오늘은 지난번에 가져왔던 video highlight 논문을 또 가져왔습니다. 이 논문은 지난번 논문에서 가장 큰 문제로 지적되는 도메인에 종속된다는 문제점을 해결하기 위해 Knowledge distilation을 가져왔습니다. 그래도 여전히 문제가 있는 것 같지만 리뷰 시작해보겠습니다.
Introduction
이 논문에서도 일반적으로 지도학습으로 수행되는 비디오 하이라이트가 특정 비디오 category에서만 학습되는 것에 목적을 두어서, 다른 category를 가진 하이라이트 모델의 성능이 그렇게 좋지 않다는 문제점을 지적하면서 시작합니다. (서핑 영상은 서핑 영상으로 학습해야, 성능이 좋다는 문제)

그래서 이 논문에서는 이 문제를 Cross-category Video Highlight Detection 문제라고 부르고, 이 문제를 Unsupervised Domain Adaptation으로 해결하고자 합니다. [그림 1]을 통해 이 방법이 필요한 이유를 설명하는데요, 학습은 보통 위의 “서핑” 케이스 처럼 되지만, 라벨링 되지 않은 “스키” 케이스 같은 경우에도 잘 작동하게 만들 수 있다는 것입니다.
또한 기존의 학습 방법이 비디오 쌍을 기반으로 하는 학습이었는데, 이 경우에는 비디오 하이라이트에서 필요한 contextual information을 충분히 학습할 수 없었다고 합니다. (이 문제는 비디오 대신 세그먼트 셋을 통해 해결합니다.)
그래서 결론은 coarse-grained learner와 fine-grained learner을 각각 학습해서 Knowledge distilation을 이용하는 Dual-Learner-based Video Hightlight Detection (DL-VHD)과 이 DL-VHD의 근간을 이루는 Set-based Learning module (SL-module)을 제안하여 이 문제를 해결했다고 합니다.
늘 정리되어 나오는 Contribution도 정리해보면 아래와 같습니다.
- 비디오 하이라이트 연구에서 최초의 cross-category를 지원하는 연구
- 비디오 세그먼트 셋 기반의 새로운 학습 방법론
- Cross-category임에도 불구하고 지도학습과 유사한 높은 성능
Method
먼저 세그먼트 셋이라는 용어가 자주 등장해서 이 부분에 대한 정의를 먼저 알아야합니다.
D_S = \{v_k^S\}{k=1}^{|D_S|}라는 source video category의 하이라이트 영역을 포함하고 있는 비디오 셋이 주어졌을 때, 이 비디오는 비슷한 길이를 가진 세그먼트 N_v로 분할 될 수 있고, 이를 표현하면\{(s_i, y_i)\}{i=1}^{N_v}로 나타낼 수 있습니다. (s는 세그먼트, y는 GT label) 그럼 D_T=\{v_k^T\}_{k=1}^{|D_T|}라는 target video category의 하이라이트 영역을 포함하고 있지만, 라벨링 되지 않은 비디오가 들어왔을 때, 여기서 하이라이트 영역을 찾는 것이 목표입니다.
사실 이 부분을 설명을 하고 넘어간 이유는 이 부분이 결국 다른 카테고리를 가진 비디오로의 전이학습을 어떻게 효율적으로 수행하는지 논문 저자가 중요하게 설명하는 부분과 연결되기 때문입니다. 여기서는 Set-based Learning이라고 부르는데, 일반적인 Pair-based learning(Positive – Negative)와 다른 점은… 입력이 세그먼트 셋 단위라는 점이 차이입니다. 이 방법이 contextual information을 보다 잘 학습할 수 있어 하이라이트 영역을 좀 더 잘 찾을 수 있다고 합니다.
Set-based Learning Module
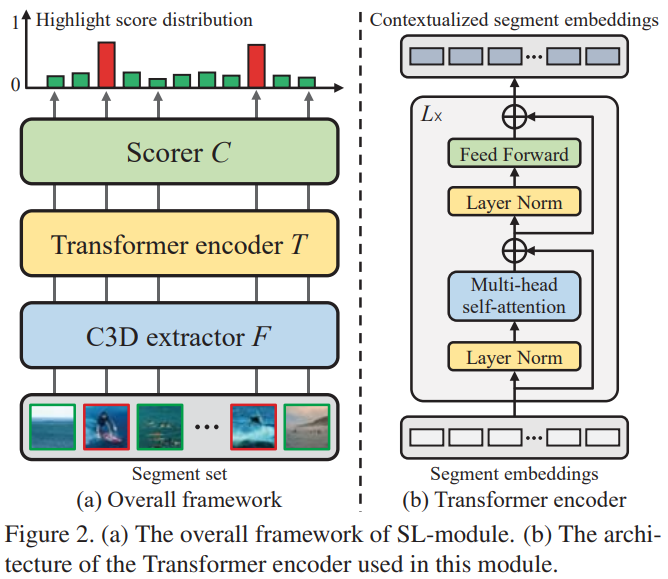
전반적인 구조를 알아보기 전에 Set-based Learning Module(SL-module)을 먼저 봅시다. 이 모듈은 C3D로 세그먼트 셋의 feature를 추출하고, Transformer encoder를 통해 contextualized segment embedding feature를 만들고, 이 피쳐를 통해 세그먼트 셋의 highlight score를 예측하는 구조로 되어있습니다.
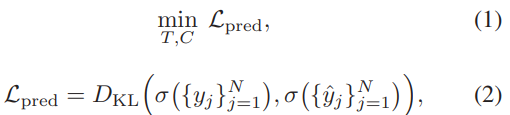
Loss로는 위와 같은 것을 가지는데요. $D_{KL}$은 Kullback–Leibler divergence를 의미하고, y는 GT를, \hat{y}는 predict값입니다. (Kullback–Leibler divergence는 확률분포의 차이를 뜻한다고 합니다.) 최종적으로 이 SL-module은 세그먼트 셋의 higlight score의 분포를 예측하도록 모델을 학습시키는 것입니다.
Dual-Learner-based Video Highlight Detection
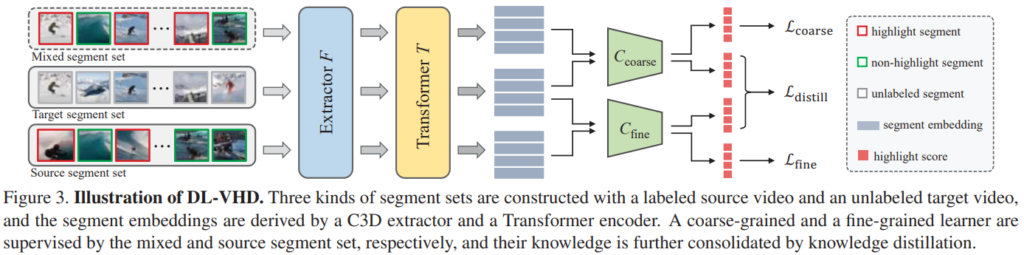
이 구조가 가능한 이유에 대한 긴 설명이 있지만, 요약하면 서로 다른 카테고리의 비디오의 하이라이트 영역은 서로를 구분하게 하는 특징들이 있지만, 공통적으로 존재하는 보편적인 특징이 있다고 주장합니다. 그러면서 제안하는 방법론의 coarse-grained learner와 fine-grained learner가 이 특징들을 각각 잘 학습할 수 있다고 주장합니다.
아무튼 두 개의 learner를 학습시켜야 하는데, 그림에서 보는 것과 같이 세가지 세그먼트 셋을 만듭니다. Target은 GT가 없는 경우고, Source는 GT가 있는 경우인데, mixed set은 두 카테고리의 비디오의 세그먼트에서 랜덤으로 선택해서 만듭니다. 이렇게 만들어진 세가지의 세그먼트 셋을 SL-module을 이용해서 두가지 learner를 학습하기 위해 만듭니다.
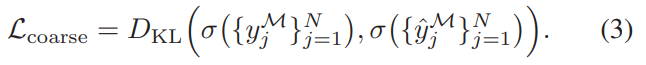
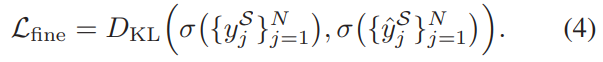
coarse-grained learner는 target segments set과 mixed segments set을 학습해서 gt hightlight distribution을 맞춥니다. 그리고 fine-grained learner는 target segments set과 source segments set을 학습해서 source에서 어느 영역이 하이라이트 순간인지를 알아내는 지식을 학습합니다. 둘 다 하이라이트 영역을 찾기 위한 정보를 학습하지만, 위에서 말했던 것 처럼 coarse는 구분적인 특징, fine은 보편적인 특징을 학습한다고 생각하면 됩니다.
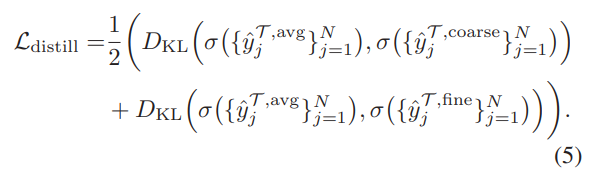
그리고 KD에서 영감을 받은대로, distilation loss를 설계해서 두 learner의 학습 과정을 합쳐줍니다. 특별하게 추가적으로 알려드릴 수식은 없고, avg만 추가적으로 설명하면 충분히 이해할 수 있는 수식 입니다. coarse와 fine의 합의 절반으로, 두 결과값의 평균을 취해준 결과입니다. 즉, coarse와 fine의 각각의 learner에 서로의 예측값의 절반만큼을 더해줘 KD loss를 구성했습니다.
Experiments
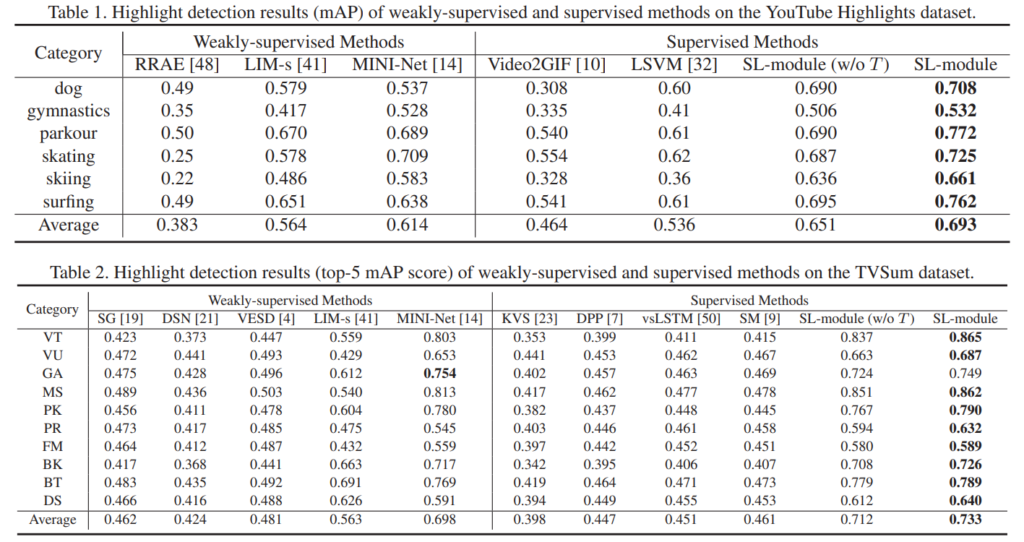
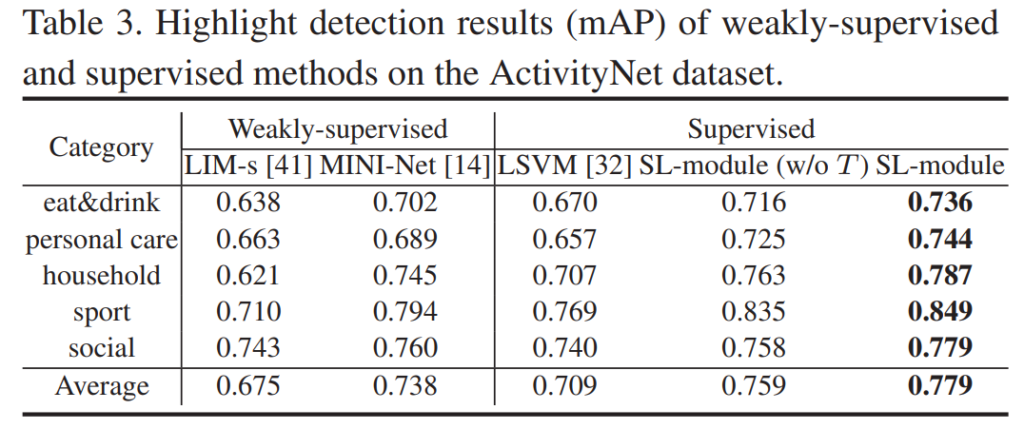
위의 실험 결과들은 해당 카테고리에서 학습하고 평가한 결과입니다. 여기서는 특이하게도 ActivityNet에서의 실험 결과도 함께 보여줍니다. ActivityNet의 “temporal action localization”를 채용해서 평가했다고 하는데… 정확한 평가는 될 수 없지만, 비교적 대용량의 데이터셋이라 간접적인 평가 지표로서 활용할 수 있다고 생각합니다. 어쨋든 기존의 video summarization 데이터셋을 가져와서 평가를 수행하는데요. 꽤 높은 성능을 보이는 것을 알 수 있습니다.
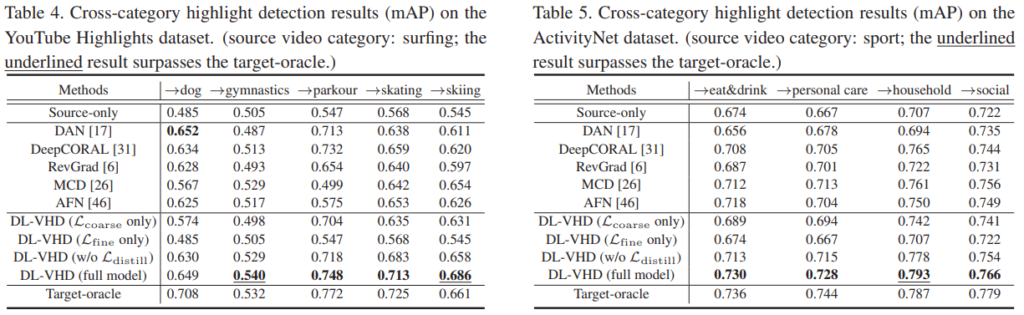
이 논문에서 주장하는 Cross-Category(서로 다른 카테고리의 데이터셋에서 학습하고 평가하는 것)에 대한 실험 결과는 위에 있습니다. 이게 사실 좀 웃기긴 한데… 서핑 카테고리에서 학습하고 개 카테고리에서 평가했을 때 이 cross-category 학습을 적용한 성능이 꽤 높게 나옵니다. 이 논문에서 예시를 드는 경우가 스키-서핑의 케이스만 존재해서, 액션이 유사해야 성능이 오르는 것인가? 라는 생각이 들었는데 그렇지 않다는 것을 보여주는 케이스가 바로 이 케이스입니다. 또한, 다른 UDA 알고리즘 대비 이 방법론의 성능이 개 카테고리에선 좋지 않지만, 인간이 등장하는 다른 카테고리에서는 oracle(같은 카테고리로 학습하고 평가한 결과)에 근접한 성능을 보입니다. 실제로 학습이 된거죠. 그리고 각각의 모듈에 따른 성능 변화도 함께 보여주어, 논문 저자들이 주장하는 대로 knowledge distillation이 이루어 진다는 것을 볼 수 있습니다.
Conclusion
확실히 회사들이 이런 연구에 관심이 많은 듯 합니다. 지난번 비디오 하이라이트는 인스타그램을 가진 페이스북이 낸 논문이었고, 이 논문은 틱톡을 가진 바이트댄스 연구팀에서 냈더라고요. 연구적인 측면에서 보자면 도메인에 종속된다는 문제점을 조금은 해결한 논문이었지만, 아직도 한계가 많은 것 같습니다. 그리고… 다양한 방법을 적용한 논문들을 찾아서 읽고 있는데, 베이스라인 방법론을 모르는 상태로 읽으니 많이 어렵네요.
좋은 리뷰 감사합니다. coarse는 구분적인 특징을 fine은 보편적인 특징을 학습한다고 설명하셨는데 low level, high level feature와 비슷한 개념인지 잘 이해가 안되서 질문드립니다.
좋은 리뷰 감사합니다.
글을 들어갈 때 도메인에 종속된다는 문제점을 해결하기 위해 Knowledge distilation을 적용하였으나, “여전히 문제점이 존재하는 것 같다” 고 하셨는데요, 그 문제가 무엇일까요? 어떤 포인트에 초점을 두고 논문이 해결해나간 방향이 논리적이다 라고 얘기할 수 있는지 궁금합니다.
리뷰 감사합니다. 비디오 요약 연구를 대기업에서 많이들 한다니, 인상 깊네요. 몇가지 질문이 있습니다.
1. Set-based Learning Module에서 사용하는 Loss는 KL Loss인 것 같은데 그렇다면 정답 예측 스코어 분포를 닮아가도록 만들어주는 게 목적인 것 같습니다. 그렇다면 Set-based Learning Module은 GT가 있는 데이터에서만 작동하는 것이 맞나요?
2. Set-based Learning Module 에서 Transformer Encoder의 역할은 segment 끼리의 dependency를 modeling 하기 위해 등장한 것인가요? 리뷰에는 별다른 설명이 없어 여쭤봅니다.
리뷰 잘 읽었습니다!
Method 단락의 초반에 나오는 D_s = 1^ {|D_s|} 부분을 잘 이해하지 못하겠어서 그런데, 좀 더 자세히 설명해주실 수 있을까요? 1 을 |D_s| 승 하는 게 무슨 뜻인 지 잘 모르겠습니다…!
‘coarse는 구분적인 특징, fine은 보편적인 특징을 학습한다’ 이라는 부분에서, fine-grained 가 더 자세하니까 구분적인 특징을 학습해야한다고 생각했는데 fine-grained learner 가 보편적인 특징을 학습하도록 이유는 무엇인가요?