기존 Self-Training의 경우 classification task에 주로 사용되었으며 비교적 복잡한 sequence generation tasks(예. machine transflation)는 target space의 구성적 특징으로 그 효과가 명확하지 않았다. 본 논문에서는 self-training이 neural sequence generation tasks에서 효과를 볼 수 있음을 실험적으로 보였다. 또한 hidden states 왜곡을 적용하는 dropout이 self-training에서 중요한 요소임을 실험적으로 확인하였다. 그러나 dropout을 적용하는것은 학습의 어려움과 noise 추가의 trade-off 관계가 있다. 본 논문은 input space에 noise를 적용하여 trade-off 문제를 해결한 noisy version of self-training을 제안하였다.
- Machin transformation에 적용
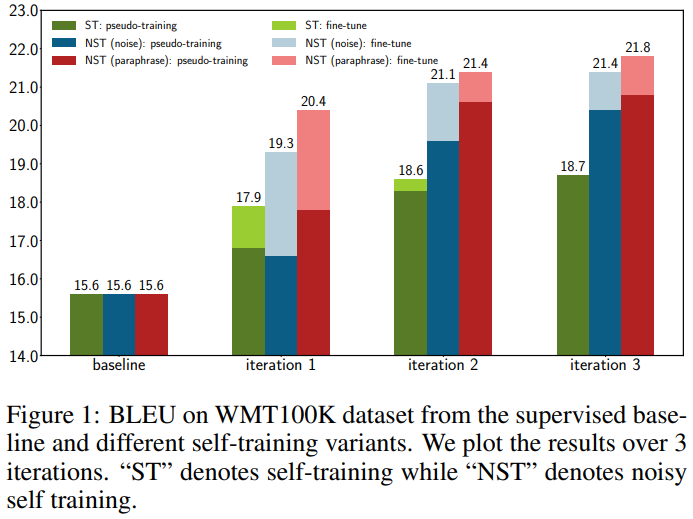
그림1은 machine trasnformation 분야에 self-training을 적용한 결과이다.3 iteration을 적용하여 성능 향상을 보였으며, 진한 막대는 pseudo-training을, 연한 막대는 이후, labeled data로 fine-tuneing 한 결과를 의미한다. 실험을 통해 machine trasnformation과 같은 sequence 정보가 중요한 task에도 기대대로 작동함을 확인 할 수 있으며, pseudo-training이후 labeled data로 fine-tuning을 통해 성능의 boosting 효과를 볼 수 있다.

그렇다면 같은 양의 데이터를 사용했음에도 self-training을 통해 성능 향상을 얻는 이유는 무엇일까? 저자는 이를 Decoding strategy와 Dropout으로 가정하고 이에 대한 실험을 진행하였다. 실험 결과는 그림2와 같다. 여기서 decoding 전략이란 nlp의 경우 문장을 생성할 때 예측한 확률값에 대응하는 단어를 vocab에서 찾는다. 이때 vocab의 크기가 너무 커서 탐색 전략이 필요하다. 저자는 beam search를 baseline인 sampling과 비교하여 채택한 decoding 전략의 성능 향상에 얼마나 영향을 미치는지 확인하였다. 확인 결과 dropout이 beam search보다 성능 향상에 더 큰 영향을 미치며, 나아가 dropout 이 self-training의 중요 요소임을 확인하였다.
2. self-training에 사용되는 noise의 효과
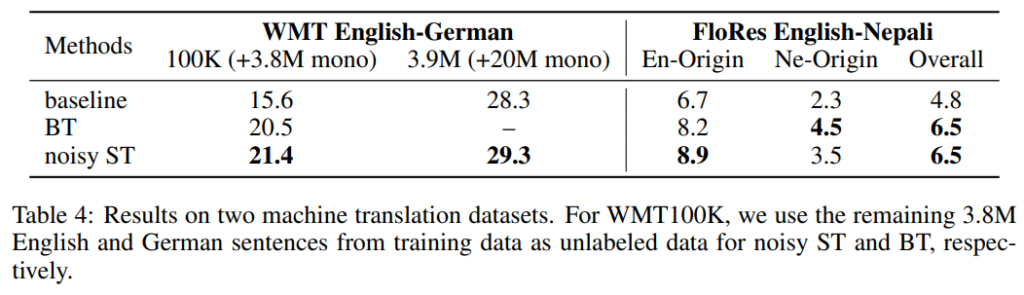
dropout이 self-training의 성능 향상에 큰 영향을 미치지만, 너무 심한 dropout은 모델 학습의 불안정성을 야기하고, 학습의 어려움을 겪게 한다. 저자는 이러한 trade-off에서 벗어나기 위해 새로운 noise를 추가하고자 하였으며, input space에 noise를 추가하는 noisy version of self-training을 제안하고 실험하였다.
3. 실험
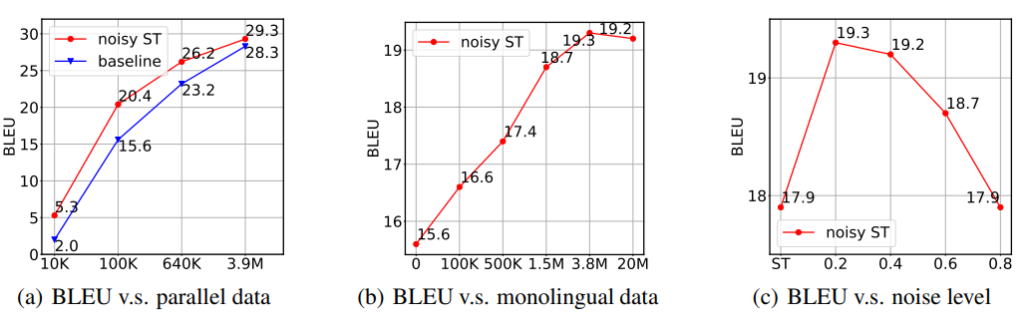
다음은 self-training의 분석 실험이다. (a)는 쌍 데이터의 양에 따른 모델 성능을 BLEU로 리포팅한 결과이고, (b)는 쌍이 없는 monolingual data에 따른 성능을 (c)는 noise(확률값에 따른 word blank 생성)의 정도에 따른 성능을 리포팅한 것이다. 이때 실험 (b)에서 사용하는 parallel data는 100k개로 한정되었으며 실험을 통해 data의 양이 많을수록 모델의 성능이 증가함을 확인할 수 있고, noise가 추가될수록 성능이 항상 좋아지는 것이 아님을 알 수 있다.
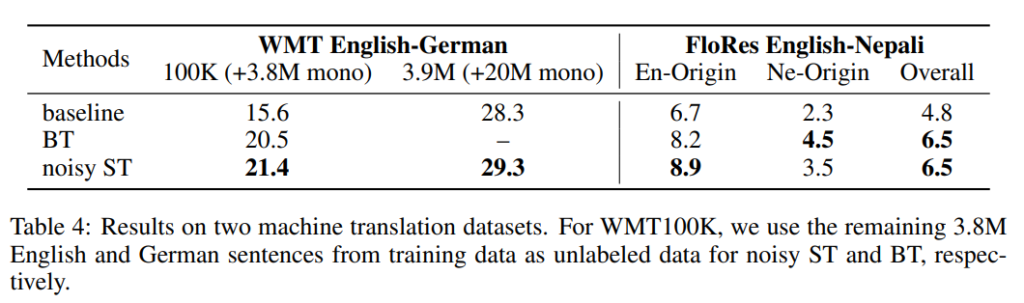
성능 비교는 BT(back-translation, 2015) 와 비교하였다. 오래 된 방법론이지만 semi-supervised learning method를 적용한 machine translation 분야에서는 가장 성공적인 방법론이라고 한다. BT와 비교하였을 때 제안하는 방법론은 전반적으로 좋은 성능을 보인다.
4. 정리
본 논문을 통해 self-training이 sequence generation task에도 활용될 수 있음을 보였으며 noise를 적용하여 self-training 모델의 성능을 개선 시킬 수 있음을 보였다. 사실 sequence task와 같은 복잡한 task에 self-training을 적용함으로써 self-training의 성격을 더 알 수 있지 않을 까 하는 마음으로 보았는데, 생각보다 초기 논문인 듯 하여 이해가 어렵고 task에 대한 소개가 많았던 것 같아 아쉬웠다.
본 논문에서 이야기하는 노이즈는 어떤걸 의미하나요?
본 논문의 노이즈는 text에 빈칸을 일정 확률 p에 의해 추가하는 것입니다.