
현재 Text-to-video retrieval 에서 SOTA 를 달성하고 있는 논문입니다. 중국의 유명한 인터넷 플랫폼 서비스 기업인 ‘alibaba’에 속한 인공지능 연구기관 ‘DAMO academy’에서 나온 논문이에요. 리뷰 시작하도록 하겠습니다!
Abstract
- 우선, Text Video Retrieval (이하 TVR)의 performance 에 영향을 끼치는 가장 중요한 요소는 Cross-modality interaction, 즉, 서로 다른 모달리티 간의 상호 관계를 잘 나타내는 것입니다.
- 이 interaction 을 계산할 때는 여러 가지 구성 요소들이 사용되는데, 그럼에도 불구하고 이 요소들이 TVR 의 성능에 어떻게, 얼마나 영향을 미치는 지에 대한 조사는 거의 진행되지 않았다고 합니다.
- 본 논문에서는 이러한 요소들을 발견하여 새로운 framework 를 제안하고, ablation study 도 하고, 다양한 TVR 벤치마크에서 이 framework가 포착한 representation 을 사용했을 때 sota를 달성함을 보여줌으로써 해당 framework 의 효과를 입증합니다.
Introduction
비디오의 어느 부분이 텍스트의 어느 부분과 매칭되는지 찾는 것, 즉, 서로 다른 모달리티에 대해 alignment 를 하는 것은, 모달리티 내에서의 representation 과 모달리티 간의 interaction 을 모두 고려해줘야 합니다.
최근에 CLIP 이 대규모의 image-caption pairs 데이터를 이용하여 pretaining 함으로써 일반적인 vision and language representation 을 학습해냈고, 이를 통해 다양한 Vision-Language task 에서 인상적인 향상을 보여줬었습니다. 이후 CLIP 을 기반으로 하여 temporal transformer 까지 사용하여 시간적인 정보, 즉 sequential features 가 representation 에 포함되도록 a single high dimensional representation 을 만들고, dot-product search 를 통해 retrieval을 하는 CLIP4Clip 이 등장하여 당시에 Text-Video retrieval 에서 sota를 달성하기도 했었습니다.
본 논문에서는 이러한 이전 연구들을 바탕으로 Text-Video Retreival 에 대해 두 가지 가정을 했습니다.

- 첫째. 비디오에 대한 설명은 비디오의 일부, 즉, local context 와 관련이 있을 것이다.
- 둘째. 동일한 비디오에 대해 설명하는 여러 문장들은 이 비디오에 대한 힌트가 될 수 있을 것이다.
본 논문에서는 이러한 관점들을 바탕으로, 그리고 서로 다른 모달리티 간의 ‘interaction’을 계산하는 구성요소들을 바탕으로, 현존하는 framework 들을 re-examine 하였습니다.
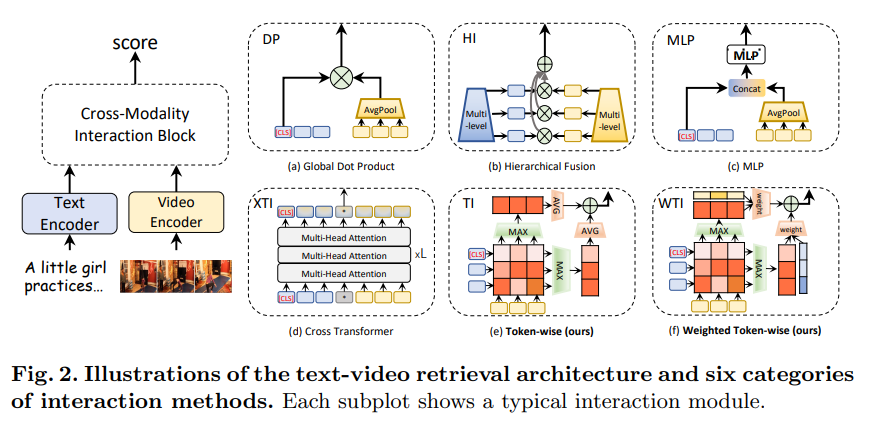
- 왼쪽 : Text Video Retrieval 를 위한 interaction method 의 전형적인 구조
- 오른쪽 : interaction method 의 ‘interaction block’ 를 process flow 에 따라 6가지로 구분한 것
이때, process flow는 “input content 의 granuality” 와 “interaction function” 라는 두 가지 요소를 통해 구분하였습니다.
(앞으로도 한 동안 Text-to-video retrieval 과 관련된 논문들을 읽을 예정이라… 이 구조에 따라 읽어볼 생각입니다!)
본 논문에서 제안하는 a disentangled framework 는 새로운 interaction method 를 사용합니다. 이것은 모든 sentence token 들과 video frame token 들과 fully-interact 할 수 있는 a lightweight token-wise interaction (오른쪽 그림 e, f,) 입니다. single-vector interaction (오른쪽 그림 a,c) 와 multi-level interaction (오른쪽 그림 b) 와 비교했을 때, 해당 method 는 fine-grained clues 를 더 잘 보존할 수 있다는 장점이 있습니다. 그리고 cross transformer interaction (오른쪽 그림 d)와 비교했을 때, optimization의 어려움과 compuatational overhead 를 완화시킬 수 있다는 장점이 있습니다.
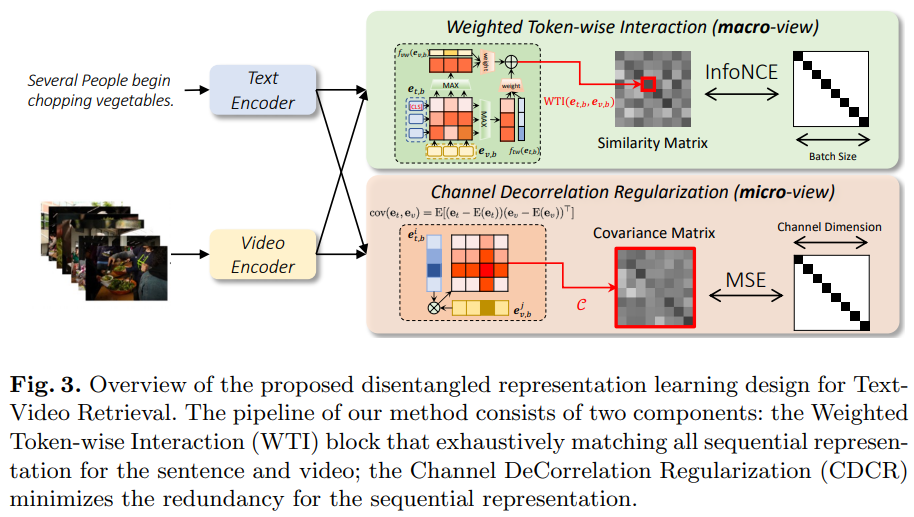
그리고, 이와 함께 a Channel DeCorrelation Regularization (CDCR) 를 사용합니다. CDCR 은 비교하는 vector 의 구성요소들 간의 중복성을 최소화 함으로써, a hierarchical representation 을 학습하는 것을 용이하게 합니다.
즉, DRL 은 a lightweight token-wise interaction 과 CDCR 을 함께 사용함으로써, TVR 에 적합한 representation 을 학습해낼 수 있다는 것이 핵심이라고 보시면 되겠습니다. 이제 DRL 에 대해 좀 더 자세히 살펴보도록 하겠습니다.
DRL
Definition
- a text query : t = {{\{t^{i}\}}^{N_t}_{i=1}} ( N_t = # of tokens)
- a set of video documents : V = \{v_n\}^N_{n=1}
- a cross-modality measurement : S(t,v)
이때, 서로 다른 두 모달리티를 동일한 ( D = feature dimension ) 차원으로 인코딩하여 나타냅니다.
- Text Encoder : E_t(t, \theta_t) → extract text features e_t \in R^{N_t \times D}
- Video Encoder : E_v(v, \theta_v) → extract video features e_v \in R^{N_v \times D} ( N_v = # of sampled video frames)
Feature extractor
해당 방법론에서는 feature extraction 을 위해서 Bi-Encoder, 즉, 텍스트 인코더와 비디오 인코더를 이용합니다.
- t : [CLS] 토큰과 [SEP] 토큰을 추가하여 문장의 시작과 끝을 나타냄
- E_t : pretrained BERT-BASE 사용
- v : uniform sampling 으로 keyframes 선택
- E_v : transformer-based network (ex. ViT) 사용
이 논문의 핵심은 pretrained networks 가 아니라 interacion module 을 디자인하는 것이기 때문에, 기성품처럼 쓰이고 있는 CLIP 을 사용하여 feature extractors 를 초기화 한 후 end-to-end 방식으로 finetuning 하여 사용합니다.
Interaction mechanisms
Token-wise Interaction
- Document and image retrieval 에 대한 이전 연구 (ColBERT, FILIP) 에서 제안하였던 token-wise interaction 을 TVR 로 도입하여 사용하였습니다.
- 이를 이용하여 TVR 에 대한 첫번째 가정 이었던 local context matching 문제를 해결합니다.
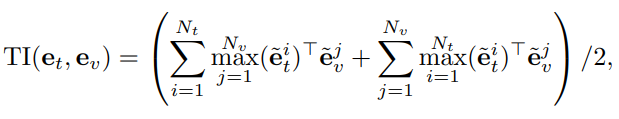
- \hat{e} = e^i / {||e^i||}_2 : the channel-wise normalization operation
- 해당 interaction 는 a parameter-free operation 이라서, 효과적인 저장/인덱싱이 가능하다는 장점이 있습니다.
Weighted Token-wise Interaction
- 문장의 모든 단어들과 비디오의 모든 프레임들이 동일한 정도로 중요하지는 않다는 점에서 착안하여, 각 token 에 weight magnitude 를 부여하는 방법을 제안하였습니다.
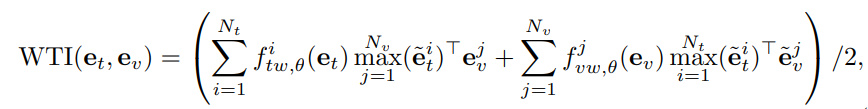
- f_{tw, \theta}, f_{vw, \theta} : classic MLP 와 a SoftMax function 으로 구성된 함수
- lightweight 한 adaptive block 이 a single-modality 를 input 으로 받습니다.
- offline process : large-scale video documents 에 대해 pre-computation 가능
- online process : attention module 을 통해, 무시할만한 정도의 computation overhead 를 갖게됨
- 해당 방법은 이전의 일반적인 mathing 방법을 계승하면서도 더 효과적/효율적입니다.
이러한 interaction mechanism 을 통해 batch size 가 B 인 video-text pairs 가 주어졌을 때 B x B 사이즈의 similarity matrix 를 생성합니다.
Channel DeCorrelation Regulation (CDCR)
- input : B \times B similarity matrix
- train : Video-Text 데이터셋을 이용한 supervised 방식
- loss : InfoNCE loss + CDCR loss
InfoNCE loss
Text-to-video retrieval loss와 Video-to-text retieval loss를 함께 사용하는, InfoNCE loss 를 사용합니다.
labelled video-text pairs 에 대한 similarity 는 최대화하고, 다른 pairs 에 대한 similarity 는 최소화하는 loss 입니다.
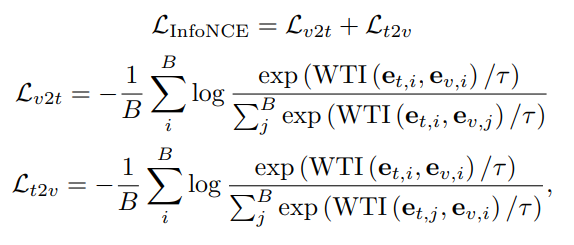
CDCR loss
Contrastive loss 는 global similarity 를 최적화하기 위한 “a macro objective” 를 제공합니다. 이때, 우리가 풀려는 문제가 multi-modality retrieval 인 건 생각해보면, 그러니까 이러한 문제에서 필요한 expression 을 생각해보면, 좀 더 “micro-views” 으로부터 얻은 semantic information 을 필요로 합니다. 예시를 들자면, channel-level 말입니다. 그리고 이걸 CDCR loss 에서 고려를 해줍니다.
[PMLR 2021] Self-supervised learning via redundancy reduction 에 영향을 받아, covariance matrix 를 이용하여 feature 들 간의 redundancy 를 측정하고 L2 normalization 을 적용해서 hierarchical representation 을 최적화합니다.
이때, 실험을 통해 CDCR 이 모든 interaction mechansim 에 대해 성능 향상을 만든 걸 확인할 수 있었다고 합니다.
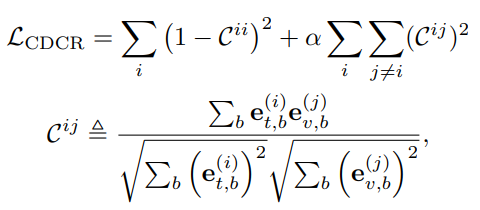
- e^{(i)}_{t,b} : b 번째 text feature e_{t,b} 의 i번째 채널
- \alpha : redundancy 정도를 조절하는 값
Total training loss
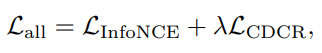
- \gamma : weighting parameter
Experiment
Experimental Settings
Dataset
- MSRVTT, MSVD, VATEX, LSMDC, ActivityNet, DiDeMo
Evaluation Metric
- Recall at rank K (R@K), Median Rank (MdR), Mean Rank (MnR)
Implementation Details
- pretrained feature extractor : CLIP 의 Bi-Encoder 사용
- vision encoder : ViT-B/32 와 4-layers of temporal transformer blocks 로 구성됨
- text encoder : temporal position embedding 과 network weight parameter 를 CLIP 으로부터 가져옴
- Fixed video length : 12 (MSR-VTT, MSVD, VATEX, LSMDC), 64 (ActivityNet, DiDeMo)
- Fixed caption length : 32 (MSR-VTT, MSVD, VATEX, LSMDC), 64 (ActivityNet, DiDeMo)
- text : special text tokens [CLS], [SEP] 사용
- video : video token 에 대한 weight factor 포착을 위해 MLP 사용
Training schedule
- CLIP4Clip 의 training schedule 을 따라서 공평하게 비교합니다.
- InfoNCE Loss의 \tau = 100, CDCR Loss의 \alpha = 0.06, Total Loss의 \gamma = 0.001
Ablation study
제안한 방법론에서의 key componentsn 인 WTI 와 CDCR 에 대한 ablation study 를 진행하였습니다.
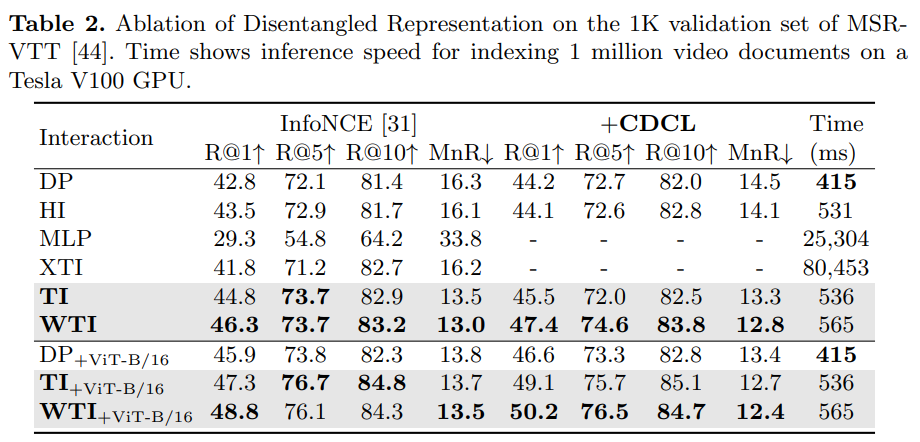
실험을 통해 WTI 와 CDCR 을 이용했을 때 성능향상을 보였고, 이를 통해 제안한 방법론의 구조가 효과적임을 알 수 있었습니다.
Retrieval results
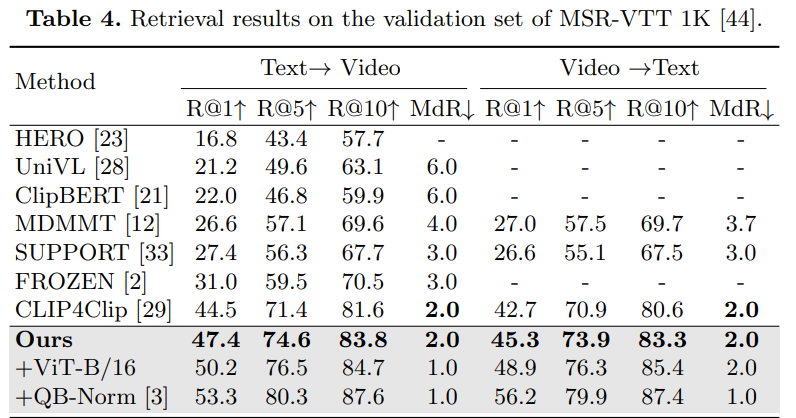
제안한 DRL 모델을 6개의 벤치마크에 대해 sota methods 와 비교하였습니다. 해당 논문의 본문에서는 MSR-VTT 에 대해 보여주고, Conclusion 뒤에 다른 데이터셋에 대해 보여줍니다. MSR-VTT 결과만 봐도 될 정도로… 다른 벤치마크들에서도 일관성 있게 전부 sota를 달성하였습니다.
Conclusion
본 논문에서 계속 강조하는 내용이 있는데, 바로 Text-Video Retrieval 을 할 때는 interaction mechanism 을 이해하는 것이 중요하다!! 라는 것입니다. 그리고 이러한 이해를 바탕으로 TVR 에 대한 두 가지 가정을 하고, 서로 다른 modality 인 text-video 의 interaction 에 영향을 끼치는 요소들에 대해 분석하여 이 가정들을 해결할 수 있는 DRL을 제안했습니다.
DRL 의 key components
- a Weighted Token-wise Interaction (WTI) : a macro-view 에서의 sequential mathing 문제 해결
- a Channel DeCorrelation Regularization (CDCR) : a micro view 에서의 feature redundancy 감소
결론적으로, DRL 은 sequential & hierarchical clues 를 잘 모델링하여 6가지의 TVR 벤치마크 데이터셋에 대해 sota 를 달성했습니다.
+) 이 논문을 통해 cross-modality 의 interaction design 이 중요하고, 앞으로 어떤 논문들을 읽으면서 TVR 에 대해 팔로우업을 해야할 지 방향을 알아갈 수 있었다는 게 가장 큰 수확이었던 것 같습니다. 앞서 CLIP 논문과 CLIP4Clip 논문을 리뷰 했었는데, DRL 에도 해당 논문들에서 가져와서 익숙한 내용들이 많이 나왔어서 (그리고 기억이 안 나는 부분도 있고 부족한 부분도 있는 것 같아서) 리뷰를 더 잘 써놔야겠다는 생각이 들었습니다 🙂
interaction mechanism에 대한 자세한 설명이 있을까요? 읽다보면 attention 느낌이 나는데, 텍스트와 비디오의 상호관계를 잘 나타내야 한다는 것 까지는 알겠는데, 어떻게 잘 나타내는지 느낌이 잘 살지 않네요. 그림 1도 이러한 interaction을 설명하기 위한 예시 같은데 추가적인 설명이 혹시 있을까 질문 남겨봅니다.
interaction mechanism 은 Text 와 Video 간의, 서로 연관이 어떻게 되는지에 대한, 즉, 상호작용 구조 그 자체를 나타내는 말입니다. 서로 다른 모달리티를 이용하는 text-to-retrieval 을 잘 하려면 text 랑 video 간의 interaction mechanism이 어떠한 구성요소들로 이루어지는지를 파악해야합니다. 본 논문에서는 interaction mechanism 을 파악하고 이 구조를 더 잘 나타내려면 그림1의 가정, 즉, intra-view 와 inter-view 에서의 문제를 해결해야 한다고 설명하였습니다. 그래서 이를 해결하도록, 즉, interaction mechanism 을 잘 파악하여 제안한 모델이 DRL 입니다.
리뷰 잘 읽었습니다. 캡스톤에서 저 방법론을 가지고 원복하고 있는 상황인데 디테일이 좀 부족한 것 같아 아쉬운 마음에 질문 몇가지 남깁니다.
1. 그림에서는 여섯가지의 Interaction이 있는데 왜 리뷰에는 두가지만 설명을 하고 있는지 궁금하네요. 찾아보니 논문에서 잘 설명을 해주고 있는 것 같은데…
2. 본 논문의 가정 중 첫번째인 비디오에 대한 설명은 비디오의 일부, 즉, local context 와 관련이 있을 것이다는 결국 비디오 전체를 설명하는 데 있어서 비디오의 일부만 봐도 괜찮다는 의미인가요? 저러한 관점의 근거는 논문에서 뭐라고 설명하나요?
리뷰가 전반적으로 논문의 내용을 단순 번역한 것만 같은 느낌이 들었습니다. 본인의 이해도를 바탕으로 한 설명이 빠져 있는 것 같아 리뷰를 읽는데 어려움을 느꼈습니다.
가령 예를들면, 각 Interaction을 설명하는 부분이나 Loss를 설명하는 부분 어떻게 보면 논문의 핵심이라고 볼 수 있는 부분이지만 모두 자세한 설명이 빠져있는 느낌을 받았습니다. 이 부분을 정말 제대로 이해를 했을까요..?
수식만 보고 바로 이해하는 사람은 논문 저자밖에 없죠… 그렇기 때문에 저도 리뷰할 때 어려운 수식에 대한 설명은 최대한 저의 이해도를 바탕으로 친절하게 설명하려고 노력하는 편입니다. 저의 지난 리뷰 중 (Action Unit Memory Network나 Background Click Supervision) 몇개를 찾아보면 어느정도(?) 느낌을 파악할 수 있다고 생각합니다..ㅋㅋ
같은 팀이기도 하고 최대한 빠르게 성장하기를 바라는 마음에서 댓글 남겨봅니다. 리뷰 잘 읽었습니다.
1. 6개의 interaction 이 있지만, 그 중 본 논문에서 제안하는 것은 ti 를 tvr 로 도입하는 것과 wti 라는 새로운 interaction 이라, 두 가지만 설명하였습니다. 이 논문에서 설명한 정도로 나머지 interaction 들을 파악하는 것보다, 해당 interaction 을 사용하는 논문을 직접 읽고 이해하는 것이 나을 것이라 생각했기에 앞으로 읽어볼 예정입니다.
2. 비디오의 일부, local context 를 설명하는 문장을 text query 로 던져도 해당 비디오가 검색되어야 한다는 의미입니다. 만약 비디오 전체 중 A 부분만으로 해당 비디오를 나타내면, 다른 B 부분을 설명하는 문장을 던졌을 때 검색되지 않을 것이기 때문에 비디오 전체를 설명하는 데 있어 비디오의 일부만 보는 것은 괜찮지 않습니다. 논문에서는 “common underlying assumptions behind TVR” 라고 설명하였고, TVR 에 사용하는 데이터셋을 살펴보았을 때에도 비디오의 일부를 설명하는 문장들이 있다는 것을 알 수 있습니다.
말씀해주신 리뷰 찾아보고 느낌 파악해보도록 하겠습니다! 조언 감사합니다 🙂