MoCo에 이어 Self-Superviesd Learning 의 근본 시리즈 2번째 편입니다.
지난번에 리뷰한 MoCo 역시 Self-Supervised Learning과 관련한 논문이었는데요. 오늘 제가 리뷰하는 SimCLR를 읽고 근본 시리즈 1편이 궁금하신 분들은 MoCo 리뷰 역시 읽어보시는 것을 추천드립니다.
[ Self-Learning 근본 시리즈 1편 ] [CVPR 2020] Momentum Contrast for Unsupervised Visual Representation Learning
MoCo는 FAIR에서 발표한 논문입니다. (저자가 무려 Kaiming He 랍니다) 무서운 기세로 딱 2달 뒤에 Google Research에서 Self-supervised Learning 방법론을 발표하는데요. 그 논문이 바로 제가 지금 리뷰하려는 “SimCLR” 입니다. ( SimCLR는 무려 제프리 힌튼 교수님이 저자로 참여한 논문…)
여담으로 짧은 전성기로 아쉬웠는지 MoCo ver.2가 SimCLR 공개 2달 뒤에 바로 나왔고, 그리고 얼마지나지 않아 SimCLR ver.2 도 발표됩니다… 이게 모두 2019 – 2020년 사이 1년이 채 안된 기간 동안의 이야기라고 하네요
제가 이리 요란하게 리뷰의 시작을 알리는 이유는.. 역시.. 근본 중의 근본 답다 싶은 논문이어서 그렇습니다 허허.. 그럼 바로 리뷰 시작하도록 하겠습니다!
시작에 앞서 제가 본 리뷰에 사용하는 그림은 The Illustrated SimCLR Framework 의 블로그 글에서 가져왔습니다.
그 전에.. Self-supervised learning은 무엇이고, 이런 연구는 왜 필요한지, 그리고 이 분야를 이해하기 위해 알면 좋은 용어들에 대해 정리해봅시다.
Self-Supervised Learning은 왜 등장하였는가?
Supervised Learning은 딥러닝의 인기가 시작됨과 함께 지속적으로 좋은 성능을 달성해와서 많은 연구자들을 딥러닝 연구로 이끈 주역 중 하나입니다. 그런 좋은 성능에는 항상 엄청난 양의 데이터셋이 함께였습니다. 그러나 우리에게 가장 익숙한 Supervised Leanring의 단점은 바로 라벨링된 양질의 데이터셋이 많이 필요하다는 것입니다.
어노테이션 작업을 해보셨다면 이 라벨링된 데이터셋을 구한다는 것은 쉬운 일이 아니라는 것을 느낌적으로 아실 수 있을 것입니다. 라벨링 작업에는 수많은 인력의 시간과 비용이 발생됩니다. 특히 segmentation 을 위한 데이터셋이라고만 생각해도 아찔해지네요. “머릿 수로 때려박으면 되지 뭐!” 라고 생각할 수도 있지만, 만일 의료 데이터 같이 전문적인 지식을 겸비한 “Human Annotator”를 요하는 특성을 가진 데이터셋이라면….. 비용 문제는 심각하게 고려할 문제 중 하나가 되겠죠.
따라서 이런 단점을 극복하기 위해 다양한 연구 분야가 등장하고, 활발하게 연구가 진행되고 있습니다. 고정된 라벨링 비용에서 모델이 최대의 효율을 내는 샘플을 선별하는 Active Learning, 가지고 있는 데이터셋 중에 일부만 labeling을 하여 학습을 시키는 Semi-Supervised Learning, 라벨이 없는 데이터만으로 학습을 진행하는 Unsupervised Learning 등 이 있습니다. (제가 언급한 분야보다 훨씬 많은 분야가 있답니다)
앞서 언급한 라벨을 아예 사용하지 않는 Unsupervised Learning 에 속하는 연구 주제가 바로 Self-Supervised Learning 입니다. Self-Supervised 은 스스로 supervision을 주면서 학습한다고 하여 붙은 이름으로, Unsupervised Learning 답게 Unlabeled 데이터셋만을 사용하여 학습합니다.
Self-Supervised Learning이란 무엇인가?

supervised-learning에서는 라벨을 만드는 과정을 사람이 직접하는 “Manual Annotation” 과정이었죠.
이제 self-supervised learning에서는 이 부분을 데이터의 속성을 creative 하게 활용하여 “pseudo-supervised task”로 대체하게 됩니다. 이제 자연스럽게 드는 질문, “pseudo-supervised task로 대체한다는 것은 무슨 뜻이죠?”

예를 들어 설명하자면, 고양이/강아지 라고 라벨링하여 학습시키는 것 대신에 “고양이-강아지 이미지를 0/90/180/270도로 회전시킨 다음, 그 회전된 각도를 맞추는 문제로 모델을 학습시키는 것”으로 문제를 바꾸는 것입니다. 이렇게 될 경우, 모델이 고양이/강아지의 라벨은 모르지만, 데이터를 0/90/180/270 도로 회전시키면서 모델은 회전 각도라는 새로운 라벨을 알 수 있게 됩니다. 이제 이 라벨을 가지고 모델은 supervised-learning을 할 수 있겠죠. 진짜 GT가 아닌 데이터 augmentation을 통해 가짜(?) 라벨을 부여하여 supervised learning을 한다고 하여 “pseudo-supervised task” 라고 한 것입니다. 그리고 이렇게 라벨이 없는 데이터에 대해 새로운 문제를 정의하고 라벨을 직접 부여한다는 의미로 “스스로 supervision을 준다”는 것을 이해하시면 좋을 것 같습니다.
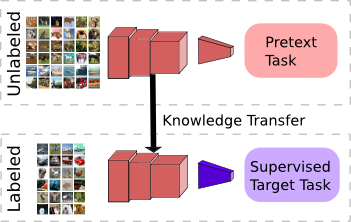
이렇게 모델이 데이터의 라벨을 스스로 부여할 수 있도록 사용자가 직접 정의한 새로운 문제를 바로 pretext task 라고 합니다. 앞서 설명한 예시에서는 바로 고양이/강아지 사진을 augmentation한 이미지들에 대하여 rotation을 맞추는 것이 pretext task가 되겠네요! 이제 정의한 pretext task을 통해 모델을 prertraining 시킨 뒤, 궁극적으로 사용자가 풀고자 하는 downstream task 로 transfer learning 을 하는 과정이 바로 self-supervised learning의 핵심이 됩니다. 위에 나와있는 그림처럼 pretext로 학습한 Network를 그대로 가지고 와서 해결하려고 했던 downstream task에 대해 학습시키는 방식이죠. 이 때, downstream task는 classification, object detection, segmentation 등에 다양한 방법론에 해당됩니다. 위에 나와있는 그림에서는 보라색으로 쓰여있는 Supervised Target Task 가 바로 downstream task가 되겠네요.
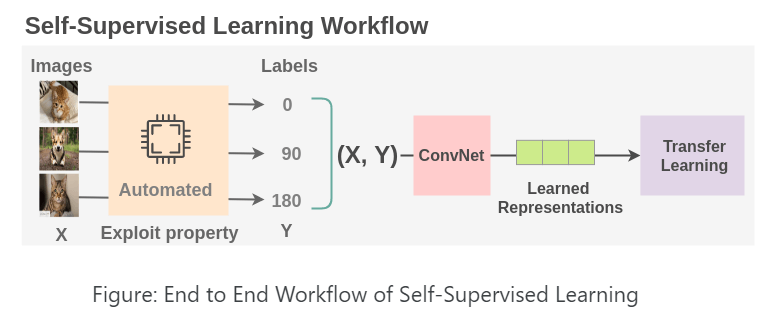
결국 self-supervised learning에서, pretext task를 통해 학습된 모델은 데이터에 대한 좋은 representation을 가질 feature를 생성해내기도, 데이터 자체에 대한 이해를 높일 수도 있게 된다는 배경을 바탕으로 다양한 연구가 진행되었습니다. 어떤 pretext task가 있었는지까지 다루면 리뷰가 너어무 길어질 것 같아 이에 대한 자세한 내용이 궁금하신 분들은 The Illustrated Self-Supervised Learning 을 읽어보시는 것을 추천드립니다.
Pretext Task 에서 Contrastive Learning으로!
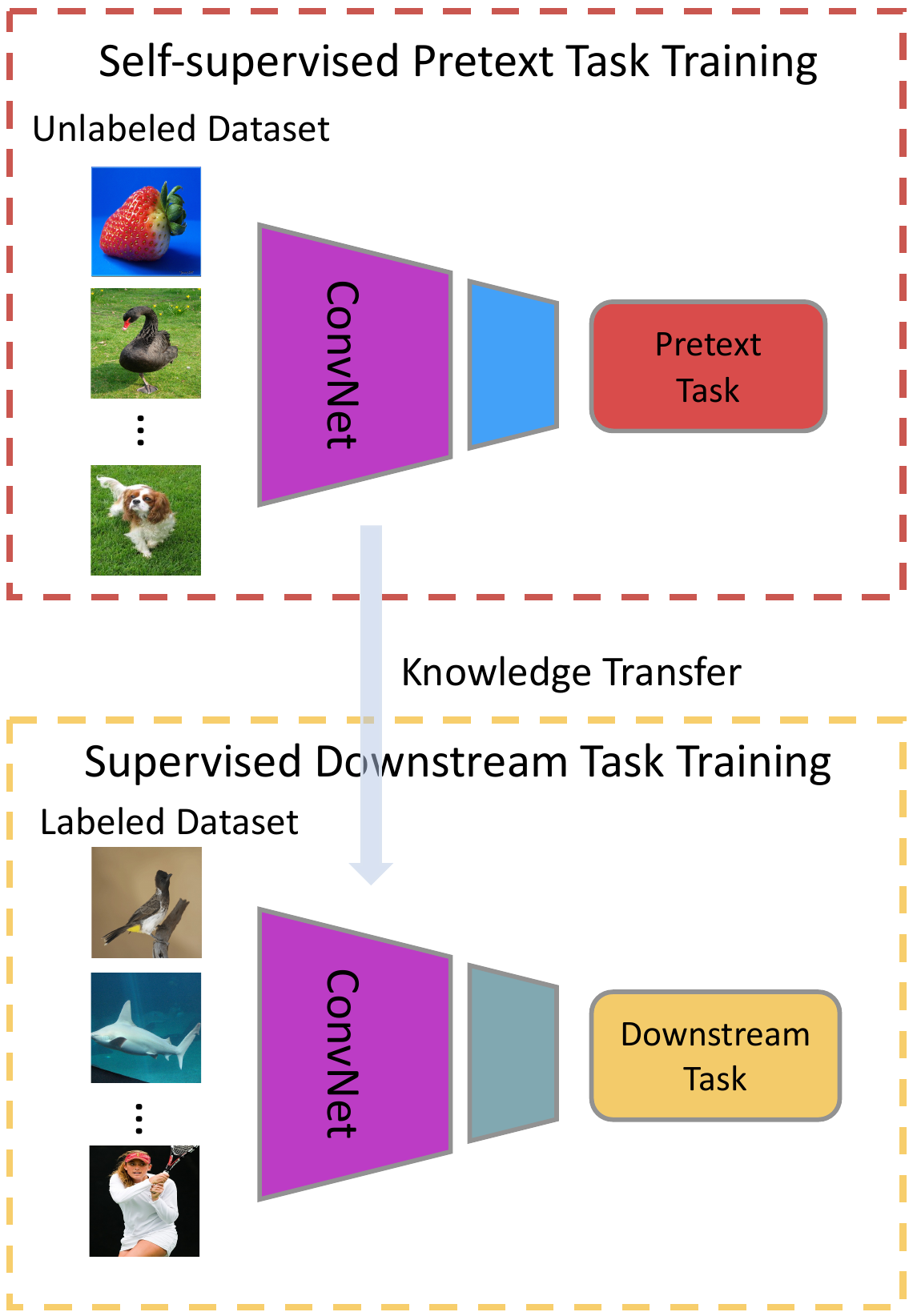
결국 self-supervised learning을 정리하면,
- 정의한 pretext task로 feature를 추출하는 Feature Extractor (Net.)를 pre-training 하고
- 학습 완료한 Feature Extractor (Net.)를 Downstream Task를 위한 모델로 다시 학습
이게 바로 기존 pretext 기반 self-supervised learning의 workflow 였습니다.
이런 pretext task 기반의 self-supervised learning 논문들은 scratch (random init) 로 학습시킨 모델보다는 훨씬 좋은 성능을 보였지만, 여전히 supervised leanring으로 학습시킨 feature extractor 에 비하면 부족한 성능을 가지곤 하였습니다.
그러다 Supervised 와 격차를 줄인 self-supervised elanring의 연구들이 등장하게 되는데요, 바로 constrasitve learning 방식을 사용하여 그 격차를 줄이고 좋은 성능을 낼 수 있었다고 합니다.
이제 이 contrastive learning을 적용하여 어떻게 SImCLR가 좋은 성능을 낼 수 있었는지에 대한 리뷰를 시작하도록 하게습니다.
A Simple Framework for Contrastive Learning of Visual Representations
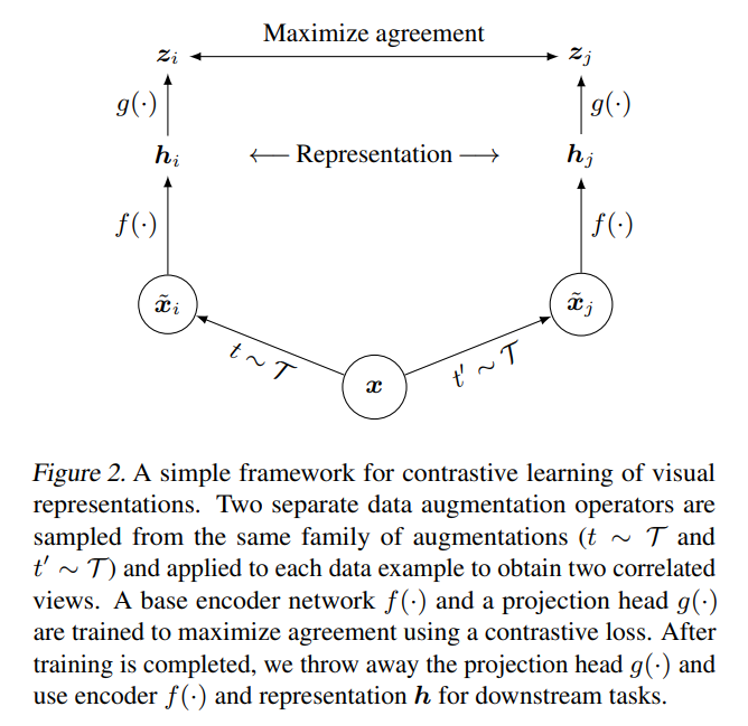
SimCLR comprises the following four major components.
- stochastic data augmentation module
- A neural network base encoder f(·)
- A small neural network projection head g(·)
- A contrastive loss function
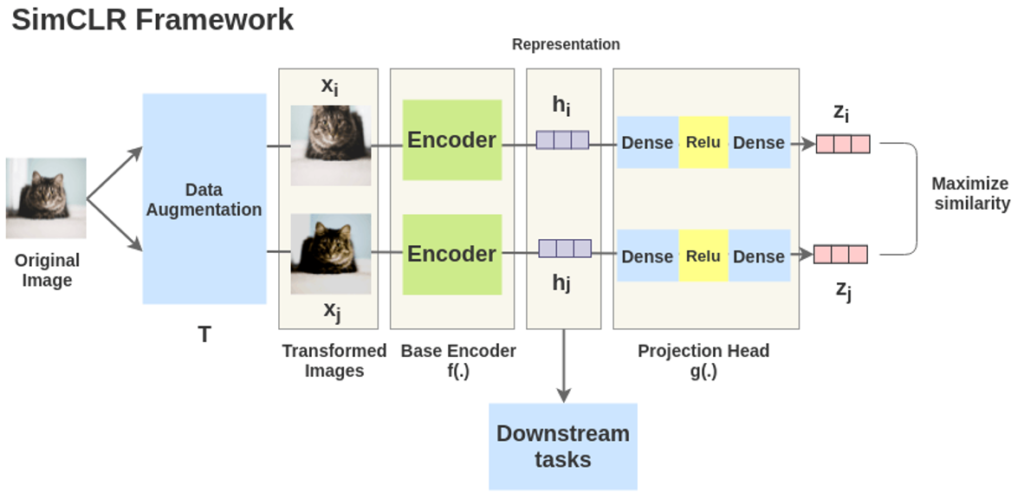
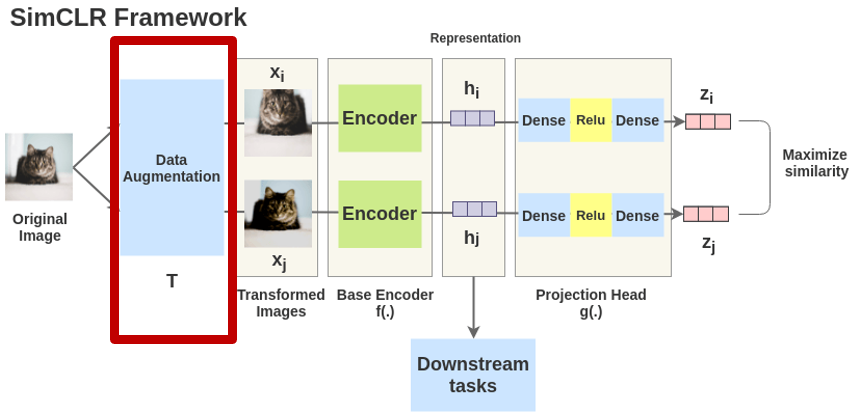
SimCLR의 모델 구조는 위 그림과 같이 굉장히 간단합니다. (거의 하나의 모듈이라고 할 정도인데요)
SimCLR의 구성 요소는 총 4가지 입니다. 1) 한 이미지에 대한 서로 다른 두 개의 augmentation을 적용하여 두 개의 이미지를 만듭니다. 그리고 contrastive learning을 위해 같은 이미지 x에서 나온 두 개의 이미지 x_1, x_2는 서로 positive pair로 정의하고, 그 외의 나머지 이미지들의 aug. 된 이미지들은 negative pair로 정의합니다.
이제 두번째 구성요소인 각각의 base encoder f(·)에 augmentation된 두 이미지를 태웁니다. 즉 representation을 학습합니다. 즉 f(·)를 통해 visual representation embedding h_i, h_j로 변환합니다.
그리고 세번째 구성요소인 projection head는 두 개의 linear layer 사이에 ReLU activation function을 넣은 구조로 구성됩니다. projection head g(·)에 앞서 구한 h_i, h_j를 다시한번 태워서 vector z_i, z_j를 추출하여 contrastive learning을 진행
일반적으로 contrastive learning 방식으로 학습을 진행할 때, 1.좋은 퀄리티를 가지며 2.충분히 많은 양의 negative pair가 필요하다고 알려져 있습니다. 학습은 batch 단위로 진행되기 때문에, 많은 양의 negative pair를 구성하기 위해서는 큰 batch size를 이용해서 학습해야 합니다. 이를 위해 SimCLR은 기본적으로 4096의 batch size(총 8192개의 sample)를 이용하여 학습을 진행하였습니다.
본 논문에서는 contrastive learning 기반의 SimCLR framework로 다양한 실험을 진행하며 이렇게 설계한 이유와 증명을 차근차근 논리적으로 진행하였습니다. 이에 대해 알아보기 전에, SimCLR는 어떻게 학습이 되는지 먼저 단계적으로 알아보도록 하겠습니다. (참고로 이후에 사용하는 그림은 The Illustrated SimCLR Framework 이 블로그 자료를 사용하였습니다)
Step by Step Example
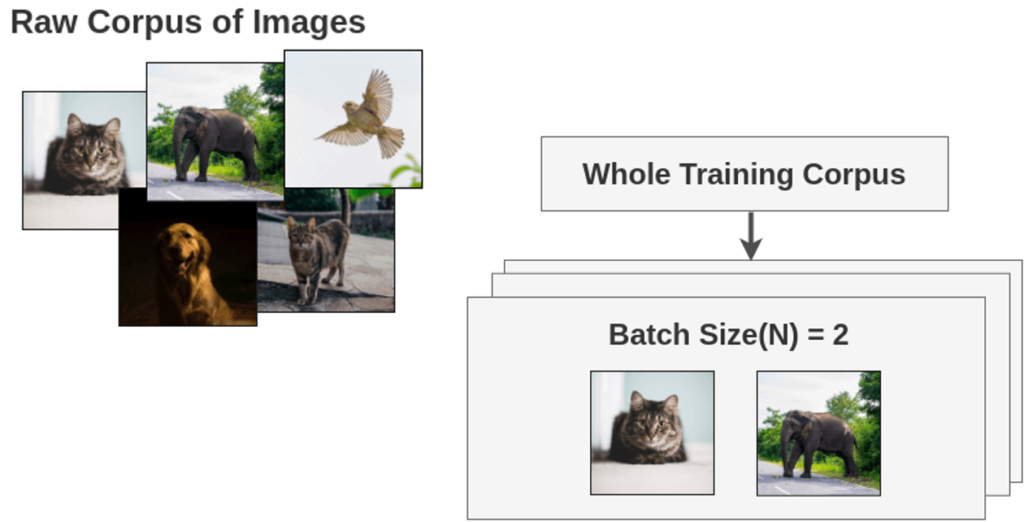
먼저 이미지에 대하여 배치 개수만큼 샘플링합니다. 여기서는 이해를 돕기 위해 배치 사이즈를 2라고 설정하였습니다.
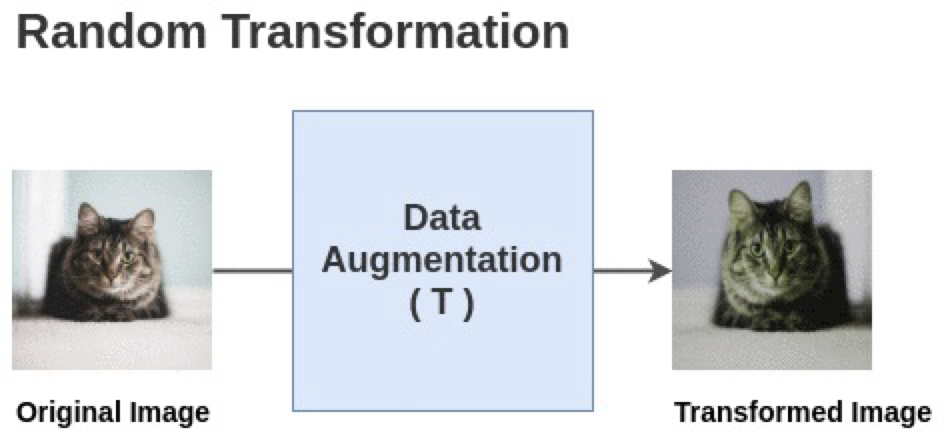
org 이미지에 대해 data augmetation이 랜덤한 두 가지의 방식을 선택하여 적용하게 됩니다.
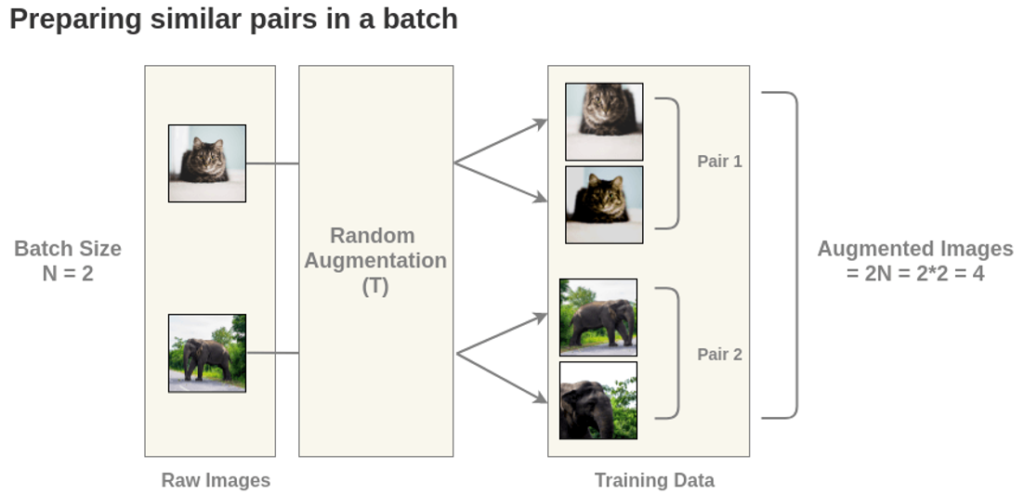
그 결과 각각 서로 다른 어그멘테이션 방식이 적용되어 총 배치 * 2의 이미지를 얻게됩니다.
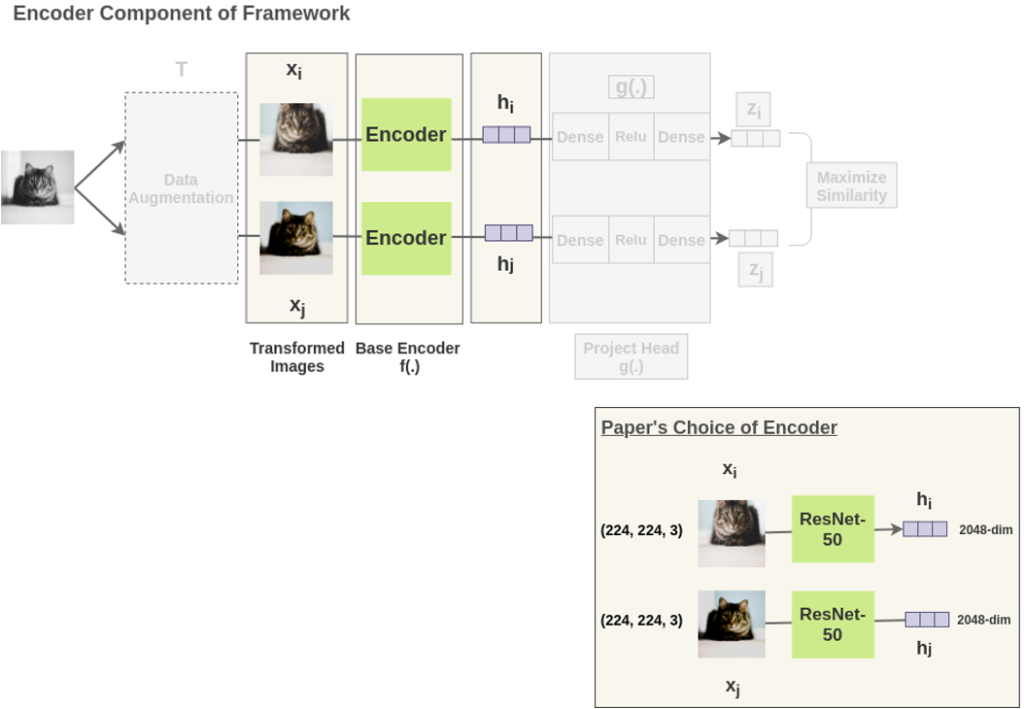
그런 다음 각각 augmetation 된 이미지를 각각의 인코더에 넣고, h라는 벡터 즉 표현 벡터를 뽑게됩니다.
이 때, 논문에 따라 h는 2018 디멘션을 가지는 벡터가 됩니다
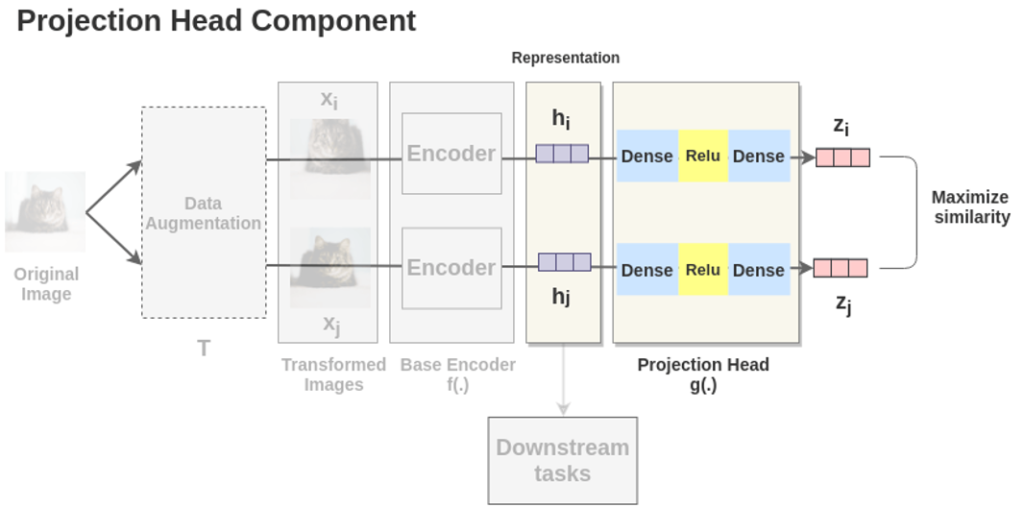
그런다음 MLP를 붙혀서 projection head를 구성합니다. 이 덕분에 z 라는 벡터가 나오게 되죠,
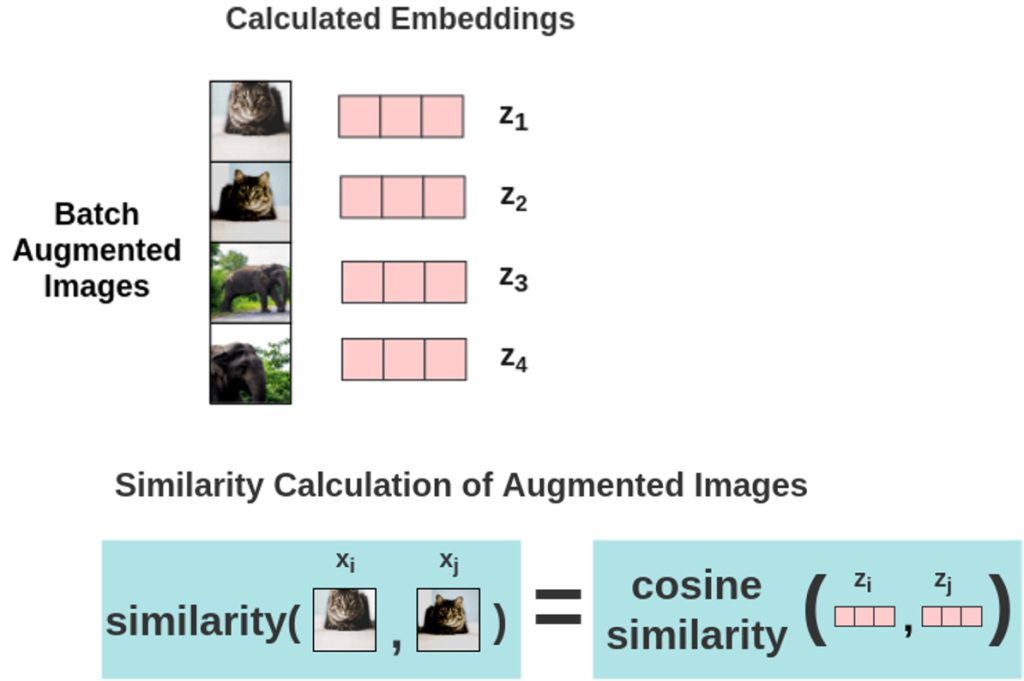
이제 앞서 구한 z를 가지고 유사도를 계산하게 됩니다. 2N개의 배치 전부에 대한 유사도를 계산합니다.
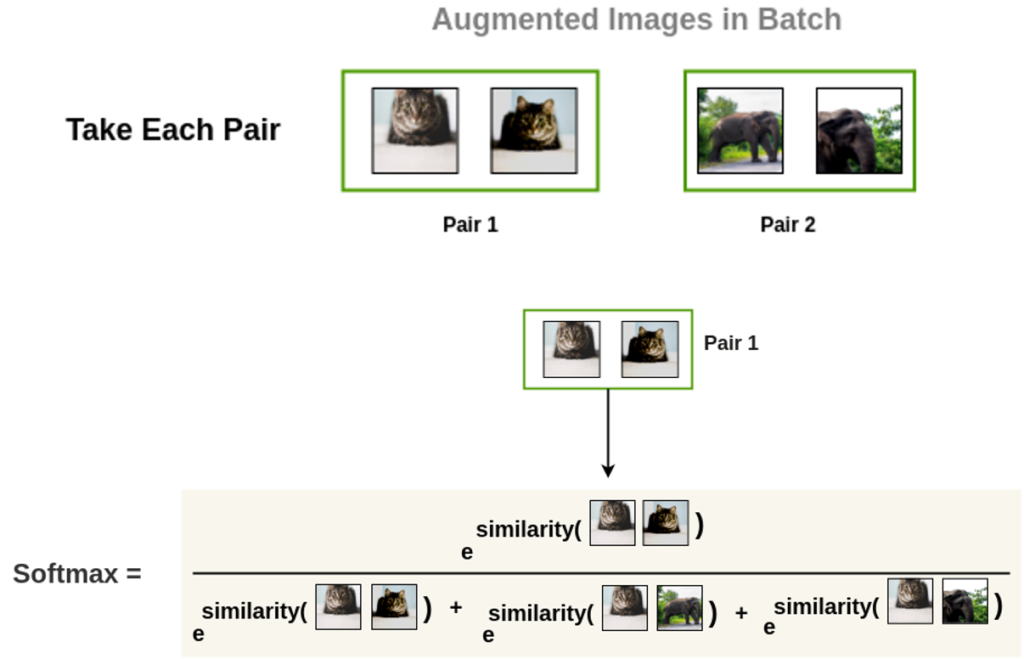
실제로 확률값은 softmax를 취하고 이제 여기 그림처럼 왼쪽 그림을 기준으로 나머지 모든 이미지의 벡터에 대하여 유사도를 계산합니다.
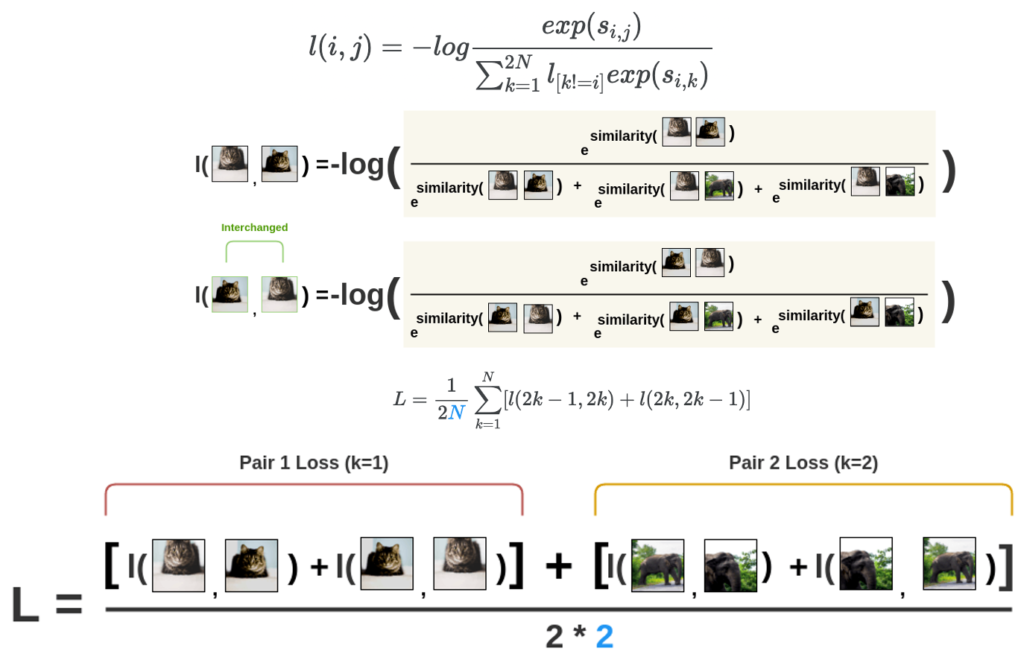
어떤 augmetation된 이미지가 왼쪽에 있는지에 따라 기준점이 달라지게 됩니다. 따라서 동일한 고양이로부터 aug. 된 이미지더라도 두 이미지의 위치가 다르다면 softmax 결과 역시 달라지며, 각각에 대해 구한 이 두 값을 더해서 평균을 내는 식으로 Loss를 계산합니다. 학습은 이 방식을 적용하여 진행됩니다
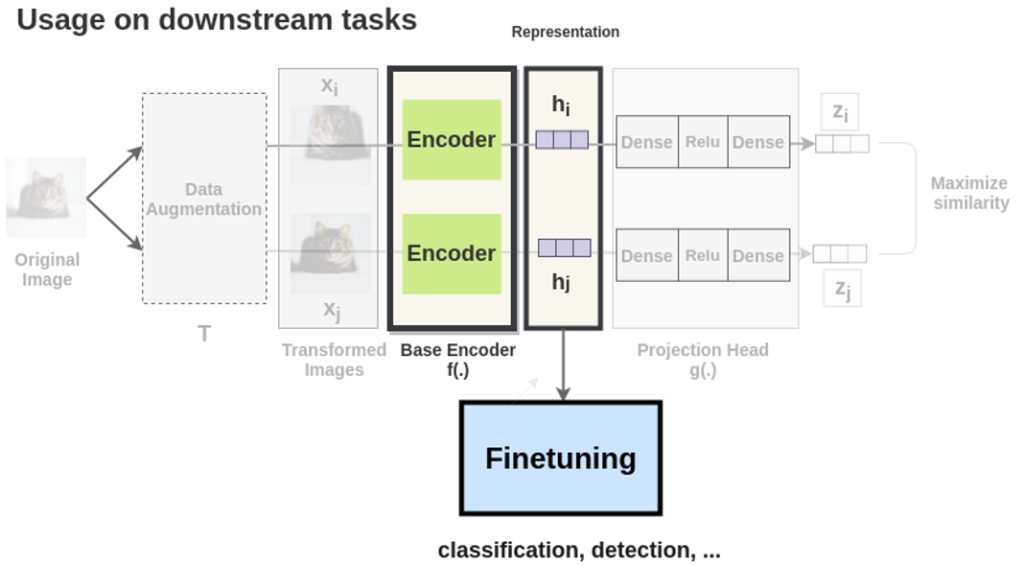
학습이 다 끝나고 나면, 이제 downstream task 로 평가를 하는데요. 가장 초반에 설명드린 것처럼 Downstream task 즉, Finetuning 을 통해 classification, object detection, segmentation 등의 태스크를 수행하게 되는데요. 이 때 주의해야하는 점은 projection head output인 z아닌 encoder 직후의 h로 downstream task 를 진행하게 됩니다. 그 이유는 추후 나오는 실험과 함께 차근차근 설명드리도록 하겠습니다.
Method
제가 SimCLR를 읽고나서 이 녀석 대단하다 라고 느낀 점이 바로 다음에 설명할 부분 때문이었는데요. 저자는 자신들의 모델을 설계한 방식과 왜 그렇게 설계하였는지를 실험과 함께 순차적으로 증명하며 이렇게 설계할 수 밖에 없었다 라고 주장합니다. 굉장히 설득력 있어서 놀라면서 읽었던 부분인데요. 예를 들어 어떤 data augmentation 방법을 사용했는지, 왜 projection head를 제외한 encoder만 실제로 이용하는지 등에 대해 이야기 합니다.
Data Augmentation
SimCLR에서는 supervised learning에서 일반적으로 사용하던 data augmentation 방법들을 이용하여 positive pair와 negative pair를 생성합니다. 즉, 어떤 기법을 사용하여 data augmentation을 좋은 visual representation으로 학습가능 한지를 실험을 통해 비교하였는데요.

기법들의 종류는 위 그림에 나와있는 것처럼 cropping이나 resizing, rotating, cutout 등 이미지의 공간적/기하학적 구조를 변형하는 data augmentation 방법과 color dropping, jittering, Gaussian blurring, Sobel filtering 등 이미지의 색상을 왜곡하는 data augmentation 방법이 있습니다. 그런데 아시다시피 ImageNet 은 모두 서로 다른 크기를 가지기 때문에, 동등한 aug. 기법 간 비교를 위해 항상 crop/resize를 진행하였습니다.
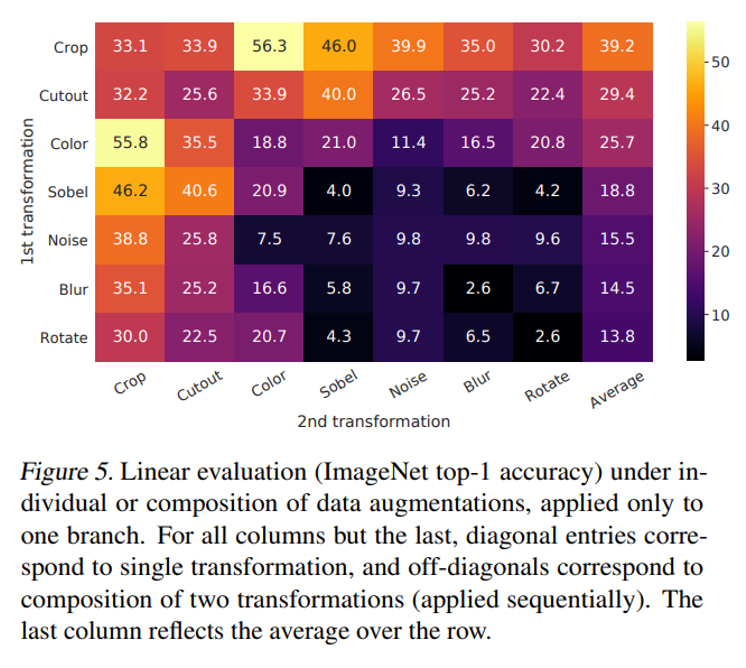
그림 5는 총 7가지의 data augmentation 방법을 한쪽 branch에만 혹은 양쪽에 적용하여 성능을 측정한 결과입니다. 결과적으로 하나의 augmentation 만으로는 좋은 성능을 달성하기 어려웠고, 여러 augmentation을 더해주었을 때 predictive task의 난이도가 높아지면서 representation quality가 증가하였다고 합니다. 특히 두 가지 augmentation을 적용한 경우, 위의 그림에서 알 수 있듯 random crop과 random color distortion을 적용한 것이 가장 좋은 성능을 보여주었습니다.
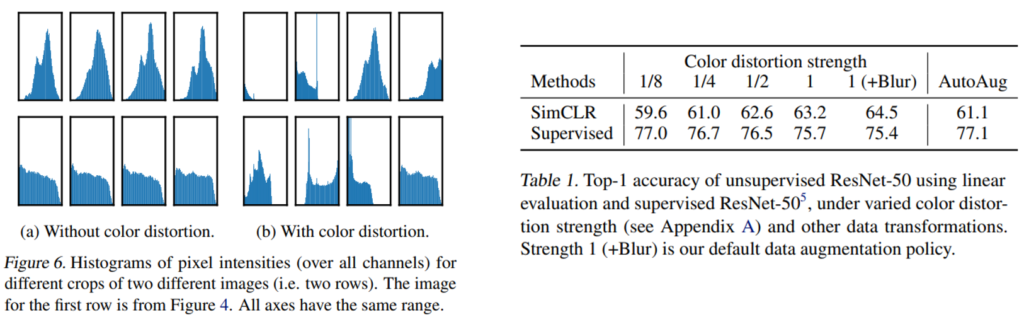
뿐만 아니라 Color distortion이 필요하고 좋은 성능을 냈다는 점에서도 나름의 분석을 보이는데, color distortion이 없으면 Fig.6의 histogram이 서로 비슷한 경향성을 보였다고 합니다. 결국 같은 이미지에서 아무리 랜덤 크롭을 적용했다고 한 들, 동일 이미지에서 나왔기 때문에 color histogram이 비슷한 분포를 보였다는 것이 저자의 분석이었는데요. 이렇게 color distortion이 없으면 결국 모델은 학습 시 representation이 아닌 색 조합에 집중하여 낮은 representation quality를 보였다고 하네요.
추가로 Table 1. 은 data augmentation의 세기를 바꿔가면서도 성능을 측정합니다. 그 결과 color distortion을 강하게 가할수록 contrastive prediction task의 난이도가 증가하여 visual representation을 더 잘 추출하도록 학습되었습니다. 게다가 같은 강도라고 해도 SUPERVISED에는 성능이 오히려 저하되는 반면 SimCLR에서는 성능 향상을 가져온 것을 볼 수 있습니다.
Architectures for Encoder and Head
이제는 이 인코더와 프로젝션 헤드를 왜 이렇게 설계하였는지에 대해 서술하는 장입니다.
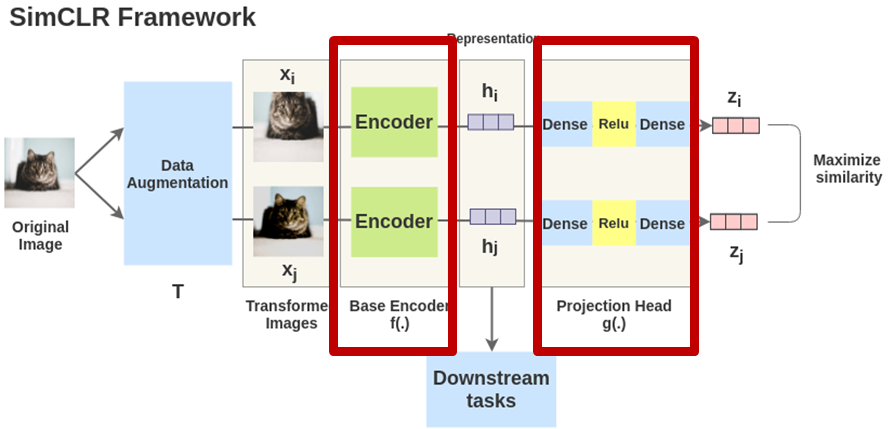
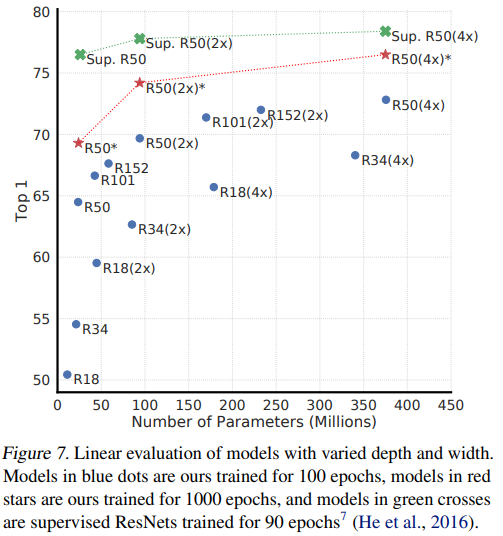
Fig.7 은 SimCLR과 supervised learning의 학습 방법을 다양한 크기의 모델에 적용시켜 linear evaluation 성능을 비교한 것입니다. Supervised learning과 마찬가지로 SimCLR도 모델의 크기가 커질수록 학습 성능이 증가하는 경향을 보였습니다. 여기서 저자는 성능 향상 추이에 집중하였는데, supervised 에 비해 모델의 크기가 커질수록 (깊어지고 넓어질수록) 큰 폭으로 향상하였다는 것을 기반으로 훨씬 좋은 benefit을 가진다고 이야기 합니다.
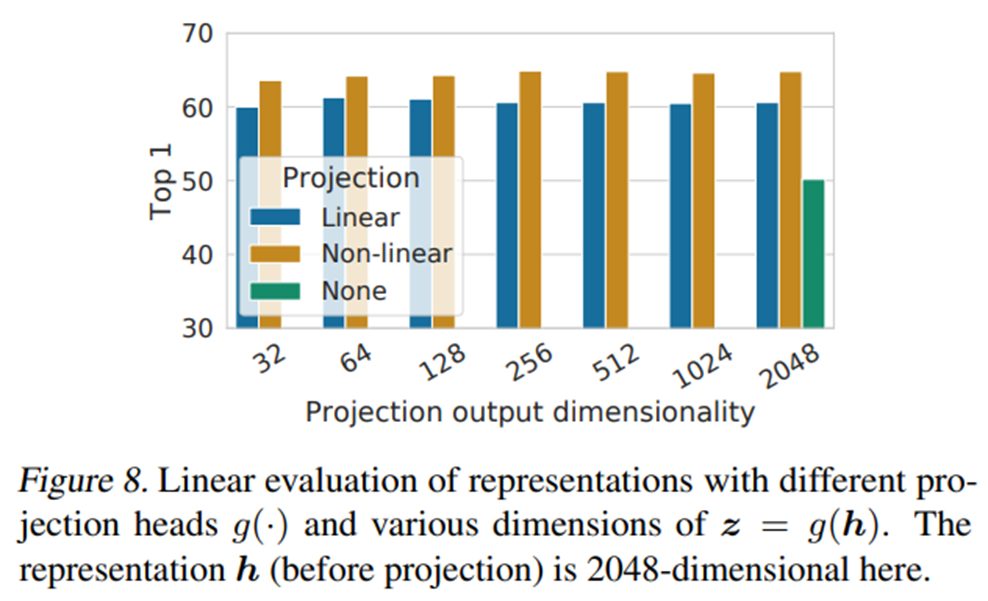
또한 non-linear projection head를 통해서 contrastive loss를 계산하는 구조 역시 linear projection head나 projection head를 아예 이용하지 않을 때보다 항상 좋은 성능을 낸다는 것을 보여주었습니다. 특히 이 점이 SimCLR의 contribution이라고 할 수 있는데요, MoCo ver.2 에서 이 projection head 사용 여부에 따라 성능이 더 높아졌다고 리포팅하기도 하엿습니다.

위에 그림은 SimCLR에서 왜 MLP 즉 projection head를 통과한 벡터는 단순히 contrasitive learning에만 사용하고 , downstream task 에는 h를 사용하느냐에 대한 실험입니다.
Projection head는 학습 성능을 높여주었지만, projection head를 통해서 얻은 output vector는 base encoder의 output보다 시각적인 특징을 잘 표현하지 못하였습니다. 위의 그림은 10개의 클래스에 대한 base encoder와 projection head의 output vector를 t-SNE 방법으로 clustering을 한 결과입니다. 인코더로부터 나온 벡터인 h가 z보다 잘 구분되는 것을 정성적으로 확인할 수 잇는데요. 논문에서는 그 이유가 MLP를 통과하면서 color와 rotation과 같은 정보가 소실되지만 그에 강인하도록 변환되기 때문이라고 합니다. 이를 증명하기 위해 오른쪽 테이블을 통해 contrastive prediction task를 두 벡터들이 얼마나 잘 맞추는지에 대한 실험을 진행하였습니다. 그 결과 projection head의 출력인 z가 h보다 rotation이나 gaussian noise, sobel filtering 등의 정보가 없다는 것을 확인할 수 있습니다.
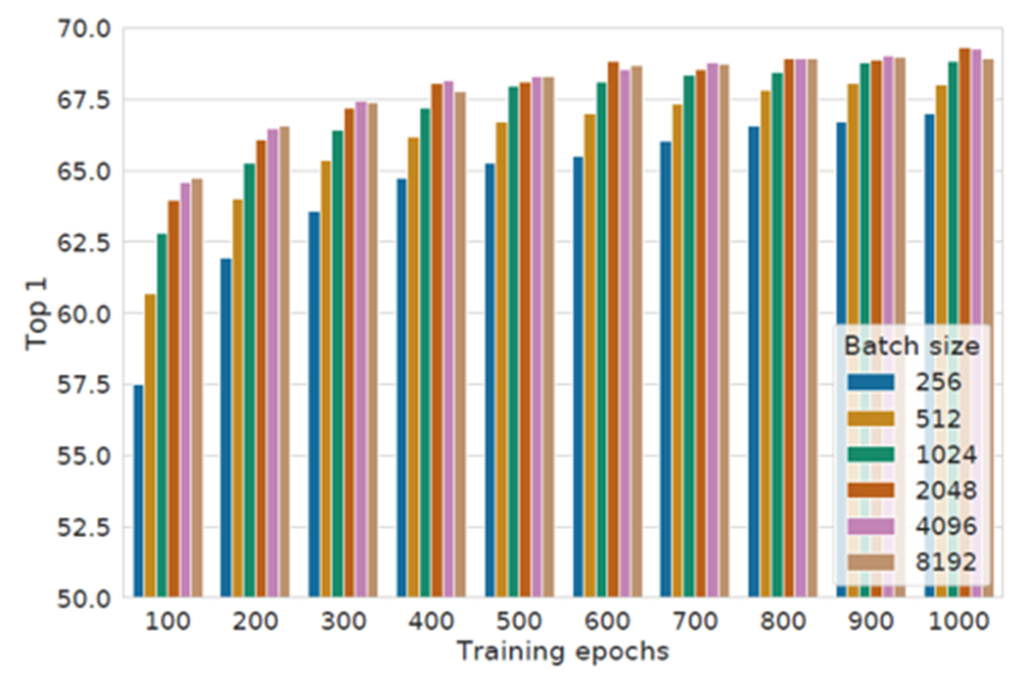
그리고 contrastive learnign에서는 충분한 양의 negative sample이 보장되어야 안정적인 학습이 가능하다고 지속적으로 이야기해 왔는데요, 특히 SimCLR는 negative sample 개수가 batch size에 비례하기 때문에 배치 사이즈 크기에 따른 성능에 대해 리포팅합니다. 그 결과 SimCLR을 학습할 때 batch size를 키울수록 모델의 성능이 증가하는 경향을 보여주었습니다. 또한 학습 과정에 random augmentation이 포함되어 있기 때문에 학습 시간이 길어질수록 충분한 양의 negative sample을 볼 수 있고, 성능에 대한 유의미한 결과를 보일 수 있었습니다.
Experiment
1.학습된 모델을 고정(freeze)하고 linear classifier를 추가하여 성능을 평가하는 linear evaluation,
2.학습된 모델과 linear classifier를 모두 learnable한 상태로 학습하는 fine-tuning,
3.학습된 모델을 다른 종류의 dataset에 대하여 learnable한 상태로 학습하는 transfer learning 의 세 가지 방법으로 평가
Linear evaluation : Protocol
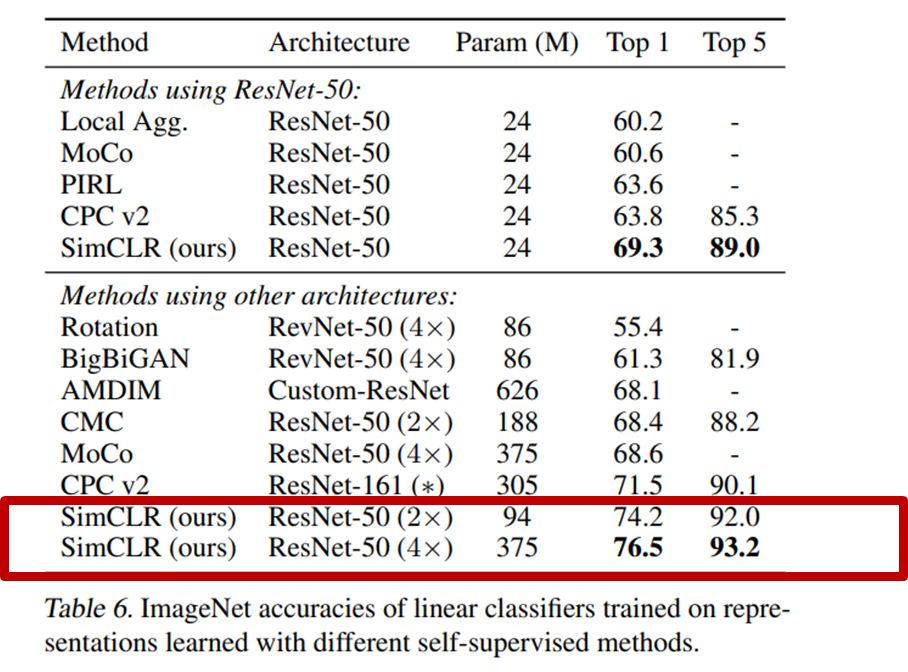
먼저 freeze 후, linear classifier를 추가한 이후의 성능입니다.
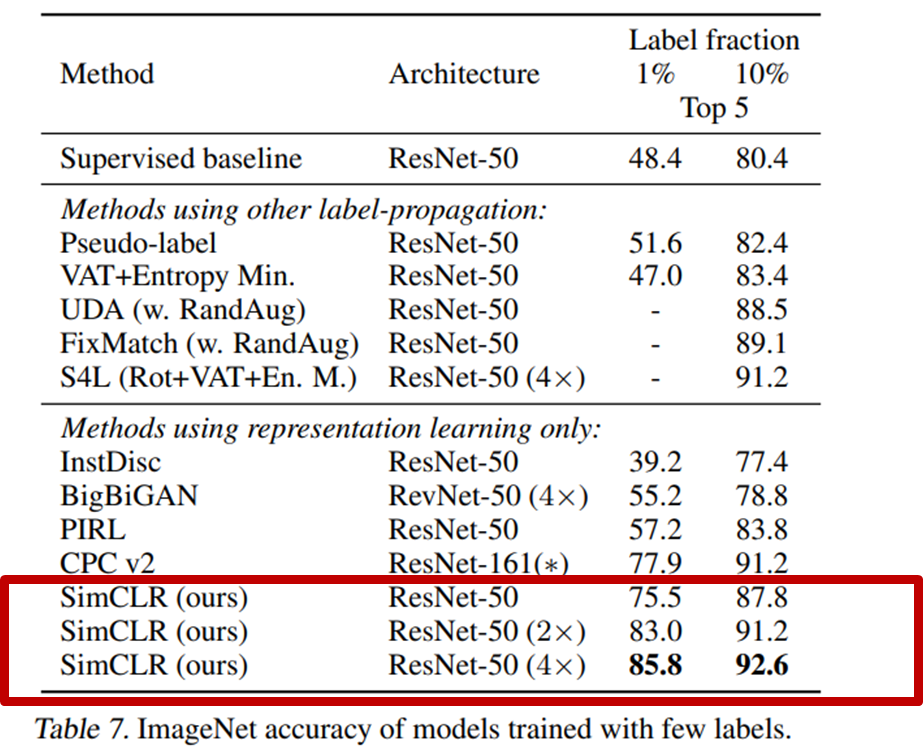
위의 두 그림은 Linear evaluation과 적은 dataset에 대한 fine-tuning 평가의 결과인데요, 둘 다 SOTA 이다.. 라고 할 수 있는데요. 특히 fine-tuning 은 같은 모델의 supervised learning 학습 결과보다도 좋은 성능을 보여주었습니다.
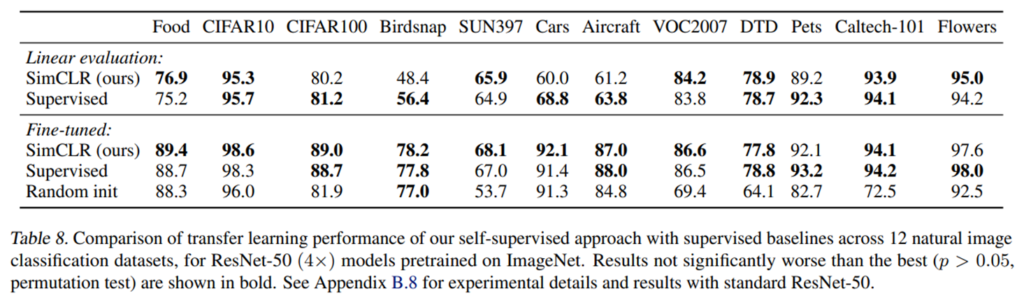
또한 다양한 데이터셋에 대해 transfer learning으로 학습했을 때, supervised learning과 비슷하거나 그 이상의 결과를 보여주었다는 특징을 가집니다.
지금까지 길고 긴 SimCLR 논문 리뷰를 진행하였습니다.
결국 요약하면 SimCLR는 1) 다양한 data augmentation 의 조합 실험으로 성능을 끌어올렸다 2) projection head라는 가벼우면서도 nonlinear transformation을 도입함으로써 성능을 끌어올렸다 일 것 같습니다.
길었던 리뷰를 마치도록 하겠습니다. 감사합니다.