이번에 가져온 논문은 비디오 요약과는 살짝 방향성이 다른, “비디오 하이라이트”입니다. Facebook에서 수행한 연구인데요… 그래서 그런지 인스타그램 비디오를 마음껏 수집해서 사용하네요. 부럽게… 아무튼 비디오 요약과 다를게 무엇인가… 싶기도 하지만 목적성이 약간 다릅니다. 비디오 하이라이트에서 다루는 것이 조금 더 범위가 좁다고 볼 수 있죠. 행동(주로 액션)이 포함된 긴 영상에서 행동이 포함된 영역만 찾는다고 생각하면 좋을 것 같습니다.
Introduction
비디오 하이라이트는 비디오에서 사용자의 흥미가 있을 법한 순간을 반환하는 태스크입니다. 이러한 하이라이트는 비디오 검색 능력을 강화하고, 추천 시스템을 강화시킨 다는 점에서 주목받고 있습니다.
하지만 큰 한계로 범용성이 없다는 문제가 있습니다. 도메인에 너무 의존해서 영상의 종류가 달라지면 모델이 딱히 중요도가 떨어진다고 생각해서 하이라이트라고 생각하지 않는다는 문제가 있습니다. 이러한 문제 때문에 지금은 정해진 카테고리 안의 비디오에서만 연구를 진행하고 있습니다.
이 논문은 이러한 하이라이트 태스크를 인스타그램에서 수집한 대용량 데이터셋을 기반으로한 비지도 학습으로 해결한 논문으로, 아래와 같은 contribution을 가집니다.
- 비디오의 길이를 학습에 활용하는 비지도 학습 기반의 비디오 하이라이트 탐지 모델 제안
- Noisy한 학습 데이터 쌍에 강인한 학습 프레임워크 제안
- 대용량 데이터셋에서 학습한 것을 바탕으로 데이터셋의 크기가 성능에 중요하다는 것을 보임
- 기존 방법론 대비 22% 정도 성능이 향상된 SOTA
Aproach
Large-scale Instagram Training Video
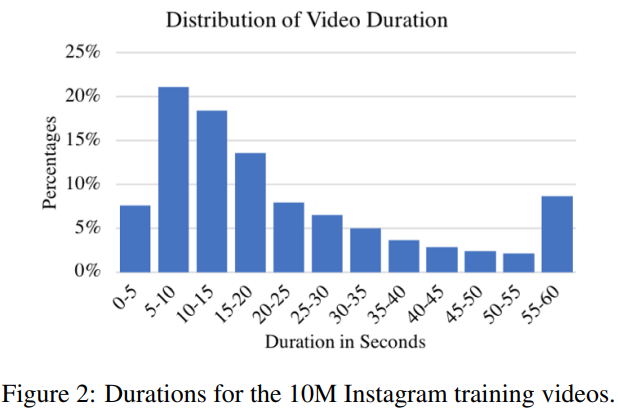
같은 회사 서비스 답게… 데이터셋을 instagram에서 마음껏 끌어다가 사용했습니다. 인스타그램에 업로드 되는 비디오들의 특성상 짧고, 눈길을 끄는 비디오들이 적절한 hashtag를 가진 상태로 업로드 되기 때문에 사용하기도 좋다고 하네요.
최종적인 목적은 도메인별로 하이라이트를 찾아주는 모델을 찾는 것이 목표입니다. 도메인으로는 dog, gymnastics, parkour, skating, skiing, surfing, changing vehicle tire, getting vehicle unstuck, grooming an animal, making sandwich, parade, flash mob gathering, beekeeping, attempting bike tricks, and dog show와 같은 종류가 있다고 하네요. 또 개별 도메인마다 최소한 200000개의 비디오를 가지고 있어 되게 큰 데이터 셋을 구축했습니다.
Learning Highlights from Video Duration
비디오 요약의 목적은 긴 비디오에서 사용자가 관심을 가질만한 작은 비디오 세그먼트를 찾아야 한다는 것입니다. 이 목적을 달성하기 위해 만들어진 함수 f(x)는 주어진 비디오 세그먼트의 하이라이트 스코어를 계산하는 것을 목표로 합니다.
하지만 다수의 라벨러로 부터 구해진 하이라이트 스코어를 바탕으로 GT 구간을 정하는 것은 어려운 문제이고, 이러한 데이터셋을 만드는 것도 비용이 매우 큽니다. (비디오 요약도 동일한 문제를 가지고 있는 상태입니다.) 이러한 이유로 인해 지도학습(paired data)로 학습하는 것이 최고지만 이러한 문제들 때문에 대규모 데이터셋을 가지고 지도학습을 하는 것은 불가능합니다. 그래서 논문 저자들은 앞서 unlabeld video로 구축한 인스타그램 데이터셋을 바탕으로 비디오 하이라이트를 학습하는 프레임워크를 만들었습니다.
자 여기서 가장 중요한 제약조건이 하나 더 추가됩니다. 그럼 하이라이트 될 가치가 있는 것은 어떻게 정할까요? 논문 저자들은 “긴 영상에는 흥미 있는 컨텐츠와 아닌 컨텐츠가 섞여있지만, 사용자들이 업로드하는 짧은 비디오에는 좀 더 흥미로운 영상들이 많을 것이다”라고 가정했습니다. 즉, 수집한 데이터셋의 짧은 영상은 무조건 흥미있는 영상이고, 긴 영상에서는 아닐 수 있다는 전제를 깔았습니다.
Training data and loss
학습을 그럼 어떻게 하는지를 통해 이 전제를 어떻게 이용했는지 알아봅시다. D를 같은 카테고리 안의 비디오 셋이라고 가정하면 D = \{D_S, D_L, D_R\}이라는 표현을 만들 수 있습니다. 여기서 S는 짧은 영상, L은 긴 영상, R은 셋의 나머지 영상인데요. 이 영상 셋들은 서로 겹치지 않는 상태입니다.
그리고 이 비디오들에 대한 각각의 세그먼트 단위로 분할되어 학습을 수행합니다. (세그먼트는 2초 간격으로 일정하게 자릅니다.) 이때 v(s_i)를 비디오의 i번째 세그먼트라고 지칭하면, (s_i, s_j) 는 v(s_i) ∈ D_s / v(s_j) ∈ D_L이 됩니다. (i는 짧은 비디오의 세그먼트, j는 긴 비디오의 세그먼트)

학습은 위와 같은 Loss를 통해 진행되는데, 위와 같은 Loss를 통해 긴 비디오의 세그먼트가 항상 짧은 비디오의 세그먼트보다 하이라이트 점수가 낮게 나오도록 유도합니다.
사실 이 조건이 너무 단순하죠? 영상 전체를 보는 것도 아니고 세그먼트 단위… 여기서는 2초짜리 세그먼트를 비교하다보면 당연히 긴 영상의 세그먼트와 짧은 영상의 세그먼트가 일치할 수도 있고, 하이라이트 될 영역이 될 수도 있습니다. 그래서 등장하는 새로운 학습 방법이 등장합니다.
Learning from noisy pairs

가장 좋은 해결 방법은 GT를 가지고 세그먼트가 하이라이트 인지 아닌지를 알려주는 방식(latent variable이라고 여기서는 부릅니다.)이 제일 좋습니다. 하지만 현실적으로 없기 때문에 여기서는 확률적인 방법론을 이용합니다. 바로… proportional loss에 따라, 임의의 p값을 설정해서 학습 데이터에서 p만큼은 정확한 데이터고, 나머지는 노이즈(긴 비디오의 세그먼트가 하이라이트 인 경우)로 설정해서 이 문제를 해결합니다.
그리고 이 노이즈 인지 아닌지를 알아내기 위한 w_{ij}=h(x_i, x_j)를 계산하는 새로운 네트워크를 만들었습니다. 이 네트워크의 목적은 이 세그먼트가 하이라이트인지 아닌지를 구분해주는 이진분류기 같은 역할을 합니다.
논문 저자는 이러한 추가적인 네트워크를 통해서 여러가지 장점이 있다고 어필을 하고 있는데요. 제가 생각했을 때는 입력 데이터에 섞여있는 노이즈에 강인하다는 점 빼고는 일반적인 모델에서 얻을 수 있는 장점과 동일하다고 생각했습니다.
사실 이 논문에서는 이 p 값을 0.8로 두어서, 전체 데이터의 80%는 올바른 데이터라는 가정을 두고 이 문제를 해결하는데요. 이 문제 해결 방식이 올바른 해결책인지에 대한 것은 의문이 있습니다. (정말로 긴 비디오 세그먼트의 20%는 짧은 비디오 세그먼트랑 유사한지에 대한 확률적인 문제)
결국은 이 세그먼트에 대한 GT를 라벨링을 하지 않고는 알 방법이 없기 때문에 확률을 이용해서 이 문제를 해결하지 않았나… 싶습니다.

최종적으로는 이 과정을 모든 쌍 P에 대해 학습을 수행해줘야 하므로 위와 같은 수식이 됩니다. 여기서 σ_g는 softmax 함수로 추가된 것을 볼 수 있는데요. 이건, h함수이 미분 가능하게 만들면서, 이전 쌍의 노이즈를 유지할 수 있도록 합니다. (n이 작으면 학습 속도가 빨라지고, 커지면 유효한 쌍이 골라질 확률이 증가합니다.)
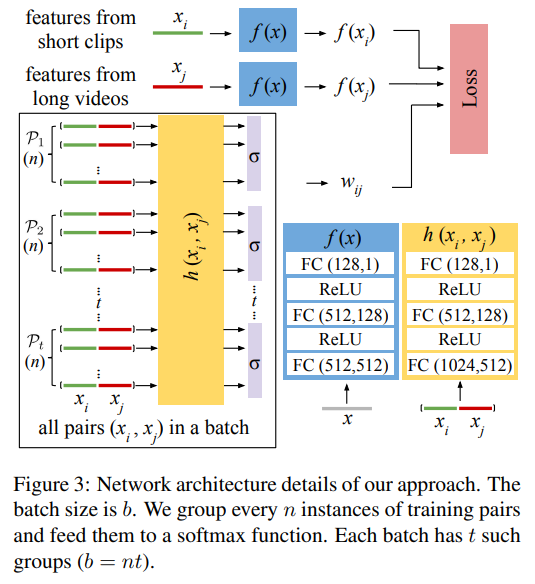
위와 같은 네트워크에서 Kinetics로 학습된 Resnet-34 베이스의 3D conv 모델을 사용했다고 합니다. 구조는 간단한데요. Loss와 함께 보면 이해가 쉬우니 같이 보시는걸 추천드리고요. 구조는 간단합니다. 학습마다 비디오의 feature를 뽑아서 Loss에 전달하고, 그 비디오 안의 세그먼트 페어를 바탕으로 w값(긴 영상 세그먼트와 짧은 영상 세그먼트를 비교해서 긴 영상이 하이라이트 세그먼트는 아닌지 판별해주는 값)을 Loss에 전달합니다. 네트워크 구조도 비교적 엄청 간단하고요.
Result
사실 학습을 인스타그램에서 수집한 비디오를 통해 하고, 따로 공개를 하지 않는 상태라 평가를 어디에서 무엇으로 할지가 좀 중요한 부분인데요. 이 부분은 마땅한 데이터셋이 없었는지 비디오 요약의 데이터셋을 가져와서 평가합니다. 물론, 비디오 하이라이트 관점에서 처리할 수 없는 비디오가 있기 때문에 이 중에서 surfing, skating, skiing, gymnastics, parkour, dog에 대한 카테고리를 가진 비디오를 가져와서 평가를 합니다. (하지만 평가는… 비디오 요약과는 다르게 mAP로 합니다.)


먼저 두가지 방법이 있습니다.
- Ours-A : domain을 구분하지 않고, 모든 데이터에서 학습한 방식.
- Ours-S : domain을 구분해서 학습한 방법. (Parade면, Parade에 해당하는 데이터만 학습합니다.)
이런 방법을 적용했을 때, 사실 Ours-S는 성능은 높지만, 범용성은 너무 떨어지겠죠? 그래도 Ours-A 성능도 다른 방법론들에 비해 꽤 높은 편입니다.

Ablation study의 일한으로 Ours-S를 기반으로 두가지 실험을 수행했습니다.
- Ranking-D : latent variables(노이즈 인지 아닌지를 결정하는 값) 없이 학습을 수행한 결과
- Ranking-EM : 기댓값 최대화 알고리즘이라고 부르는 EM 알고리즘을 사용해서 latent variables를 학습한 결과
이 말은 결국 전체 데이터셋에서 아까 0.8로 설정한 p값을 고정하는 것이 가장 좋다는 말이 됩니다. 애시당초 데이터셋의 확률적 분포상 이게 적합한 값이었다는건데… 범용성은 좀 떨어지지 않나 싶습니다.


정성적 결과라고 볼 수 있는 결과들입니다. 위는 하이라이트 탐지 결과이고, 아래는 latent variable을 결정한 것인데… 사실 말로 설명하면 잘 이해가 안가지만 아래처럼 예시를 통해 보면, 짧은 영상의 세그먼트가 하이라이트가 아니고, 긴 영상의 세그먼트가 하이라이트일 경우 이 값이 음수에 가까워지고, 반대일 경우에는 양수에 가깝게 나와 세그먼트 끼리의 학습이 원할하게 수행되도록 합니다.
Conclusion
비디오 요약과 비슷하지만 살짝 목적이 다른 비디오 하이라이트가 보여서 논문을 읽어봤습니다. 비디오 추천 시스템이 필요할만한 회사 입장에서는 이쪽에 관심을 더 두는 것 같더라고요. 하지만 아무래도 도메인에 너무 종속되서 범용성이 떨어진다는 것은 너무 큰 단점같습니다. 그리고 제가 이해를 잘 못했을 수는 있지만, “Learning from noisy pairs” 파트의 문제 정의가 너무 모호하다고 느꼈습니다. 후속 논문에서는 범용성 문제를 해결한 것 같아서 한번 그것까지는 읽어보려고 합니다.
비디오 하이라이트와 비디오 요약의 대표적인 방법론으로 같은 데이터셋에서 평가하였을때, 오버랩되는 부분이 어느정도 되는지, video duration은 어디 테스크가 일반적으로 더 긴지 등이 궁금하네요. 거의 비슷한 컨셉인거 같은데 두개를 동시에 사용하는건 어떤가요?
하이라이트가 좀 더 특정 도메인에서만 작동하는 경향이 있습니다. 학습하는 데이터셋도 그렇고… 좀 더 읽어봐야 알겠지만 여기도 평가 데이터셋을 무엇을 쓸지가 조금 모호한 경향이 있는 것 같고요. 이런 문제들 때문에 같이 사용하는건 무리가 있을 것 같고, 길이는 요약쪽이 더 긴것 같습니다만… 나머지 정보들은 supplimentary에 있을 것 같은데… 논문에는 분명 읽고 오라는데 제가 찾아보니 없어서 확인할 수가 없네요.