

이번에 리뷰할 논문은 self-supervised video representation을 다룬 “Spatiotemporal Contrastive Video Representation Learning” 이라는 논문입니다. 해당 논문에서는 CVRL이라는 video representation learning을 위한 데이터 augmentation 기법을 통해 꽤나 높은 성능을 보였으며, 심지어 이는 image 데이터 셋에서 supervised learning된 방법론의 inflating 버전 대비 12.6%나 높았습니다. 때문에, 현재 CVRL은 해당 분야에서 유명한 논문들 중 하나로 자리잡고 있습니다. 이러한 CVRL에 대해 리뷰하도록 하겠습니다.
1. Method
1.1 Video Representation Learning Framework
기존 video의 다양한 분야에서는 image 분야에서 사용하던 기술들을 접목시켜왔습니다. 예를 들어, image에서 사용되던 SIFT라는 유명한 알고리즘은 video 분야를 위해 3D SIFT로 제안되었습니다. 이처럼 다양한 video 분야에서 image 기반 기술들을 응용시켜왔으나, 해당 논문 이전의 self-supervised representation에서는 image와 video를 따로 구분했습니다. Self-supervised video representation에서는 주로 static image에서 다루지 못하는 future prediction이나 temporal sampling rate change 같은 것을 적용시켜오면서 말입니다.
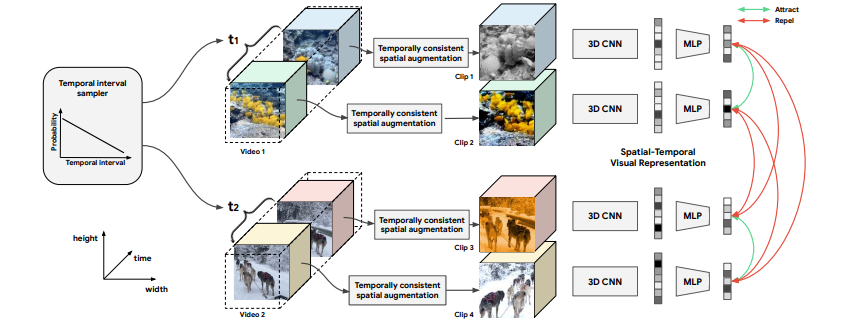
본 논문에서는 기존 static image의 spatial space에서 연구되어 왔던 self-supervision signal들을 video에 적용하고자 합니다. 이러한 motivation으로 Fig 2에 해당하는 CVRL framework를 학습시키기 위해 InfoNCE loss를 사용합니다. InfoNCE Loss는 self-supervised representation learning에서 자주 사용되는 loss이며, CVRL framework에서는 한 video 마다 positive한 관계를 지니고 있는 두 개의 clip 간의 representation을 유사하게 만들어 줍니다.
1.2 Video Encoder
CVRL의 framework에서 augment된 clip들을 InfoNCE Loss로 학습시키기 위한 encoder로 3D-ResNet을 사용하였다고 합니다. 이때, SlowFast의 Slow pathway에서 첫번째 layer의 temporal stride를 2로, 첫번째 convolution layer의 temporal kernel 크기와 stride를 각각 5와 2로 수정한 것과 동일하다고 합니다. 그리고 R3D를 거친 2048-D feature에 SimCLR에서 제안되었던 것처럼 projection 시켜 128-D 의 feature z를 생성하고, 이들 간의 contrastive learning이 진행됩니다.
1.3 Data Augmentation
Encoder를 학습시키기 위한 positive pair를 만드는 과정은 총 두 가지로 나뉩니다.
- Temporal Augmentation
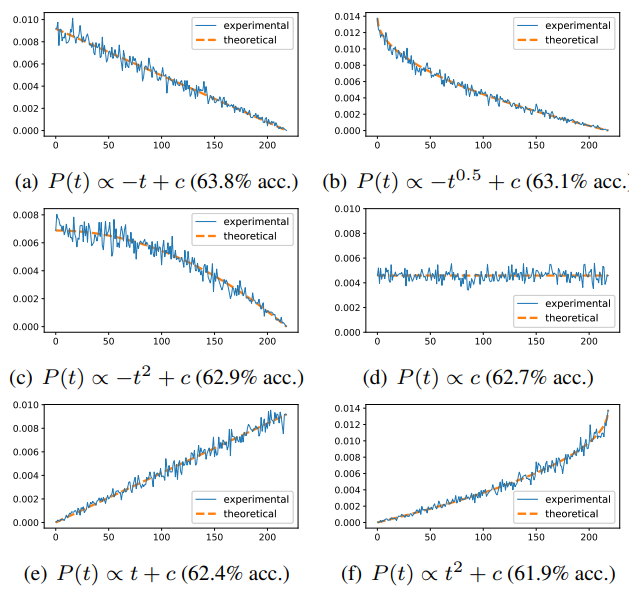
한 비디오에서 두 개의 clip을 선택해 positive pair로 선정합니다. 이때, CVRL framework는 Fig 4와 같은 실험을 통해, 한 비디오 내에서 뽑는 두 clip의 거리가 멀수록 낮은 확률로, 거리가 가까울 수록 높은 확률로 택합니다. 이는 비록 한 비디오에 속해 있지만, 비디오의 dynamic한 성질로 인하여 거리가 멀수록 두 clip 간의 contents 차이가 커진다는 가설로부터 기인하였습니다. 또한 x축이 두 clip 간의 거리를 나타내고 y축이 샘플링 확률을 나타내는 Fig 4의 실험에서도, 해당 가설에 속하는 (a), (b), (c)일 때 성능이 가장 높았으며 그 중 가장 성능이 높던 linear한 (a) 형태로 clip을 샘플링하였습니다.
- Spatial Augmentation

앞선 temporal augmentation을 통해 positive pair clip을 뽑은 뒤, self-supervised image representation에서 자주 사용되던 spatial augmentation 기법들을 활용해 각 clip을 augmentation하였습니다. 이때, self-supervised image representation에서와 같이 clip 내의 각 image 마다 랜덤하게 spatial augmentation을 할 경우, 한 clip에서 나타나는 motion 정보가 약해지고 encoder의 표현력을 떨어뜨리게 됩니다. 이를 방지하고자, CVRL에서는 Algorithm 1과 같이 한 clip에 속한 모든 프레임에 같은 spatial augmentation을 적용하는 temporally consistent한 방식을 사용하였습니다.
2. Experiments
2.1 Linear evaluation
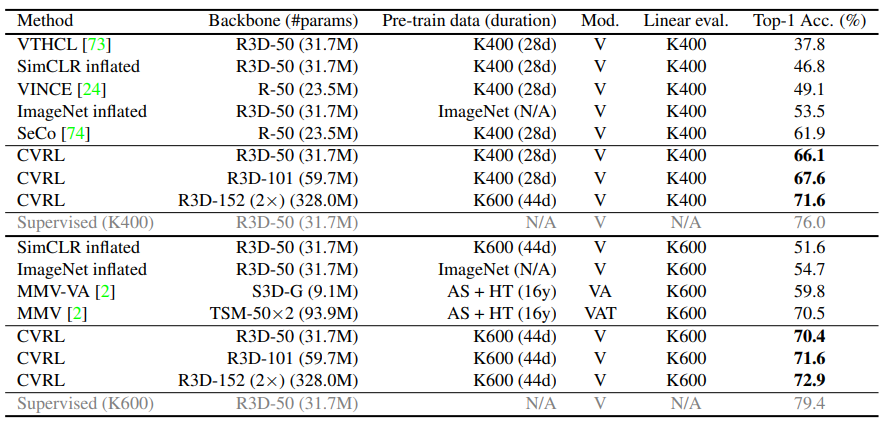
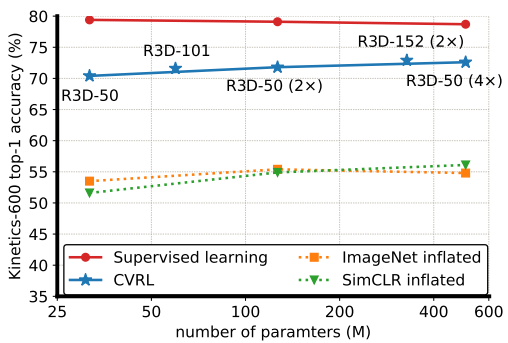
Linear evaluation은 self-supervised learning 방식으로 학습된 backbone network에서 feature를 추출한 뒤, Linear SVM을 통해 분류한 실험을 의미합니다. 직관적으로 backbone network가 제안된 방식을 통한 표현력 향상의 정도를 확인할 수 있습니다. CVRL은 Kinetics 400에서 기존 SOTA 였던 SeCo 방식보다도 약 5%가량 높은 성능을 내었으며, I3D의 pretrained weight라고도 볼 수 있는 ImageNet inflated 보다는 12.6% 높은 성능을 보였습니다. 뿐만아니라 동일 backbone일 경우 supervised 방식과 약 10퍼정도 차이로 가장 supervised signal에 가까운 경향성을 보여주었습니다. 이러한 경향성은 좀더 대용량 데이터 셋인 Kinetics 600에서도 동일하게 보였습니다.
2.2 Semi-supervised learning
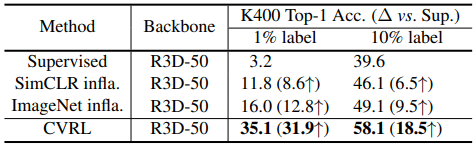
Table 2는 각 방식으로 pretrain 시킨 뒤, 소량의 label로 Kinetics 400에서 학습시켰을 때인 Semi-supervised learning 성능입니다. 1%만 label을 사용했을 때, 다른 방법론의 경우 상당히 성능이 낮은 경향을 보이지만, CVRL 방식은 최소 약 3배정도의 높은 성능으로 제안된 방식의 효력을 나타냅니다.
2.3 Downstream action classification
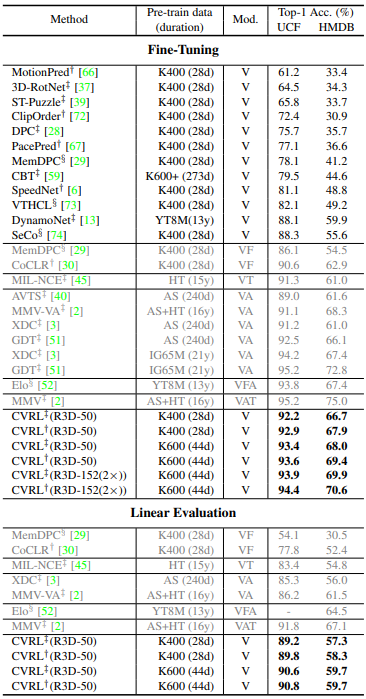
Table 3는 Kinetics 데이터 셋에서 pretrain 시킨 뒤, UCF101과 HMDB51에서 각각 transfer learning 했을 때의 성능입니다. Fine-Tuning의 경우, 모든 layer를 갱신시키며 transfer learning한 것을 의미하며, Linear Evaluation의 경우, backbone network를 freeze 시키고 마지막 linear classifier만 학습시켰을 때의 성능입니다. 두 경우 모두, vision modality만 사용한 CVRL이 multi modality를 사용한 다른 방법론에 거의 근접하거나 능가하는 정도의 성능을 보여주었습니다.
2.4 Ablation Study
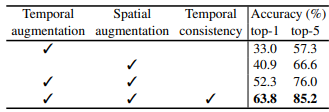
Table 4는 해당 논문에서 제안된 augmentation 기법에 따른 Kinetics 400에서의 linear evaluation 결과 입니다. 각 augmentation 기법들을 하나씩 추가할 때마다 상당히 높은 성능 향상 폭을 보여주며, 해당 논문에서 제안된 augmentation 방식이 추후 video 연구에서 필수적임을 시사합니다.
Reference
[1] https://arxiv.org/pdf/2008.03800.pdf
좋은 리뷰 감사합니다.
1. temporal augmentation 부분이 잘 이해가 안되어 질문드립니다.
temporal augmentation이라는 것이 Fig 4의 실험에 따라 (a)형태로 positive pair를 샘플링하는 것 자체를 의미하는 것인가요? 그것이 맞다면 2.4 ablation study 부분에 temporal augmentation을 제외한 성능은 positive pair를 같은 동영상 내의 랜덤 클립으로 샘플링했을 때의 성능을 말하는 것인지도 궁금합니다.
2. 또한 spatial augmentation을 수행하는 Algorithm1에서 flip, jitter, grey를 각각 다른 확률로 적용해주는데, 확률의 수치도 저자들이 실험적으로 찾아낸 것인지, 아니면 이 분야만의 관례가 있는것인지 궁금합니다!