저는 이번에도 Self-supervised learning 논문에 대해 리뷰해보려고 합니다. 벌써 4주 연속으로 리뷰를 self-supervised learning 중에서도 contrastive loss를 사용한 논문에 대해서만 리뷰하는 것 같네요. 다음주부터는 조금 더 최신 방법론들에 대해 찾아보고 읽어봐야겠다 생각이 들기도 합니다.
self-supervised learning에 contrastive learning을 방식을 사용한 이래로 지도학습과 거의 인접할 정도의 성능 향상을 가져왔습니다. 1) Data Augmentation 2) Contrastive loss를 사용하여 동일한 이미지에서 transformation된 두 이미지로부터 나온 representation은 contrastive loss를 통해 가깝게, 이 외의 다른 이미지로부터 나온 representation끼리는 멀게 위치하도록 학습하는 방식이 바로 contrastive loss 기반의 self-supervised learning이라느 것은 다들 익숙하실 겁니다. 제가 리뷰하려는 논문은 여기에 “code”를 이용한 cluster의 관점에서 문제를 해결하려고 하였습니다. 즉, clustering을 추가하여 성능을 향상시켰다고 이해하시면 좋을 것 같습니다.
Unsupervised Learning of Visual Features by Contrasting Cluster Assignments

Introduction
앞서 설명드린대로 기존의 contrastive learning은 image 에 대해 두 가지 augmentation을 적용한 새로운 이미지를 생성한 후, 각 이미지에 대한 representation 혹은 feature (본 논문에서는 view라고 표현)를 비교하는 방식으로 진행됩니다. 그리고 view끼리 비교하기 위해 타겟을 하나의 view 로 설정하여 학습하고, 학습이 진행되며 타겟을 변화시키는 online learning을 취하게 됩니다.
(여기서 online learning은 시작할 때 모든 정보를 입력하지 않은 상태로 input 값을 차례로 받아들이면서 학습하는 방식이고, 반대로 offline learning은 풀고자 하는 모든 데이터를 받은 상태에서 학습을 시작할 수 있는 방식입니다.)
이렇게 contrastive learning을 진행하다보면 같은 이미지로부터 만들어진 representation pair 끼리는 유사도를 높이고, 다른 이미지로부터 만들어진 representation pair끼리는 유사도를 낮추는 방식으로 진행됩니다. 이 때 이론 상 하나의 이미지를 제외한 전체 데이터셋에 포함하는 이미지끼리 비교해야하나, 실제 적용하기에는 어려움이 따르므로 큰 배치 사이즈를 사용하여 배치 안에 포함된 이미지끼리 비교하여 contrastive loss를 구하고 학습을 진행하게 됩니다. 그러나 이러한 방법은 큰 batch size로 학습하여 많은 views끼리 비교를 수행해야지 좋은 representation을 배운다는 한계가 있었습니다. 이 외에도 memory bank, 혹은 momentum encoer가 필요하지 마련이었습니다.
따라서 본 논문에서 제안하는 Swapping Assignments between multiple Views of the same image (SwAV)는 clustering 기법으로 대표적인 클러스터 representation을 지정하고, 이를 통해 더 많은 군집끼리 비교하여, 더 큰 비교가 가능하도록 학습 방식을 제안하였습니다. 즉, 개별 images 별 feature가 아닌 similar한 feature를 group으로 할당하여 구별하는 clustering 기법을 사용하였습니다. 이 때, 일반적인 클러스터링 방식은 online learning이 아니기에, self-learning에 적합하도록 SwAV에서는 온라인 학습 기반의 클러스터링 방식을 제안합니다. 추가로 multi-crop이라는 새로운 augmentation 기법으로 한 장의 이미지 내에서 다양한 크기의 multi-crop을 생성하여 성능 향상으 가져왔다고 리포팅하기도 합니다.
Method
먼저 본 모델의 학습 방식에 대해 이야기 후, 용어를 정리한 뒤 방법들에 대해 설명드리겠습니다. 아래 그림을 통해 순서대로 따라가면 이해하는데 도움이 될 듯 합니다.
하나의 이미지X에 대해 서로 다른 두 개의 augmentation을 적용하여 두 개의 views X_1, X_2를 생성합니다. 이 후, 변환된 이미지에 대한 representation(feature)을 추출하는 각각의 인코더 f_\theta에 태웁니다. 여기서 나온 output인 feature가 Z_1, Z_2가 됩니다. (저자는 이 feature vector를 unit shpere로 projection 시킨 것이라고 표현합니다. 이건 아래 애니메이션을 보면 이해가 좋을 듯 합니다.) 이후, K개의 학습가능한 prototype인 C[latex]로 [latex]Z_1, Z_2를 ㅁ핑시켜 feature를 code Q_1, Q_2로 계산합니다. (code는 cluster assignment입니다) 다시 말해, 비슷한 feature끼리는 비슷한 code로 매핑될 수 있도록 추가적인 C 학습 파라미터인 prototype을 구하는 것이죠.
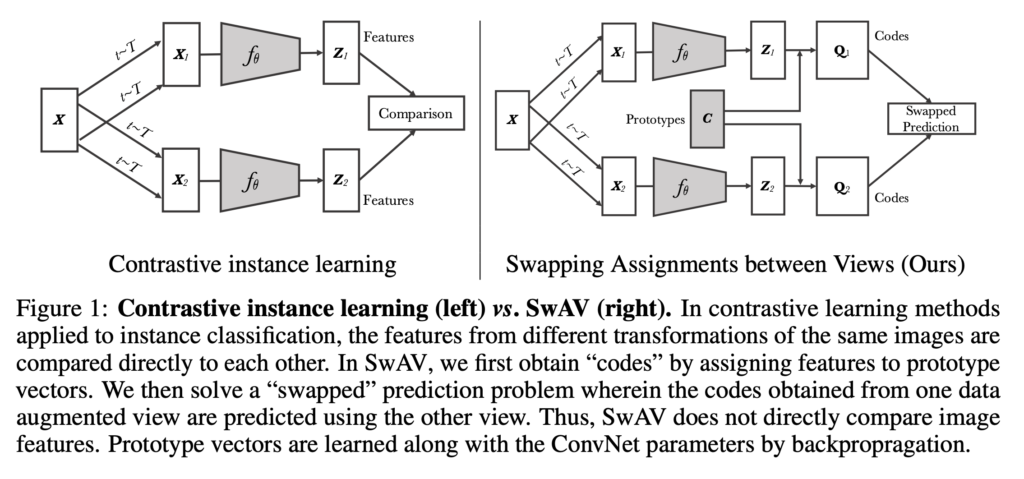
기존의 클러스터링 학습은 offline(풀고자 하는 모든 데이터를 받은 상태에서 학습을 시작)으로 진행된다고 하였는데요 왜 그럴까요? 보통 클러스터링 방식은 1) training 2) cluster assignment 단계로 구성됩니다. 1)을 통해 데이터를 잘 군집화할 수 있는 feature로 학습하는 단계와 2) 과정은 대표적인 cluster를 할당하는 단계이죠. 데이터가 추가되면 이미 선정된 cluster 혹은 feature가 제대로 추출되지 못할 경우가 있기에, 처음부터 다시 학습하고 cluster를 할당해야합니다.
다시 말해, 기존 클러스터링은 모든 데이터에 대해 feature 를 매번 새로 추출해야하는 과정을 거쳐야하므로, 데이터가 들어오면서 매번 feature의 변화를 업데이트하는 online 학습에는 적합하지 않습니다. 따라서 본 논문은 online learning이 가능하도록, 같은 이미지에서 augmented 된 이미지로부터 code (cluster 라고 이해하시면 됩니다.) 의 consistency를 enforce하는 방향으로 학습됩니다. 즉, code 자체를 타겟으로 삼지 않고 같은 이미지로부터 파생된 이미지들이 할당된 code 가 일관되도록 하자는 것이죠.
일반적인 clustering 기법은 전체 image dataset의 image features를 clustering하고 cluster code(clustering numbering)을 부여하는 방식인 offline 방식입니다. 여기서 code는 cluster assignment를 의미합니다. 이러한 방법은 학습을 진행할때 feature를 업데이트하기 위해, 전체 image dataset을 반복적으로 input하기 때문에 target이 계속 변하는 online 학습에는 시간적 문제때문에 practical하지 않습니다. 따라서, 논문에서는 cluster code 자체를 target으로 간주하지 않고 image로부터 생성된 augmented views로 부터 cluster code를 할당하고 동일한 image로 부터 생성된 다른 augmented views로부터 cluster code를 예측하는 방법을 제안하였습니다.
다시 말해, 같은 image로부터 2개의 다른 augmentation view features인 z_t와 z_s가 주어졌을때, K prototypes c_1, c_2, ... c_Kset에 일치시켜 codes q_t와 q_s를 계산합니다. 이후, 아래와 같은 loss function을 사용하여 “swapped” prediction problem을 제안합니다.

상단 Loss 수식을 보면 feature인 z_t, z_s를 직접적으로 비교하지 않고 code인 q_t, q_s를 통해 비교합니다.z_t, z_s가 비슷한 정보를 가지고 있다면 q_t를 z_s로 예측하는 것이 가능할 것이다라는 아이디어에서 나왔다고 하빈다.
SwAV의 핵심은 프로타타입 벡터와 code를 훈련과정 동안 online 방식으로 업데이트 하는 데 있습니다. 그렇다면 위의 총 loss함수에서 l(zt,qs), l(zt,qs)[\latex]은 다음과 같이 정의될 수 있는데요. [latex]l(zt,qs)는 feature zt 로부터 다른 변환 방식으로 augmentation된 code qs를 예측하는 것으로qs와 zt, C로부터 얻은 softmax code 확률 간의 cross entropy loss로 정의할 수 있습니다. (Equation 2, τ는 temperature 파라미터)
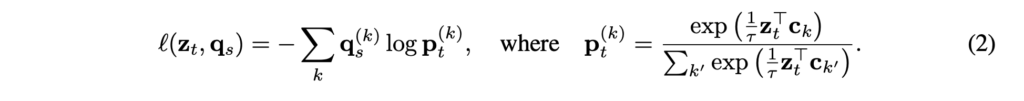
Implementation details of SwAV training
학습 과정에 대해 논문에서 제공하는 수도코드입니다.
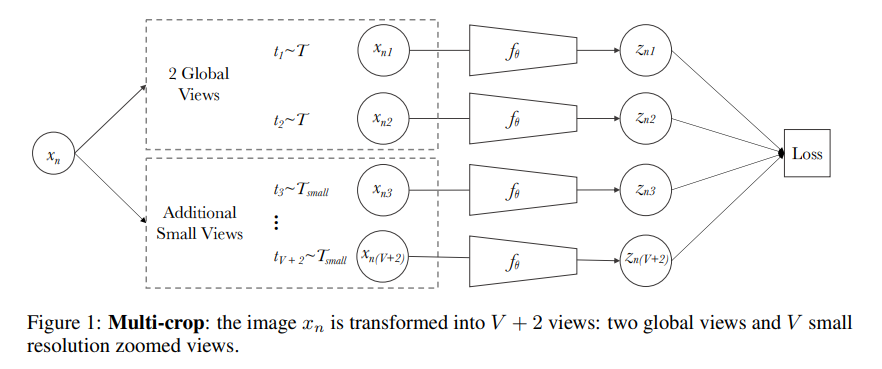
Data augmentation used in SwAV
SwAV는 2개의 일반적인 random crop/resize, V개의 low resolution random crop/resize, 총 V+2개의 augmentation을 사용합니다. 먼저 2개의 random crop/resize는 RandomResizedCrop 함수를 사용하며 가로로 폭이 좁게 s=(0,14,1)s=(0,14,1)로 랜덤하게 crop 한 후 224x224 의 크기로 리사이즈 합니다. V개의 추가적인 augmentation은 s=(0.05,0.14)s=(0.05,0.14)로 저해상도 random crop 한 후 96x96의 크기로 리사이즈합니다. 이후 각 augmentation에 랜덤한 horizontal flips/color distortion/Gaussian blur를 적용합니다.
Experiments
SwAV 의 기본 실험 세팅은 SimCLR 와 거의 비슷합니다. 배치 사이즈는 4096을 사용하고 τ=0.1τ=0.1, ϵ=0.05ϵ=0.05를 사용합니다. 또한, LARS 옵티마이저를 사용하며 SimCLR 처럼 learning rate를 초반에 4.8로 높게 선택하고 일정 epoch 이후 cosine learning rate decay에 의해 감소시킵니다. 마지막으로 2-layer MLP projection head를 사용합니다.
실험 전체적으로는 ResNet-50 모델을 400 epoch 만큼 훈련시키며 2개의 일반적인 random crop (160), 4개의 추가적인 저해상도 random crop (96), 총 6개의 augmentation을 사용합니다. 또한 code (cluster)를 할당하는 프로토타입의 차원 K는 차원에 따른 성능이 거의 없었고 지나치게 증가시키면 Sinkhorn 알고리즘 계산 시간이 성능 이득에 비해 오래 걸리므로 3000으로 설정합니다.

Evaluating the unsupervised features on ImageNet
ResNet-50 모델에 대해 linear evalutaion/semi-supervised 실험을 수행합니다. 먼저 고정된 representation에 적용하는 linear evaluation 에서 SOTA의 성능을 거두었으며, semi-supervised learning 에서 또한 독보적인 성능을 보였습니다. 다른 self-supervised learning 모델과 마찬가지로 SwAV 또한 모델이 커질수록, 오래 훈련할수록 성능이 증가합니다.

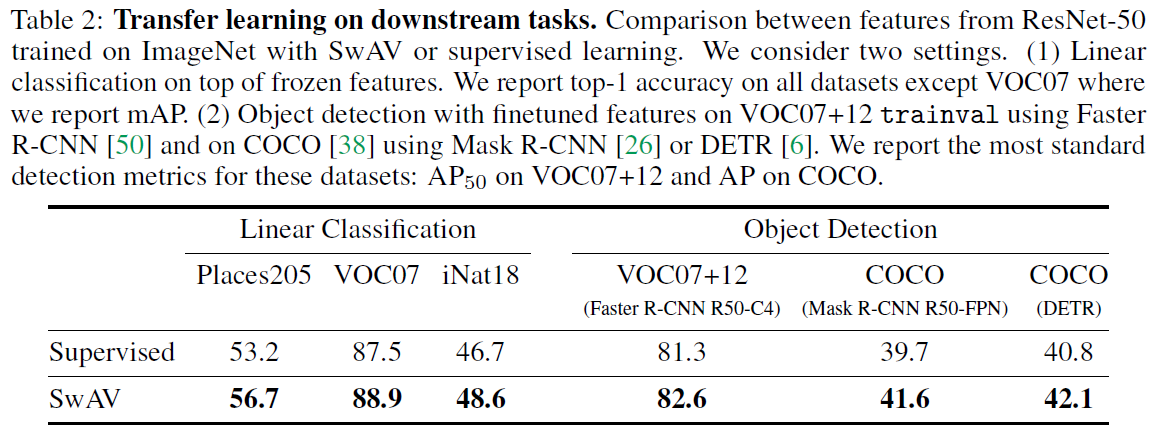
Transferring unsupervised features to downstream tasks
다음으로 ImageNet으로 pretrain 시킨 representation을 이용하여 다른 데이터셋/태스크에 적용하는 transfer learning을 수행합니다. 다른 데이터셋에 linear classification을 적용한 경우 supervised 에 비해서도 높은 성능을 거두었고 object detection task에서도 기존의 supervised를 뛰어넘었습니다.
점차 contrastive leanring에서 벗어나려는 시도가 등장하고 있는 것 같습니다. 앞으로는 새로운 방법론의 논문을 읽어서 최신 흐름을 알아봐야할 것 같습니다