안녕하세요. 오늘은 Image retrieval 논문을 가져왔습니다. 연초에 비디오 검색 과제에서 활용하려고 visual search 논문들을 많이 읽었는데요. 이번 논문도 그 연장선이라고 보시면 됩니다. 논문 제목에서도 알 수 있듯이 이 논문은 이미지 검색에 관한 내용입니다. 하지만 기존의 이미지 검색이 아니라 “instance-level”에서의 이미지 검색을 목표로 합니다.
Introduction
이 논문에서 목표로 하는 “Instance-level image retrieval”은 쿼리 이미지가 주어졌을 때, 매우 큰 데이터베이스 이미지들 중에서 쿼리 이미지와 동일한 객체를 포함하는 모든 이미지를 찾는 visual search task입니다. 논문 저자들은 이 연구에 기존의 ImageNet으로 학습된 pretrained_model들의 성능이 향상이 그렇게 좋지는 않다는 부분에 집중했습니다.
그래서 이 논문에서는 Landmark 데이터셋을 재가공한 데이터셋을 제공하고, 이 데이터셋을 효율적으로 학습할 수 있는 모델을 제안합니다. 이와 더불어 이미지에서 물체의 표현력을 향상시키기 위해 R-MAC에 RPN을 결합한 방법론을 제안하고, multi-resolution descriptor를 제안했습니다. 사실 내용이 많은데… 결론은 물체 중심의 데이터셋을 학습 방법과 데이터 셋을 제안했다!로 압축할 수 있을 것 같습니다.
Leveraging large-scale noisy data

[그림 1]은 Landmarks라는 데이터셋의 예시입니다. 이 데이터셋에는 전 세계의 유명 랜드마크 장소들의 사진이 모여있는데요. 문제는 이 데이터셋에 위와 같이 전혀 상관없는 장소가 같은 장소로 분류되어 있습니다. 그리고 내부와 외부 사진이 혼합되어있죠. 이러한 상태는 효율적인 학습을 방해하기 때문에 논문 저자들은 이 문제를 자동으로 수정할 수 있는 방법을 고안해서 두가지의 수정된 데이터셋을 공개했습니다. “Landmarks-full”과 “Landmarks-clean”입니다.
“Landmarks-full”은 너무 적은 데이터를 가진 라벨을 제거하고 중복을 제거해서 만들었다고 합니다. 그리고 landmarks-clean 데이터셋을 만들기 위해서, SIFT와 affine transformation 같은 방법을 이용해서 이미지간의 키포인트 매칭을 수행합니다. 그렇게 이미지간의 유사도 점수를 확보하고, 이를 연결 그래프 형태로 구성합니다. 이 방법을 통해 같은 클래스의 이미지들이 서로 유사한 이미지를 확실하게 가지고 있도록 했습니다.
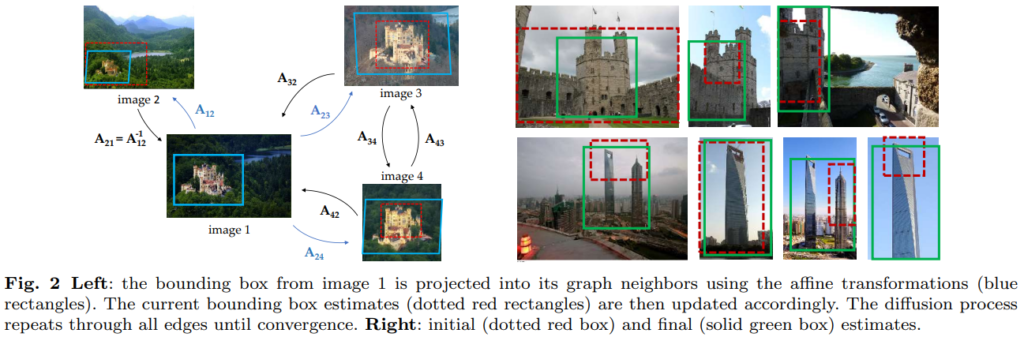
하지만 하나의 문제가 더 있습니다. 정확히 유사한 이미지들을 정제해냈지만, “Bounding box”를 어떻게 추정하는지에 대한 문제가 남았습니다. 대략적인 Box위치를 빨간색과 같이 가지고 있을 때, 파란색 혹은 초록색과 같이 전체 건물을 커버할 수 있도록 수정할 필요가 있다고 합니다. 이 과정도 앞에서 사용했듯이 keypoint를 매칭시키도록 diffusion process를 업데이트하며 수행해주었다고 합니다.
Learning to rank: an end-to-end approach
Learning to retrieve
R-MAC의 장점은 모든 연산이 미분 가능하다는 것입니다. 이 점에서 착안해서, 이 R-MAC을 detection의 맥락에서 RPN을 결합시킬 수 있다는 결론이 나옵니다. 또한, PCA는 shift와 FC 레이어의 조합으로 볼 수 있기 때문에, 여기서는 PCA를 쓰는게 아니라 이 조합으로 대체하였다고 합니다. RPN의 결합에 관한 내용은 뒤에 나옵니다. 아무튼… 이 검색 결과로부터 좋은 학습 결과를 이끌어 내기 위해 두가지의 Loss를 고안했다고 합니다.
Learning with classification loss (Cls)
Landmark 데이터셋을 Cross-entropy loss를 사용해서 학습을 하면서, 기존의 weight를 improved convoultion filter로 대체해서 R-MAC에서 베이스라인을 잡았다고 합니다. 이 학습에서는 두가지 부분을 주의해야합니다.
- Retrieval로 학습하는 것이 아니라, Classification으로 학습을 한다.
- R-MAC을 통해 학습하는 것이 아니라, low-resolution square crops을 이용한 classification 구조로 학습을 한다.
학습이 다 끝난 다음에 R-MAC weight를 사용하는 이런 단순한 파인튜닝 방법론이 성능이 좋다는 것을 보여주고 있습니다.
Learning with ranking loss (Rnk)
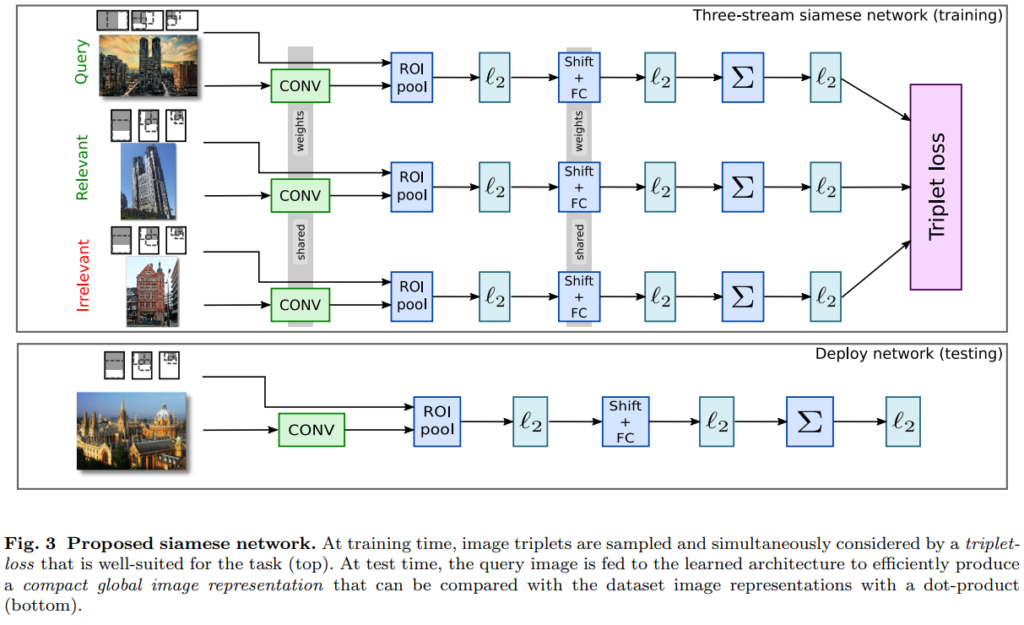
Triplet loss에 기반한 ranking loss를 사용하기 위해 [그림 3]과 같이 siamse network를 구성하였습니다. 사실 이건 이제는 triplet loss하면 다들 아실만한 방법이죠?
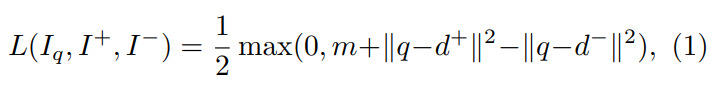
q는 R-MAC descriptor이고, I는 이미지를 뜻합니다. d는 descroptor를 뜻하고요. 위 수식에서 마진 m을 가진 상태에서 Query 이미지와 Relevant 이미지, Irrelvant 이미지간의 표현력을 학습합니다.
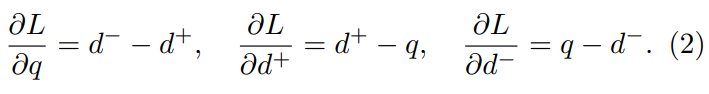
그리고 0이 아닌 loss값을 생성하기 위해 위와 같은 sub-gradient를 또 계산한다고 합니다. 중요한 점은 학습을 할때 PCA까지 학습합니다. 위에서도 말했다시피 여기서 PCA는 Shift와 FC레이어의 조합이기 때문에 그렇습니다.
Practical considerations
Triplet loss를 사용할 때 적절한 Triplet이 있어야 성능이 오릅니다. 여기서는 이 성능이 오르는 조합을 확보하기 위해 무작위 샘플링을 통해 후보군을 만들고, 후보군 안에서 학습을 해서 최종적으로 Loss가 높은 하나의 쌍을 선택합니다. 이 문제는 이 쌍을 고르기 위한 시간을 많이 소요한다는 것이 문제라고 하는데… 사실 이 부분은 Triplet loss를 이렇게 쓰면 공통적인 문제가 아닌가합니다. 이와 더불어 학습할 때 메모리를 많이 먹는 것도 문제입니다. 사실 이때 학습에 사용한 M40 GPU 메모리가 12기가더라고요. 그래서 이런 문제점들 해결하기 위한 우회방법이 제시되어있는데, 요즘은 더 좋은 방법이 많은 것 같아 리뷰에서는 넘어가겠습니다.
Experiments
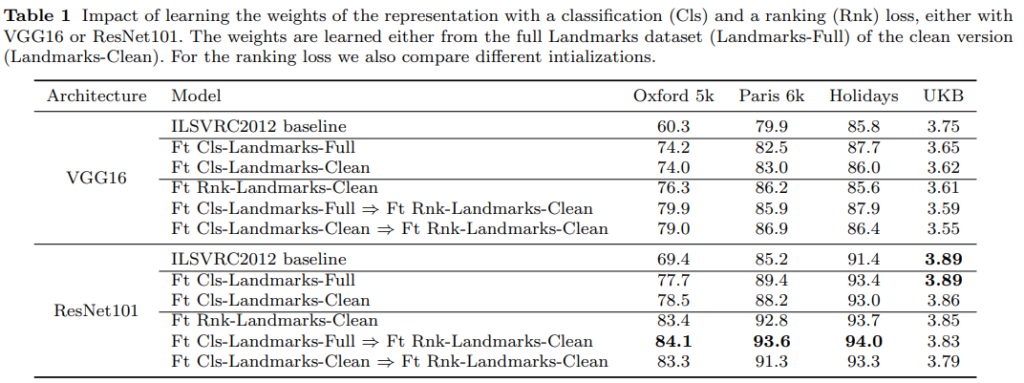
이렇게 설계한 R-MAC 베이스라인과 설계한 두가지 loss(Cls, Rnk)가 성능에 미치는 영향을 분석하기 위해 실험을 수행합니다. 일단, 학습은 ImageNet pretrained weight에서 Lanmarks데이터셋으로 파인튜닝 하는 방식으로 진행했는데요. 일단 성능이 전반적으로 크게 올랐습니다. 다만 Rnk loss는 Landmarks-Full에서 성능이 좋지 않아서 단독 실험은 빠졌다고 합니다.
이러한 점을 고려해도 성능이 크게 오르는 것은 논문 저자들이 주장한 것 처럼, 기존의 Imagenet 기반의 pretrained weight는 물체 중심의 이미지 검색에 적합하지는 않다는 것을 보여주는 것 같습니다. 그래서 Full 데이터셋을 통해 Cls를 학습하고, Clean 데이터셋에서 Rnk를 학습하는 파인튜닝이 성능이 제일 좋았다는 것을 보여줍니다. 실제로 예시 그림도 첨부되어 있는데, 학습 후에 유사한 이미지들을 잘 찾아내는 것을 보입니다.
Improving the R-MAC representation
R-MAC이 end-to-end 방법론에서도 효과적임을 앞선 baseline을 구축하면서 보였으니, 앞에서 말한 것 처럼 RPN을 결합해서 성능을 향상시켜봅시다!
Beyond fixed regions: proposal pooling
일단 R-MAC의 고정된 multi-scale 그리드가 문제라고 제시됩니다. 이 방법은 최소한 한 영역에는 물체가 위치하도록 하지만, 사실상 어느 물체도 그리드와 정확하게 일치하지도 않고, 물체가 작아질수록 대부분이 배경을 가리킵니다.
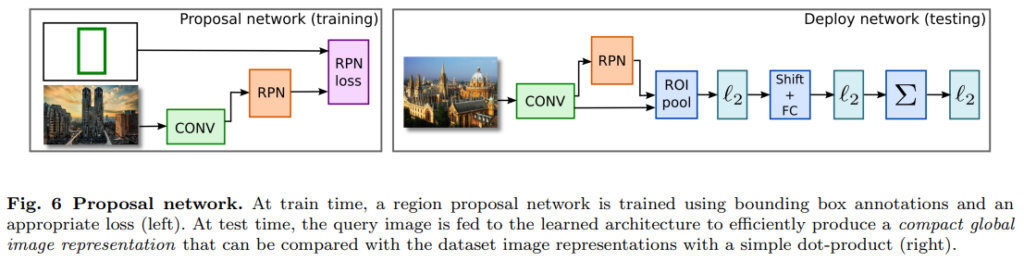
그래서 R-MAC의 구조를 수정해서 이 그리드를 RPN을 통해 지정하도록 합니다. 사실 아까 데이터셋을 가공할 때, bounding-box를 가공해준 이유가 바로 이 RPN 때문입니다. [그림 6]과 같은 구조를 통해 RPN을 통해 물체의 위치에 그리드가 지정되도록 할 수 있게 됩니다.
사실 정확한 위치를 RPN이 반환하는 것을 기대하는 것은 아니고, RPN도 여러 candidate box를 그리고 이 box안에 물체가 위치하는지의 확률을 계산해서, 최종적으로 K개의 proposal을 생성함으로써 고정된 그리드를 완전히 대체합니다. 이러한 수정을 통해 겹치지 않으면서도 물체를 포함하고 있는 관심 영역을 생성할 수 있다고 합니다. (겹치지 않는 것의 장점은 최종적으로 matching을 수행할 때 적은 수를 수행할 수 있어서 장점이라는 뜻입니다.)
RPN loss는 classification loss와 regression loss를 함께 사용했다고 합니다. Box의 라벨은 binary class로 설정했고요. 사실 이 학습 과정은 detection에서 쓰는 것과 동일한 듯 합니다. 학습은 먼저 rigid grid를 통해 학습을 한 다음, 마지막 conv 레이어의 값만 이용해서 RPN을 학습했습니다. RPN만 따로 학습한 이유는, 딱히 Rnk를 같이 학습해도 성능이 오르지 않아서 그렇게 했다고 하네요.
Multi-resolution
R-MAC이 최초로 제안되었을 때 이미지의 크기는 고정값인 것으로 제안되었다고 합니다. 물체의 크기가 다양하기 때문에 논문 저자들은 이 문제를 개선하고 싶었습니다. 그래서 R-MAC이 이미지의 비율은 유지하지만, 3가지의 크기를 가지도록 했습니다. (마지막에 aggregate하기 때문에 최종 descriptor는 하나입니다.) 이건 R-MAC이 어떤 크기의 이미지를 입력받던지 같은 크기의 descriptor를 반환하는 특성에서 이렇게 만들었다고 하네요. 이렇게 3가지의 크기를 저장하는 방법을 multi-resolution이라고 부르고, 사실 이미 다른 연구들에서도 transformation-invariant representations을 위해서 많이 사용한 방법이라고 합니다. 다만, 여기서는 siamese network에서도 적용했다는게 큰 차이라고 하네요.
Experiments
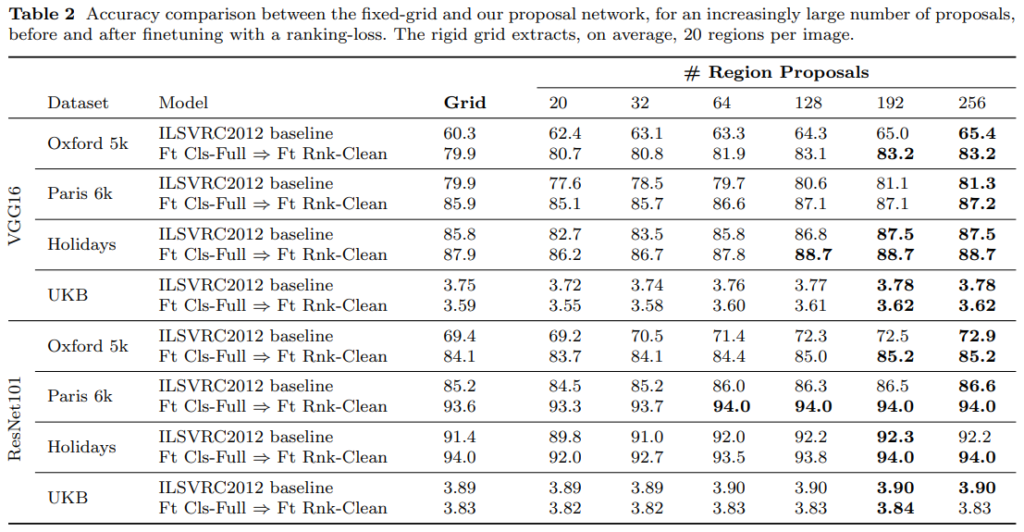
Grid는 베이스라인 성능이고, Region Proposal의 성능이 R-MAC의 그리드를 RPN으로 대체한 성능입니다. 전반적으로 성능이 올랐지만, ResNet에서는 VGG에 비해 큰 성능 향상을 보이지 않았습니다. 논문 저자들은 이에 대해 원래 Resnet 자체가 배경을 덜 보고, representation을 잘 만들어서 그렇다고 분석합니다. 그래서 딱히 RPN을 적용할 필요가 없기 떄문에, 이 뒤의 실험에서 Resnet의 경우 RPN을 적용하지 않고 실험했다고 합니다.
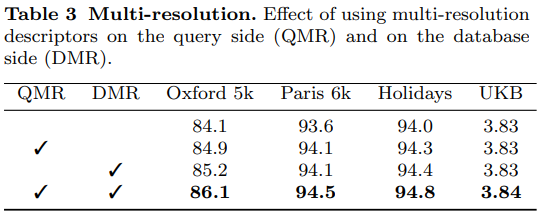
전반적으로 약간의 성능 향상이 있었는데… 검색 속도와 저장 공간을 그대로 유지하면서도 이정도 성능 향상을 보일 수 있다는 것은 좋습니다. 하지만 데이터셋에 있는 물체의 scale의 변화가 커야 성능 향상이 있는 방법론이 아닌지… 생각이 드네요.
Experiments
Evaluation of QE and DBA
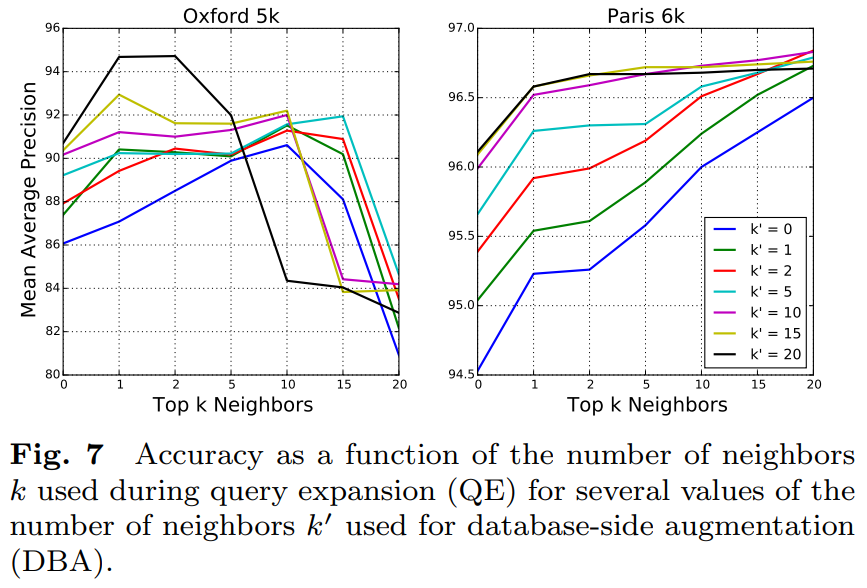
보다 더 나은 성능을 위해서, Query expansion(QE)와 Database-side augmentation(DBA)를 통해 성능 향상을 이끌어냈다고 합니다. QE와 DBA는 성능 향상을 위해 이미지 검색 분야에서 흔히 사용하는 방법론이라고 합니다.
QE는 이름에서 알 수 있듯이 말 그대로 쿼리를 확장하는 방법론입니다. 이미지가 입력되면, 그 이미지를 바탕으로 Top K개의 이미지를 선택하고, 이를 spatial verification stage를 통해 일치하는 결과들을 묶어서 두번째 쿼리로 만드는 방법입니다. 검색 정확도는 올라가지만, 검색 속도는 두배로 걸리는 방법인것이죠.
DBA는 데이터 베이스에 저장된 이미지들을 바탕으로 수행됩니다. 특정 이미지의 주변 이미지들의 feature를 leveraging하는 방법을 통해 표현력을 향상시킵니다. 사실… 설명만 읽으면 왜 좋아지는지는 이해하기가 어려운데, 일반적으로 image signature가 비슷한 상태로 저장되어있으면 같은 object를 가진 물체니까 이를 통해 검색 표현력 향상을 노리는 것 같습니다.
성능 평가에서 알 수 있듯이 데이터셋에 따라 성능이 오르거나 떨어지는데요. 이건 Paris 데이터셋에서는 쿼리와 관련된 이미지가 데이터셋에 많아서 그렇다고 합니다. 이러한 성능 평가를 통해 QE는 1로, DBA는 20으로 설정했다고 합니다.
Comparison with the state of the art
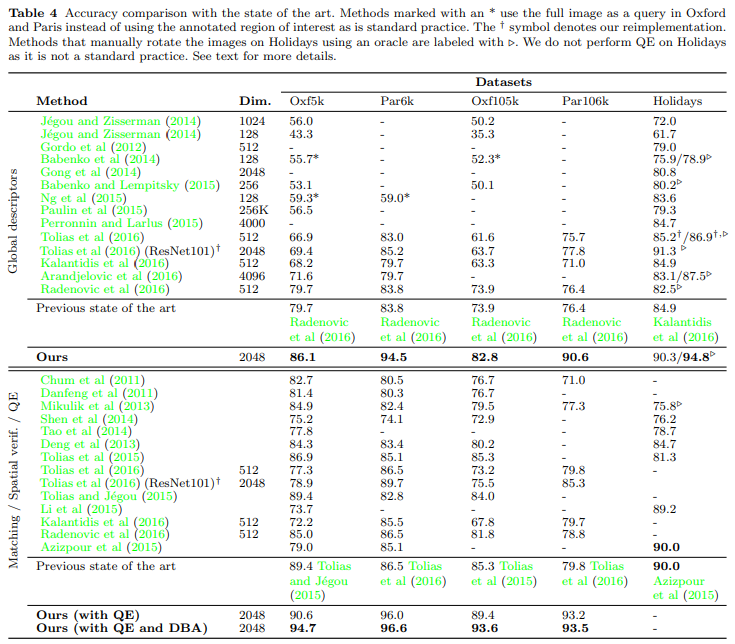
다른 방법론들과 비교해봤을 때, 큰 폭으로 성능이 오른 것을 확인할 수 있습니다. 일단 성능이 오르지 않은 것처럼 보이는 Holidays 데이터셋에서는 평가 프로토콜이 다르기 때문에 그 부분을 감안하면 SOTA입니다. 결국 이 논문 저자들이 말하는 최종적인 내용, 물체 중심의 이미지 검색은 기존의 pretrained된 모델로는 적합하지 않으니 파인튜닝을 해야한다는 주장이 옳다는 것을 크게 오른 성능으로 보입니다.
Short image codes with PCA and PQ
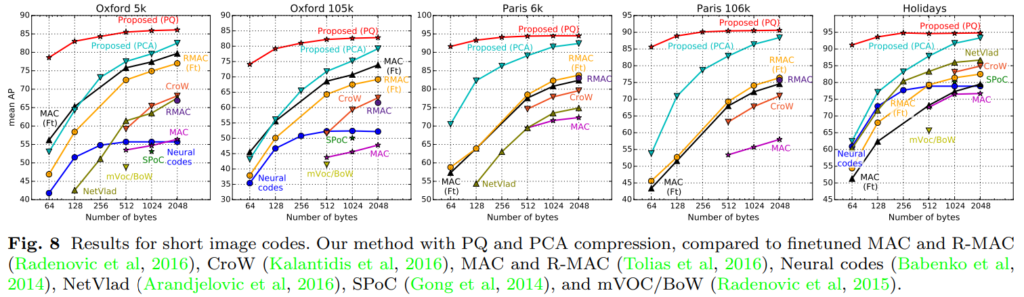
검색 시스템의 효율성을 위해서 PCA와 PQ에 대한 실험도 함께 수행했습니다. PCA와 PQ에 대한 학습은 Landmarks-clean에서 수행했다고 합니다. 표 아래의 숫자가 압축된 descriptor 크기인데요. 역시 제안된 방법론이 전반적으로 압축을 해도 성능이 좋았고, 그중에서도 PQ가 정확도가 떨어지는 정도가 가장 덜했습니다. 이건 사실 실제 시스템에서 적용할 때, 검색 속도와 저장공간 문제를 해결하기 위해 적용하는 방법론이라… 이정도만 알면 될 것 같습니다.
Conclusion
논문을 읽으면서 기존의 비디오 검색 모델들도 R-MAC을 많이 사용하기 때문에, 이 방법론으로 물체 중심의 비디오 검색으로 활용할 수 있지 않을까 하는 생각을 하긴 했지만, 논문 저자들이 말하는 대로라면 Resnet 백본에서 성능 향상을 기대하기는 어려울 것 같다는 생각도 듭니다. 물론 물체 중심의 비디오 데이터셋을 어떻게 구성하느냐에 따라 차이가 있을 것 같긴 합니다. 이런 부분들도 고려를 해 봐야겠습니다.
PCA를 differentiable하게 바꿔서 end-to-end 로 파이프라인을 구성하기 위해 PCA는 shift와 FC 레이어의 조합으로 replace한걸로 이해했는데요. 해당부분에 대해서 좀 더 자세히 설명해주실수 있나요?
딱히 추가적인 설명이 논문에 없긴 한데, 다시 정리해드리면 PCA도 학습 가능하게 변경하기 위해 PCA를 shift(mean centering) + FC(projection)으로 바꾸어 사용했다고 합니다. 이러면 각각의 weight를 학습할 수 있게 된다고 합니다.
평가에 사용한 데이터 셋에서 각각 finetuning을 했나요? 혹은 finetuning만을 위한 데이터 셋이 따로 있나요?
파인튜닝은 Landmark. 데이터셋으로 위에 보이는 데이터셋 4종을 재가공한 데이터셋에서 파인튜닝 하였습니다.