안녕하세요 이번에 제가 다루게된 논문은 LabelFusion이라고 불리는 논문입니다.
해당 논문은 3D 라벨링을 하는 파이프라인을 다룬 논문 2018년 ICRA에 발표된 논문입니다. 가동원전 데이터셋 촬영에 대한 고민을 하는 과정에서 발견하고 읽게되었습니다.
결과론적으로 논문에서 취득하고자하는 데이터셋은 Depth정보와 RGB이미지로 구성된 RGB-D 데이터셋이며, 각각의 RGB-D이미지쌍은 Segmentation 라벨링정보와 6D 포즈에 대한 정보를 포함합니다.
2D 이미지에 2D bbox를 annotation하는 것과는 다르게 3D에서의 6D pose를 annotation하기 위해서는 복잡한 과정이 필요합니다. 그런데 이러한 부분들을 semi-automation으로 설계하여 2명의 annotator만으로도 2일만에 수백만장의 RGB-D 이미지를 annotation 할 수 있었다고 합니다.
그렇다면 2D 이미지와 비교했을때, 3D에서 6D자세를 annotation하는 것은 왜 어려울까요? 일반적으로 6D자세를 annotation하기 위해서는 3D CAD 모델이 필요합니다. 그리고 해당 3D CAD모델과 RGB-D 이미지를 이용해서 6D자세를 라벨링합니다. 구체적으로 먼저 RGB-D 정보를 이용해서 포인트클라우드로 나타낼 수 있고, 해당 포인트클라우드상에 3D 모델을 랜더링해서 3D모델과 포인트클라우드를 manual하게 align을 맞추는 방식으로 6D자세를 annotation해줍니다. 이때 6D자세는 카메라로부터 물체까지의 상대적인 pose로 Rotation matrix와 translation vector로 구성됩니다.
위에서 설명한 것처럼 6D pose를 라벨링하기 위해서는 2D BBox에 비해서 훨씬 많은 노력이 필요합니다. 그리고 일반적으로 6D Pose estimation task에서는 segmentation 정보를 요하는데, 아시다시피 2D segmentation을 하는데는 마찬가지로 labour cost가 많이 발생합니다.
그렇다면 논문에선 이러한 부분들을 어떤식으로 개선하였을까요?

먼저 위에 파이프라인을 보시면 raw RGB-D 데이터와 object mesh를 인풋으로 사용합니다. 그리고 최종적인 결과물은 segmentation 라벨과 6D Pose입니다. 보통 이러한 과정을 사람이 하려면 일일히 segmentation 정보를 라벨링해야하고, 6D pose를 직접 3D상에서 alignment를 맞추어가며 라벨링해야합니다. 하지만, 제안하는 파이프라인에서는 단순히 3개의 점만을 이용해서 rough하게 pose를 부여하면 나머지는 모두 automatic하게 처리가 가능합니다.
설명할것이 많은데 하나씩 천천히 설명해보겠습니다.
먼저 라벨링을 하기 위해서는 reconstruction이란 작업을 해주어야합니다. Reconstruction에는 기존에 존재하는 다양한 방법이 있는데 그중에서 camera tracking을 제공하는 방법은 아무거나 사용해도 해당 논문에서 제안하는 파이프라인에 사용이 가능하며, 해당논문에서는 ElasticFusion이라고 불리는 방법론을 사용하였습니다.
이게 무슨소리냐… 데이터셋을 촬영할때는 한개의 scene마다 multiple frames을 촬영합니다. 그때 한개의 scene에 해당하는 frames는 카메라의 viewpoint를 바꾸어가며 촬영을하는데, 보통 scene에서 workspace가 있으면 workspace위에 카메라를 위치하고 위에서 아래로 내려다보는 view형태로 촬영합니다. 그리고 viewpoint를 회전시켜가며 한개의 scene에 대해서 다양한 각도로 촬영을하며, 이를 통해 reconstruction을 하게됩니다. 그리고 해당 reconstructed된 scene을 이용해서 라벨링을 하는데 사용합니다.
다음 스텝에서는 reconstructed된 scene에서의 물체와 object mesh에서의 물체에서 corresponding하는 점을 3개찍어줍니다. object mesh는 쉽게말하면 3D CAD모델과 흡사합니다. 근데 3D CAD모델은 사람이 직접 만드는 반면에 해당 논문에서 이야기하는 object mesh는 3D scanner를 이용해서 만든 obj파일입니다. 논문저자가 해당 데이터셋 취득 파이프라인을 공개하면서 직접 취득한 데이터셋또한 공개를 하였는데, 그 데이터셋은 총 12개의 클래스로 구성되어있으며, 각 class마다 object mesh 취득방법을 달리하였다고합니다. 4개는 YCB-Video에서 사용한 obj파일을 그대로 사용하였고, 나머지는 여러종류의 Scanner기반으로 취득한걸로 보여지는데, 이러한 scanner없이 obj mesh파일을 만들 수 있을지는 사실 의문입니다. 그 다음 3개 점을 이용해서 rough 하게 6D pose를 구하고 ICP알고리즘으로 해당 pose를 refinement하는 방식으로 최종 6D Pose를 구해줍니다.
6D Pose를 구했다는것은 Rotation matrix하고 translation vector를 구했다는 의미입니다. 이후에 해당 transform정보와 카메라 파라미터를 이용해서 3D 좌표상에 있는 object를 다시 2D로 reprojection하는 방식을 취해서 2D segmentation정보를 얻어줍니다.
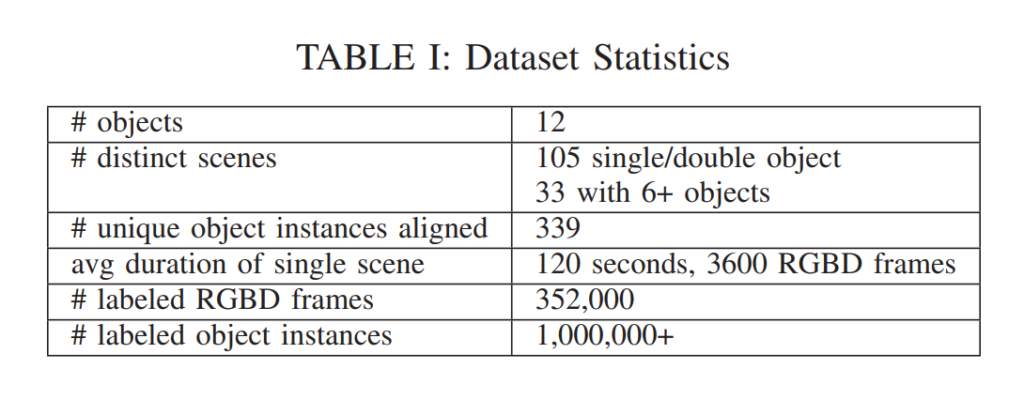
그러한 과정을 거쳐서 직접 데이터셋을 취득하였고, 12개의 class로 구성하였으며, 위와 같이 100만개가 넘는 instance에 대해서 2일만에 2명이서 annotation을 다했다고 합니다. 일반적인 2D annotation도 아니고 3D annotation을 빠르게 할 수 있었던 이유는 바로 라벨링을하는 파이프라인에서 사람이 개입되는 부분이라고는 3개의 corresponding하는 점을 찍는 부분 뿐이기 때문입니다.

직접 취득한 데이터셋은 위와같이 cluttered object도 포함하고, low light, motion blur 등등 다양한 경우를 추가하였다고 합니다. 그리고 기존에는 라벨링 코스트가 너무 커서 못하던 다양한 케이스들을 고려할 수 있었다고 합니다.
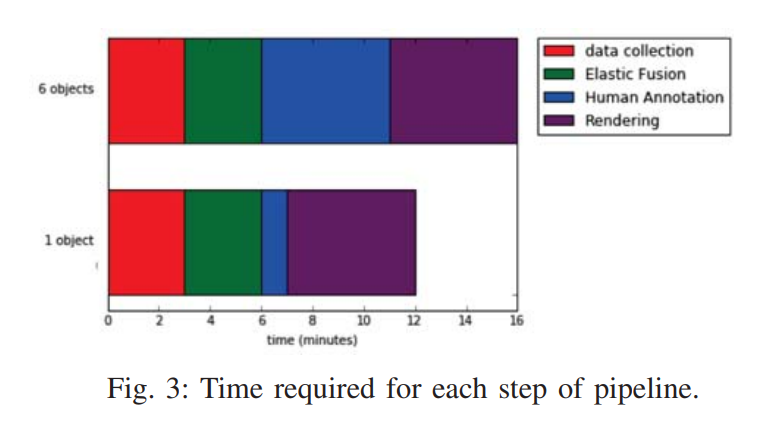
그래서실제로 라벨링을하는데 어느정도 시간이 드는지 측정한 결과라고합니다.

위 사진은 과연 automatic한 방식으로 라벨링하여도 segmenation 정보가 제대로 나오나 확인해본 정성적 결과입니다. 캘파람, depth정보오차, 6D pose 오차, object mesh 오차 등이 누적되서 사람이 manual하게 한것과 비교했을때 오차가 있을까 우려가 되기도 하였는데 생각보다 많이 정확한거 같습니다. 사실상 여러종류의 오차가 누적되는건 사실이나 각각의 오차가 크지않을 것으로 생각되기에 위와같은 정성적인 결과가 체리픽은 아니라고 생각합니다. 그리고 실제로 사용한 코드및 취득한 데이터셋을 공개하였습니다. (아직 제가 확인은 못해봤습니다.)
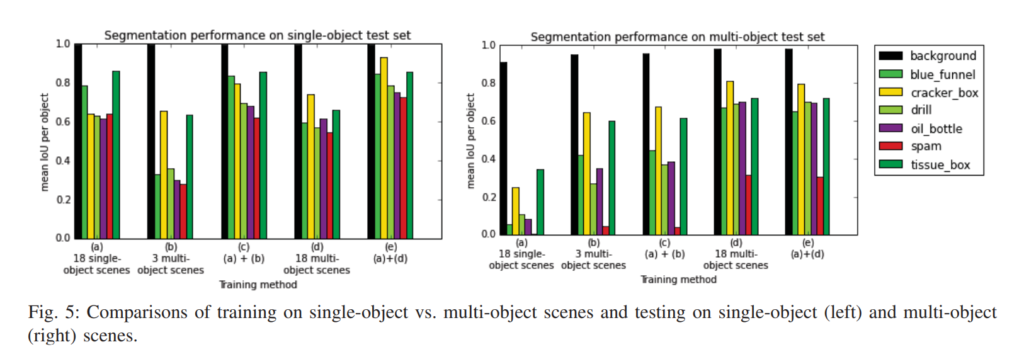

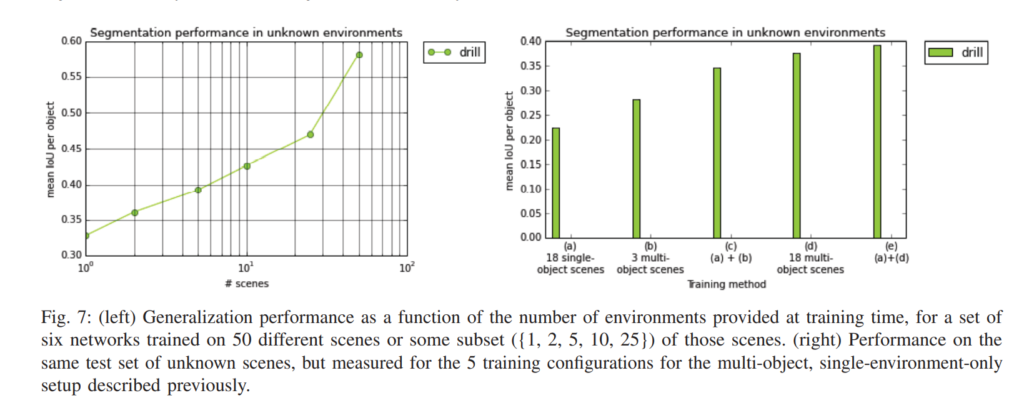
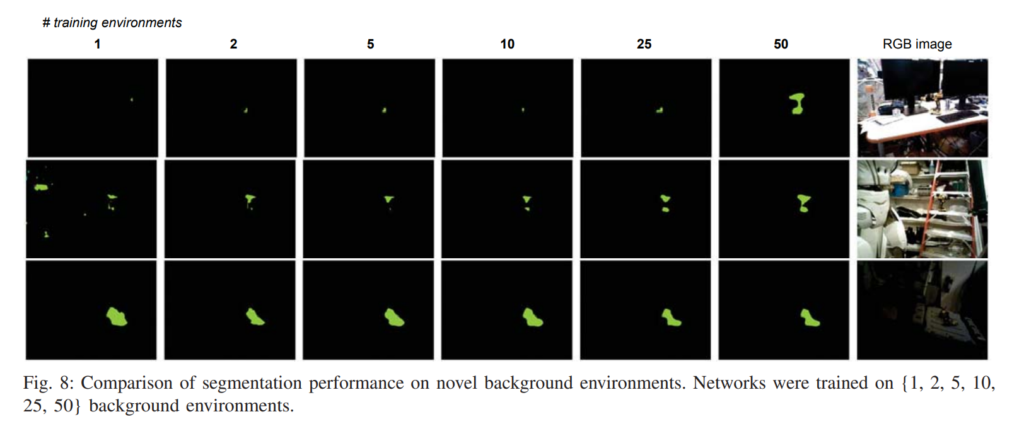
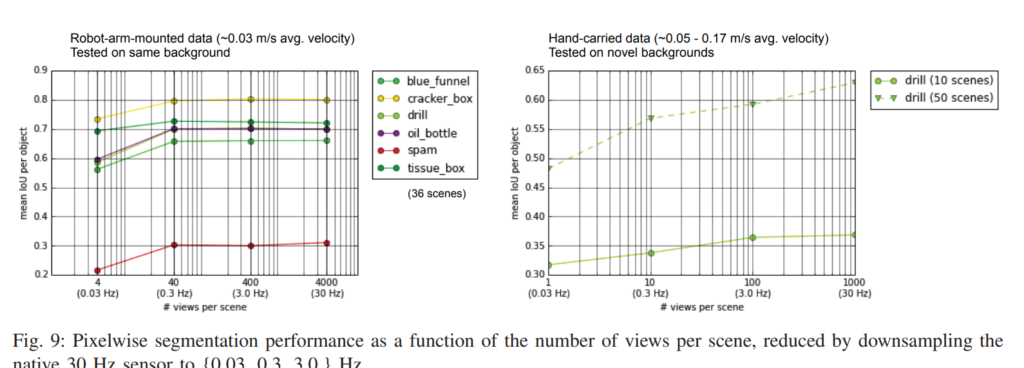
위의 결과들은 실제로 semi-automatic하게 취득한 데이터셋에서 segmentation 성능을 뽑아본 모습입니다.
후기
6D pose를 어떤식으로 라벨링해야하는 고민에서 읽게된 논문이며 많은 도움이 되었습니다. 해당논문에서 제시하는 데이터셋 라벨링 파이프라인은 코드도 제공하고, GUI도 지원하며 현재까지도 많이 사용되는 방법인거 같습니다. 실제로 BOP챌린지에서 사용되는 벤치마크 데이터셋중 한개인 T-LESS도 해당논문에서 제안하는 파이프라인과 비슷한 방법으로 취득된거 같습니다.
그런데 해당 방법론을 제공하려면 결국에는 object mesh파일이 있어야하는데 해당 저자들이 제안하는 방법은 object mesh파일을 3D scanner를 이용해서 얻습니다. 그게 아니라면 3D modeling을 해야한단 소리인데 3D modeling이나 3D scanner장비없이 object mesh파일을 만드는 방법이 있는지 아직 잘 모르겠습니다.
좋은 리뷰 감사합니다. 제가 6D pose를 잘 몰라서 질문을 드립니다. 6D pose 라벨링을 할때 어떠한 값들로 구성이 되어있는지 궁금한데 알려주실 수 있나요?
3×3 Rotation matrix와 3×1 Translation vector 이며, 카메라와의 상대적인 R|t관계를 의미합니다.
좋은 리뷰 감사합니다.
결국 본 논문은 데이터셋에 대한 논문인가요? 그리고 “일반적으로 6D자세를 annotation하기 위해서는 3D CAD 모델이 필요하다고 하셨느데” CAD 모델은 어떻게 만들어지는지 … 궁금합니다.. 실측을 하여 직접 하나하나 설계를 하는 것인지.. 그래서 6D pose에 대한 어노테이션이 쉽지 않은것인지요 감사합니다
네 3D CAD모델은 실측을하여 만들어야 하며, 6DoF pose annotation이 힘든 이유는 이러한 CAD모델이 있다고 하더라도 3차원상에서 Alignment를 맞추어서 annotation하는 과정에서의 코스트가 크기 때문입니다.
그리고 본 논문은 데이터셋을 취득하는 파이프라인에 대한 논문이며, 자신들이 제안하는 파이프라인으로 취득한 데이터셋을 공개하기도 하였습니다.