
image가 주어졌을 때, 그에 대한 text 를 prdict 하는 것을 목적으로 pretrained 된 모델, CLIP에 대한 리뷰입니다.
우선 CLIP은 Contrastive Language-Image Pretraining 의 약자인데요.
이 리뷰를 읽게 되신다면 Contrastive 가 어떤 의미인지, 왜 Language-Image 데이터를 쓰는지, 그리고 해당 모델이 Pretraining 을 통해 어떤 이점들을 얻었는지 등을 살펴보시면 좋을 것 같습니다.
우선 기존 SOTA 컴퓨터비전 시스템들은 미리 정의 해놓은 object categories를 predict 하는 방식으로 학습되어 왔습니다. 이에 대한 예시로는, CIFAR-10 데이터셋을 활용하여 image classification 을 하는 task 가 있습니다. 해당 데이터셋에는 10개의 카테고리 (airplane, automobile, bird, cat, dog… )가 정의되어 있고, 각 이미지에는 해당 이미지가 속하는 카테고리에 대한 라벨이 있습니다. 이때 (imge-label) pair 를 이용해서 image 에 대한 정답 label 값을 예측하는 모델을 학습하는 것이 목적이죠.
그런데 이때, 단순히 이미지에서 나타나는 ‘dog’, ‘cat’, 등의 이런 카테고리에 대한 정보가 아니라, 다른 visual 한 concept 도 이용하고 싶다면 어떻게 해야할까요? 앞서 CIFAR 데이터셋에서 카테고리에 대한 labeled data 가 있었듯이, 이 visual concept에 대한 labeled data 또한 필요하게 됩니다. 그렇지만, 이 label 을 어떻게 정의해야 할까요? 예를 들어 물체의 종류 뿐만이 아니라 색깔이라는 특성도 활용하고 싶다고 해봅시다. 그럼 지금 ‘dog’ 카테고리에 속하는 이미지들을 보고, 색깔에 대한 데이터를 라벨링해주면 되겠네요. 그런데, 색깔의 범위는 어떻게 해야할까요? ‘sky blue’ 나 ‘yellow green’, ‘magenta’ 이런 색깔도 추가해야할까요? 어떻게 정의하고 라벨링을 다 해서 데이터셋을 만들었다고 쳐도, 나중에 또 다른 visual concept, 예를 들어 강아지가 지금 뭘 하고 있는지 등의 정보가 필요하다면 또 다시 라벨링을 해야합니다. 뿐만 아니라 이미 정의해놓은 카테고리에 속하지 않는 라벨을 정답값으로 갖는 이미지가 들어오면, 학습할 때 그에 대한 라벨이 없었으니까 당연히 예측을 할 수도 없겠지요.
NLP 분야에서는 이러한 단점들이 있는 crowd-labeld datasets 이 아닌 raw text 을 이용해서 pretrainig 하는 방법이 사용되고 있습니다. 해당 방법은 데이터를 확정하고 특정 task 에 대해 성능을 잘 내도록 학습된 모델과 비교했을 때에도, 견줄만한 성능을 내고 있습니다.
WIT (WebImage Text dataset)
본 논문에서는 이러한 방식을 차용하여, natural language 와 image 쌍으로 이루어진 새로운 데이터셋 WIT (WebImage Text) 를 구축했습니다. 총 40 억 개의 (image-text) pairs로 구성되어 있고, 대략적인 정보는 아래와 같습니다.

Pretraining method
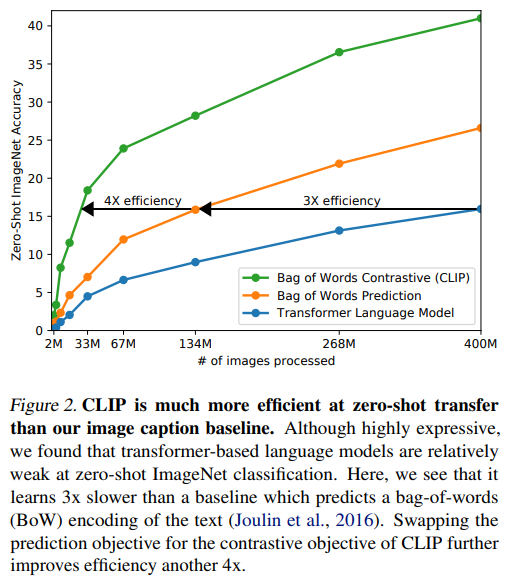
해당 모델은 image를 입력 받았을 때 이에 해당하는 caption 을 예측할 수 있도록 모델을 pretraining 시키려고 합니다. 이때, 학습 시 사용하는 데이터셋과는 다른 데이터셋을 추론 시 사용하는, ‘Zero-shot’ 방식을 사용하여 정확도 성능을 측정하였습니다.
데이터셋
- train : WIT datastet
- inference : ImageNet dataset
메소드
- Transformer Language Model
- Bag of words prediction
- Predictive representation learning 사용
- Bag of words Contrastive
- Contrastive representation learning 사용
Figure 2를 보면 알 수 있듯이, Bag of words contrastive 메소드가 비교한 방법론들 중에 제일 좋았습니다.
Bag of words contrastive
- 입력 : N개의 (image-text) pairs (batch size = N)
- image encoder : image N개-> encoding -> image features N개
- text encoder : text N개-> encoding -> text features N개
- similarity matrix : cosine simialrity를 이용하여, NxN개의 유사도 구함.
- 학습 : NxN 개의 (image-text) pairs 중, 올바른 N개에 대한 유사도는 높아지도록, 나머지는 낮아지도록 encoder 의 contrastive learning 진행
다른 방법론들과 비교했을 때, image-caption accuracy task 시 3배, 그리고 그에 대해 4배로 효과적이었습니다.

Pretrainig model
image encoder
- 5 개의 ResNets (ResNet50, ResNet101, RN50x4, RN50x16, RN50x64)
- 이때 x? 는 ResNet50 을 이용해서, EfficientNet-style model scaling 을 한 것
- 3 개의 Vision Transformers (ViT-B/32, ViT-B/16, ViT-L/14)
- 이때, ViT-L/14 는 성능을 높이기 위해 336 pixel resolution 을 사용함. (이하 ViT-L/14@336px)
실험을 통해 ViT-L/14@336px 이 best 였고, 이후 CLIP 에서 해당 인코더를 사용합니다.
text encoder
- Transformer
- Radford et al. (2019) 이 제안한, Natural language processing tasks (question answering, machine translation, reading comprehension, and summarization) 등 여러 분야에서 사용하는 language model 을 사용합니다.
- 구조 : 12-layer 512-wide model with 8 attention heads
- language-modeling 을 위해 Masked self-attention 을 사용하는데, 본 논문에서는 이에 대한 탐구는 후속 연구로 남겨놓겠다고 언급하였습니다.
- 입력 : text representation (BPE)
- [SOS] 과 [EOS] 토큰을 사용하는 표현 방식
- layer normalized 되고 multi-modal embedding space 에 projection 되어도 feature 를 잘 representate 한다는 특징이 있다.
Zero-shot performance
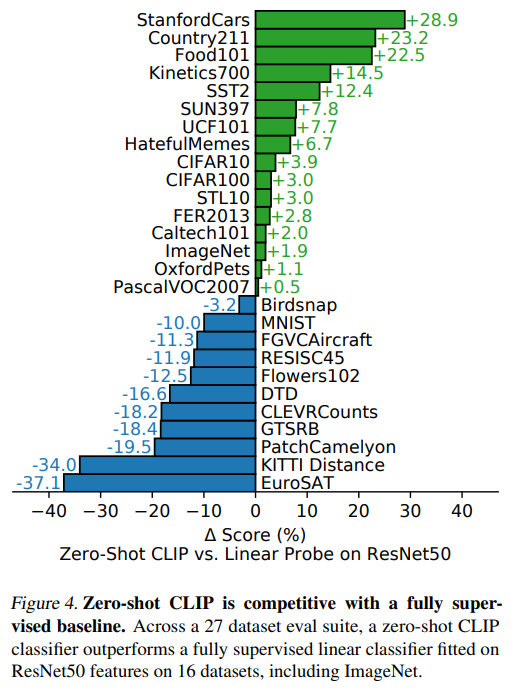
컴퓨터비전 분야에서, ‘Zero-shot learning’ 이라는 것은 image classification 을 할 때, 본 적이 없는 object categories 에 대해도 잘 할 수 있도록 모델을 일반화하는 연구를 말합니다.
본 논문에서는 이 용어를 좀 더 확장해서, ‘본 적이 없는 데이터셋’에 대해서도 잘 하도록 하는 것으로 정의합니다.
Figure 4를 보면, RestNet 과 CLIP 을 16개의 데이터셋에 대해 비교합니다. 이때 ResNet 은 학습할 때와 같은 데이터셋을 사용하고 CLIP 은 본 적이 없는 데이터셋을 사용했는데, 실험을 통해 Zero-shot CLIP 이 이에 대적할 만하다는 것을 알 수 있었습니다.
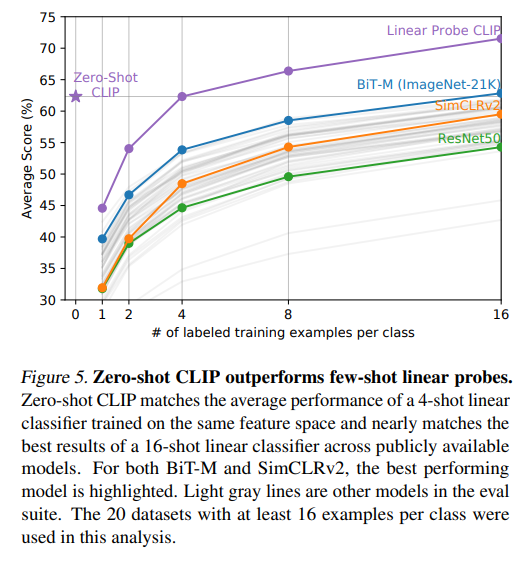
또한, few-shot learning 을 하는 경우 CLIP 이 더 성능이 좋았습니다.
이에 대해, CLIP 의 zero-shot approach 를 통한 성능이 좋은 이유에 대한 2가지 분석이 가능합니다.
- CLIP 의 zero-shot classifier 는 natural language 를 통해 생성되었습니다. 따라서, 해당 text 로부터 visual concepts 를 직접적으로 추론할 수 있습니다.
반면 일반적인 supervised learning 은 학습 데이터에 있는 concepts (카테고리의 라벨)으로부터 간접적으로 추론을 하게 됩니다. 이는 context-less example-based learning 이라고 부르는데, 이 때문에 one shot learning 시 성능이 좋지 않은 것입니다. 하나의 이미지는 여러 개의 visual concepts 를 갖고 있는데, 하나의 라벨으로부터 추론하게 되는 것이니까요. - few-shot logistic regression learning 을 한 것 중에 best인, 16-shot classifier 보다도 zero-shot CLIP이 성능이 좋습니다. 이때 해당 모델은 ImageNet-21K에서 학습된 BiT-M ResNet152x2를 사용했는데, 이 보다 더 큰 데이터셋인 JFT-300M 과, 더 큰 모델인 BiT-L 에서 학습을 하고 이를 사용하면 CLIP보다 성능이 더 좋을것이라고 하였습니다. 그러나, 해당 논문이 발표됐을 시 아직 released 되지 않았기에 직접적으로 비교되지 않았습니다.
Performance
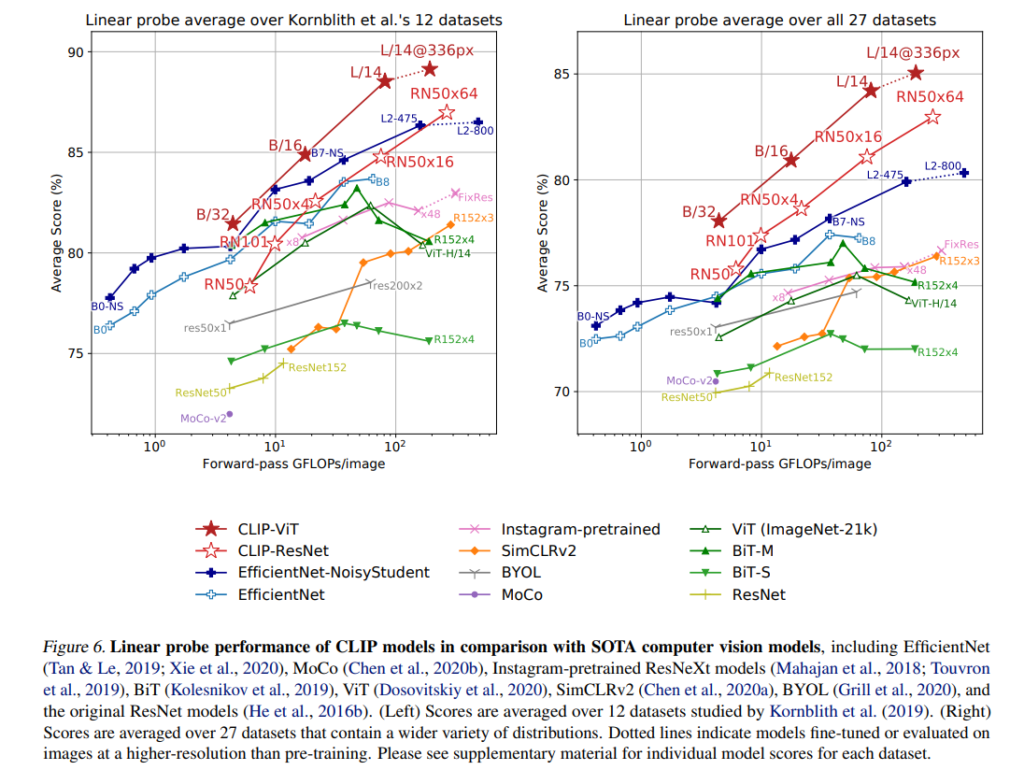
Figure 6은, CLIP (ViT-L/14@336px) 모델이 이 당시 존재하는 모든 모델을 능가했다는 것을 보여줍니다.
또한, scale 에 상관없이, 모든 CLIP 모델들이 compute efficiency 관점에서 모든 다른 시스템들을 능가했습니다.
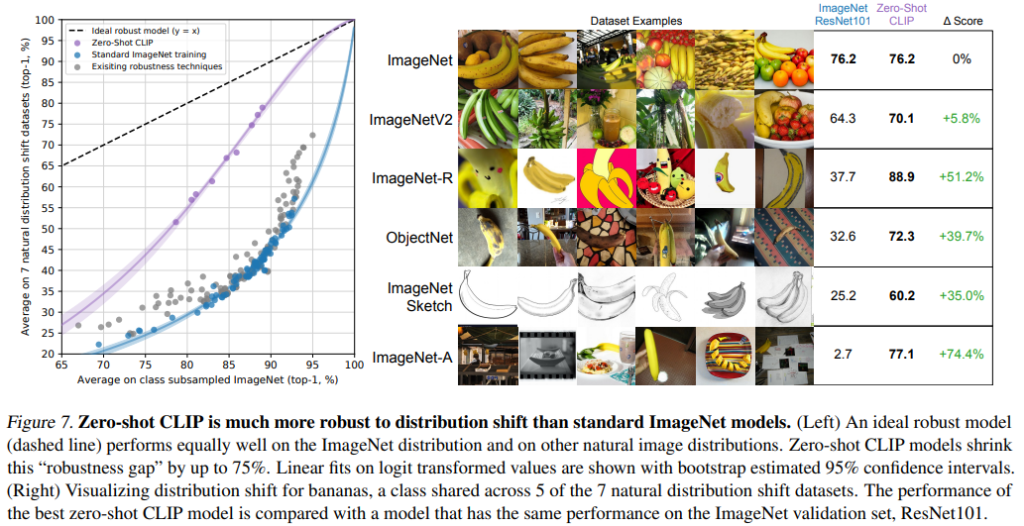
Figure 7은 zero-shot CLIP 모델을 일반적인 ImageNet models 와 natrual distribution shifts 관점에서 비교했습니다.
모든 Zero-shot clip 모델이 imagenet accuracy 와, distribution shift 관점 아래에서의 accuracy 의 gap 을 줄였습니다.
즉, 카테고리별 정확도 분포의 갭을 줄인 것이고, 학습 데이터에서 카테고리별 데이터가 균등했을 것이라는 가정이 있으므로, 이 값을 줄일 수록 더 견고한 모델인 것입니다.
CLIP 모델은, NLP 의 task-agnositc (풀고자하는 문제에 상관없는) pre-training 기법을 image-text 로 transfer 하여 사용한 모델입니다.
앞서 언급했던 Contrastive 가 어떤 의미인지, 왜 Language-Image 데이터를 쓰는지, 그리고 해당 모델이 Pretraining 을 통해 어떤 이점들을 얻었는지를 다시 정리하고 리뷰 마치도록 하겠습니다.
- Pretraining 시 image 에 대한 text 를 예측하도록 학습이 되는데, 이때 NxN 개의 image-text pairs 중 정답인 N개의 pair의 similarity 는 커지게, 나머지는 작아지도록
Contrastive방식으로 학습을 한다. - visual concept 을 raw text 로부터 얻어, 보다 다양한 concepts 를 학습에 사용하여 representation 을 더 잘 나타내게 하도록 하기 위해 (Label-Image) 가 아닌,
Language-Image를 사용한다. - natural language 에 대한 정보를 갖기 때문에, 훈련할 때 사용한 데이터셋 뿐만 아닌, 다른 데이터셋을 통해 성능을 측정하는 Zero-precision 에 대해서도 견고함을 보인다.