 비효율적인 영상이 생성될 수 있다는 문제가 있었습니다. 이러한 문제를 극복하기 위해서 저자는 융합 모델과 검출 모델 간 협력 학습 방법을 사용하길 제안합니다. 또한 앞서 여러 벤치마크에서 SOTA를 달성함으로써, 효과를 입증합니다.
마지막으로 저자는 IVIF의 필요성을 보이고 융합 모델의 실질적인 효과를 입증하고 학습하기 위해서 다양한 환경과 특성이 고려된 데이터가 필요하다고 주장합니다. 하지만 기존의 존재하는 데이터 셋들은 제한된 환경에서 촬영된 데이터 셋만 존재하기 때문에 두 모달리티의 상호보완적인 특성을 학습하고, 모델의 효율성을 입증하기 어렵다는 문제가 있었습니다. 그렇기에 저자는 다양한 환경과 특성을 고려한 데이터 셋 Multi-scenario Multi-Modality(M3FD Dataset)을 제안합니다.
저자는 제안한 데이터 셋 외에도 추가적으로 4개의 멀티스펙트럴 벤치마크를 사용하여 알고리즘의 효과를 입증하고자 하였으며, 융합 모델과 검출 모델 모두 SOTA를 달성하였습니다.
Method
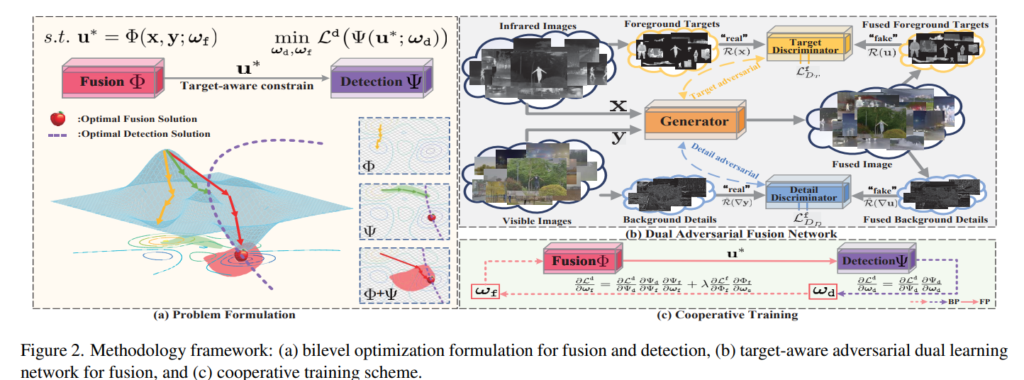
저자가 제안하는 방법론은 앞서 이야기한 바와 같이 두 모달리티를 융합하는 것 뿐만이 아니라 물체 검출을 잘 할 수 있도록 하고자 합니다. 이러한 측면의 IVIF를 detection-oriented fusion라고 칭한다고 합니다. 기존 방법론(the truism Stackelberg’s theory를 따르는)에서는 융합 모델과 검출 모델을 모두 최적화하기 위한 이중 수준 최적화 모델(a bilevel optimization model)을 정의하면 다음과 같다고 합니다.
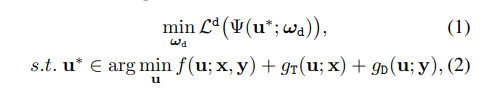
ω_d는 detection model Ψ의 학습 가능한 파라미터에 해당합니다. f는 두 모다리티 영상 X, Y을 기반으로 융합 영상 u를 생성하기 위한 모델이며, g_T와 g_D는 각 모달리티에 따른 제약 입니다. 수식 2에서 볼 수 있듯이 기존 전통적인 융합 기법들은 단순한 등호/부등식 제약이 아닌 구조임으로 두 모델을 한번에 최적화하기가 쉽지 않습니다. 저자는 기존 전통적인 융합 기법을 학습 가능한 모델로 변경함으로써, 이러한 문제를 해결할 수 있다고 합니다. 이를 정의하면 아래와 같습니다.
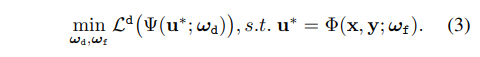
기존 모델 f를 학습 가능한 파라미터 ω_f를 가진 융합 모델 Φ로 변경함으로써, 두 모델의 파라미터를 상호 최적화가 가능한 모델링이 가능해진다고 합니다.
TarDAL
Target-aware dual adversarial learning network(TarDAL)은 하나의 생성 모델과 두개의 타겟 측면의 적대 모델로 구성됩니다. fig 2의 오른쪽 상단의 그림이 전체 파이프라인을 도식화한 그림으로 보이는 것과 같이 생성 모델 G는 멀티스펙트럴 페어 쌍을 입력으로 받아 IVIF 영상을 생성합니다. 생성된 영상을 토대로 두 개의 적대 모델은 두 모달리티 별로 구성됩니다.
두 적대 모델은 조도 변화에 강인하게 타겟의 구조를 잘 표현하는 열화상 영상의 타겟 위주(sailency model R() = X*mask m)로 보는 Target Discriminator D_T와 풍부한 컨텐츠 정보를 가진 컬러 영상의 백그라운드(^R() = x*(1-m)의 gradient~e.g. sobel)를 위주로 보는 Detail Discriminator D_D로 구성됩니다.
두 적대 모델은 두 모달리티의 특성을 고려하여 제약을 가함으로써, 생성 모델이 적절한 융합 영상을 생성하도록 유도합니다.
Generator. 생성 모델은 앞서 설명한 바와 같이 멀티스펙트럴 영상 쌍을 입력으로 하여 영상을 생성합니다. 생성 영상과 두 모달리티 간의 구조적 유사성을 학습하기 위해 SSIM loss를 이용합니다. 이에 대한 수식은 아래와 같습니다.
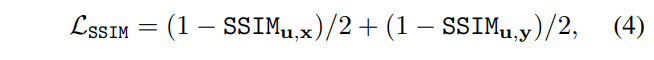
구조적 유사성 뿐만이 아니라 원본 영상간의 pixel intensity distribution의 밸런스를 유지하며 학습 하기 위해서 the saliency degree weight (SDW)를 이용합니다. SDW의 기본 수식은 아래와 같습니다.
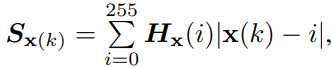
H()는 영상 X의 히스토그램에 해당합니다. k는 픽셀의 인덱스 정보에 해당합니다.
++ 해당 수식에 대해 풀이하자면 해당 인덱스의 픽셀 값의 강도를 표현한다고 생각하시면 될 것 같습니다.
최종적으로 SDW는 아래 수식과 같이 Pixel loss에 사용되어집니다. 해당 loss를 통해 두 모달리티와 융합 영상 u간의 pixel intensity distribution를 가지도록 합니다.
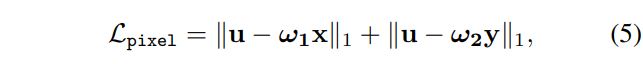
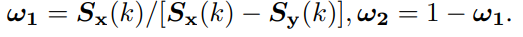
Target and detail discriminator. 두 적대 모델은 두 모달리티의 특성을 고려하여 전경에 해당하는 타겟과 전경외의 백그라운드의 디테일을 잘 생성하도록하기 위한 모듈로 설계됩니다. 전경에 해당하는 타겟과 타겟 외의 정보인 백그라운드를 구분하기 위해서 저자는 사전학습된 saliency detection network를 이용하여 saliency map인 mask m을 생성합니다. m은 열화상 영상을 근간으로 생성되어집니다. 이를 통해 원본 영상으로부터 전경과 배경을 구분할 수 있게 됩니다. 따라서 adversarial loss L_adv^f는 다음과 같이 정의됩니다.
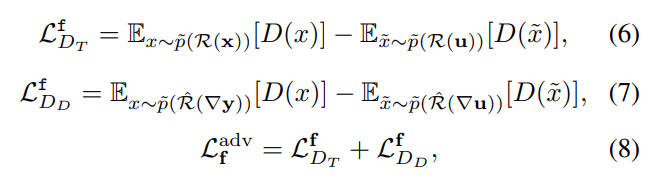
여기서 R = X o m에 해당하며, 원본 영상으로부터 전경만 검출한다고 보시면됩니다. ^R = 1- R은 R과 반대로 배경을 검출하는 연산으로 보시면 됩니다. 또한 수식 7에서의 그래디언트는 e.g. SOBEL로 보시면 됩니다. 즉, 백그라운드의 디테일 정보를 edge 검출기를 통해 윤관 정보에 집중함으로써, 컨텐츠 정보 복원 능력에 집중한다고 보시면 됩니다.
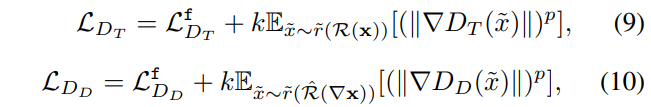
최종적으로 두 적대 모델은 위의 수식 9, 10을 통해 학습되어 집니다.
++ 수식 9, 10은 WGAN에서 사용되는 loss로 궁금하신 분들은 wGAN 논문을 참고하시면 될 것 같습니다. 저자는 k=2, p=6을 사용했다고 합니다.
최종적으로 TarDAL의 loss는 다음과 같이 정의되어집니다.
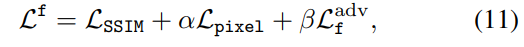
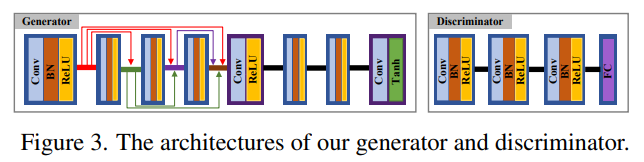
++ 생성 모델의 구조와 두 적대 모델의 구조가 궁금하신 분들은 아래의 그림을 참조해주시길 바랍니다. 두 적대 모델은 동일한 모델을 사용하였습니다.
Cooperative training strategy
해당 전략은 검출 모델과 융합 모델간 서로 상호적인 학습 전략을 이용합니다. 이를 통해 두 모델 모두 성능이 향상되는 효과를 가지고자 합니다. 앞서 정의한 이중 수준의 최적화 모델인 수식 3을 정리하자면 다음과 같습니다.
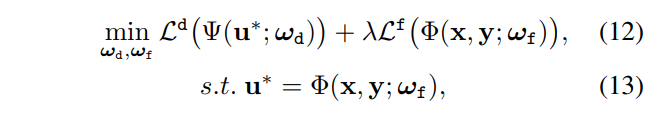
해당 수식을 토대로 loss에 대한 미분 수식을 정리하자면 다음과 같습니다.
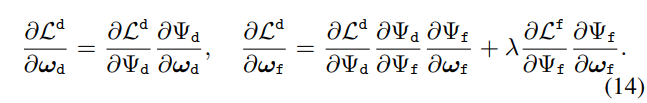
미분 수식과 같이 앞서 정의된 detection-oriente model의 이중 수준의 최적화 모델이 서로 상호적인 파라미터 학습이 가능하다는 것을 확인할 수 있습니다.
++ 수식 14가 성립하려면 수식 12는 통합 loss L = L_d + L_f로 구성되어야 하는데… 아마 오타인 것 같습니다.
Datasets-M3FD

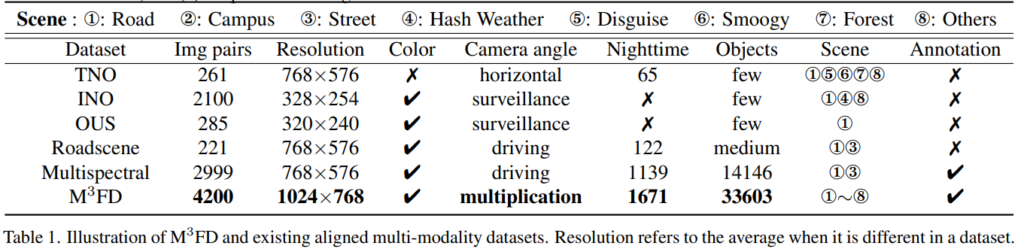
저자는 또한 IVIF의 필요성을 보이고 융합 모델의 실질적인 효과를 입증하고 학습하기 위해서 다양한 환경과 특성이 고려된 시나리오(e.g. Daytime, Overcast, Night, and Challenge. table 1 참고)로 구성된 데이터 셋을 제안합니다. 해당 데이터 셋의 예시는 위와 같은 구성으로 되어 있으며, 33,603개의물체(e.g. People, Car, Bus, Motorcycle, Truck and Lamp) bbox 정보가 가공되어져 있습니다. 또한 해당 영상들은 열화상 영상을 컬러 영상으로 사영하며 최적화된 호모그래피를 이용한 정렬된 4,200개의 멀티스펙트럴 영상쌍을 제공합니다.
Experiment
실험은 융합 모델 평가를 위해 TNO, INO, OUS, Roadscene, M3FD가 사용되어졌으며, 융합 모델과 검출 모델 평가를 위해 , Multispectral, M3FD가 사용되었습니다. 또한 공평한 평가를 위해 7개의 IVIF 모델를 통해 비교를 수행하였습니다. 검출 모델은 YOLOv5를 재학습하여 평가를 진행하였습니다.
++ 각 데이터 셋들은 IVIF를 위해 가공된 데이터 셋이며, 정렬된 상태가 아닌 영상들로 구성된 것으로 확인했습니다. 추가로 Multispectral은 KAIST 데이터 셋이 아닙니다.

Fig 6은 융합 모델의 정성적인 결과 입니다. 다른 모델에 비해 타겟의 윤곽 정보와 백그라운드의 컨텐츠 정보가 블러된 현상 없이 명확하게 보이는 모습을 볼 수 있습니다.
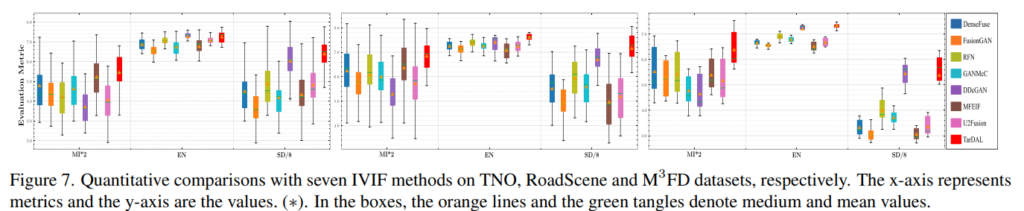
또한 융합 모델의 정량적 평가를 위해 mutual information (MI), entropy (EN), standard deviation (SD)를 사용하여 평가하였습니다. 대부분 정량적인 결과, 다른 방법론에 비해 낮은 분포도를 가진 것을 통해 다양한 씬에서도 비교적 안정적인 영상을 생성한다는 것을 볼 수 있습니다.
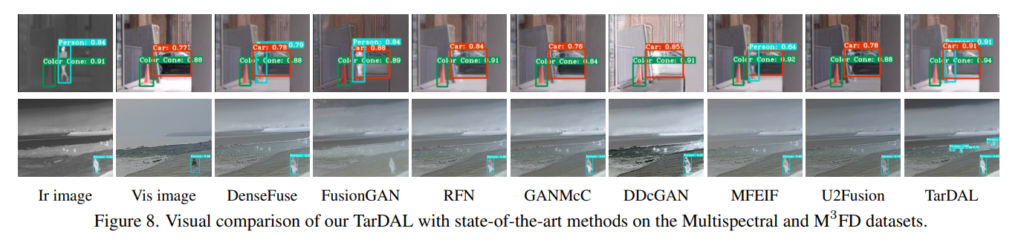
Fig 8에서는 검출 성능입니다. 해당 방법론의 생성 영상이 IVIF의 상호 보완적인 영상을 생성함으로써, 다른 방법론 대비 좋은 검출 능력을 보여줍니다. 위의 영상이 작아 아래의 그림을 첨부합니다.

위의 그림에서 볼 수 있듯이 다른 방법론에 비해 타겟의 구조적 정보와 배경의 디테일 정보가 명확하게 구분되어져 생성되어지는 모습을 볼 수 있으며, 이를 통해 작은 객체나 겹쳐있는 객체에서도 좋은 검출 능력을 보여주고 있습니다.
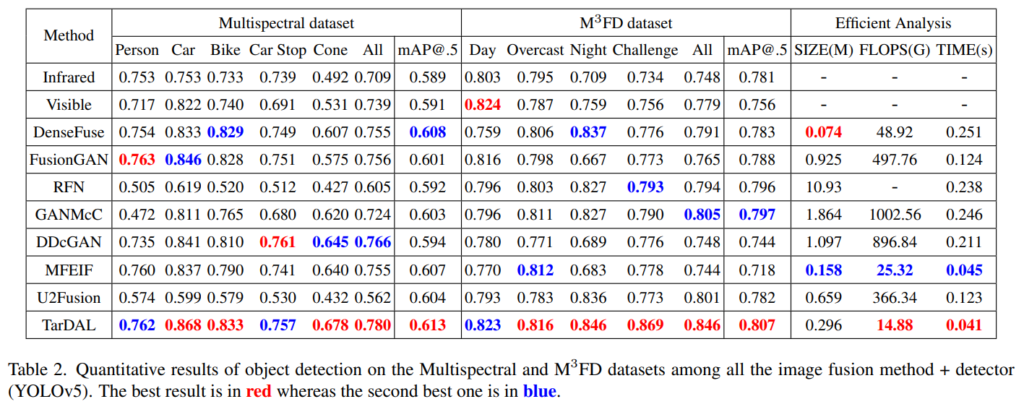
또한 YOLOv5를 베이스 검출 모델로 하여 평가한 정략적인 결과, table 2와 같이 모든 데이터 셋 에서 SOTA를 달성한 것을 볼 수 있습니다.
++ M3FD에서 infrared와 visible만 이용한 검출 성능이 조금 이상한 것 같습니다. infrared가 overcast를 제외하고는 visible을 이기지 못하고 있습니다. 그리고 Night에서는 visible이 오히려 0.05 앞서는 결과가 보입니다…. 또한 mAP@.5의 결과도 갑자기 infrared가 이기는 모습을 보여주는데;; fig 1의 데이터 구성 분포를 고려하더라도 수치가 납득이 안되네요. 나중에 데이터 셋 구성을 봐야 할 것 같습니다. 현재 수치를 토대로라면 visible에서 challenge한 경우는 적을 것으로 보입니다.

저자는 Cooperative training strategy의 효과를 입증하기 위한 실험을 진행하였습니다. DT는 direct training으로 논문에 직접적인 언급은 없었지만, 융합 영상을 생성하고 독립적으로 YOLOv5 학습한 결과로 보입니다. TT는 Task-oriented training으로 수식 14의 Detection loss만 학습한 결과이며, CT는 Cooperative training에 해당합니다. 실험적인 결과 Cooperative training에서 가장 높은 성능을 보여줌으로써, 효과를 입증합니다.
(다른 ablation study가 있었지만, 크게 중요하단 생각이 들지 않아 따로 기재하진 않았습니다. 궁금하신 분들은 논문을 참고해주시길 바랍니다.)
처음에 R2T2와 동일한 셋업 구성을 가진 데이터 셋을 공개한 논문이 CVPR2022 Oral이 되었다고 하여 굉장히 놀란 마음으로 논문을 읽었습니다. 한편으로는 이런 방법으로 풀 수 있다는 점에서 아쉬움이 남았기도 했고, 다른 한편으로는 다른 방향성의 논문이라 다행이라는 생각을 했습니다.
그리고 유사한 구성의 데이터 셋을 구축하고자 하는 연구가로써, 몇 가지 의문점이 드는 부분이 있었습니다. 두 모달리티간 베이스라인이 4cm 차이가 나는 영상을 호모그래피만 이용하여 정합을 하였는데, 저 정도로 잘 정합된 결과를 보여준다니;; 뭔가 치팅이 있지 않을까란 의심이 있습니다. 또한 컬러 영상과 열화상 영상의 검출 성능이 생각한 경향성과 너무 상이하여 데이터 셋 구성이 예시로 보여준 양상과는 다를 형태일 것 같습니다. 다른 아쉬운 점으로 해당 논문에서 공개한 코드를 하나하나 살펴보았습니다. 허나 해당 논문의 다른 기여 중 하나인 Cooperative training strategy에 대한 코드는 공개하지 않아 아쉬운 점이 있었습니다.
여러 의문점과 아쉬운 점이 있었지만, 다양한 기여도 가진 논문이라는 점에서 사실이기에… 이 정도는 되어야 Oral이구나 싶은 생각이 드는 논문이였습니다…
앞에 수식 1~3 부분에서 리뷰로 작성해주신 설명만으로 이해하는데 어려움이 조금 있는 것 같습니다. 수식 2와 3의 차이가 최적화 관점에서 전통적인 융합 기술을 학습 가능한 파라미터를 가진 모델로 바꿨다는데 이것에 대해서 조금 더 자세히 설명해주실 수 있나요?
예를 들어서 전통적인 융합 기술(f)이란 무엇이며 학습 가능한 융합모델(Φ)이라 함은 밑에서 설명해주신 Generator를 의미하는 것인가요?
Q. 앞에 수식 1~3 부분에서 리뷰로 작성해주신 설명만으로 이해하는데 어려움이 조금 있는 것 같습니다. 수식 2와 3의 차이가 최적화 관점에서 전통적인 융합 기술을 학습 가능한 파라미터를 가진 모델로 바꿨다는데 이것에 대해서 조금 더 자세히 설명해주실 수 있나요?
A. 수식 1~3 부분에서 의미하는 전통적인 융합 기법들은 딥러닝 기법이 아닌 방법론이라고 보시면 좋을 것 같습니다. 간단하게 예시를 들자면 두 모달리티간의 블렌딩 기법(전통적인 융합 기술)이 학습 가능한 딥러닝을 이용한 블렌딩 방법론(e.g. GAN)으로 변경한다고 보시면 될 것 같습니다.
Q. ‘ 예를 들어서 전통적인 융합 기술(f)이란 무엇이며 학습 가능한 융합모델(Φ)이라 함은 밑에서 설명해주신 Generator를 의미하는 것인가요?’
A. 논문에서 흔히 ‘전통적인’이라는 의미는 기계학습 방법론을 의미한다고 생각합니다. 최종적으로 융합 영상을 생성하는 모델 Generator라는 측면에서라면 같다고 보셔도 좋을 것 같네요.