캡스톤에서 V2V를 하게 되어 Video Retrieval관련 논문을 찾아보게 되었습니다. content-based video retrieval이기는 하지만 contribution을 읽어봤을 때, 영상적인 측면에서 기여가 있다고 판단하여 읽게 되었습니다.
Abstract
해당 논문은 유사한 비디오를 찾는 과정에 classifier없이 쿼리 비디오의 카테고리를 예측하기 위해 각 카테고리에 대해 deep feature의 프로토타입을 계산하는 PCA-CBVP기반의 CBVR 방식을 제안한다. 또한 Fine Search 과정을 통해 쿼리 비디오와 가장 유사한 비디오를 찾는 과정을 제안한다. 논문에서 제안한 방법론은 데이터베이스가 업데이트 되어도 classifier를 다시 학습시킬 필요가 없고, few-shot learning 방식을 이용하여 3D CNN feature extractor을 fine-tuing하였다. 또한 프래임을 균일하게 샘플링하지 않고, 두드러지는 프레임을 샘플링하여 PCA-CBVR의 성능을 향상시켰다.
Introduction
비디오에는 motion, audio, text 정보가 포함된다. 이러한 다양한 content를 활용하기 위한 CBVR(content based video retrieval)이 연구된다. 딥러닝 기반의 CBVR 방법의 문제 중, 이 논문에서는 다음의 문제들을 해결하려 한다.
- 차원 축소로 인한 정보 손실
비디오를 deep feature로 압축하여 사용하기 때문에 발생하는 문제 - 데이터베이스 업데이트 시 classifier 재학습 필요
기존 연구는 사용자의 쿼리 데이터의 카테고리를 예측하기 위해 데이터베이스에 있는 비디오로 classifier가 학습되므로 데이터베이스가 업데이트 되면 재학습이 필요했음. 하지만 실제 비디오 검색에서는 데이터베이스가 계속 업데이트 되므로 classifier를 계속 재학습해야 함. - 학습 cycle을 줄이기 위한 새로운 domain adaptation 능력
데이터베이스가 업데이트될 경우 새로운 카테고리가 추가될 수 있음. 이때 추가적인 학습 없이 도메인 adaptatio을 적용할 수 있다면 시간과 자원을 효율적을 활용할 수 있음. - 효율적 비디오 검색을 위한 비디오 프레임 샘플링
의미있는 프레임들로 비디오 검색을 하는 것이 더욱 좋은 성능을 가져옴.
이러한 문제를 해결하기 위해 PCA-CBVR(prototypical category approximation)이라는 방법론을 제안한다. PCA-CBVR은 차원축소와 classifier 없이 쿼리 비디오의 카테고리를 예측한 후 fine-search 단계를 통해 가장 유사한 비디오를 찾는다. (1,2 문제 해결을 위한) 또한 few-shot learning방식의 fine-tuning을 적용하고 cross-domain 평가를 통해 도메인 adaptation능력을 높일 수 있는 지 검증한다.( 3 문제 해결을 위한) 마지막으로 두드러지는 프레임을 샘플링하는 방식을 적용하여 성능이 향상되는 것을 확인한다.(4 문제 해결을 위한)
PCA-CBVR
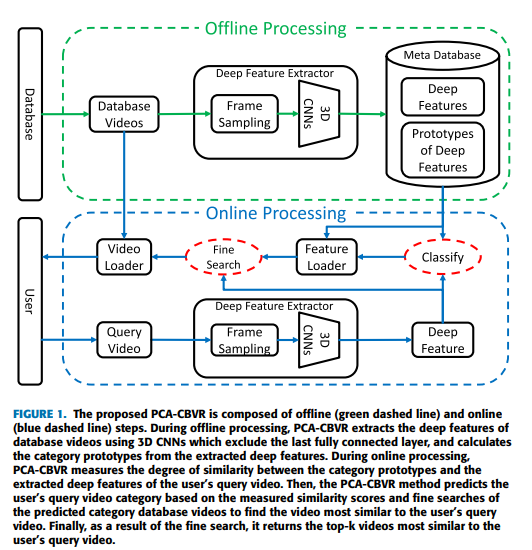
offline 프로세스_데이터베이스 비디오의 카테고리 원형을 저장하고 계산
- 데이터베이스의 비디오를 균일하게 16프레임으로 샘플링하고 112×112로 resize한다.
- 마지막 fc-layer를 제거한 pre-trained 3D CNN을 이용하여 deep feature를 추출한다.
- 각 카테고리에서 추출된 deep feature의 프로토타입을 계산한다.
- meta-database에 카테고리 프로토타입을 저장한다.
online 프로세스_사용자의 쿼리 비디오와 가장 유사한 데이터베이스 비디오를 검색
- 데이터베이스의 비디오를 균일하게 16프레임으로 샘플링하고 112×112로 resize한다.
- 마지막 fc-layer를 제거한 pre-trained 3D CNN을 이용하여 deep feature를 추출한다.
- meta database에 있는 카테고리 프로토타입 통해 쿼리비디오의 카테고리를 예측한다.
- 사용자의 쿼리 비디오와 유사한 비디오를 정밀하게 탐색한다.
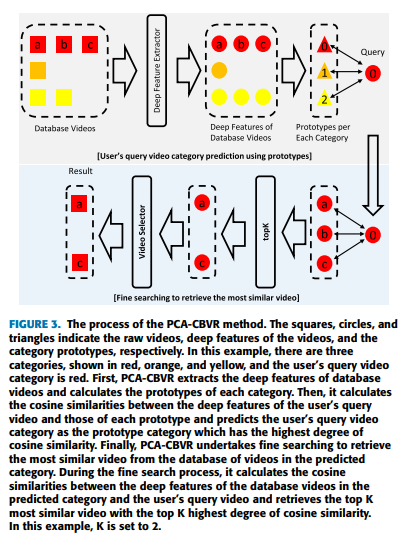
User’s query video category predictions with prototypes
데이터베이스가 업데이터 되면 분류기를 재학습해야하므로 분류기 없이 쿼리 비디오을 분류하기 위해 Prototypical networks for fewshot learning(2017) 논문에서 제안한 prototypical category approximation technique을 사용한다.
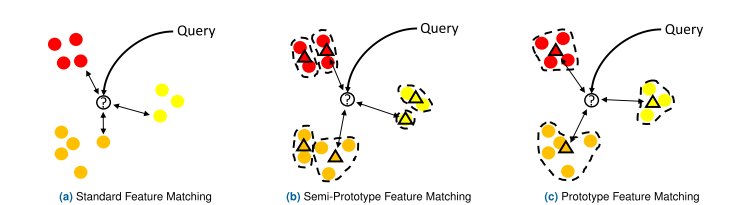
일반적으로 사용하는 (a)방식은 데이터베이스 내의 모든 비디오와 비교하여 쿼리 비디오의 카테고리를 예측하는 방식은 시간과 메모리가 많이 필요하다. (b),(c) 와 같이 K-means 클러스터링 알고리즘을 이용하여 deep feature 매칭 포인트를 줄일 수 있다. 다음 식은 분류기 없이 쿼리 비디오의 카테고리를 예측하는 식이다.
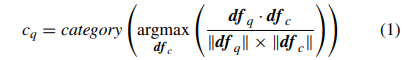
c_q는 예측하고싶은 쿼리 비디오의 카테고리, df_q는 쿼리비디오의 deep feature, df_c는 데이터베이스 비디오의 클러스터의 중심(centroid)를 나타낸다. 코사인 similarity가 가장 큰 클러스터 중심을 카테고리로 예측한다. 각 카테고리의 클러스터 수를 1로 설정하면 제안한 PCA-CBVR 방식으로, K-meanse 클러스터링 방식을 적용하지 않아도 되며, df_c는 다음 식으로 계산할 수 있다.
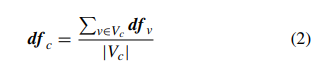

Fine searching on the selected embedding space
쿼리비디오를 예측한 이후, 가장 유사한 비디오를 찾기 위한 과정으로 다음 식으로 표현할 수 있다.
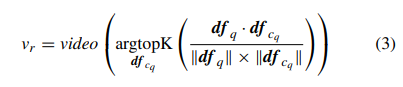
v_r은 검색되는 비디오를 의미하고 argtopK는 상위 랭킹에 있는 K개의 비디오를 의미한다. df_{c_q}는 예측된 카테고리에 해당하는, 데이터베이스에 있는 비디오의 deep feature를 나타낸다.
Experiments and Result
PCA-CBVR을 활용한 성능

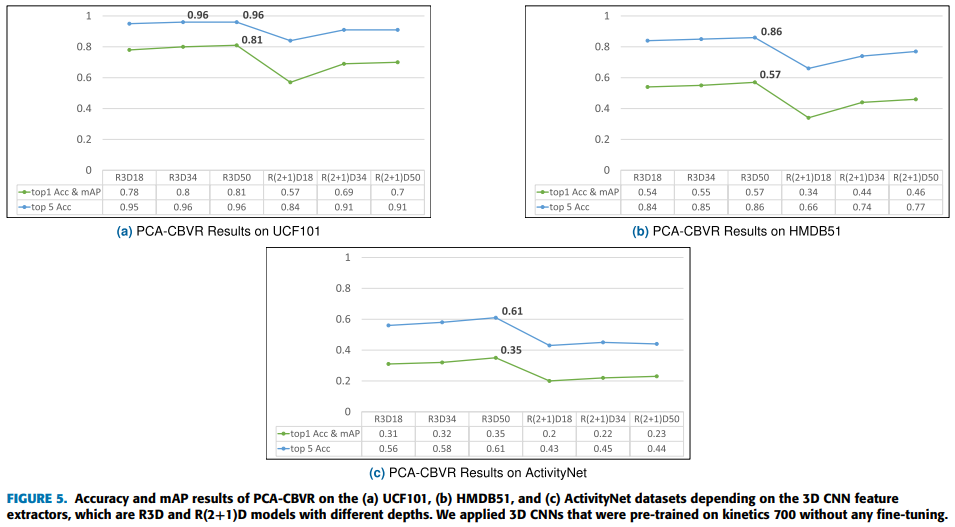

Cross-domain evaluation for the PCA-CBVR domain adaptation ability
사용자의 쿼리 비디오와 데이터베이스의 도메인이 다른 문제를 해결하기 위해 domain-adaptation능력을 높여야 한다. 이를 위해 few-shot learning방식을 따라 3D CNN의 feature extractor를 fine-tuning하였다.
샘플링 되지 않은 비디오 데이터를 쿼리비디오, 잘린 작은 크기의 데이터가 데이터베이스라고 가정하였다. UCF101로 모델을 fine-tuning하고, ActivityNet데이터에 대해 평가하였다. 5-way 1-shot, 5-way 5-shot, and 5-way 10-shot의 상황으로 실험을 하였고 그 결과를 표 6에 작성하였다.
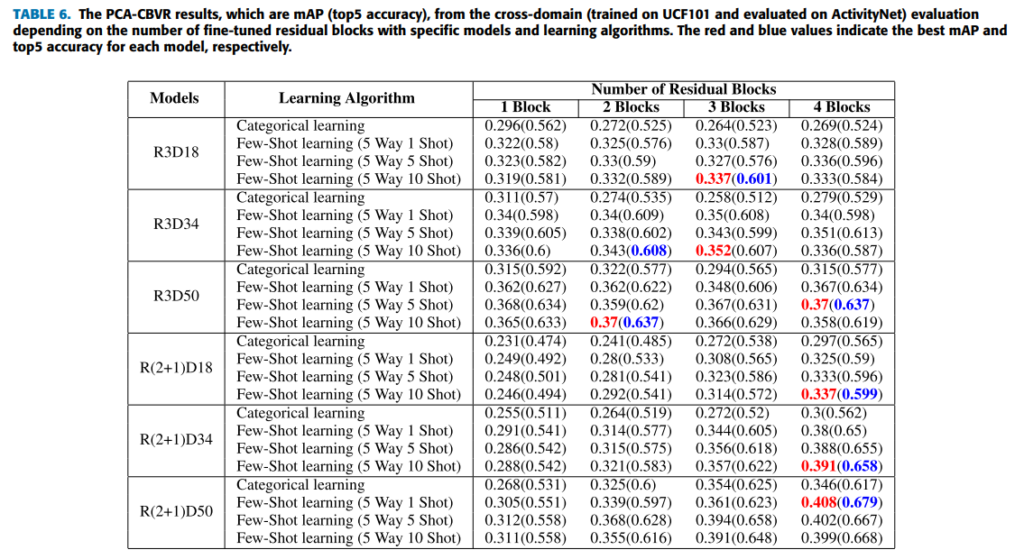
fine-tuning한 블록을 다르게 조정
Random selection vs. Fine searching
예측된 카테고리에서 비디오를 선택할 때 랜덤하게 비디오를 선택한 경우 아래 그림과 같이 영상이 유사하지만 실제로는 다른 비디오를 가져오게 도리 수 있다. 따라서 fine-searching을 이용해야 한다. fine-searching은 예측된 영상의 카테고리를 Mixing이라 할 때, 거품기, 볼 등을 포함한 영상을 검색한다.

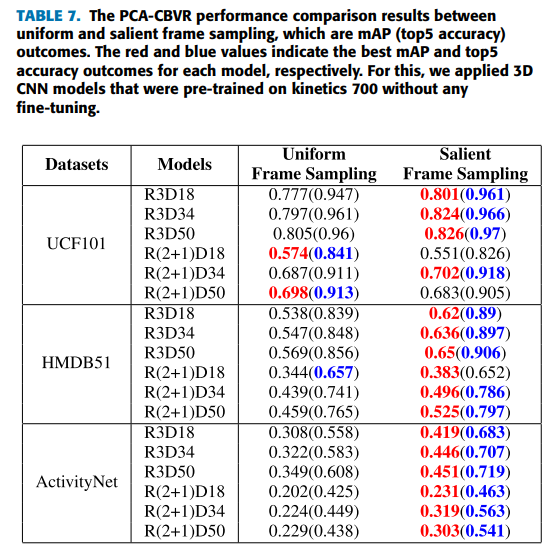
Uniform frame sampling vs. salient frame sampling
PCA-CBVR은 프로토타입으로 사용자의 쿼리 비디오의 카테고리르 에측하므로, deep feature에 특이치가 많으면 프로토타입의 표현혁에 영향을 준다. deep feature를 추출하는 프레임을 샘플링하는 방식을 비교하기 위해 (1)균일한 샘플링을 통해 무작위로 프레임을 선택하는 방식과 (2) 모든 deep feature의 평균을 통해 비디오의 무의미한 프레임과 특이한 프레임을 제거하는 방식으로 실험을 하였다.
비디오 retrieval 과정을 이해하기 좋을 것 같아 읽어본 논문입니다. 특별히 새롭게 제안하는 내용이 있는 것이 아니고 방법론들을 활용하여 개선한 논문인 듯 합니다.
salient frame sampling 에 대한 설명은 실험부분에서만 나오는건가요? 정확히 어떻게 sampling 하는것인지 이해가 잘 안갑니다.
deep feature들의 평균값을 계산하고 모든 deep feature들과 평균값의 코사인 similarity를 구한 뒤, 내림차순으로 정렬하여 상위 n개만 선택한 후 다시 정렬하여 해당 인덱스에 해당하는 프레임을 샘플링하는 방식입니다.
리뷰 잘 읽었습니다! PCA-CBVR 에 대해 궁금한 점이 있어 질문 남깁니다.
“각 카테고리의 클러스터 수를 1로 설정하면 제안한 PCA-CBVR 방식으로, K-meanse 클러스터링 방식을 적용하지 않아도 되며” 라는 말이 있는데 뒤에서는 “위의 표와 같이 클러스터링 방식을 정의한다. 왼쪽부터 순서대로 (a),(b),(c)방식이다. K는 K-meanse clustering알고리즘으로” 라는 말이 있어서요. 아마 다른 논문에서 가져온 거라 동일한 방식을 갖고 K-means 가 맞다고도 하고, 아니라고도 하는 것 같습니다. 본 논문에서는 K-means clustering 방식을 무엇이라고 정의한건가요?
카테고리마다 하나의 값을 뽑으면 되기 때문에 클러스터링방식이 아닌 식(2)를 이용하면 된다고 이해하였습니다. 여기서 말한 ” K-meanse 클러스터링 방식을 적용하지 않아도 되며”라는 의미는 (b)와같이 유사한 데이터들을 모아주는 과정을 하지 않아도 된다는 의미로 이해하였습니다.
논문 출처를 같이 밝혀주시면 좋을 것 같네요.