이번에 진행할 리뷰는 Image Translation task과 거의 유사한? Image Manipulation 분야의 논문을 가져왔습니다. 저자는 CycleGAN의 저자인 박태성님이 주저자로 작성한 논문입니다. 이분도 그렇고 Adobe Research가 이쪽 분야로 논문을 참 잘쓰는 것 같네요.
아무튼 리뷰 시작합니다.
Intro
일단 위에서도 설명드렸고, 제목에도 나와있다시피 이 논문에서 다루고자 하는 task는 Image Manipulation입니다. Image Manipulation에 대해서 익숙치 않으신 분들을 위해 잠깐 해당 분야에 대해서 설명드리자면, 쉽게 말해 Photo-editing tool과 관련된 분야라고 보시면 될 것 같습니다. (이 논문의 연구팀이 “Adobe Research”라구요?)
그래서 해당 분야의 목표는 영상 속 특정 영역을 “inpainting”하거나, 실제 사진처럼 새롭게 “synthesizing”하기도 하며, 기존 물체를 대체하거나 지워버리기도 합니다. 어쨋든 영상 편집 및 조작에 모든 행위를 다룬다고 볼 수 있으며 그 중에서 해당 논문은 그림1과 같이 “texture swapping”을 목표로 한 방법론을 제안합니다.

그림1을 확인해보시면 제일 좌측에 있는 그림이 입력이며 우상단에 있는 reference image를 함께 넣어주게 되면 reference image와 유사하게 건물의 texture를 입히는 모습입니다. 그리고 입힐 때는 당연히 photo-realistic 해야만 하고 배경과 전경을 잘 구분해서 반영해야겠죠.
task에 대해서는 대충 이해할 수 있으며 그림1 결과만 보면 잘되는 걸 보니 쉬운 task인가? 싶을 수도 있으시겠지만, 좀 더 생각하면 제법 어려운 task에 속합니다. 예를들어서 input image와 reference image가 서로 동일한 구조에 단순히 texture만 다른 영상이면 픽셀레벨로 쉽게 비교할 수 있겠으나, 대상도 다르며 촬영 구도도 완전히 다르게 되어있습니다.
애초에 structure는 동일한 사진인데 texture만 다른 데이터 셋은 세상에 그리 많지 않을 뿐더러, 있다하더라도 취득하기가 상당히 어렵습니다. 그래서 CycleGAN과 같이 Unpaired dataset으로 학습이 가능한 방법론들이 계속해서 제안되고 있죠.
해당 논문도 마찬가지로 image editing을 위해 완벽히 unpaired한 데이터 셋으로 학습을 하는 unsupervised setting 기반 방법론을 제안합니다. Unpaired 데이터 셋으로 학습하는 방법론들이 가장 중요시 여기는 것은 바로 영상 속 texture와 structure를 잘 구분하여 분리하는 것이 중요합니다.
이러한 개념은 제가 예전에 자주 리뷰한 Style Transfer 방법론과 상당히 유사합니다. Style Transfer는 이미지를 Style과 content로 구분지어서 입력 영상의 컨텐츠에 reference 영상의 style을 입히겠다는 분야입니다. 해당 논문에서 자주 언급할 Texture와 Structure는 Style Transfer에서 Style와 Content라고 이해하시면 좋겠습니다.
아무튼 저자는 unsupervised setting에서 image editing을 위해 structure와 texture를 잘 구분짓도록 하는 새로운 방법론을 제안합니다. 대략적인 방법론으로는 먼저 auto encoder를 통해 2개의 latent code를 생성하게 됩니다. 각각의 latent code는 서로 영상 속 다른 특징을 가지고 있는데 그것이 바로 위에서 설명한 structure와 texture를 의미합니다.
이렇게 2가지 요소로 구분짓기 위해서, 저자는 동일 영상 내부에 코드를 가지는 모든 영상 패치들이 서로서로 일관성을 가지도록 학습한다고 합니다. 말이 조금 어려운데 밑에서 자세히 다뤄보도록 하죠.
본격적으로 방법론에 들어가기 앞서, 한가지 궁금증에 대하여 논문에서는 친절히 답을 해줍니다. 바로 Unconditional GAN같이 그냥 간단한 컨셉에 방법론이 존재하는데 왜 그걸 안써? 라는 질문입니다.
저자는 이에 대한 대답으로, Unconditional GAN 방법론들은 기존 영상(existing image)을 작업하는데 있어 잘 동작하지 못한다고 합니다. 이게 무슨 말이냐면, Unconditional GAN은 무언가 입력 영상에 대해 수정을 하는 것이 아닌, 단순히 학습했던 데이터의 확률 분포를 따라가도록 학습하기 때문에 입력이 자신이 학습했던 입력 데이터 분포에서 벗어나면 성능이 매우 떨어지는 것이죠.
물론 입력 영상을 기반으로 새로운 영상을 생성하는 Conditional GAN기반의 Image Translation 방법론들도 있지만, 해당 방법론들은 즉석에서 이미지 편집을 하기 힘듭니다. 이게 무슨 말이냐면 보통 Image Translation 방법론들은 도메인이 단일로 결정되는 것이 대부분입니다.
예를 들어 말을 얼룩말로 변경하거나, 여름 영상을 겨울 영상으로 바꾼다는 것이 있죠. 하지만 영상 편집 분야에서는 하나만을 바꾸고 싶어하지 않겠죠. 때로는 얼룩말이 풀밭에서 뛰어놀고 있는 이미지가 있다면 얼룩말은 그냥 갈색 말로 바꾸면서 동시에 배경은 눈 덮인 겨울 풍경으로 만들어야 하는 것이죠. 즉 새로운 도메인 또는 다양한 유저 입력에 맞추어 모델이 새롭게 학습을 하지 않는 이상 영상 편집 분야에 Image Translation 방법론을 접목하는 것은 쉽지 않다는 얘기입니다.
물론 다중 도메인으로의 변환을 수행하는 image translation 방법론들도 있지만.. 사실 그러한 방법론들은 단일 모달리티 대비 성능 향상 폭이 좋지 않은 편입니다.
서론이 길었네요 이제부터는 방법론에 대해서 알아봅시다.
Method
일단 위에서도 말씀은 드린 것 같은데 다시 정리하자면 해당 논문의 목표는 Image editing을 “잘” 하는 것으로 “잘”의 기준은 입력 이미지를 쉽고 정확하게 재구성하는 것을 의미합니다. 그 과정에서 편집된 영상은 사실적으로 보여야 하며 수정된 느낌이 전혀 들지 않아야만 하죠. 또한 영상 내 글로벌한 영역과 로컬한 영역 모두에 대해서 편집을 지원해야만 합니다.
요구하는 조건들이 까다롭긴한데, 저자는 이러한 모든 것을 잘 수행하기 위해서 아래 그림2와 같이 Swapping autoencoder라는 구조를 사용합니다.
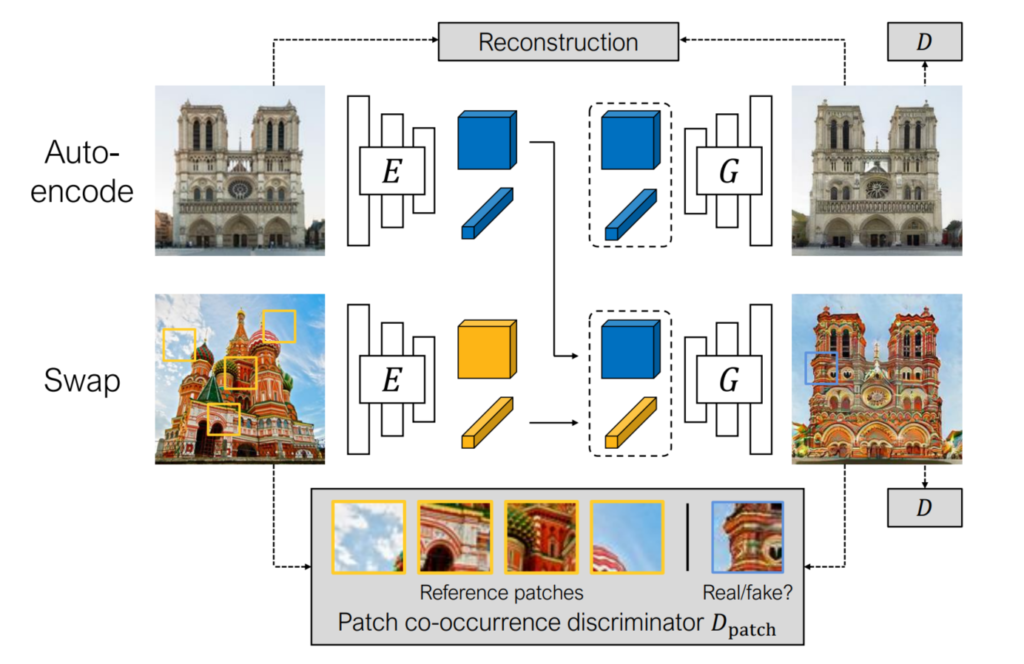
Swapping autoencoder라는 구조는 쉽게 말해 E라고 표현된 encoder와 G라고 표현된 Generator로 나뉘어 있습니다. 그림속에서는 Encoder와 Generator가 각각 2개씩 존재하는 것처럼 보이지만, 실제로는 각각 하나씩 존재하여 weight를 공유한다고 보시면 될 것 같습니다.
그림2만 봐도 어떤식으로 동작하는지는 쉽게 이해하실 수 있을 것이라고 생각이 드는데, Auto-encode라고 적힌 그림과 Swap이라고 적힌 그림을 각각 Encoder의 입력으로 태워서 2쌍의 latent code를 생성합니다. 한 쌍의 latent 코드 안에는 각각 structure와 texture를 뜻하는 코드들이 존재합니다.
그리고 Generator는 Auto-encode 그림에서 추출한 Structure와 texture code를 이용해 다시 입력 영상을 재구축하게 됩니다. 이것이 바로 Reconstruction loss이며 아래와 같습니다.
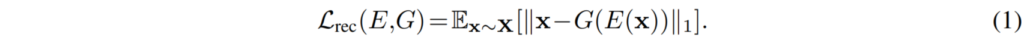
여기서 x는 입력 영상, E는 Encoder, G는 Generator를 의미합니다. 차례대로 Encoder 통과하고 그 결과값을 그대로 Generator로 태워서 생성된 값을 다시 입력 영상과 L1 loss로 비교합니다.
이를 통해 Generator는 Encoder의 latent code를 기준으로 structure의 손실이 최소화된 영상을 생성하게끔 학습할 것입니다. 게다가 저자는 보다 더 사실적으로 영상을 생성하기 위해 단순히 L1 loss만을 사용하지 않고 Discriminator를 활용한 GAN loss도 사용합니다. GAN loss를 활용하게 되면 생성되는 영상이 더욱 선명해지고 사실적으로 된다는 점이 있죠.
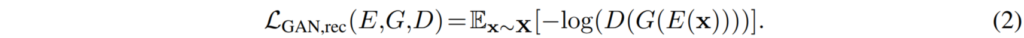
D는 Discirminator를 의미하고 그 외의 표현들은 수식1과 같습니다.
Decomposable latent codes
위의 과정만 수행하게 되면 Generator는 Encoder의 latent 코드를 가지고 사실적인 영상을 만들 수는 있겠지만 가장 중요한 문제점을 놓치게 됩니다. 바로 Encoder를 통해 추출된 2가지의 latent code들 중에 어떤 코드가 Structure를 담당할지 아니면 texture를 담당할지에 대해 명확하게 학습이 안된다는 점입니다.
이를 위해서 저자는 두 latent code가 서로 명확하게 구분이 되도록 하기 위해서 swapping 방식을 이용해 학습을 진행합니다. 먼저 용어 정리부터 해야하는데 Encoder를 통해 나온 각각의 latent code들에 대하여, 먼저 해당 코드들이 존재하는 latent space를 Z라고 정의하면 Encoder의 출력값은 z = (z_{s}^{i}, z_{t}^{i})라고 표현할 수 있습니다.
여기서 s와 t는 각각 structure와 texture를 의미하며 i는 몇번째 영상인지를 나타냅니다. 예를 들어서 z_{s}^{1}라고 한다면 첫번째 이미지에서 추출한 structure code라고 볼 수 있겠네요. 아무튼 이제 그림2에서와 같이 저자는 Generator의 입력으로 1번째 이미지에서 추출한 structure code와 2번째 이미지에서 추출한 texture code를 조합하여 넣습니다. 그리고 그렇게 생성된 결과는 GAN loss를 통해 진짜 영상인지 가짜영상인지 구분하는 방식으로 학습이 됩니다.
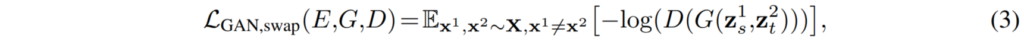
위의 수식3 loss와 더불어 수식1~2 loss를 함께 학습하게 되면, 1번째 영상에서 추출된 z_{s} 는 어떠한 texture code가 들어온다 하더라도 항상 structure를 잘 보존해야하도록 학습이 되어야 하며(수식1의 영향이 클 것 같네요), z_{t} 코드들은 Discriminator를 속이기 위해 최대한 texture 정보를 모방하려고 할 것입니다.
게다가 저자는 z_{s} 와 z_{t} 의 shape 자체를 다르게 하여 예측하는데, z_{s} 의 경우에는 spatial dimension이 존재하는 2D feature map 형식으로 예측이 되고, z_{t} 의 경우에는 채널축만 존재하는 1D 벡터 형식으로 생성하게 됩니다.
이렇게 함으로써 z_{s} 가 보다 더 structure 정보를 담으려고 할 것이며, 보통 texture의 경우에는 색상, 질감 등 어떤 물체의 구조와는 상관없이 픽셀값들의 분포를 가지고 있기 때문에 벡터 형식으로 학습함으로써
Co-occurrent patch statistics
사실 이러한 과정은 어찌보면 당연한 듯한 느낌도 조금 들구요, 무언가 참신하다는 느낌은 크게 들지 않습니다. 왜냐하면 해당논문이 2020년에 나왔을 때 기준, 이미 예전부터 다른 분야에서 texture를 feature의 평균 및 표준편차로 보는 등 전역적인 특성을 나타내는 수치로 봤었기에 1D 벡터로 생성한 것이며, structure는 당연히 2D 상 위치관계가 중요하기 때문에 1D vector 형식으로 latent code를 추출해서는 안되기 때문이죠.
저자 또한 단순히 위의 과정들만으로 학습을 한다고 하더라도 Image Editing에서 좋은 성능을 기대할 수 없다고 말합니다. 이러한 이유는 단순히 수식1~3과정만으로는 z_{s} 와 z_{t} 가 실제로 structure 및 texture를 대표한다고 보장할 수 없기 때문입니다.
그래서 저자는 이 문제를 해결하고자 그림2아래와 같이 patch단위로 계산하는 loss를 사용합니다.
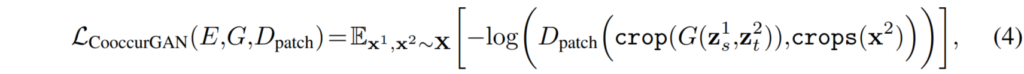
수식으로만 보면 1번째 영상의 structure와 2번째 영상의 texture를 통해 생성된 Swapped image에서도 패치를 추출하고, 실제 texture를 추출했던 2번째 원본 영상에서도 patch를 추출해서 어떤 패치가 진짜 패치인지를 구분하는 GAN loss를 계산하는 것입니다.
이러한 방식을 사용하게 된 계기로는 “Julesz’s theory”라는 것이 있습니다. “Julesz’s theory”란 쉽게 말해 유사한 이미지들은 두 feature들 간에 통계치가 매우 유사하거나 근소한 차이를 보인다는 것입니다. 즉 저자는 co-occurence discriminator를 통해 학습된 표현(texture code)의 통계치가 잘 유지되도록 학습하게끔 loss를 주는 것입니다.
Experiments
그럼 이제 실험 섹션을 간단히 소개하고 리뷰를 마치도록 하겠습니다. 아무래도 이러한 Image Manipulation 분야는 생성된 결과와 매칭되는 정답 영상들이 없기 때문에 대부분 정성적인 결과를 더 중요시 여기거나 정량적인 성능이 feature similarity 등으로 표현됩니다. 아주 가끔씩 사람의 주관으로 평가하는 방식(AMT)으로도 평가하는데, 이 논문에서도 해당 방식을 사용했더군요.

그림3의 정성적 결과를 살펴 보시면, texture를 자연스럽게 입힘과 동시에 structure들이 어떠한 왜곡 없이 잘 표현된 모습입니다.
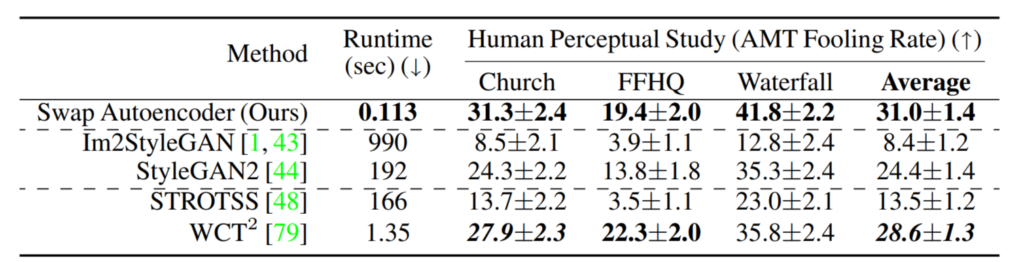
위의 표는 각각의 방법론에 대해 각 데이터 셋 별로 AMT 성능 평가를 해본 것입니다. 먼저 저자의 방법론은 영상의 texture와 structure를 추출하도록 학습을 했기 때문에, 학습 때 보지 못한 영상이 들어온다 하더라도 빠른 속도로 inference가 가능합니다. 하지만 SoTA 방법론들은 대부분 unconditional한 방식으로 이루어져 있어서 새로 학습하느라 속도가 느린 것 같은데, 이러한 점을 집어서 RunTime을 함께 보여준 것 같네요.
아무튼 FFHQ 데이터 셋을 제외하고는 모든 데이터 셋에서 자신들이 가장 좋은 성능을 보였다고 합니다. 보통 이렇게 사람의 주관이 들어간 평가 방식은 별로 신뢰하고 싶진 않지만, 해당 논문에서는 총 1000명을 대상으로 진행을 하였기 때문에 믿을만 하다고 주장합니다. (하긴 주변 친구가 1000명이 아닌 이상 조작은 힘들겠죠?)

그 외에도 Image hybrids의 정성적 결과를 보여줍니다. 보시면 StyleGAN2의 경우 2행에서 texture image의 눈동자를 모방해버리는 모습 즉 structure를 못살린 모습이며, Im2StyleGAN은 거의 모든 영상에서 왜곡 현상이 심하게 일어나는 모습입니다.
그에 비해 논문에서 제안하는 방법론은 structure를 잘 살리면서 동시에 texture도 자연스럽게 입힌 모습입니다.

마지막으로 논문에서 제안한 방식이 과연 reconstruction을 얼마나 잘 표현하였는지를 나타내는 결과입니다. 좌측 그림부터 보시면, StyleGAN2는 눈동자를 잘 못살린다던지, 성의 texture 및 structure들이 모두 잘못 표현된 모습입니다.
그나마 Im2StyleGAN의 경우 input 영상과 최대한 비슷하게 생성되고자 했으나, 무언가 영상의 선명도가 많이 떨어지는 모습입니다. 하지만 제안하는 방법론은 reconstruction도 잘 됐을 뿐더러 영상 자체도 선명하게 잘 생성된 것을 볼 수 있습니다.
또한 LPIPS라는 영상 품질 평가 네트워크의 수치값을 통해서도 자신들의 결과가 Church 데이터 셋을 제외하고는 모두 높은 유사도를 보였다고 하네요.
좋은 리뷰 감사합니다!
실험 결과와 관련하여 질문이 있습니다.
Structure를 유지하고 Texture를 변경하는 방법론으로 이해하였는 데, 실험 결과 사람에 대한 정성적 결과를 봤을 때 전체적으로 구조는 유지되지만 texture에 대한 변경 결과가 전체적으로 아쉬워 보입니다.(사람의 머리색이 일부 변경되지 않는 점 등) 이는 데이터 특성상 건축물과 다르게 사람이라 그런것인가요?? 이러한 실험 결과에 대한 분석이나 정민님의 분석이 있는 지 궁금합니다.
음 일단 자세히 확인해보지는 않았지만 논문에서는 따로 다루지는 않은 것 같습니다.
그리고 제가 생각했을 때도 말씀해주신 것처럼 사람과 건물의 차이가 크기 때문에 그런 것 같은데 이 논문에서는 texture를 feature의 통계학적 관점으로 접근하기 때문에 영상이 보다 더 명확하고 다채로울수록 정확해질 것 같습니다.(예를 들면 열화상 영상과 RGB 영상은 정말 큰 분포 차이를 가지고 있죠. 또는 푸른 숲의 여름과 눈이 내린 겨울 또한 다른 분포를 가질 것이구요)
하지만 사람의 경우에는 유색인종의 차이 등 큰 틀에서의 texture가 아닌 이상은 사실 수염이나, 주름, 안경 등의 high level을 잡아내기란 해당 방법론에서는 쉽지 않을 것으로 판단됩니다.
좋은리뷰 잘 읽었습니다.
auto encoder를 통해서 각각 structure와 texture를 나타내는 latent code를 생성한다고 했는데, 아래 방법론 설명쪽에서 이 두가지 encoder는 실제론 하나이며 weight를 공유하는 방식이라고 이해했습니다. structure와 texture를 추출(?) 하는 것은 엄연히 구분이 되어서 수행이 된다고 생각이 되고, 추출된 2가지의 latent code가 각각 어떤것을 나타 내는지 구분하는 것도 중요한 문제라고 했습니다. 이런 관점에서 encoder를 역할별로 하나씩 만들지 않고 weight를 공유하는 하나의 encoder로 설계 한 이유와 관련된 내용이 논문에 언급이 되어 있었나요??
논문에는 따로 설명이 없지만 말씀해주신 “encoder를 역할별로 나누는 것이 아닌 하나의 encoder에서 두가지 역할을 수행하도록 설계한 이유”는 일반적으로 많은 방법론들이 사용하는 방법입니다.
물론 두 가지 일을 수행하기 위해서 두 가지로 모델을 구분지어서 학습 및 추론을 시킬 수도 있겠으나, 그렇게 하게 될 경우에는 결국 학습과 추론 때 모델이 2개가 되어야하는 하기 때문에 속도와 메모리 측면에서 매우 큰 단점으로 볼 수 있습니다.
그리고 다른 하나는 일종의 multi-task learning 관점으로 접근해볼 수도 있을 것입니다. multi-task란 두 가지 이상의 task를 동시에 학습함으로써 모델이 더 좋은 feature representation을 가지도록 학습하는 것을 의미합니다.
가장 쉬운 예시로는 Object-detection과 Semantic Segmentation을 동시에 학습하게 되면 feature가 보다 더 object를 구분하는 표현력이 좋아질 수 있는 것이죠. 물론 앞서 설명드린 예시는 multi-task의 매우 이상적인 예시라고 보시면 될 것 같으며 대부분은 오히려 서로의 task를 잘하도록 loss를 계산하다가 이들의 gradient가 서로 반대되는 gradient conflict 현상이 발생하기도 합니다.
사설이 조금 길었는데 결과적으로 저자도 하나의 encoder에서 texture와 structure를 구분짓도록 loss를 주고 학습함으로써 모델 입장에서는 하나의 이미지에서 이 요소는 texture, 이 요소는 structure로 나눌 수 있구나 라는 식으로 영상의 구성 자체를 더 잘 구분짓고 나눌 수 있도록 학습이 될 수 있을 것입니다.
즉 메모리와 속도 측면에서도 이점이 있으며 multi-task learning 관점에서 모델을 따로따로 구분지어 학습했을 때보다 오히려 함께 학습하는 것이 더 좋은 성능을 보일 수 있다는 것이죠.