어김없이 돌아온 저의 Self-supervised depth estimation 논문리뷰가 되겠습니다. 이 논문 또한 3DV 논문이며 저희 논문의 비교군중 하나라 생각하시면 됩니다.
이 논문은 저희 논문과 유사한 면이 있다고 볼 수 있기도 하고 아니기도 한데요. 두가지 attention 방식을 통해서 Local detail과 long range dependencies를 강화하고자 했습니다. 그리고 각 attention 방식이 기존 방식하고는 달라서 신기한 …? 논문 입니다.
기존 CNN based U-Net 구조의 depth estimation 방법론들은 semantic 정보만을 가지고 예측을 하기 때문에 디테일한 부분이나 영상 전체의 구조적인 부분은 고려하지 못해 성능에 한계가 있다고 합니다. 따라서 이러한 문제를 극복하기 위해서 이 논문에서는 두가지 방법론을 제시합니다.
- Structure Perception Model (SPM)을 제안하며 이 모듈은 Self-Attention 방식(?) 으로 영상 정체의 structure 정보를 강화하기 위해서 제안 되었음.
- Details Emphasis Module (DEM) 을 제안하며 이 모듈은 이름 그래로 영상의 디테일한 정보를 강화해서 object boundary 등과 같은 영역의 성능을 끌어올림
Method
이 방법론 또한 기존에 제가 소개드린 depth estimation 방법론들과 같이 Monodepth2의 학습 방식을 그래도 사용하고 있기 떄문에 따로 Loss설명은 하지 않도록 하겠습니다.
(1) Overall architecture
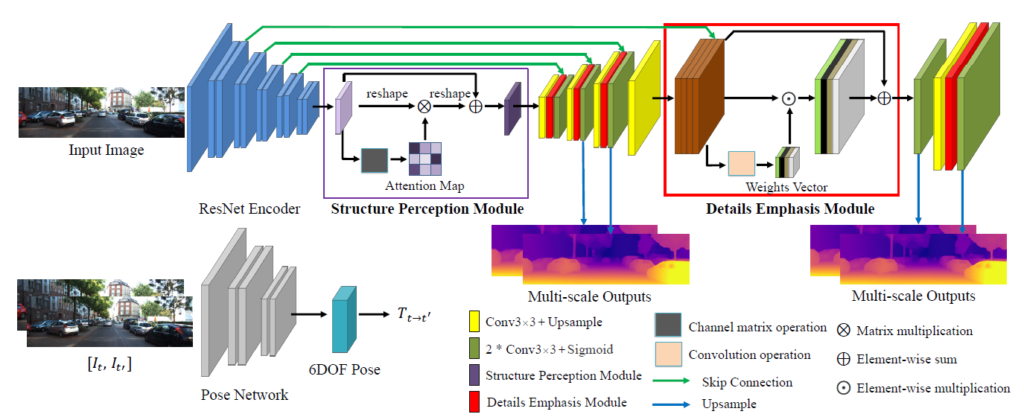
전체 아키택쳐는 그림 1과 같습니다. 보시면 DDV[1] 과 같이 encoder에서 나온 feature를 attention mechanism을 활용해서 channel 간의 관계성을 키웠다고 합니다.
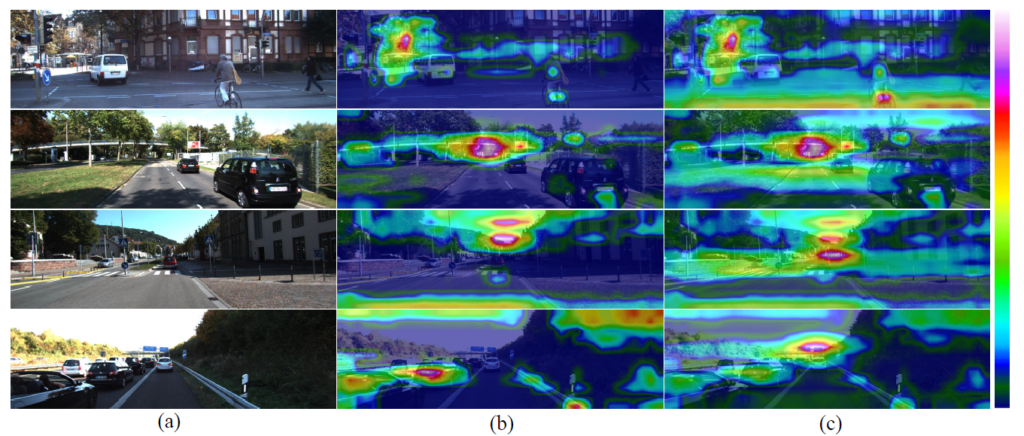
위 그림과 같이 SPM 모듈을 사용하지 않을 경우 feature들간에 상호 작용이 떨어지지만 (c)와 같이 SPM을 사용할 경우 feature 들간에 높은 상호 작용을 할 수 있다고 합니다.
그리고 skip connection하는데 있어서 low level feature 와 high level feature를 단순히 융합하는 것은 local detail을 뭉게는 결과를 초래하기 때문에 두 feature가 만나는 지점에 DPM 모듈을 추가해서 두 feature가 잘 융합될 수 있도록 설계했다고 합니다.
(2) SPM
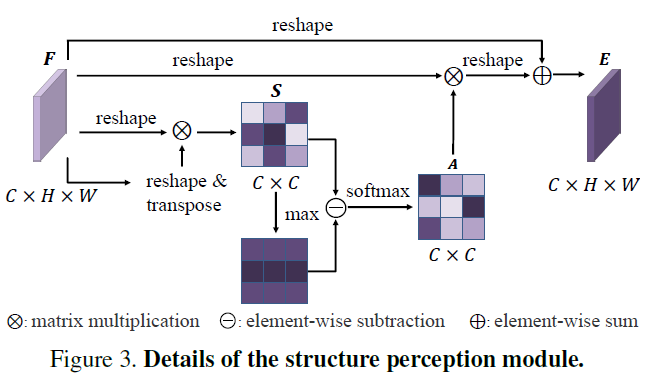
위 그림에 SPM의 자세한 모습이 포함되어 있습니다. 보면 기존 Self-attention 방식하고는 매우 다릅니다.
이 방법론에서 중요하게 본 부분은 channel간에 유사도를 강제로 remapping 해서 모든 channel들간에 관계도를 강화하는 것입니다. 그것을 하기 위해서 위 그림과 같이 feature를 먼저 CxN (N=HxW) 로 reshape 한 후 이 걸 transpose한 것과 matrix 곱을 해줍니다. 이렇게 하면 두 vector간의 similarity S 가 나오게 되며 이 Similarity 에서 값이 클경우 해당하는 channel들간에 유사도가 높다는 것을 의미합니다. 이런 상황에서 이 논문에서는 feature 간의 유사도가 클 경우 그걸 강제로 끊어 버리고 기존에 유사도가 떨어졌던 channel들과의 유사도를 강화시켜 다양한 유사도 관계를 만들어주는 모듈을 제안합니다.
저자가 원하는 의도에 맞게 끔 아래 식과 같이 similarity 에 max를 빼줘서 관계도를 변경 시켜줍니다.
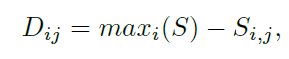
그리고 softmax를 취해줘서 attention 형식으로 변경한다음 feature와 곱해주고 residual하게 원래 feature와 더해주며 마무리 합니다.
(3) DPM
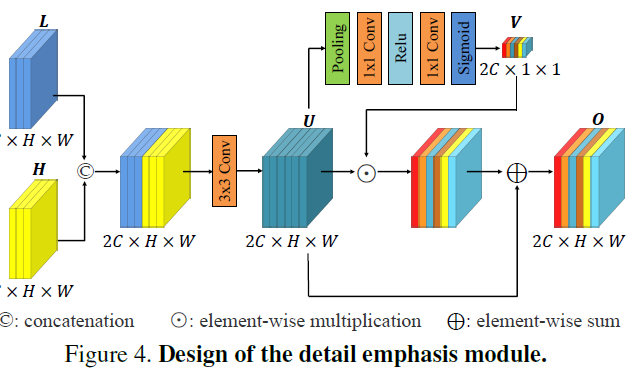
위에서 설명한대로 Low level feature와 high level feature가 skip connection 과정 중에 잘 융합되게 하기 위해서 위 그림과 같이 channel-wise attention을 추가했다고 합니다.
사실 이 모듈을 다른데서도 쓰이고 있어서 디테일한 설명은 생략하도록 하겠습니다.
Results
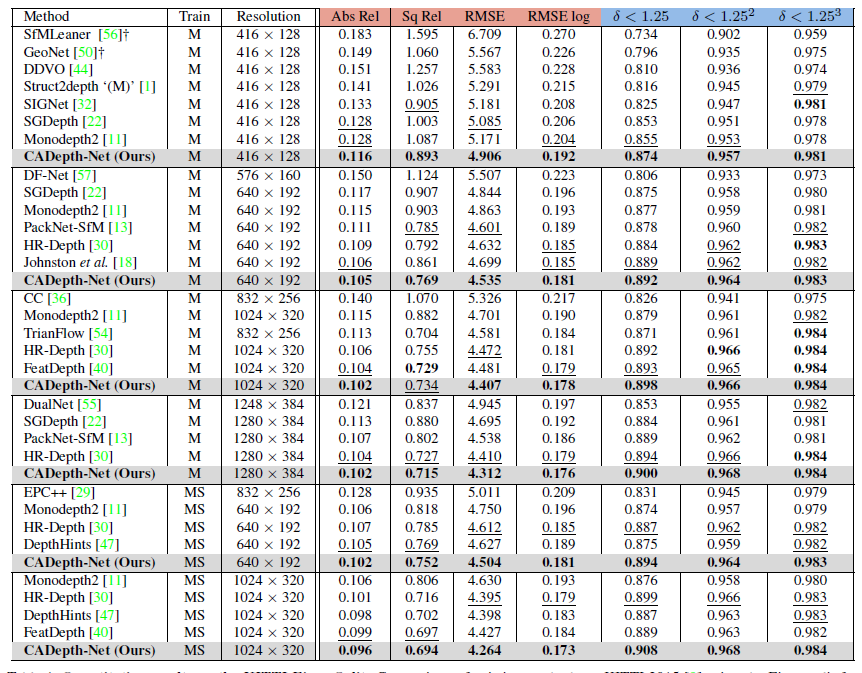
해상도 별로 성능 평가 입니다. 주목하셔야 될 부분ㄴ은 640 x 192 일 때 성능이며 이때 SoTA를 보여주는 것을 확인 할 수 있습니다. 뭐 이정도 성능이면 사실 DIFFNet이 없었더라면 어딜가던 SOTA라고 할 수 있는 정도라 보시면 됩니다. 그리고 나머지 평가에서도 좋은 결과를 보실 수 있습니다.
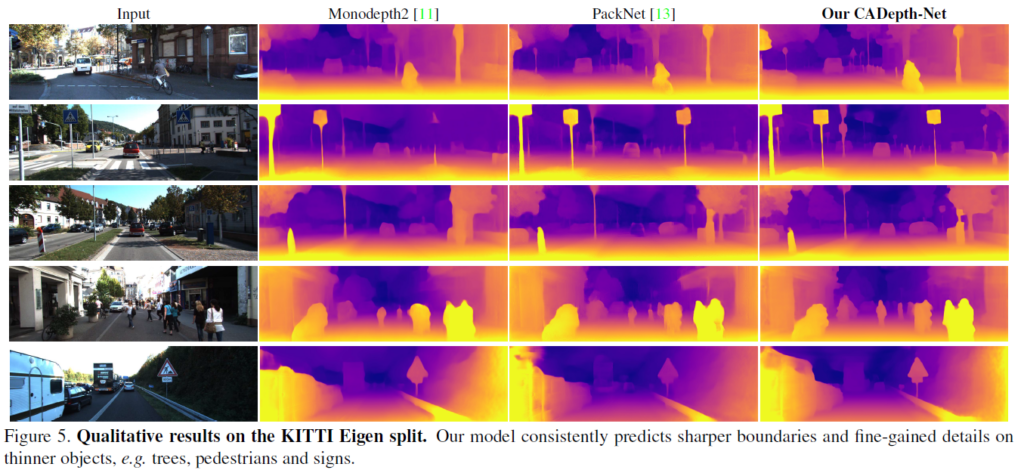
다음은 정성적 결과입니ㅏㄷ. 이 결과 비교를 DDV랑 하면 더욱 좋았을 것 같으나 뭐… 정성적 결과는 씹고뜯고 맛보고 즐기기 좋은 Monodepth2와 PackNet으로 하는게 국룰이라 봐주도록 하겠습니다. 그래도 음… 좀더 깔끔하게 이기는걸 보여주는게 좋았을 것 같다는 생각이 있습니다.

Ablation study 결과 입니다. 아마 reviewer 가 왜 resnet 18에서는 동작안하냐고 물어봐서 이렇게 Resnet18과 resnet50을 둘다 보인것 같지만 그래도 두 네트워크 모두에서 각 제안하는 방법론의 성능 부스팅을 확인할 수 있습니ㅏㄷ. 그래도 R50에서 더욱 뚜렷하게 보여서 R18을 넣기 정말 싫었을 것 같습니다.
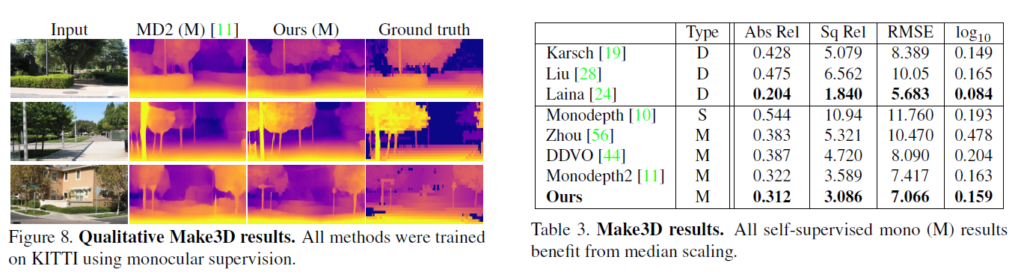
마지막으로는 국룰로 이겨주는 Make3D 결과 입니다. 비교군을 너무 예전 결과만 넣은 것 같아서 정말 SOTA가 맞는지 의심스럽네요.
Reference
[1] Self-supervised Monocular Trained Depth Estimation using Self-attention and Discrete Disparity Volume
리뷰 잘 읽었습니다.
작성해주신 리뷰의 내용으로 보았을 때는 DPM보다는 SPM이 더 핵심적이라고 판단되는데 SPM과 관련되어서 궁금한 점이 있어서 질문드리려고 합니다.
먼저 SPM 설명 중 유사도가 너무 높은 영역은 강제로 끊어버린다고 말씀해주셨습니다. 그림에서는 아마 max값을 가져다가 이를 element-wise subtraction 연산을 하여 제거가 된다는 것으로 보이는데, 여기서 채널간 유사도가 높은 결과는 어떠한 단점이 있길래 논문에서 제거하고자 한 것인가요?
그리고 max값으로 빼게 될 경우에는 결국 CxC의 similarity map의 scale 값 자체가 SIFT된 것이 아닌가요? similarity 에서 max 값으로 빼주었다고 해서 저자가 원하는 유사도가 높은 영역만을 제거하였다는 것이 어떻게 성립한다는 것인지 잘 모르겠습니다. 유사도가 일정 임계치를 넘어가면 그 영역들에 대해서만 제거해준다는 지 등 무언가 추가적인 기법들이 있어야만 할 것 같은데 말이죠.
max 유사도를 끊어주는 이유는 다양한 Channel들과의 유사도를 높이기 위함입니다. 유사도가 높은 channel을 그대로 유지하면 그 채널만 강조되기 때문에 강제로 연산해주는 것입니다ㅏ.
제가 설명을 잘못 써놨는데 Max- value라서 큰값은 작아지고 작은 값은 커지는 효과를 받습니다 .