이번에 제가 소개할 논문은 2021 ICRA에 나온 논문으로 6DoF pose estimation을 위해 취득한 데이터셋에서 6D pose를 빠르게 라벨링하는 방법에 관한 논문입니다.
일반적으로 6DoF Pose를 라벨링하는 과정은 2D annotation에 비해 코스트가 큰편입니다. 100% manual하게 하려면 3D object mesh 파일이 있어야하며, 해당 object mesh 파일을 이용하여 일일이 alignment를 맞추어서 라벨링해야 합니다. 이 과정이 생각보다 시간이 오래걸려서 크기가 큰 데이터셋을 라벨링하기에 상당히 쉽지가 않습니다.
그래서 대부분 테크니컬한 방법을 사용하여 라벨링하는 과정에서 코스트를 최대하 줄여서 데이터셋을 취득합니다. 대표적인 데이터셋 취득 파이프라인 논문중에 하나로 제가 지난번에 리뷰했었던 LabelFusion이 있습니다. Label Fusion에서는 라벨링을 최소한의 사람의 개입으로 하는데 성공하였지만, 여전히 object mesh파일(CAD 파일)이나 3D cam scanner이 필요하단 한계가 있었습니다.
그러나 manual하게 CAD모델을 만들거나, 3D cam scanner를 이용하여 object mesh파일을 만드는 것에는 비용이 많이 들어갑니다. 과연 저러한 특수작업없이 6D Pose를 annotation하는 방법이 없을까? 란 궁금증에 서베이를 계속 진행을 하던 중에 발견한게 이번에 리뷰할 논문이며, 전체적인 파이프라인은 아래그림과 같습니다.
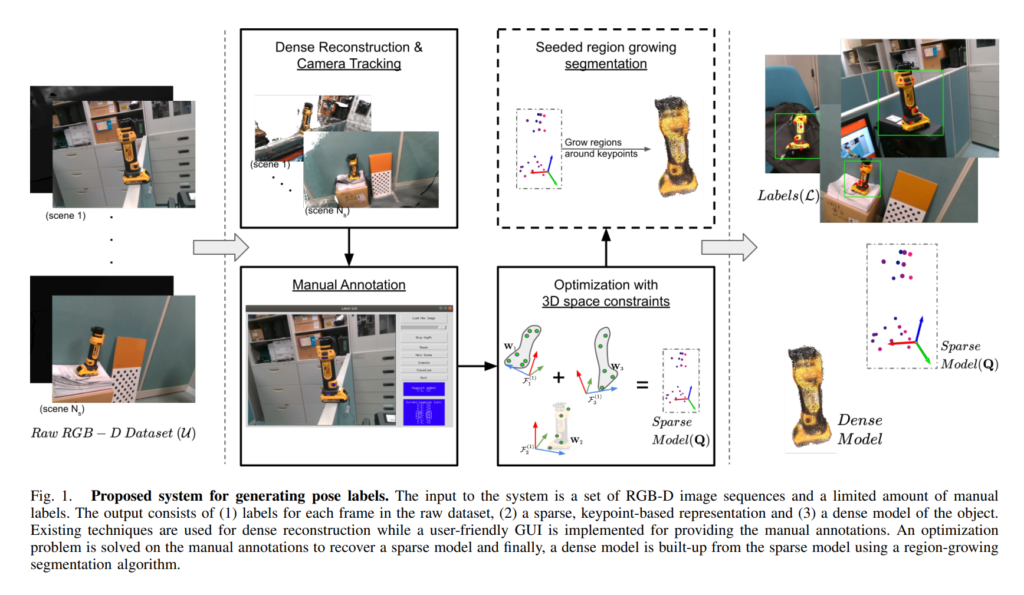
해당 논문에서 제안하는 파이프라인을 사용하면 3D object mesh파일없이도 6D Pose를 라벨링하는 것이 가능합니다. 위의 그림에서 보시면 오른쪽 아래의 Dense Model이라고 적혀있는 그림이 바로 해당 파이프라인을 거치며 구한 object mesh파일에 해당합니다. 물론 CAD로 직접 그린거보다 정확하진 않지만, GT CAD모델을 이용하여 라벨링하여 제공한 데이터셋과 비교했을때 유의미할 정도의 유사한 결과를 얻었다고 합니다.
그럼 위의 파이프라인 과정에 대해서 좀 더 자세히 살펴보겠습니다.


먼저 위의 수식 (1)이 의미하는것은 카메라의 초기위치가 t=1 일때, t초후에 같은 scene에 해당하는 point들을 다시 transformation matrix를 이용해서 다시 초기위치로 3D Point를 옮긴 것 입니다. 좀 더 구체적으로 카메라 intrinsic parameter와 depth 센서를 이용하여 취득한 depth정보 및 RGB이미지 정보를 3차원 point cloud로 올린 점이 해당 수식(1)에서 d에 해당하며, point cloud로 올리는 과정에 대해서는 최근 신정민연구원이 리뷰한 pseudo-lidar 논문을 참고하시면 학습하는데 도움이 될거 같습니다. t초에서의 3D 포인트를 1초에서의 3D 포인트로 변환해줍니다. t초에서의 3D 포인트를 1초에서의 3D point로 변환하는 과정에는 camera pose matrix가 사용이 되었습니다. 해당 과정에서 사용된 camera pose matrix로는 기존에 이미 존재하는 3D reconstruction & camera tracking 기법을 사용하여 같은 scene에서 multiple frame을 취득하고, 각 프레임마다 camera의 pose를 tracking하여 나온 결과를 사용하였습니다. 결과론적으로 W를 얻었으며, W는 t개의 프레임에서 manual하게 annotation한 3D point들을 t=1일때 카메라 기준으로 transform한 결과의 집합을 의미합니다.
내용을 디테일하게 설명하려다보니 말이 너무 어려워졌는데요… 실제로 논문자체가 좀 복잡하여 디테일한 부분을 다 설명하려니 말이 자연스럽게 어려워졌습니다. 좀 더 직관적인 표현으로 위의 과정을 설명해드리겠습니다.
어려운 내용이 많이 나왔지만, 결과적으로 보자면, 아래와 같은 내용입니다. 최대하 쉬운말로 풀어써보았으니 참고하시고, 이해하신다음 위의 내용을 다시 읽어보시길 권장드립니다.
- 1개의 scene에 대해서 여러장의 사진을 촬영하고, 촬영하는동안 camera의 pose를 tracking합니다. (카메라 포즈 행렬 획득)
- 각 프레임마다 rigid한 body에서 특징이 되는 점을 8~16개 정도 선정한다음 manual하게 annotation 하여줍니다. (모든 프레임에서 동일한 특징점 annotation 하여야 함)
- Annotated point들과 depth정보 및 intrinsic parameter를 이용해서 3차원상으로 pseudo-lidar를 만들어줍니다. 일반적으로 depth정보라고 하면 1차원데이터고, 실제 라이다를 통해 얻은 라이다 데이터는 4차원데이터가 됩니다. 이때, 실제 라이다는 x,y,z, reflectance로 구성이 되는데 depth정보와 intrinsic parameter를 이용하여 3차원에 띄운 pseudo-lidar같은 경우에는 x, y, z 정보만이 해당됩니다. (reflectance가 없습니다.)
- 2과정에서 얻은 Pseudo-LiDAR를 t=1초일때 카메라프레임으로 모두 transform하여줍니다. 1번에서 카메라 포즈행렬을 구했기 때문에 1~t초동안 같은장면에 대해서 n개의 프레임을 취득하였다고 한다면, n개의 프레임에 상응하는 n개의 카메라 포즈행렬이 있을것 입니다. n개의 프레임에서의 Pseudo-LiDAR를 해당 카메라 행렬을 이용해서 t=1초 일때로 transform해줍니다. (설명의 편의상 n개라고 표현하였으나, 정확히는 1초일때를 제외하면 n-1이 맞습니다.)
위와 같은 과정을 거치면 t=1초에서의 frame으로 transform된 3D keypoint들을 얻을 수 있게 됩니다. 그리고 이러한 정보는 각 scene마다의 transform관계를 구하기 위해 식(2)에서 W로 사용됩니다.
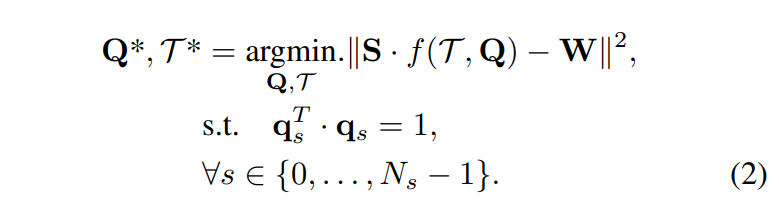
위의 식에서 f안에 들어있는 Q는 각 프레임별 keypoint들이고, T처럼생긴 문자는 쿼터니온 rigid transform 행렬입니다. f는 연속적으로 쿼터니온 transform을 Q에 적용하는 함수이며, S는 selection maxtrix로 reference로 사용가능한 W가 존재하는 경우의 Q만을 selection하여주는 역할을 합니다. 이후, t=1초 일때 기준으로 위에서 구한 W와 여러개의 scene에 대해서 3D point를 합하여 구한 sparse model Q를 transformation을 하였을때의 l2 distance를 최적화하는 방식으로 scene간의 transformation maxtrix를 optimization 하여줍니다.
지금까지 Sparse model과 scene에 존재하는 frame간에 relative 한 rigid transform 및 sparse model를 구하는 과정에 대해서 알아보았습니다.
이제 해당 정보를 이용해서 Dense한 object mesh를 얻는 방법에 대해서 소개해드리겠습니다.
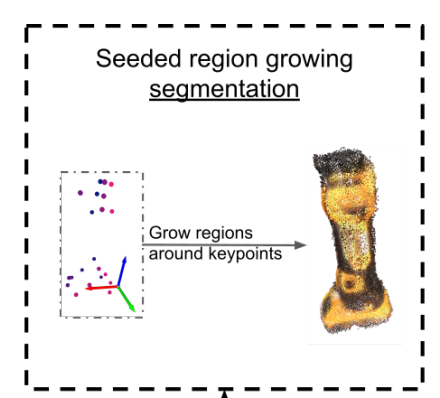
해당 과정에는 앞서 구한 sparse model인 Q를 이용하여 구했다고 합니다. PCL라이브러리에서 제공하는 Seeded region growing segmentation 방법으로 취득하였다고 합니다. 이때, Seed는 앞서 구했던 sparse한 model의 keypoint집합이 됩니다. 좀 더 구체적으로, 각 scene마다 region growing segmentation을 적용하고, 앞서 구했던 relative rigid transformation matrix를 적용하여 dense한 object mesh를 만들었습니다.
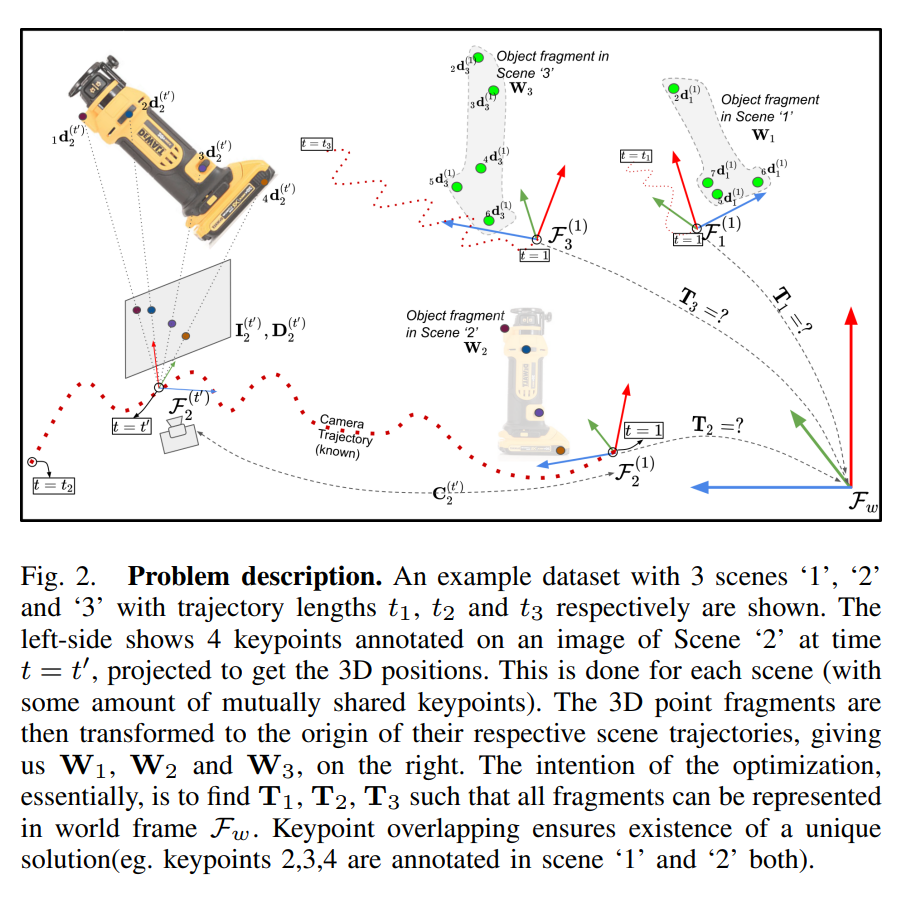
위의 그림은 앞서 설명했던 내용을 직관적으로 표현하여 보여줍니다.
이제 여태까지 구한정보를 이용해서 어떻게 라벨링을 하는지에 대해서 살펴보겠습니다.
사실 이 과정은 앞선 내용을 이해했으면, 그다지 어렵지 않습니다.
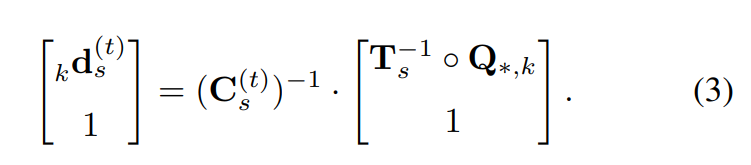
위와 같은 수식으로 정의가 되는데요. 위의 수식에서 구하고자하는 d는 dense한 모델에 있는 keypoint값으로 해당 keypoint값을 안다는 것은 6DoF pose estimation에서 물체의 포즈를 안다는 것과 같습니다.
해당 수식에서는 앞서 구한 카메라 포즈행렬과, relative rigid transformation matrix, dense model이 사용되었습니다. 앞선 과정에서 dense model을 얻었고, 같은 scene에 해당하는 frame간의 transformation matrix 및 camera pose matrix가 있으니, 이를 이용해서 t초에 해당하는 object의 keypoint들을 얻을 수 있는 것 입니다.

이제 이러한 방식으로 취득한 label이 얼마나 유효한지에 대해서 실험을 해보아야하는데요. 해당 논문에서는 위와같이 2개의 데이터셋에서 실험을 하였습니다. (a)는 자체취득한 데이터이며, (b)는 6DoF pose estimation 분야에서 유명한 YCB-Video 데이터셋 입니다.
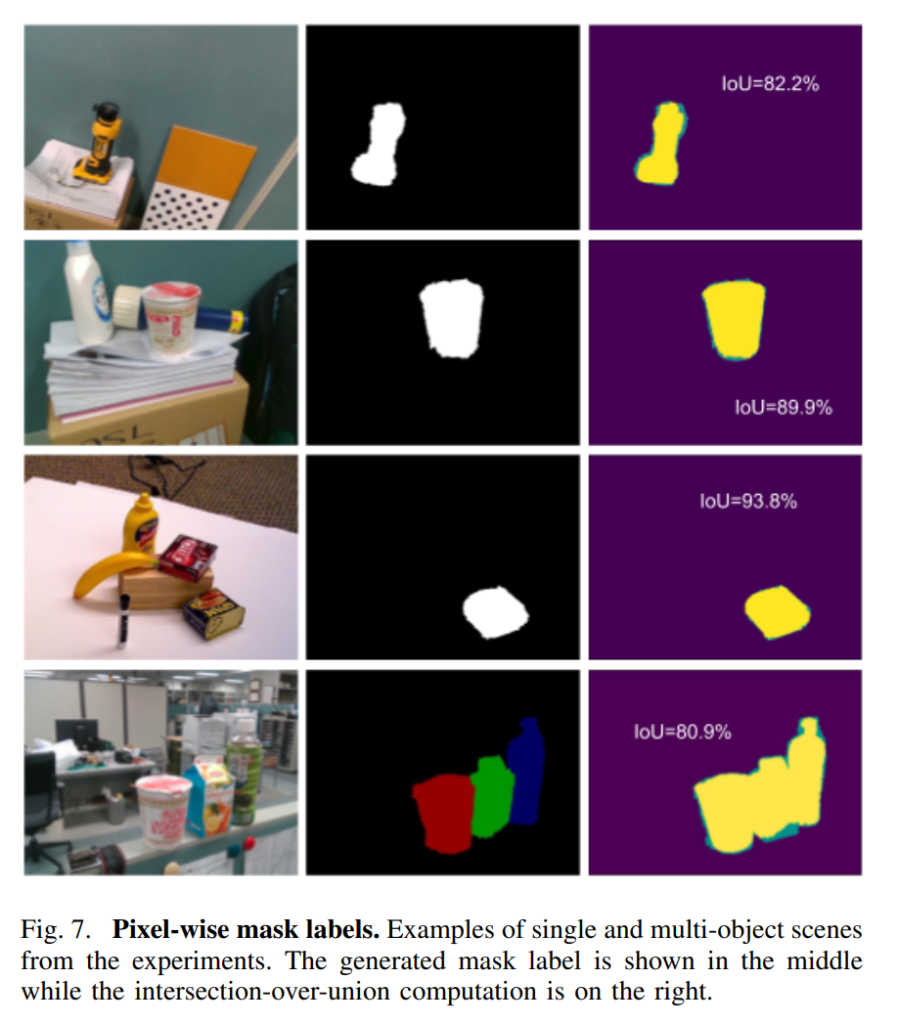
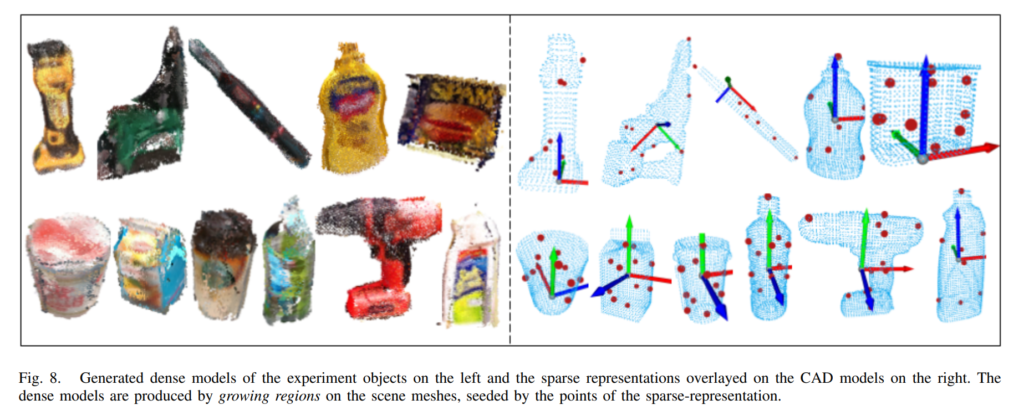
위의 그림들이 실험결과인데, 실제 GT와 비교했을때, 본 논문에서 제안하는 방법으로 labeling을 하는게 확실히 유효해보입니다. 하지만, object mesh파일을 보면 hole이 존재하는 등 완벽하지 않은것을 확인할 수 있습니다. 저자는 이러한 부분을 필요시 manual하게 crop하여 사용할 수도 있다고 말합니다.
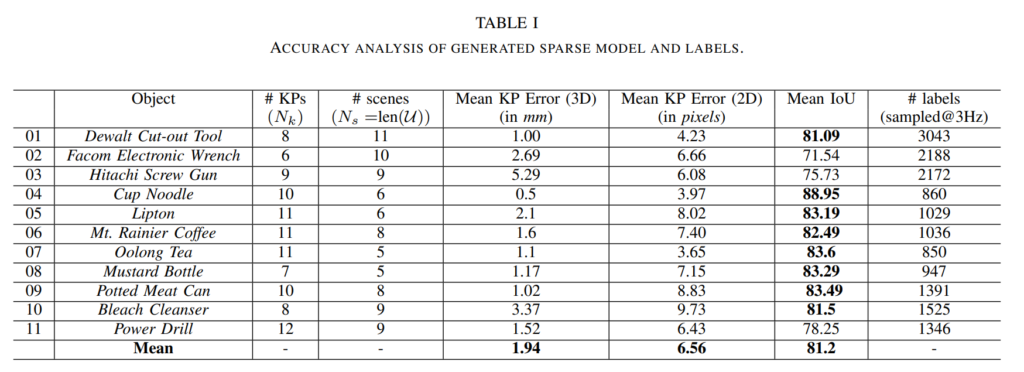
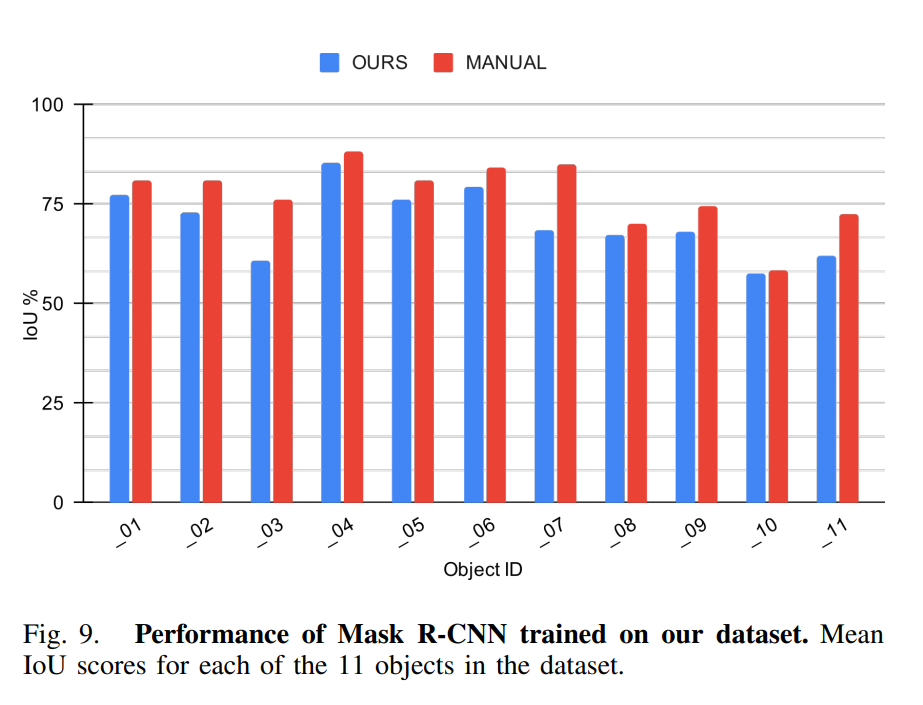
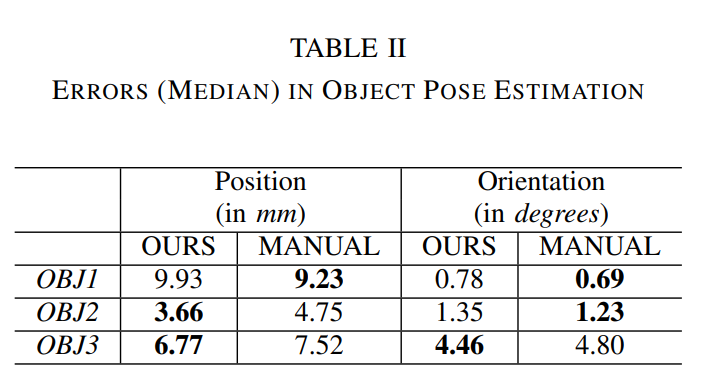
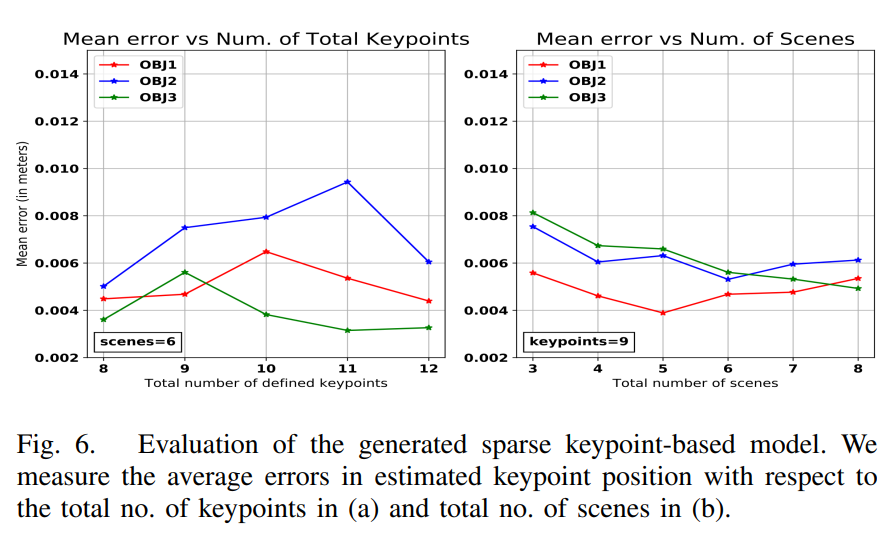
정량적으로도 위와같이 보았는데, 사실 이러한 시도가 기존에 있었던게 아니라 비교군이 없어서 어느정도 좋은진 모르겠지만, 제가봤을땐, 확실히 결과가 유효한거 같습니다.
수식이 많이나오고, 내용이 좀 어려워 설명이 쉽지 않았던거 같은데 혹시 이해안가시거나 질문이 있으시면 댓글로 남겨주세요.
리뷰 잘 읽었습니다.
실험에서 매뉴얼이 3d 모델링으로 주석 처리한 데이터를 사용했다고 생각하면 될까요?
그리고 lablefusion과 핵심적인 차이가 뭔지 알려주신다면 감사드리겠습니다.
첫번째 질문은 이해를 못하였습니다… labelFusion과의 차이점은 3D scanner나 메뉴얼하게 3D CAD 모델 생성없이 몇개의 keypoint annotation만으로 3D object mesh 파일을 만들어서 사용한 것 입니다.