
Text-Video 데이터셋으로 많이 쓰이는 HowTo100M 에 대한 리뷰입니다.
본 논문의 주요 컨트리뷰션은 아래의 세 가지 입니다.
- 기존 데이터셋들보다 Large-scale 인, Text-Video 데이터셋
HowTo100M제안 HowTo100M을 이용하여 학습한text-video embedding을 이용했을 때,instructional video데이터셋(ex. YouCook, CrossTalk)을 이용하는 text-to-video retrieval 과 action localization 에서 sota 달성HowTo100M을 이용하여 학습한text-video embedding을 이용하고, 다른 도메인의 데이터셋(ex. 일반적인 유튜브 비디오 데이터셋인 MSR-VTT, 영화 데이터셋인 LSMDC)으로 finetuning 했을 때, 해당 도메인의 데이터셋만을 이용하여 학습한 모델의 성능 능가
HowTo100M 이라는 데이터셋을 제안하는 것이 가장 큰 컨트리뷰션이고, 다른 컨트리뷰션도 이를 바탕으로 이뤄진 것이기 때문에, 해당 데이터셋이 어떻게 수집되고 구성되었는지를 먼저 살펴보겠습니다
wikiHow
우선 해당 데이터셋에 대해 설명하기 앞서, wikiHow 라는 커뮤니티 사이트에 대해 소개해보도록 하겠습니다.
wikiHow는 다양한 기술에 대한 메뉴얼을 제공하는 사이트입니다. 덕분에, ‘how to ~’ 로 시작하는 수많은 article 들이 존재하죠. 이 사이트를 이용하면 ‘~하는 방법’, 즉, 어떠한 행동을 묘사하는 문장을 얻을 수 있게 됩니다.
많은 web instructional videos 데이터셋들은 이 wikiHow 로부터 인기있는(많이 사용되는) query text 를 수집하고, 해당 query text 를 Youtube에서 검색어로 이용하여 비디오를 수집합니다. 그럼 이 비디오는 query text 를 보여주는 instructional videos 가 되는 것이죠. 즉, text 는 해당 video 를 설명하게 되는 것입니다.
Instructional videos 를 이용하여 모델을 학습을 하는 것은 아래와 같이 다양한 분야에서 인기를 끌었다고 합니다. 즉, Instructional videos 를 text 와 함께 사용했을 때 video 에 대한 representation 을 잘 학습할 수 있다는 의미로 이해하였습니다.
- learning steps of complex task
- visual-linguistic reference resolution
- action segmentation in long untrimmed videos
- joint learning of objcet states and actions
해당 논문 또한 wikiHow 를 이용하는 접근 방식을 통해 Instructional videos 을 수집하여 HowTo100M 를 만들었습니다.
HowTo100M
데이터셋 구축 이유
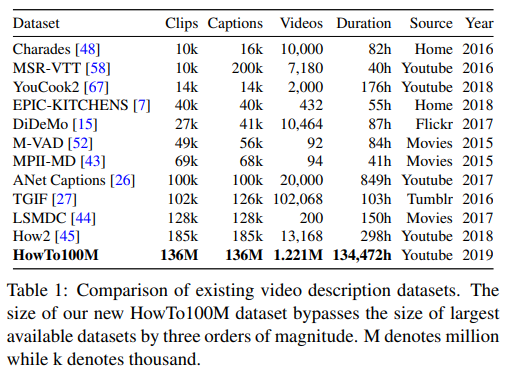
HowTo100M 은 기존 데이터셋들과 비교했을 때 우선 양 적인 측면에서 압도적입니다. 뿐만 아니라, 특정 도메인에 얽매이지 않기 때문에 다양한 데이터를 포함합니다. 그렇다면, 왜 이렇게나 많은 데이터를 수집하여 데이터셋을 구축하였을까요? 본 논문은 NLP 에서의 BERT, GPT, GPT-2 와 같은 Language Models 에게 영향을 받았다고 합니다. 이러한 모델들은 Large-scale 의 데이터로 학습되었는데, 이를 이용하였을 때 다양한 tasks에 대해서 sota를 달성했고, Zero-shot 세팅에서도 sota 를 달성했었습니다. (ex. 학습할 때 사용하지 않은 unseen 데이터를 seen 데이터의 class 로 예측) 또한 vision 분야에서는 image meta 데이터를 이용하여 image classifiers 를 pretrain 하는 연구에게도 영향을 받았다고 합니다.
따라서, 이러한 Large-scale 의 데이터셋을 사용하면 Video-language 의 joint understanding 을 잘 해내는, 강력한 embedding 을 학습할 수 있을 거란 기대로 HowTo100M 데이터셋이 만들어졌습니다.
비디오-자막 데이터 수집 방법
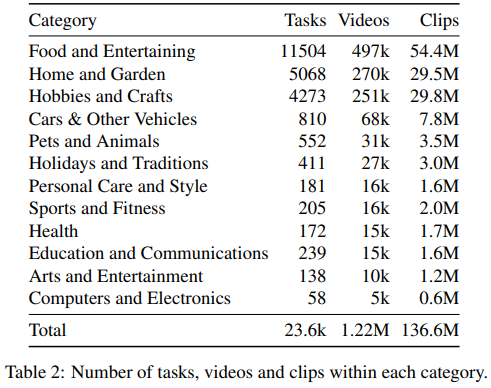
- wikiHow 로부터 a large list of activities 수집
- 12 개의 카테고리에서 23,611 개의 visual tasks 수집 (비디오 검색 시 query 로 쓰이는 text)
- a large list of activities 중에서, visual tasks 를 나타내도록 12개의 카테고리로 제한
- 추상적인 카테고리 (Relationships, Finance and Business) 제외
- primary verbs 는 physical actions (ex. make, build, change)으로 제한
- primary verbs 가 non-physical verbs (ex. be, accept, feel)이면 제외
- 앞서 수집한 visual tasks 를 이용하여, Youtube 에서 “자막”이 있는 “intructionanl videos” 수집
- 검색어 예시 : how to paint furniture
- 영어 자막이 있는 비디오들로 제한 (manually / automatically 상관 없음)
- 검색 시 top 200 안에 있는 것으로 제한
- 시청 수가 100 view 미만이면 제외
- 자막의 words 수가 100개 미만이면 제외
- 비디오의 길이가 2,000 초 보다 길면 제외
HowTo100M 은 이러한 방식으로, video-language embedding 을 잘 학습할 수 있을 만한 비디오-자막 쌍으로 구성된 데이터를 수집하였습니다. 이를 이용하여 클립-캡션 쌍으로 구성된 데이터셋을 구축합니다. 이때, 수집된 비디오들의 평균 duration 은 6.5 분 입니다.
클립-캡션 데이터 구축 방법
- 앞서 수집한 데이터에는, 하나의 비디오와 그에 대한 자막이 있습니다.
- 그런데 이 자막은 비디오를 시간대 별로 설명하기 때문에, video-language embedding 을 학습하기 위해서는 하나의 문장이 하나의 영상을 표현하도록 데이터셋을 구축해줘야 합니다.
- 이때, 자막에 있는 하나의 문장이 “캡션” 이고, 그 캡션이 설명하는 비디오의 일부 구간 영상을 “클립”이라고 합니다.

클립-캡션 쌍으로 구성된 다른 데이터셋으로는 MSR-VTT 가 있습니다. 이는 사람이 클립을 직접 보고 캡션을 manually 하게 annotated 했는데, HowTo100M 은 이와 달리 narration(subtitle) 을 이용하여 automatically 하게 annotated 됩니다. 때문에 효율 측면을 고려했을 때, 적은 cost 로 큰 데이터셋을 구축할 수 있었습니다.
영상의 바깥에 있는 사람의 목소리가 narration에 포함이 되어 있는 경우도 있는데, 확인해본 결과 narration 이 영상에 보여지는 물체에 대해 이야기하는 경우도 있기 때문에, joint embedding 학습에 유용할 수도 있을거라 생각하여 제외하지 않고 진행하였다고 합니다. 뿐만 아니라 문법적으로 올바르지 않은 경우도 있고, 문장이 아닌 단순 단어의 나열 형태로 이루어진 경우도 있어서, 이를 이용하여 생성한 caption 은 불완전합니다. 즉, clean-annotated captions 을 갖고 있지 않고, 이로 인해 Weakly-paired 된 데이터셋이라고 표현됩니다.
앞서 수집한 비디오들을 이용했을 때, 하나의 비디오(+자막)는 평균 110 쌍의 클립-캡션 쌍을 생성합니다. 이때 평균적으로, 클립의 duration 은 4초, 캡션에 포함된 words 수는 4개 입니다. 데이터셋에 대한 추가적인 설명은 Appendix 에 포함되어 있습니다.
Text-video joint embedding model
용어 정의
앞서 말했던 HowTo100M 의 클립을 여기서 말하는 비디오로 이용한다고 보시면 됩니다.
- 비디오(클립) : V
- 캡션 : C
- 비디오 V 를 나타내는 d_v 차원의 feature representaion : v \in R^{d_v}
- 캡션 C를 나타내는 d_c차원의 feature representation : c \in R^{d_c}
- i 번째 비디오-캡션 쌍 : (V_i, C_i)
- n 개의 비디오-캡션 쌍으로 이루어진 set : \{(V_i, C_i)\}^{n}_{i=1}
이때, HowTo100M 데이터셋을 이용하여 학습하고자 하는 것은 클립 feature와 캡션 feature를 같은 embedding space 에 위치하도록 만들기 위한, video-language embedding model 이었습니다. 즉, 두 feature 를 같은 차원 (이하 d 차원)에 위치하도록 임베딩 시켜주는 함수를 학습하는 것이 해당 embedding model 의 목표입니다.
- f : R^{d_v} → R^{d} : d_v 차원의 video feature 를 d d 차원으로 mapping 시켜주는 함수
- g : R^{d_c} → R^{d} : d_c 차원의 caption feature 를 d d 차원으로 mapping 시켜주는 함수
해당 함수를 이용하면, 비디오 V 와 캡션 C 의 feature 를 동일한 d 차원에서 embed 할 수 있기 때문에, 단순히 이 공간에서의 cosine similarity 를 계산하여 이 둘 간의 유사도를 계산할 수 있게 됩니다. 이 유사도 점수가 높을 수록, 비디오 V 와 캡션 C 가 유사한 것입니다.
- s(V,C) = {<f(v), g(c)>} \over {{||f(v)||}_{2}* {||g(c)||}_{2}}
본 논문에서는 이전 논문에서 사용한 방법에 따라, non-linear 한 형태의 embedding fucntion 을 사용하였습니다.

해당 함수는 입력으로 사용하는 input feature vector 간의 non-linear 한 multiplicative interaction 을 잘 모델링하여 text-video embedding 을 할 때 효과적인 함수이라는 것이 증명되어 왔기에, 이를 사용하였습니다.
Loss
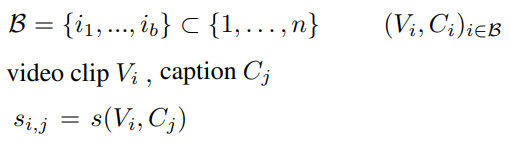
우선, 앞서 정의 했듯이 데이터셋에는 n개의 비디오클립-캡션 쌍이 있습니다.
이 데이터셋을 이용하여 학습할 때 mini-batch 로 샘플링하여 학습합니다. 이 batch 에는 B 개의 클립-캡션을 포함합니다. 이때, 각 클립에 대해 Negative 한 캡션과의 유사도와 유사한 캡션과의 유사도의 차이, 각 캡션에 대해 Negative 한 클립의 유사도와 유사한 클립과의 유사도 차이를 아래와 같이 이용하는 Margin ranking loss 를 사용하여 학습합니다.
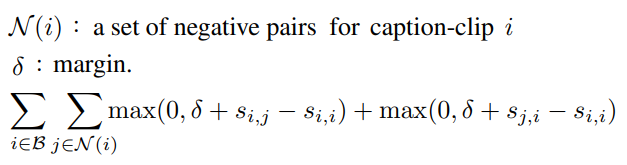
이때, 본 논문에서는 margin 값은 0.1, lr 은 le-4 , optimizer 는 Adam 으로 설정하여 학습을 진행했습니다.
이때, i번째 caption-clip 에 대한 negative pairs 는 절반은 다른 영상에서 가져왔고, 나머지 절반은 intra-negative sampling strategy 를 적용하여 만들었습니다. 이는, 동일한 영상으로부터 negative sample을 만들기 때문에, 모델이 background 같이 상관없는 feature 에 집중하지 않도록 하여 텍스트와 영상이 서로 상관있는 feature 에 집중하도록 만들어주는 효과가 있습니다. 실험을 통해, 이 기법을 사용했을 때 성능 향상에 크게 도움이 됐다는 것을 보여주기도 하였습니다.
Experiments
본 논문에서는 HowTo100M 을 이용하여 학습한 video-test embedding function 이 강력하고, 이를 통해 생성한 representation 이 여러 task / 데이터셋에서 유용하다는 것을 보이기 위해, 다양한 데이터셋에서 실험을 진행했습니다.
Datasets (다양한 domain)
- CrossTask : instruction videos
- YouCook2 : cooking vidoes
- MSR-VTT : generic YouTube videos
- LMSDC : movie video clips
Tasks
- Step localization in insturcion videos : CrossTask
- Text based video retrieval : YouCook2, MSR-VTT, LSMDC
Video features
본 논문에서는 2D CNN 과 3D CNN 을 이용하여 video features 를 추출하였습니다.
- 2D CNN : ImageNet pre-trained ResNet-152 (rate : 1 frame per second) → frame-level features
- 3D CNN : Kinetics pre-trained ResNeXt-101 16-frames model (1.5 features per second) → video-level features
- 하나의 video clip 으로부터 추출한 두 features 를 concat 하여, sinlge vector R^{d_v}, (d_v = 4096) 를 만듭니다. 이를 video feature 로 사용합니다.
- 이때, 길이가 긴 video clip 으로부터 뽑은 features 는 temporal maxpooling 을 통해 aggregate 한 후, concat 하여 사용합니다.
Text features
- 우선, transcribed 된 video narrations 으로부터 ‘common English stop-words’ 를 버립니다.
- Word2Vector : GoogleNews pre-trained word2vec embedding model → word representation
- sentence 로부터 만든 이 representation을, text features R^{d_c} 로 사용합니다.
Negative pair sampling strategy
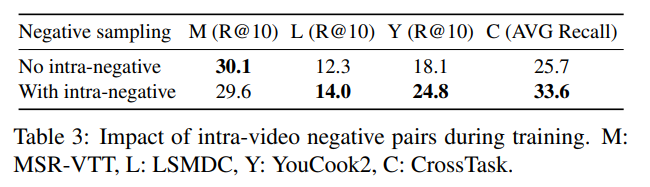
실험을 통해 해당 전략을 사용했을 때의 성능이 대체로 높았습니다. 이때, 데이터셋이 더 fine-grained 할 수록, 즉, MSR-VTT 나 LSMDC 보다 YouCook2 와 CrossTask 에서 성능이 비교적 많이 올랐음을 알 수 있습니다.
CrossTask
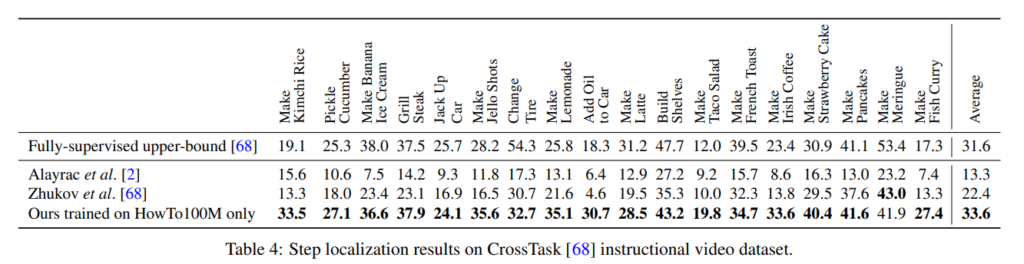
해당 데이터셋에서, 하나의 task 만을 제외하고는 모두 성능이 향상되었습니다. 이는 많은 양의 narrated videos 를 이용하여 학습하는 것이, carefully 하게 annotated 된 적은 양의 데이터셋을 사용하는 것보다 학습이 잘 된다는 것을 보여줍니다.
YouCook2
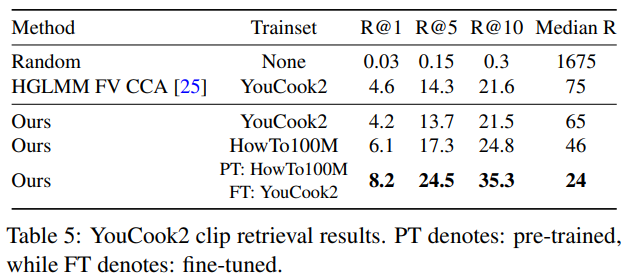
YouCook2 에서 제공하는 clip retrieval 벤치마크는 없기 때문에, 당시 sota 인 text-video embedding model, HGLMM FV CCA 를 이용하여 성능을 비교하였습니다. 그리고 Clip retrieval 에 대한 성능을 평가하였을 때, YouCook2 을 이용하여 학습시키는 것보다 더 큰 스케일의 HowTo100M 을 이용하여 학습시켰을 때 성능이 좋고, 이보다는 HowTo100M 을 이용하여 pretraining 을 시킨 후 YouCook2 을 이용하여 Fine-tuning 을 시킨 모델이 성능이 좋다는 것을 알 수 있었습니다.
MSR-VTT
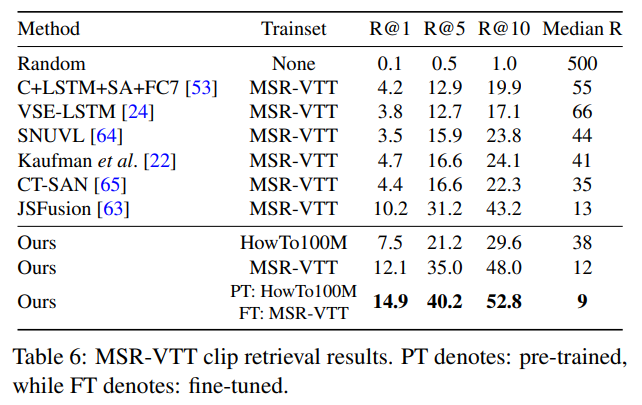
MSR-VTT 의 YouCook과는 다르게, HowTo100M 만을 이용하여 학습했을 때의 성능보다 MSR-VTT 를 이용하여 학습했을 때의 성능이 높았습니다. 저자는 이 이유를 HowTo100M 데이터셋이 YouCook과는 유사한데, MSR-VTT 데이터셋과 내용적인 측면에서 다르기 때문이라고 분석하였습니다. MSR-VTT 도, 마찬가지로 한 가지 데이터셋만을 이용하여 학습했을 때 보다 HowTo100M 으로 pretrain 을 한 후 MSR-VTT로 finetuning 을 했을 때 성능이 향상됐음을 볼 수 있었습니다.
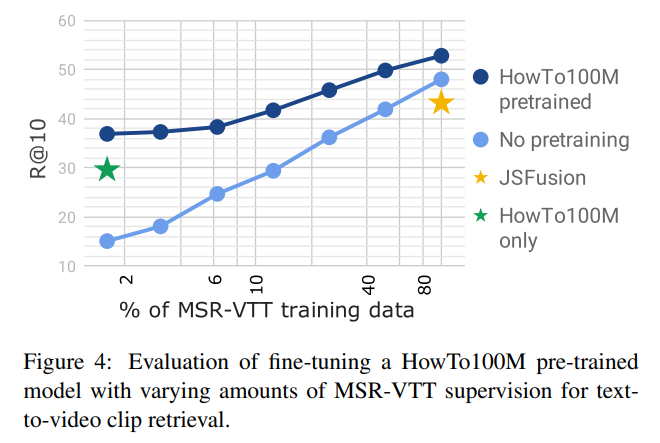
또한, HowTo100M 으로 pretrained 된 모델을 이용하여 MSR-VTT 데이터셋으로 fine-tuning 을 할 때, MSR-VTT의 양을 늘리면서 학습을 해보았는데, MSR-VTT 데이터셋의 양이 늘어날 수록 성능이 오르는 것을 알 수 있었습니다. 또한 당시 MSR-VTT 만을 이용하여 학습한 sota 모델은, HowTo100M 으로 pretrained 된 모델이 MSR-VTT 의 20%를 사용했을 때 달성하고, 더 사용하면 이를 능가한다는 것을 볼 수 있었습니다.
LSMDC
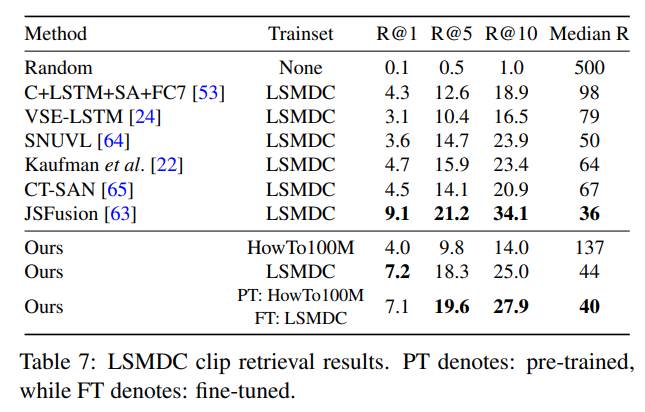
LSMDC 도 MSR-VTT 와 유사한 경향을 보였습니다.
Cross-dataset fine-tuning evaluation
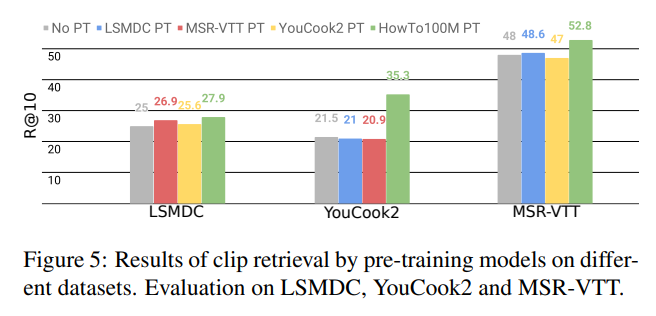
다양한 데이터셋으로 pretrained 된 모델을, 다양한 데이터셋으로 finetuning 시킨 성능을 측정하여 Cross-dataset 평가를 진행하였습니다. 결론적으로, HowTo100M 을 이용하여 pretrainig 을 시켰을 때의 성능이 항상 가장 좋은 성능을 보였습니다.
Qualitative results

HowTo100M 을 이용하여 학습한 joint text-video embedding model 을 이용한 text-video retrieval 결과입니다. 이는 현재 해당 사이트 를 이용하여 검색해볼 수도 있습니다. NLP 분야에서의 연구를 기반으로, 텍스트-비디오 데이터셋의 양을 늘릴 수 있고, 이를 이용하여 구축한 Large-scale의 Dataset 과 Pretraining 의 중요성을 알 수 있었습니다.