이번에 논문은 오래만이면서도 친숙한 backbone 논문입니다. 듣기로는 CVPR2022에 붙은 논문이라고 하는데, 아무튼 그렇습니다.
Intro
제목에서도 대략적인 느낌을 아실 수 있으시겠지만, Dense Prediction(object detection, semantic segmentation 등)에 잘 동작할 수 있도록 초점을 맞춘 백본 논문입니다. 제가 dense prediction에 대해 관심이 많다 보니, 관련된 모델 및 loss 등 방법론들에 대해서도 많이 다뤘었는데 그러다보니 인트로 내용도 다 고만고만해서 간략하게만 소개하고 넘어가도록 하겠습니다.
Dense Prediction task에서 가장 중요한 것은 바로 모델이 multiple scale에 대한 feature map을 잘 표현할 수 있도록 학습시키는 것입니다. Object detection도 그렇고 pixel level prediction에서도 그렇고, 영상 속 크고 작은 물체에 대해서 잘 구분하고 정확하게 예측을 할 수 있어야하기 때문이죠.
기존의 Inception Network나 VoVNet이라는 CNN 기반 방법론들은 multi-grained convolution kernel을 통해 동일한 feature level에 적용함으로써 다양한 receptive field를 가지는 효과를 누리고, 검출 성능을 크게 향상시켰다고 합니다. 그리고 제가 예전에 리뷰한 HRNet도 스테이지를 지날 때마다 feature map이 다운샘플링 되는 구조가 아닌, multi-resolution feature map이 스테이지 끝단까지 병렬적으로 유지되는 구조를 통해 Coarse와 Fine grained feature map을 모두 학습할 수 있었습니다.
하지만 Vision Transformer의 경우에는 사실 앞서 설명드린 연구들처럼 multi-scale representation에 대해 연구에 초점을 많이 두고 있지 않는다고 저자는 주장합니다. 물론 Swin, PvT와 같이 최근에 제안된 transformer 연구들은 CNN과 유사한 계층적 구조로 모델을 설계하고는 있습니다만 사실 그것은 가장 일반적인 multi-scale 표현법이고 보다 직접적으로 multi-scale feature representation을 연구하는 논문은 그리 많지 않았습니다.
그래서 multi-scale feature representation을 보다 더 잘 모델링할 수 있는 Transformer backbone을 설계하는 것이 해당 논문의 Goal이며, 대략적인 파이프라인은 아래 그림1과 같습니다.
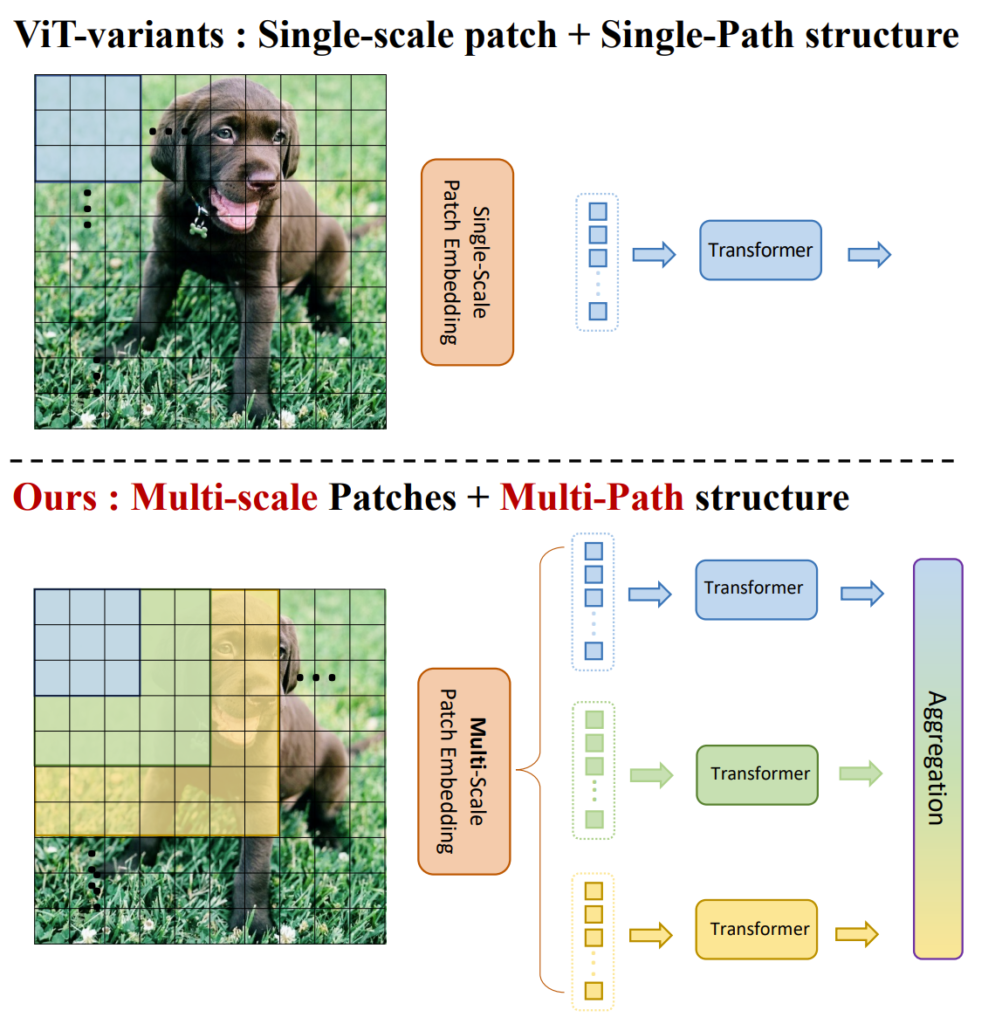
보시면 기존의 ViT는 영상 속 패치를 word embedding vector로 변환한 다음 해당 feature를 Multi-head Self Attention(MSA)가 포함된 Transformer block에 태워서 학습합니다.
반면에 논문에서 제안하는 방식은 서로 다른 크기의 패치를 각각 word embedding vector로 변환합니다. 이 때 각 패치들은 그림1에서도 볼 수 있듯이 각 패치들마다 겹치는 영역이 존재하며 패치 크기는 다르더라도 embedding vector는 모두 동일한 크기로 만들게 됩니다.
아무튼 서로 다른 영역들에 대해 패치 임베딩 과정을 마쳤다면 이들을 각각 Transformer block에 병렬적으로 태워서 MSA연산 처리가 된 feature map을 생성합니다. 그리고 이 모든 feature map을 통합하는 과정을 거쳐서 최종적인 feature를 만들게 되는데 이렇듯 다양한 크기의 patch로 연산을 하다보니, 다양한 receptive field를 가질 수 있게 되며 덕분에 fine & coarse 정보를 잘 표현할 수 있었다고 합니다.
결과적으로 해당 논문에서 제안하는 contribution들을 정리하자면, 먼저 저렇게 multi-scale patch들에 대해 병렬적으로 transformer 연산을 수행하는 multi-scale & multi-path 구조가 하나의 큰 contribution으로 볼 수 있을 것이며, 둘째로 마지막에 aggregation하는 과정에서 사용되는 global-to-local feature interaction(GLI)라는 모듈을 새로 제안한다고 합니다.
Architecture
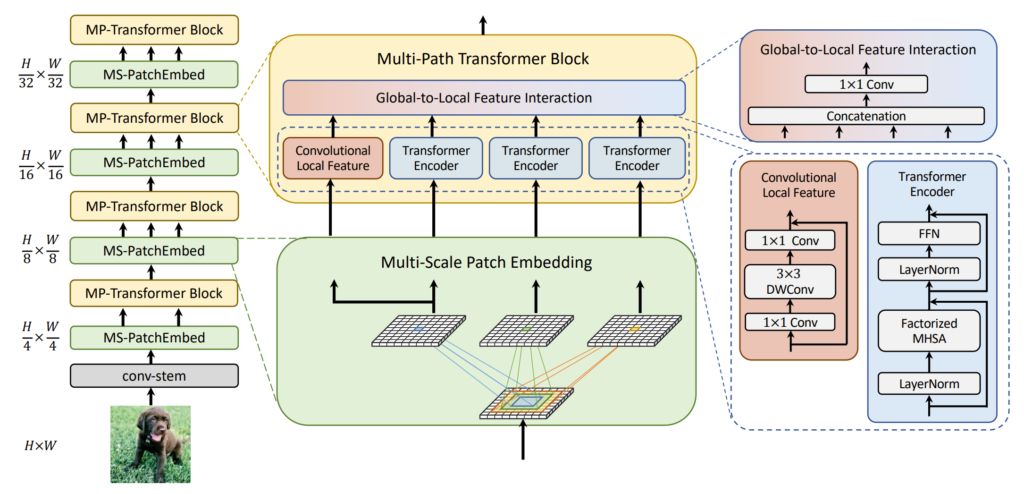
그림2는 논문의 전체 흐름에 대해서 나타낸 것입니다. 일단 dense level prediction에 초점을 맞췄기 때문에 당연하게도 Swin Transformer처럼 스테이지는 크게 4단계로 구성하고 feature map이 각 stage를 지날 때마다 2배 down-sampling이 되는 것을 확인하실 수 있습니다.
이 때 첫번째 스테이지에서는 원본 영상 대비 4배 줄어드는데 이는 일반적으로 Transformer 백본들이 영상에서 단어 임베딩 벡터로 보고자 하는 가장 작은 patch 단위가 4×4 패치이기 때문입니다. 조금 더 디테일하게 설명하자면, 그림2에서 입력 영상이 바로 MS-patchEmbed로 통과하지 않고 Conv-stem을 거치는 것을 볼 수 있는데, 해당 Conv Stem은 Transformer 백본들에서 많이 활용하는 구조로 논문에서는 2stride를 가지는 2개의 컨볼루션 layer를 태워서 4배 다운샘플링을 먼저 진행했다고 합니다. (채널은 순서대로 C/2, C 값을 가지게 됨.)
최근에 많은 연구들이 제일 마지막 feature map에서는 CLS token을 사용하지 않고 global average pooling을 대체한다고 합니다. 그래서 저자도 유행에 맞게 마지막 feature map은 GAP로 대체하였다고 합니다.
Multi-scale Patch Embedding
먼저 패치 임베딩에 대해서 다루도록 하겠습니다. 일반적으로 패치 임베딩이란 위에서도 계속해서 말씀드린 것처럼 word라는 개념을 활용하기 위해 패치 영역으로 임베딩 벡터를 만드는 과정을 의미합니다. 해당 논문에서는 Multi-scale patch를 활용하기 때문에 패치 임베딩 과정에서도 multi-scale에 맞게끔 변경해주는 작업이 필요합니다.
구현 과정은 단순한데 저자는 overlapping patch에 컨볼루션 연산을 사용했다고 합니다. 예를 들어서, 이전 스테이지 X_{i}에서 추출된 2D reshaped output feature map이 주어진다면, 패치 임베딩을 위해 F_{k \times k}()라는 함수를 학습하게 됩니다.
F_{k \times k}() 함수는 X_{i}를 새로운 토큰으로 만들어주는 함수를 의미하며 2D로 reshape이 된 feature를 입력으로 넣은 것이다 보니 F_{k \times k}()는 k x k 커널(패치 사이즈)을 가지는 2D 컨볼루션 연산이라고 보시면 됩니다.
저자는 다양한 크기의 visual token을 생성하기 위해서 다양한 크기의 커널 사이즈를 가지는 컨볼루션을 적용하였는데, 그림1에서와 같이 3×3, 5×5, 7×7 크기의 패치 사이즈를 활용했다고 합니다. 여기서 실제 커널 사이즈를 5×5, 7×7로 활용한 것은 아니고 3×3 컨볼루션 레이어를 연속적으로 사용하는 방법을 통해 receptive field를 넓혔다고 합니다.
예를 들어서 볼까요. 3×3 컨볼루션 레이어를 연달아서 2번 태우게 되면 이는 5×5 컨볼루션 연산을 한 것과 동일한 receptive field를 가지게 됩니다. 하지만 실제 파라미터의 수는 더 줄어들기 때문에 메모리면에서 더 이점을 얻을 수 있습니다.( [/latex] 2 \times 3^{2} < 5^{2}[/latex])
요약하자면 feature X_{i}에 대하여 저자는 F_{3\times 3}(X_{i}), F_{5\times 5}(X_{i}), F_{7\times 7}(X_{i}) 의 feature map들을 계산하였으며, 각각의 feature map들은 모두 동일한 spatial resolution을 가지고 있다는 점입니다.
그리고 저자는 multi-path structure로 인하여 더욱 많은 임베딩 레이어들이 구성되어있다는 점을 고려하여, 모델의 파라미터 수와 연산 량을 줄이고자 임베딩 레이어에 3×3 depthwise separable convolution을 적용했다고 합니다. Depthwise separable convolution은 3×3 DW Conv에 연달아 1×1 Conv가 적용되는 구조로 해당 방식이 standard 3×3 conv보다 연산량을 적게 먹기 때문에 mobile net과 같은 경량화 모델에서 많이 활용합니다.
아무튼 이렇게 임베딩 과정까지 마무리된 서로 다른 (receptive field로 연산된) feature map들은 각각 transformer encoder에 병렬적으로 연산이 수행됩니다.
Global-to-Local Feature Interaction
저자는 다양한 논문들을 인용하여 Transformer와 CNN의 특성에 대해서 설명합니다. 해당 부분들에 대해서 간략하게만 소개드리자면, Transformer의 경우 Self-Attention 연산을 통해 Long-range dependency를 잘 포착한다는 장점이 있는 반면에, 패치 내부에 structural information이나 local relationship에 대해서는 무시하는 경향성을 드러냅니다.
추가적으로 Transformer는 shape bias한 성질을 가지고 있기 때문에, 영상 내 중요한 부분에 대해서 집중하는 경향을 보입니다.
반면에 CNN의 경우 고정된 filter weight를 통해 영상 내 패치 단위로 연산을 수행하기 때문에, translation invariance한 성질을 가지고 있으며 이를 통해 local connectivity를 극대화 시킬 수 있다고 합니다. 또한 inductive bias는 CNN이 shape보다는 texture에 더 의존하도록 하는 성질도 있다고 합니다.
이러한 각각의 반대되는 특징들을 잘 조합하는 관점에서 저자는 CNN의 local connectivity와 transformer의 global context를 결합할 수 있도록 하는 모듈을 제안합니다.
i번째 stage에서 Local feature L_{i}에 대해, 저자는 depthwise residual bottleneck block을 적용하였다고 합니다. 해당 블록은 1×1 conv와 3×3 DW conv, 그리고 1×1 conv가 차례대로 구성되어 있으며, 각각의 연산 동안에 채널의 크기는 변경되지 않는다고 합니다. (그럼 왜 bottleneck block이지..?)
그리고 2D reshaped global feature G_{i,j}와 앞서 언급한 local feature L_{i}를 Concat하여 aggregation 해준 다음, 서로가 상호작용하도록 학습시켜주었다고 하는데 수식으로 표현하면 아래와 같습니다.
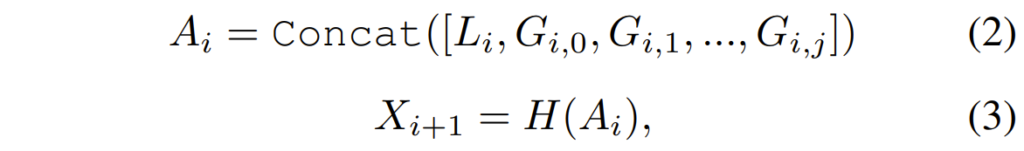
H 함수가 각 feature map들이 상호작용하도록 학습하는 함수라고 보시면 되는데, H함수는 그냥 1×1 컨볼루션입니다. 아무튼 이렇게 연산이 된 X_{i+1} feature map은 다시 앞선 섹션에서 설명한 multi-scale patch embedding부터 쭉 연산을 수행하게 됩니다.
Experiments
실험 부분은 간략하게 ImageNet과 Semantic Segmentation 성능만을 리포팅하겠습니다. Detection 및 Instance Segmentation에 관심 있으신 분들은 해당 논문의 실험 섹션을 참고해주시길 바랍니다.
먼저 ImageNet-1K 결과입니다. 제일 작은 Tiny 모델은 ResNet18보다도 작은 사이즈의 크기를 가지고 있으며 이들 중 성능이 가장 좋은 것을 보실 수 있습니다. 또한 흥미로운 점은 Tiny 다음에 Small이 아닌, XS가 있습니다. 무슨 옷 사이즈도 아니고 XS로 구분을 두나 싶긴한데 아무래도 타 모델들의 Tiny랑 비교하다보니 이름만 놓고 봤을 때 자신들의 모델이 더 무겁다고 느껴질까봐 우리 모델 크기 작아요 라고 은연 중으로 강조하고 싶지 않았나 생각합니다. 물론 실제로도 타 모델 대비 크기가 작은 편에 속하는 것을 볼 수 있으며 반대로 야무진 성능을 보여주고 있습니다.
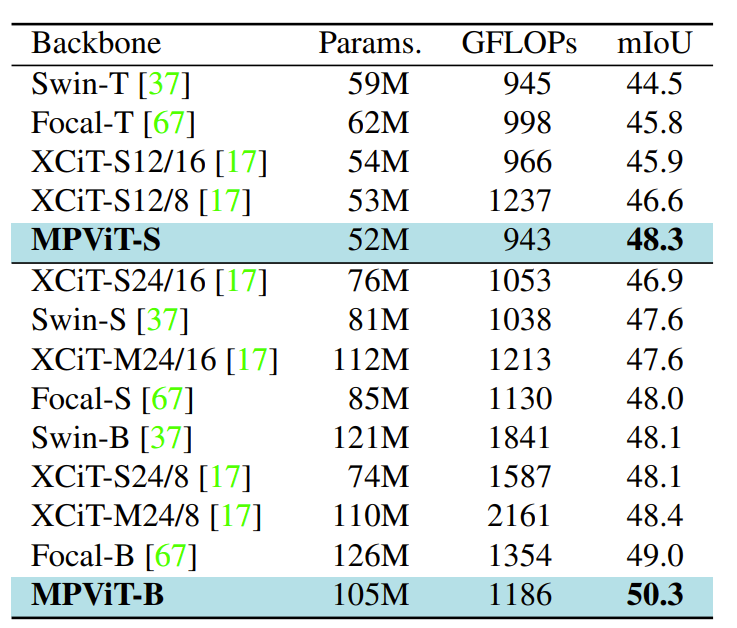
다음은 ADE20k에 대한 semantic segmentation 성능을 리포팅 한 것입니다. 보통 무슨 decoder를 사용했는지에 대해서도 설명해주긴 하는데 여기서는 설명이 없는 것을 보아 가장 흔한 UpperNet을 사용한 것 같습니다.
성능은 베이스 기준 50.3퍼센트로 꽤 좋은 모습을 보여주고 있는데, 다만 왜 Swin-Base랑 비교 안하고 Swin-small이랑 비교했는지는 모르겠네요. 크기 격차만 놓고 봤을 때 Swin-B랑 조금 더 격차가 좁은 것 같은데 흠..
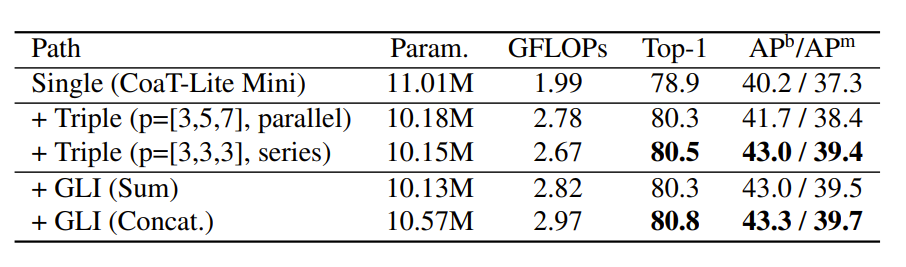
다음은 Ablation study를 나타내는 표입니다. 대략적으로 보시면 아까 multi-stage patch embedding 과정에서 서로 다른 크기의 커널 사이즈(3×3, 5×5, 7×7)를 적용해준다고 했었는데, 이 때 실제로 그 커널 사이즈를 활용하는 것이 아닌, 3×3 컨볼루션을 연달아 사용해서 receptive field가 마치 5×5, 7×7로 늘어나는 효과를 보이는 방식을 채택했었다고 말씀드렸습니다.
아마 그것에 대해 실제 5×5, 7×7필터를 사용한 것 대비 성능이 얼마나 개선되었는가를 의미한 것 같네요. 보시다시피 직접적으로 커널 사이즈를 늘리는 것 보다는 간접적으로 커널 사이즈를 늘리는 방식이 모델의 파라미터 수 및 GFLOP을 미세하게 낮춘 효과도 보였으며 반면에 성능 개선도 꽤나 유의미하게 나타낸 것을 볼 수 있습니다.
커널 사이즈를 높이고 싶을 때 직접적인 방식보다 간접적인 방식이 여러 측면에서 좋다는 것을 알아가게 되네요.
그리고 두번째로 Global-Local Interaction에 대한 실험인 것 같은데, 사실 이 부분도 Local Feature와 Global Feature를 합칠 때 Sum을 할지 아니면 Concat을 할지 그 차이에 대해서만 실험한 것 같습니다. 그 결과 더하는 것보다는 합치는 방향이 더 좋은 결과를 가져왔다고 하네요.
생각보다 높은 성능 향상을 보여주지는 않네요. 고만고만한거 같습니다. Depth estimation에 적용가능할까요?
그래도 뭐 백본 네트워크니깐 Depth Estimation에 적용할 수 있지 않을까 싶긴한데, 결국 attention 연산이 들어가다보니 저희 방법론에서는 학습이 잘 안될수도 있겠네요