
우선, 요즘 MSR-VTT 데이터셋을 이용하는 원복 실험을 하는 중인데, text-clip retrieval 의 경우 해당 논문에서 사용한 방법으로 evaluate 를 하길래 읽게 되었습니다. (이 내용이 핵심은 아닙니다!)
본 논문은 서로 다른 모달리티의 sequence 데이터 간의 Semantic Similarity 를 계산할 수 있는, JSFusion (Joint Sequence Fusion) 이라는 이름의 방법론을 제안합니다. 결과적으로 해당 방법론을 사용했을 때, Multimodal Retrieval 에 대해서는 sota, Video QA 에 대해서는 sota에 대적할만한 성능을 냈습니다.
Video Captioning, Video Question and Answerning, Video retrieval for a language query 등, Video-language 데이터를 사용하는 task를 해결하기 위해서는 텍스트(word sequences)와 비디오(frame sequences) 간의 ‘a hidden joint representation’ 을 학습하는 것이 중요합니다. 이렇게 학습을 통해 각 모달리티로부터 representation 을 잘 얻어서, 이 를 이용하여 둘 간의 Semantic 한 similarity 를 잘 계산하는 것이 해당 task 에 핵심이니까요.
이 학습을 위해 이전 연구에서 사용한 방법들을 살짝 짚고 넘어가겠습니다.
Video classification : 모델을 학습하여 비디오로부터 얻은 representation 을 이용하여 특정 class 로 분류할 수 있도록 하는 방식입니다. 그러나 이 경우에는 class 의 수가 정해져 있었고, ‘분류’를 위해 학습을 진행하였기에 보다 video-language 의 복잡한 task 를 위한 representation 을 학습하는 데는 한계가 있었습니다.
Multimodal semantic embedding : Deep representation learning 이 발전함에 따라, 서로 다른 모달의 데이터를 같은 차원의 공간에 embedding 하는 방법론이 등장하였습니다. 그러나 기존 방법론들은 visual 정보와 language 정보를 각각 하나의 vector 로 embed 시켰기 때문에, ‘video’ 와 ‘natural sentence’ 를 이용해야하는 task 에서는 한계가 있었습니다. 서로 다른 ‘sequence’ 모달리티로부터 각각 vector 하나씩만을 가져왔으니까, ‘Hierarchical matching(계층적 매칭)’, 즉, sequence 데이터의 부분 부분들 간의 다양한 관계를 알아내어 매칭시키는 것에는 한계가 있었던 것이죠.
이후 이러한 Hierearchical structure learning 을 위한 방법론이 등장하기도 했었지만, Groundtruth parse tree 나 segmentation label 이 필요한 방법론이라는 한계가 있었다고 합니다.
JSFusion (Joint Sequence Fusion) Model
본 논문에서 제안하는 JSFusion 모델은, attention mechanism 을 사용하여 bottom-up recursive matches 를 학습해서, multimodal sequence data 의 pairs 간의 semantic similarity 를 측정할 수 있도록 합니다. 이때 모델의 핵심 구성요소로는 크게 두 가지, Joint Semantic Tensor(JST) 과 Convolution Hierarchical Decoder(CHD) 가 있습니다. 먼저 전처리를 어떻게 하는 지 살펴보고, 방금 언급한 구성요소에 대해 설명해보도록 하겠습니다.
Preprocessing
Sentence representation
- Sentence → Word : 사용하는 데이터셋에서 3번 이상 등장하는 단어들을 수집하여 a vocabularty dictionary V 를 정의합니다. 그리고, V 에 있는 단어가 아니면 제거하여 word level 데이터로 encode 합니다.
- Word → Word embeddings : GloVe 라는 논문에서 제안한 pretrained glove.24B.300d 라는 모델로부터 얻은 word embedding matrix E \in R^{d \times |V|} (d = 300) 를 이용해 임베딩을 얻습니다. 이때 d 는 word embedding dimension 입니다. 즉, voca dictionary 에 있는 각 word 가 300 차원의 vector 로 표현된 것입니다.
- output : \{w_m\}^{M}_{m=1} (M = sentence 에 포함되어 있는 word 의 갯수, M_max = 40)
즉, 이러한 방법을 통해, 하나의 sentence 가, 하나의 representation 으로 표현된 것입니다. 이때 m 은 sentence 에서의 word 의 index 입니다. 만약 문장이 너무 길면 문장에서 m > M_{max} 인 단어를 버리고 사용했다고 하는데, 이 이유는 M_{max} = 40 이상의 길이의 sentence 를 이용해 training 하더라도, 0.07% 정도의 적은 성능 향상밖에 없었기 때문이라고 합니다.
Video representation
- Sampling : fps = 5 를 사용하여, frame redundancy 와 inforamtion loss 간의 tradeoff 관계를 고려하여 비디오로부터 프레임을 샘플링하였습니다.
- Visual description : ImageNet pretrained ResNet-152 의 pool5 layer 에서 R^{2047} 의 feature map 을 추출합니다.
- Audial description: VGGish + PCA 를 사용하여, R^{128} 의 feature map 을 추출합니다.
- Video descriptor : 비디오에 있는 frame 의 갯수가 N개라고 할 때, video descriptor 는 앞서 추출한 두 feature 를 concat 하여, \{v_n\}^{N}_{n=1} \in R^{2156 \times N} 를 사용합니다. ( N_max = 40 )
즉, 하나의 video 가 하나의 representation 으로 표현된 것입니다. video frame 의 index 는 n 이고, 마찬가지의 이유로 N_max 개 이하의 frame 을 사용하는데, 이때는 sentence 처럼 초과되는 부분을 버리는게 아니라, uniform 하게 샘플링 하도록, 즉, equidistant frames 를 선택하여 사용했습니다.
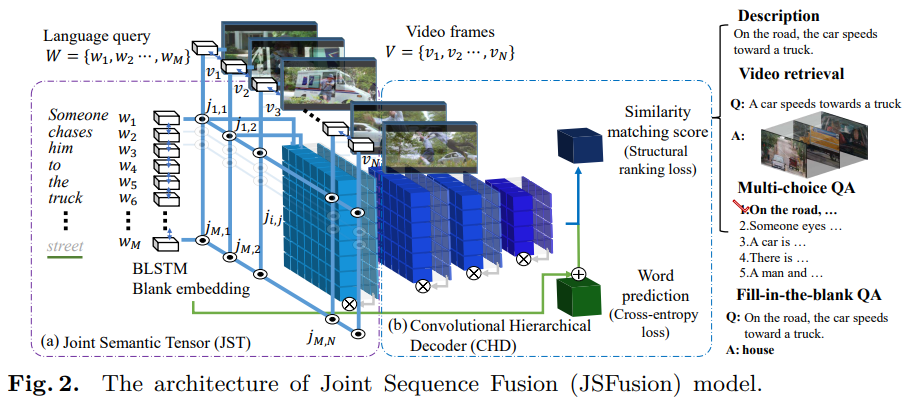
Joint Semantic Tensor (JST)
앞서 preprocessing 과정을 통해 얻은 Sentence-Video representation 을 이용하여, JST 라는 3D tensor 를 만듭니다.
Sequence Encoder : Sentence-Video representation → encoder representation
- word sequence encoder (1) : bidirctional LSTM network (BLSTM) 의 forward hidden states
- word sequence encoder (2) : bidirctional LSTM network (BLSTM) 의 backward hidden states
- video sequence(frames) encoder : CNN
Word domain : x_{w,t} = [h^{f}_{w,t}, h^b_{w,t}, w_t ] (h^b_t , h^f_t \in R^{512}
Visual domain : x_{v,t} = [h^{cnn}_{v,t}, v_t ] (h^{cnn} \in R^{2048}
- Attention-based joint embedding : output of sequence encoder → 3D vector JST
3D vector에 Self-gating mechanism 을 적용시켜서, 모든 pairwise embedding 간의 fine-grained 한 match 를 찾을 수 있도록 합니다.
fully-connceted (dense) layer (Dk) , Convolution layer (Convk), 그리고 attention weights a, represenation r 을 이용해서, 앞서 얻은 sequential 한 feature 간의 joint embedding 을 나타내는 JST 를 얻습니다.
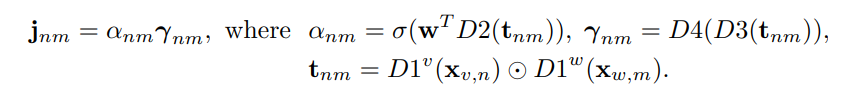
이때 (.) 는 hadamard product 이고, sigma 는 sigmoid functino 입니다.
그리고 학습 과정을 통해, w 라는 parameter 를 학습합니다.
encoder 의 output 이 각 frame 주변, 즉, 이웃비디오의 feature 를 나타내기 때문에, 어텐션 a 는 가능한 pairs 중 어떤 것에 더 weight 를 줘야할 지 학습하게 됩니다.
이 과정을 통해, 3D tensor 인 J = [j_n, m]^{n=1:N_{max}}_{m=1:M_{max}} 를 얻습니다.
Convolutional Hierarchical Decoder (CHD)
CHD는, 3d tensor인 jst 에 convolution 을 하여 positively aligned pairs는 activate 하고, negative 는 deactivate 하는 decoder 입니다. 4개의 dense layer 에 video-sentence representation 을 input 으로 넣어, similarity matching score 를 계산합니다.
Evaluate
- LSMDC 데이터셋 이용해서 retrieval 이랑 VQA tasks 에 대해서 측정했고, sota 를 달성했습니다.
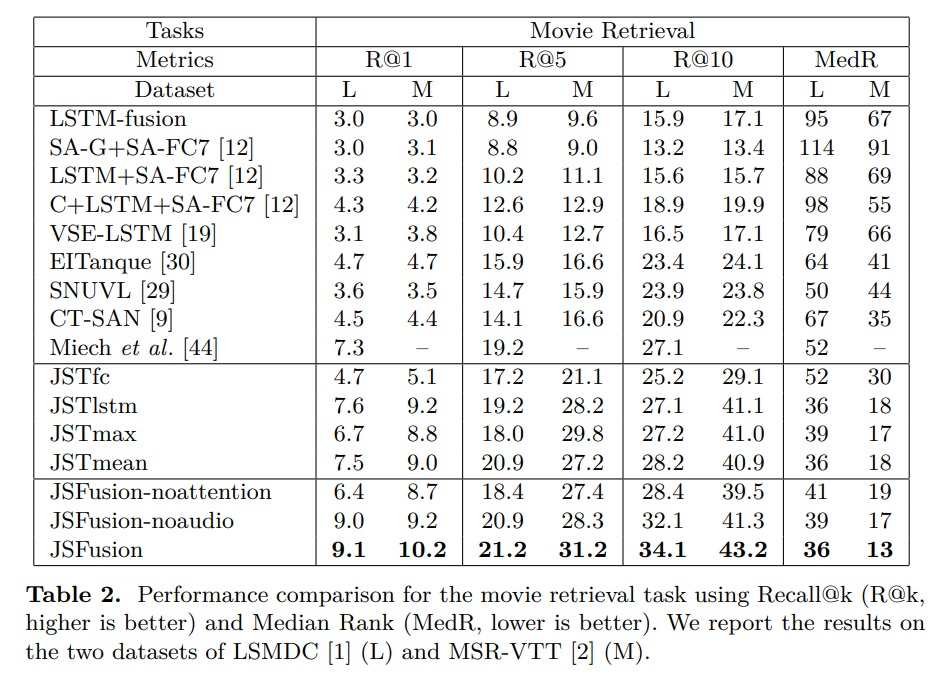
- MSR-VTT 데이터셋 이용해서 multiple-choice 랑 movie retrieval 에 대해서도 측정했고, sota에 대적할 만한 성능을 달성했습니다.
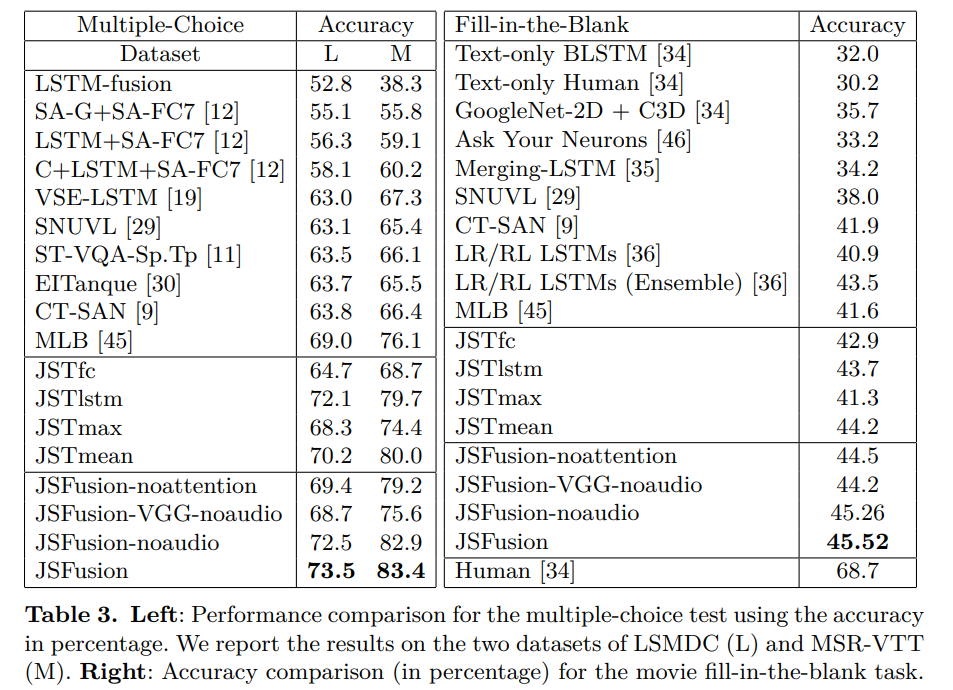
텍스트는 특정 길이를 넘어가는 단어에 대해서는 입력으로 치지 않는 것 같은데, 비디오는 샘플링 방식을 제한하는 것 이외에 입력 크기를 제한하는 방법을 사용하지는 않네요. 문장도 비슷한 논리로 특정 길이 이상을 자르는게 아니라, 랜덤 샘플링 해서 길이를 맞추어 학습할 수도 있을 것 같은데, Text-Video를 같이 읽고계신 입장에서 이런 방법은 고려되지 않나요?
제가 여태 읽은 논문들을 바탕으로 말씀드리자면 문장에서 top-k 개의 중요한 단어를 샘플링하는 방법은 아직 못 봤고, NLP toolkit 등을 이용해 문장에 있는 단어들 중 의미 있는 단어들만 고르도록 preprocessing 한 후 zero padding 을 감싸서 길이를 맞춰주는 게 주된 방법인 것 같습니다.
좋은 리뷰 감사합니다.
첨부해주신 JST 그림에서 JST 3D 텐서와 CHD를 거쳐 “Fill in the blank QA”라는 태스크도 할 수 있는 것으로 보이는데, 어떤 태스크인지 간략하게 설명해주실 수 있으신가요?
비디오와 이에 대해 설명하는 빈칸이 뚫린 문장이 주어졌을 때, 빈칸에 어떤 단어가 적절할 지 넣어주는 태스크입니다! 예를 들어 비디오(강아지가_뛰어다니는_영상.mp4)와 빈 칸이 뚫린 문장(‘A [~] is running around’) 가 있을 때, 이 빈 칸에 들어갈 ‘dog’ 를 예측하는 태스크입니다. 이 빈칸 같은 경우는 fill-in-the blank 를 위한 데이터셋을 만들 때, 비디오와 텍스트로부터 추측할 수 있도록 빈칸을 뚫어 준다고 해요.
그리고 본 논문에서 설명하는 Fill-in-the blank 은 풀네임은 원래 Video fill in the blank 이고, NLP 쪽에서 텍스트만 가지고 하는 Fill in the blank 가 video-language task 로 넘어온 것입니다…!